ed编辑器
Ken Thompson编写,一个unix的标准文本编辑器(单行纯文本编辑器)。
特点:
单行编辑器, 一次只能编辑一行, 以非全屏的方式进行,这一点与vi,vim文本编辑器有很大的区别。
ed编辑器可以用于创建、修改、显示文本文件。
当用ed打开一个文本文件的时候,将复制文件的内容到ed命令的缓冲区中, 在ed中的操作都是造作在缓冲区的复制文件中,只有在命令行状态写入的时候才会改变原文本的文件。
ed编辑器的模式:
- 命令模式(command mode):输入的是命令, 制定对编辑文本的操作。进入编辑器的默认模式。在命令行模式里如果输入非法字符将出现
?。
2.输入模式(input mode):输入的是文本,配合命令行模式对源文件进行一定的修改。模式的转化:
命令行模式转输入模式:a:在文件的末尾添加新的内容、c:把文件的最后一行替换成输入的内容、i:在最后一行的前面输入
输入模式转命令行模式:.
通常使用:
重要的点:
地址:在ed编辑器中, 默认的地址是文件的最后一行。最后的保存命令会根据地址对编辑文本进行操作。
改变并且输出当前行的内容:
.表示当前行
$表示文本的最后一行
n表示文本的d第n行
-n表示从当前行开始的前面的第n行
+n表示从当前行开始的后面的第n行
-表示从当前行向后一行
+表示从当前行向前一行
m,n表示从文本的第m行到第n行
,表示文本的所有行
;表示从文本当前行到最后一行
/reg/从当前行起, 下一个匹配的行
?reg?从当前行起, 上一个匹配的行
小例子:
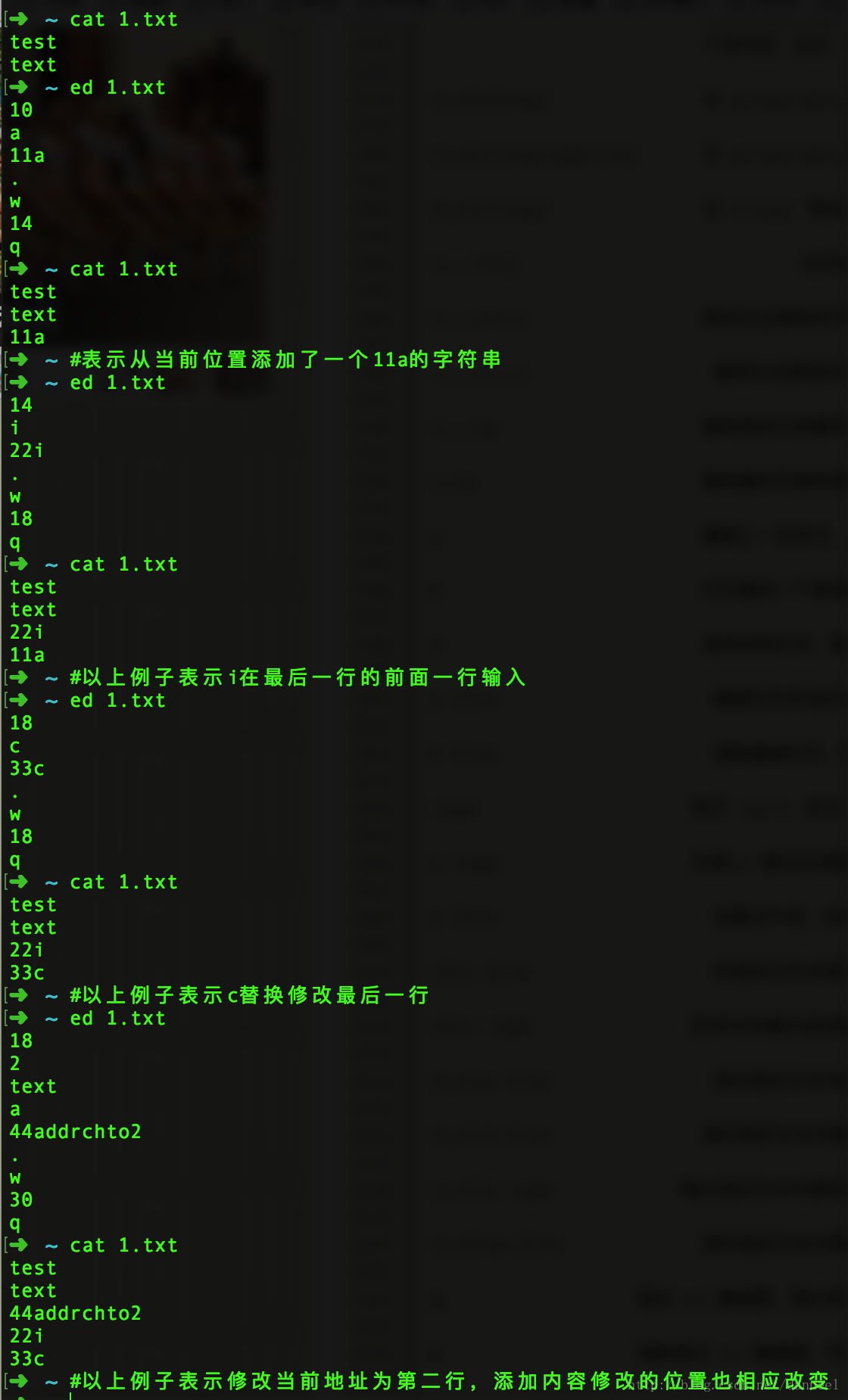
注:ed命令打入的时候如果没有写入文件名, 则可以在最后的命令行w [filename] 之后加上名字。
sed:非交互式面向字符流的编辑器
命令格式:
- sed [options] ‘command’ file(s)
- sed [options] -f scriptfile file(s)
命令选项
-e command, –expression_r=command ##允许多台编辑。
-h, –help ##打印帮助,并显示bug列表的地址。
-n, –quiet, –silent ##取消默认输出。
-f, –filer=script-file ##引导sed脚本文件名。
-V, –version ##打印版本和版权信息。
常用命令操作
删除:d命令
sed′2d′example−−−−−删除example文件的第二行。 sed ‘2, d′example—–删除example文件的第二行到末尾所有行。 sed ' d′example—–删除example文件的最后一行。 sed ‘/test/’d
example—–删除example文件所有包含test的行。
替换:s命令
sed‘s/test/mytest/g′example—–在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。 sed -n ‘s/^test/mytest/p’
example—–(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
sed ‘s/^192.168.0.1/&localhost/’
example—–&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加
localhost,变成192.168.0.1localhost。 sed -n ‘s/(love)able/1rs/p’
example—–love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。 $ sed
‘s#10#100#g’
example—–不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
