通常我们都从两个层面定义性能场景的需求指标:业务指标和技术指标。而两个指标是不能脱离开来的,例如我们可以回答 "在多少的响应时间有多少个TPS"这样的问题,但不能回答“业务状态是什么”的问题。
举例来说,如果一个系统要支持 1000 万人在线,可能你能测试出来的结果是系统能支持 1 万 TPS,可是如果问你,1000 万人在线会不会有问题?这估计就很难回答了。
可以看一张图
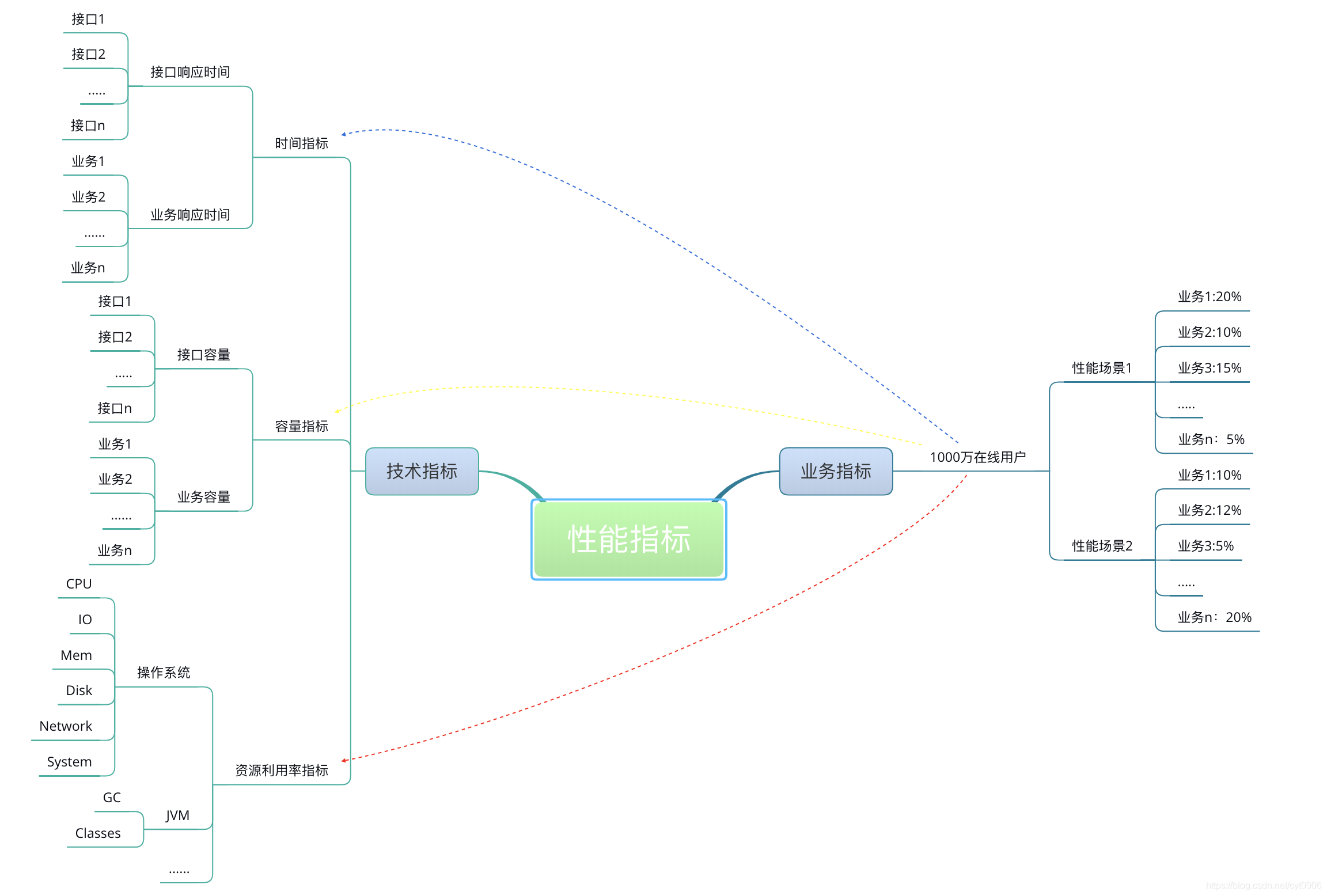
这个示意显然不够详细,但也能说明关系了。所有的技术指标都是在有业务场景的前提下制定的,而技术指标和业务指标之间也要有详细的换算过程。这样一来,技术指标就不会是一块废地。同时,在回答了技术指标是否满足的同时,也能回答是否可以满足业务指标。
比如我们可以把用户从发送请求到被响应,定义为一个技术指标,也是能够回答问题的,但是业务流程往往很复杂,需要考虑的地方也很多。
行业常用的性能指标表示法:

对这些性能指标都有哪些误解
为了区分这些概念,我们先说一下 TPS(Transactions Per Second)。我们都知道 TPS 是性能领域中一个关键的性能指标概念,它用来描述每秒事务数。我们也知道 TPS 在不同的行业、不同的业务中定义的粒度都是不同的。所以不管你在哪里用 TPS,一定要有一个前提,就是所有相关的人都要知道你的 T 是如何定义的。
通常情况下,我们会根据场景的目的来定义 TPS 的粒度。如果是接口层性能测试,T 可以直接定义为接口级;如果业务级性能测试,T 可以直接定义为每个业务步骤和完整的业务流。
所以要创建什么级别的事务,完全取决于测试的目的是什么。同样的我们根据测试的目的,选择性能指标例如QPS、RPS、HPS这些。
这些性能指标概念本身并没有问题,但是当上面的概念都用来描述一个系统的性能能力的时候,就混乱了。对于这种情况,有几种处理方式:
1、用一个概念统一起来。直接用 TPS 就可以,其他的都在各层面加上限制条件来描述。比如说,接口调用 1000 Calls/s(CPS,每秒调用数),这样不会引起混淆。
2、在团队中定义清楚术语的使用层级。
3、如果没有定义使用层级,那只能在说某个概念的时候,加上相应的背景条件。
