本系列已完结,全部文章地址为:
Transformer解析——(二)Attention注意力机制-CSDN博客
Transformer解析——(三)Encoder-CSDN博客
1 背景
Transformer诞生于经典的论文《Attention is All You Need》,用于Seq2Seq任务,即输入一个序列,输出一个序列,输出的序列长度由模型决定。序列可以是一段文字,一串语音等,所以应用场景包括语音识别、语言翻译、聊天机器人等。近期火爆的DeepSeek也是基于transformer架构的。
Transformer最大的特色就是使用Attention机制,关注上下文的影响。以语言翻译为例,上下文对于机器理解语义是非常重要的,比如英译汉"Bob is a boy, he is smart.",如果想让机器理解"Is Bob smart?",机器需要识别Bob和he的上下文关系。RNN虽然也可以处理上下文,但是无法并行训练,因为RNN要将上一时刻的输出作为这一时刻的输入。而transformer优点是可以并行训练,提高了效率。
Transformer主要包含2个组件,Encoder(编码器)和Decoder(解码器)。Encoder和Decoder均应用Attention机制。
Encoder和Decoder的作用与AutoEncoder类似,可以类比理解:编码是为了提取信息本质;解码是为了将信息本质通过文字这一载体为人所知。 编码时输入多少字就输出多少字,输出的内容就是对应输入文字的信息。解码时输出文字的长度是不定的,直到输出<END>(结束符号)才结束。
2 结构
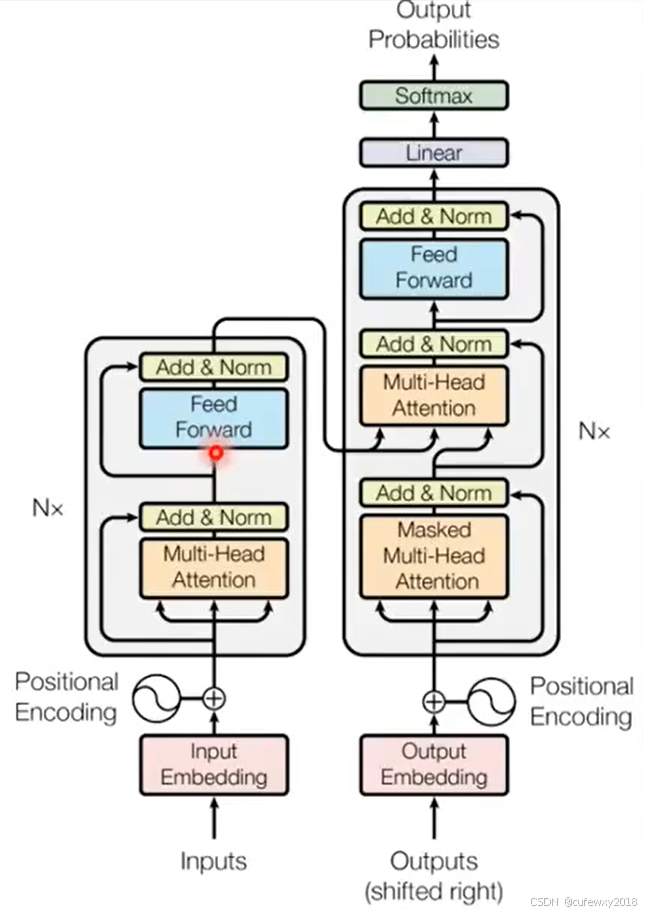
Transformer整体的结构如上图所示。
左侧下方是输入序列,先经过分词转换为计算机可以看懂的数字;经过Embedding将每个词转换为向量;通过Positional Encoding加入位置信息。传入到Encoder。
左侧上方是Encoder,由N个Block组成,每个Block包含多头注意力、Add&Norm归一化、前馈神经网络、Add&Norm归一化,结果输出到Decoder中。
右侧下方是目标序列,同样经过分词等操作输入到Decoder中。
右侧上方是Decoder,同样由N个Block组成。接收目标序列的输入到多头注意力模块,经过Add&Norm归一化后输入到交叉注意力模块,同时Encoder的输出也将输入到交叉注意力模块,通过Add&Norm归一化、前馈神经网络、softmax等步骤,得到输出每个词的概率。
3 输入
下面笔者具体介绍Transformer的各组件,先简要介绍输入。
3.1 Token化
首先需要将输入的文字转变为计算机可以看懂的数字。可利用Bert等模型将输入的文字转变为token,类似于分词。
Token是语言模型中常见的概念,中文可称为“词元”,是文本处理的基本单元。对于英文来说,Token类似于词根词缀,例如unhappiness可能拆分成un(表示否定)+happy(表示快乐的情感)+ness(表示名词),机器将该词分解成了3个token来处理。比如机器识别到这里的"ness"表示名词,那么后续可能会接上"is"构成“主系表”结构。对于中文来说,一个汉字不能再继续拆分了,所以Token至少是一个汉字,也可能是多个。比如“我想旅游”可以拆成“我”+“想”+“旅游”3个token。
3.2 Input Embedding
利用Embedding神经网络将每个token由一维转变为多维的向量,Embedding中的权重是可学习的。
Embedding神经网络的作用是将单个数字转变成N维向量。需要设置输入和输出大小。输入大小即词汇表的大小,输出大小即希望每个token转变的维度数N。假设词汇表的大小是6(即每个token的标号是0到5),想将token转变为2维的向量,则神经网络的输入和输出分别是6和2。