sed−n‘/test/,/check/p′example—–所有在模板test和check所确定的范围内的行都被打印。 sed -n '5,/^test/p' example-----打印从第五行开始到第一个包含以test开始的行之间的所有行。 sed‘/test/,/check/s/ /sed test/’
example—–对于模板test和west之间的行,每行的末尾用字符串sed test替换。
多点编辑:e命令
sed−e‘1,5d′−e‘s/test/check/′example—–(−e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。 sed –expression=’s/test/check/’ –expression=’/love/d’
example—–一个比-e更好的命令是–expression。它能给sed表达式赋值。
从文件读入:r命令
sed‘/test/rfile′example—–file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。写入文件:w命令 sed -n ‘/test/w file’
example—–在example中所有包含test的行都被写入file里。 追加命令:a命令 $ sed
‘/^test/a\this is a example’ example—–‘this is a
example’被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。
插入:i命令
sed ‘/test/i\abcde’ example——-abcde被插入到包含test的行的前面。
下一个:n命令
$ sed ‘/test/{ n; s/aa/bb/; }’
example—–如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。
变形:y命令
$ sed ‘1,10y/abcde/ABCDE/’
example—–把1–10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。也就是说,被替换的字符串要与替换的字符串的长度相同。
退出:q命令
$ sed ‘10q’ example—–打印完第10行后,退出sed。
保持和获取:h命令和G命令
sed−e′/test/h′−e′ G‘ example—–
在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空
间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。
第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中
就是追加到最后一行。简单来说,若使用的是H命令,则任何包含test的行都被复制并追加到该文件的末尾,若是h命令,则只有最后一个包含test的行被
复制并追加到该文件的末尾。
保持和互换:h命令和x命令
$ sed -e ‘/test/h’ -e ‘/check/x’ example
—–互换模式空间和保持缓冲区的内容。也就是用前面包含test的行去替换包含check的行,而并不是互换两行
awk:模式匹配编程语言
awk的调用方式:
- awk [options] ‘script’ var=value file(s)
- awk [options] -f scriptfile var=value file(s)
常用命令行选项
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
常用的操作
print & $0
print 是awk打印指定内容的主要命令
awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd
awk '{print " "}' /etc/passwd //不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