所以,当你和同事在沟通性能指标用哪些概念时,应该描述得更具体一些。在一个团队中,应该先有这些术语统一的定义,再来说性能指标是否满足。
响应时间 RT
从上面这张图我们可以得出相应时间 RT = T2 - T1,没错吧很简单。但是我们忽略了一个问题,如果这个相应时间很久问你原因是什么,可不可以优化你就傻了。我们来看下一张图。
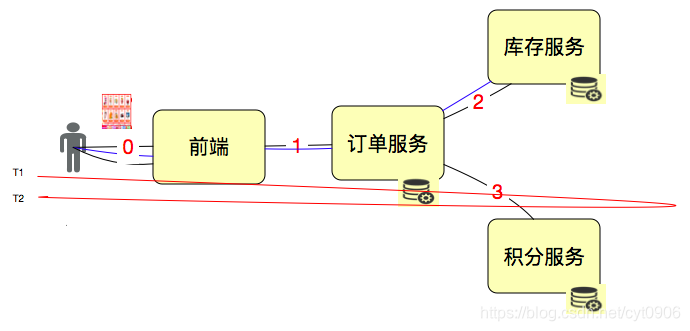
我们要先画架构图,看请求链路,再一层层找下去。去看到底是哪个地方影响了RT。
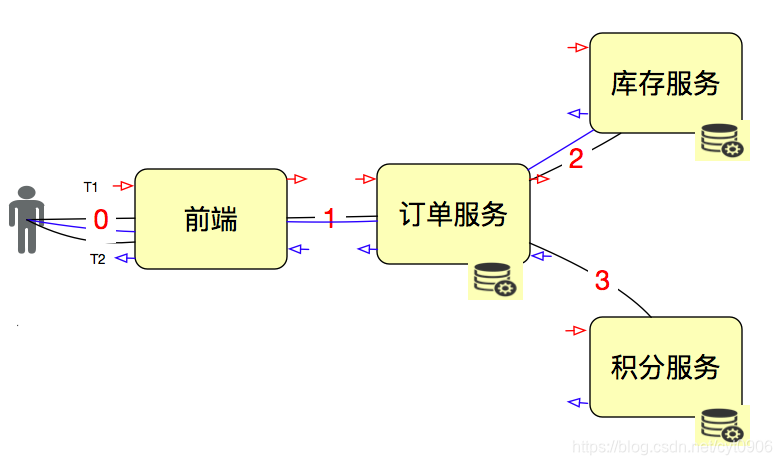
其实这件事情做起来不复杂,会有一些链路监控工具帮助我们做这件事情。但是我们要知道,这并不是性能测试的结束,还有最重要的调优。而调优是件很复杂的事情,需要很多基础理论。
压力工具中的线程数和用户数与 TPS
这里先说明一个前提,上面的一个框中有四个箭头,每个都代表着相同的事务。
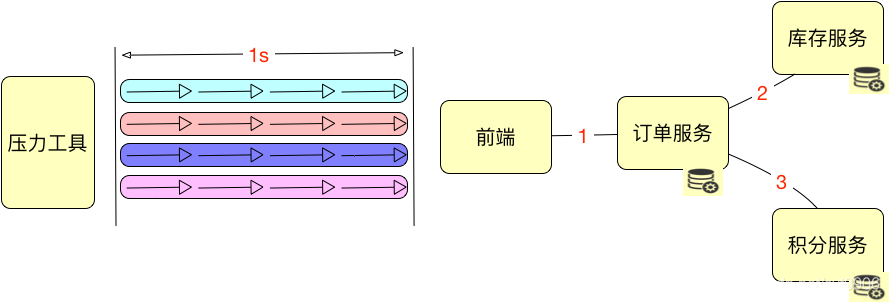
在解释这张图前,我们要先明确 ”并发“ 这个概念用什么来承载。可以是TPS、QPS、RPS等等,但是不管用什么指标,我们都要明确它的含义,并让其他人也清楚这个在上文对这些性能指标都有哪些误解已经说过了。这里就用TPS好了。
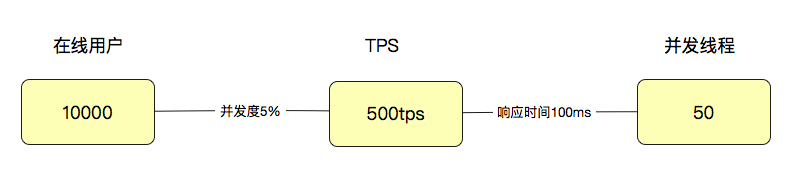
上图表示的很清楚,压力工具有4个线程,每1秒钟可以处理4个事物。所以并发(TPS) = 4 * 4 = 16 。
那么用户数怎么来定义呢?如果系统的在线用户是1万,哪同时并发就是1万TPS吗,显然是不会的。通常,我们会对在线的用户做并发度的分析,在很多业务中,并发度都会低于 5%,甚至低于 1%。
如果拿5%来计算 TPS = 10000用户 * 5% = 500 (TPS) ,我们同时需要响应500个TPS,如果响应这500TPS需要100ms
那么压力工具需要 500 / (1000ms/100ms) = 50线程(1s = 1000ms ,TPS每秒事务数,因为响应时间为100ms故每秒10TPS)
通过这样简单的计算逻辑,我们就可以看出来用户数、线程数和 TPS 之间的关系了。
但是!响应时间肯定不会一直都是 100ms 的嘛。所以通常情况下,上面的这个比例都不会固定,而是随着并发线程数的增加,会出现趋势上的关系。