假设词汇表是0:你,1:好,2:我, 3:想, 4:学, 5:旅游,那么“我想旅游”这句话由3个token组成[2, 3, 5],代表在词汇表中的位置。做one-hot处理后,3个token每个维度都变成6,one-hot指词汇表维度中只有对应位置的元素为1,其余位置元素为0,例如“我”表示成[0,0,1,0,0,0]。将该6维数据输入到神经网络中,输出是2个神经元,即得到2维向量。
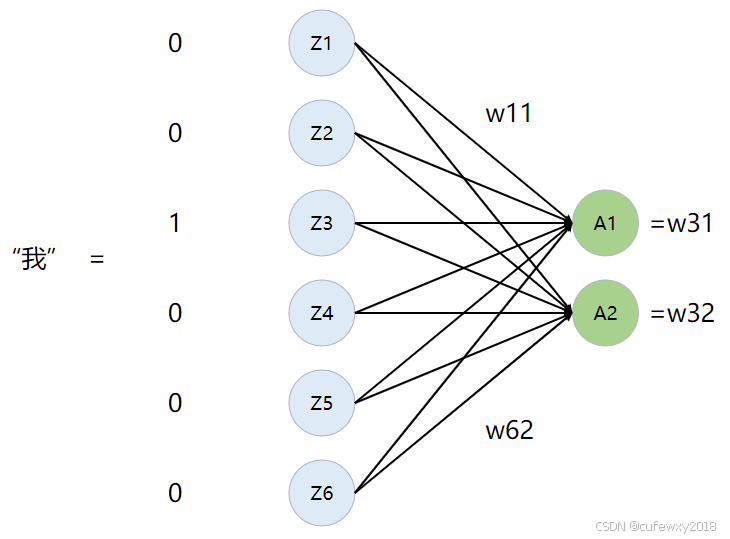
实际上Embedding等价于一个6*2的矩阵。输入的单词通过one-hot转变成1*6的矩阵,与Embedding矩阵相乘后即可得到1*2的矩阵,实现了单词升为2维向量。

由上述分析可知,如果Embedding输入一个比词汇表大小更大的数,比如10,是会报错的,因为无法用6维的one-hot表示。
在单词做Embedding后,需要先除以sqrt(d_model),d_model表示词向量大小。因为Embedding是线性加权,d_model维度越高会导致数值越大,影响词向量表示效果。
3.3 Positional Encoding
语序对于翻译是有影响的,比如“我打球”和“球打我”是完全不一样的意思。Transformer没有使用RNN的方式处理语序影响,而是使用位置编码控制语序。
虽然用Attention能处理每个词与整个序列的相关性,但并不掌握每个词语位置的信息。换句话说,只要模型的参数训练好,把输入的序列打乱,计算Attention的结果是一样的,因此要加入位置信息。
可能有读者有疑问,Attention计算时不是考虑了上下文吗,上下文不是语序吗?Attention考虑了上下文不错,但上下文不等于语序。计算Attention时是打乱了语序的,比如"What a beautiful day"中,计算"day"和其他词(注意模型中实际是计算token之间的注意力,这里笔者为了方便理解直接用词代替)的注意力时,并不会因为与"beautiful"距离近就提高attention,也不会因为与"what"远就降低attention。
请注意Input序列是并行输入的,并没有顺序。【如果读者没有相关基础知识,可先略过此段落】。Decoder最开始是将<BEGIN>标识符输入到第一个attention,然后将Encoder的输出输入到第二个attention,预测出各个词的概率。那么如果我们把Encoder的输入顺序打乱,QKV参数是不变的,那么他们之间的Attention结果是不变的,Encoder的输出只是换了个顺序,并不影响最终概率的计算。就像是如果只考虑实力,跳水运动员的成绩不会受到他们出场顺序影响一样。
经典的位置编码的算法是用正余弦函数。具体算法为
PE(pos,2i)=sin(pos/10000^(2i/d))
PE(pos,2i+1)=cos(pos/10000^(2i/d))
其中PE表示Position Encoding,pos表示位置序号(即第几个token),2i表示词向量维度中偶数的部分,2i+1表示词向量中奇数的部分(即第pos个token中词向量第2i或2i+1维度),d表示词向量维度大小。
这样设计的好处是:
第一,方便识别词与词之间的相对位置关系,因为第i个词与第i+k个词之间是有规律的,基于正弦和余弦定理,sin(i+k)=sin(i)cos(k)+cos(i)sin(k), cos(i+k)=cos(i)cos(k)-sin(i)sin(k),因此,两个前后间隔k个位置的编码是有线性规律的,这就像是编码阶段预留的“彩蛋”,后续transformer训练时也可以找到这种规律,从而理清楚词与词之间的位置关系。
第二,正余弦函数是周期性函数,因此可以处理任意长度的序列,即使序列很长超过训练集里最长的序列,也可以代入位置编码函数中得到结果。
第三,计算效率高,sin和cos都是简单函数,而且导数也易于计算。
将位置编码叠加到Embedding,即可得到最终的输入。
4 行文思路
本系列中笔者尽量避免照本宣科,而是以问题为切入点,并辅以通俗例子讲解。这样的行文思路可以帮助读者理解Transformer为什么这么设计。笔者希望本系列走出“懂的都懂,不懂的依然不懂”的怪圈。当然,在此之前可能需要读者有部分机器学习的背景知识。