awk '{print "a"}' /etc/passwd //输出相同个数的a行,一行只有一个a字母
awk -F":" '{print $1}' /etc/passwd
awk -F: '{print $1; print $2}' /etc/passwd //将每一行的前二个字段,分行输出,进一步理解一行一行处理文本
awk -F: '{print $1,$3,$6}' OFS="\t" /etc/passwd //输出字段1,3,6,以制表符作为分隔符
-f指定脚本文件
awk -f script.awk file
BEGIN{
FS=":"
}
{print $1} //效果与awk -F”:” ‘{print $1}’相同,只是分隔符使用FS在代码自身中指定
awk 'BEGIN{X=0} /^$/{ X+=1 } END{print "I find",X,"blank lines."}' test
I find 4 blank lines.
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is",sum}' //计算文件大小
total size is 17487
-F指定分隔符
$1 指指定分隔符后,第一个字段,$3第三个字段, \t是制表符
一个或多个连续的空格或制表符看做一个定界符,即多个空格看做一个空格
awk -F":" '{print $1}' /etc/passwd
awk -F":" '{print $1 $3}' /etc/passwd //$1与$3相连输出,不分隔
awk -F":" '{print $1,$3}' /etc/passwd //多了一个逗号,$1与$3使用空格分隔
awk -F":" '{print $1 " " $3}' /etc/passwd //$1与$3之间手动添加空格分隔
awk -F":" '{print "Username:" $1 "\t\t Uid:" $3 }' /etc/passwd //自定义输出
awk -F: '{print NF}' /etc/passwd //显示每行有多少字段
awk -F: '{print $NF}' /etc/passwd //将每行第NF个字段的值打印出来
awk -F: 'NF==4 {print }' /etc/passwd //显示只有4个字段的行
awk -F: 'NF>2{print $0}' /etc/passwd //显示每行字段数量大于2的行
awk '{print NR,$0}' /etc/passwd //输出每行的行号
awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd //依次打印行号,字段数,最后字段值,制表符,每行内容
awk -F: 'NR==5{print}' /etc/passwd //显示第5行
awk -F: 'NR==5 || NR==6{print}' /etc/passwd //显示第5行和第6行
route -n|awk 'NR!=1{print}' //不显示第一行
//匹配代码块
//纯字符匹配 !//纯字符不匹配 ~//字段值匹配 !~//字段值不匹配 ~/a1|a2/字段值匹配a1或a2
awk '/mysql/' /etc/passwd
awk '/mysql/{print }' /etc/passwd
awk '/mysql/{print $0}' /etc/passwd //三条指令结果一样
awk '!/mysql/{print $0}' /etc/passwd //输出不匹配mysql的行
awk '/mysql|mail/{print}' /etc/passwd
awk '!/mysql|mail/{print}' /etc/passwd
awk -F: '/mail/,/mysql/{print}' /etc/passwd //区间匹配
awk '/[2][7][7]*/{print $0}' /etc/passwd //匹配包含27为数字开头的行,如27,277,2777...