业务模型的 28 原则是个什么鬼?
有些文章中写性能测试要按 28 原则来计算并发用户数。大概的意思就是,如果一天有 1000 万的用户在使用,系统如果开 10 个小时的话,在计算并发用户数的时候,就用 2 小时来计算,即 1000 万用户在 2 小时内完成业务。
这符合业务逻辑吗,每个系统的并发度都由业务来确定,而不是靠这样的所谓的定律来支配着业务。
业务模型应该如何得到呢?
这里有两种方式是比较合理的:
1、根据生产环境的统计信息做业务比例的统计,然后设定到压力工具中。有很多不能在线上直接做压力测试的系统,都通过这种方式获取业务模型。
2、直接在生产环境中做流量复制的方式或压力工具直接对生产环境发起压力的方式做压力测试。这种方式被很多人称为全链路压测。其实在生产中做压力测试的方式,最重要的工作不是技术,而是组织协调能力。
响应时间的 258 原则合理吗?
对于响应时间,有很多人还在说着 258 或 2510 响应时间是业内的通用标准。然后我问他们这个标准的出处在哪里?谁写的?背景是什么?几乎没有人知道。真是不能想像,一个谁都不知道出处的原则居然会有那么大的传播范围,就像谣言一样,出来之后,再也找不到源头。
其实这是在 80 年代的时候,英国一家 IT 媒体对音乐缓冲服务做的一次调查。在那个年代,得到的结果是,2 秒客户满意度不错;5 秒满意度就下降了,但还有利润;8 秒时,就没有利润了。于是他们就把这个统计数据公布了出来,这样就出现了 258 principle,翻译成中文之后,它就像一个万年不变的定理,深深影响着很多人。
距离这个统计结果的出现,已经过去快 40 年了,IT 发展的都能上天了,这个时间现在已经完全不适用了。所以,以后出去别再提 258/2510 响应时间原则这样的话了,太不专业。
那么响应时间如何设计比较合理呢?
这里有两种思路推荐给你。
1、同行业的对比数据。
2、找到使用系统的样本用户(越多越好),对他们做统计,将结果拿出来,就是最有效的响应时间的制定标准。
性能测试概念中:性能指标、性能模型、性能场景、性能监控、性能实施、性能报告。
性能场景中:基准场景、容量场景、稳定性场景、异常场景。
性能指标中:TPS、RT。 (记住 T 的定义是根据不同的目标来的)