awk -F: '$1~/mail/{print $1}' /etc/passwd //$1匹配指定内容才显示
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //与上面相同
awk -F: '$1!~/mail/{print $1}' /etc/passwd //不匹配
awk -F: '$1!~/mail|mysql/{print $1}' /etc/passwd
IF语句
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //简写
awk -F: '{if($1~/mail/) {print $1}}' /etc/passwd //全写
awk -F: '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd //if...else...条件表达式
== != > >=
awk -F":" '$1=="mysql"{print $3}' /etc/passwd
awk -F":" '{if($1=="mysql") print $3}' /etc/passwd //与上面相同
awk -F":" '$1!="mysql"{print $3}' /etc/passwd //不等于
awk -F":" '$3>1000{print $3}' /etc/passwd //大于
awk -F":" '$3>=100{print $3}' /etc/passwd //大于等于
awk -F":" '$3<1{print $3}' /etc/passwd //小于
awk -F":" '$3<=1{print $3}' /etc/passwd //小于等于逻辑运算符
&& ||
awk -F: '$1~/mail/ && $3>8 {print }' /etc/passwd //逻辑与,$1匹配mail,并且$3>8
awk -F: '{if($1~/mail/ && $3>8) print }' /etc/passwd
awk -F: '$1~/mail/ || $3>1000 {print }' /etc/passwd //逻辑或
awk -F: '{if($1~/mail/ || $3>1000) print }' /etc/passwd 数值运算
awk -F: '$3 > 100' /etc/passwd
awk -F: '$3 > 100 || $3 < 5' /etc/passwd
awk -F: '$3+$4 > 200' /etc/passwd
awk -F: '/mysql|mail/{print $3+10}' /etc/passwd //第三个字段加10打印
awk -F: '/mysql/{print $3-$4}' /etc/passwd //减法
awk -F: '/mysql/{print $3*$4}' /etc/passwd //求乘积
awk '/MemFree/{print $2/1024}' /proc/meminfo //除法
awk '/MemFree/{print int($2/1024)}' /proc/meminfo //取整输出分隔符OFS
awk '$6 ~ /FIN/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
awk '$6 ~ /WAIT/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
//输出字段6匹配WAIT的行,其中输出每行行号,字段4,5,6,并使用制表符分割字段输出处理结果到文件
①在命令代码块中直接输出 route -n|awk 'NR!=1{print > "./fs"}'
②使用重定向进行输出 route -n|awk 'NR!=1{print}' > ./fs格式化输出
netstat -anp|awk '{printf "%-8s %-8s %-10s\n",$1,$2,$3}'
printf表示格式输出
%格式化输出分隔符
-8长度为8个字符
s表示字符串类型
打印每行前三个字段,指定第一个字段输出字符串类型(长度为8),第二个字段输出字符串类型(长度为8),
第三个字段输出字符串类型(长度为10)
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-10s %-10s %-10s \n",$1,$2,$3}'
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-3s %-10s %-10s %-10s \n",NR,$1,$2,$3}'IF语句
awk -F: '{if($3>100) print "large"; else print "small"}' /etc/passwd
small
small
small
large
small
small
awk -F: 'BEGIN{A=0;B=0} {if($3>100) {A++; print "large"} else {B++; print "small"}} END{print A,"\t",B}' /etc/passwd
//ID大于100,A加1,否则B加1
awk -F: '{if($3<100) next; else print}' /etc/passwd //小于100跳过,否则显示
awk -F: 'BEGIN{i=1} {if(i<NF) print NR,NF,i++ }' /etc/passwd
awk -F: 'BEGIN{i=1} {if(i<NF) {print NR,NF} i++ }' /etc/passwd
另一种形式
awk -F: '{print ($3>100 ? "yes":"no")}' /etc/passwd
awk -F: '{print ($3>100 ? $3":\tyes":$3":\tno")}' /etc/passwdwhile语句
awk -F: 'BEGIN{i=1} {while(i<NF) print NF,$i,i++}' /etc/passwd
7 root 1
7 x 2
7 0 3
7 0 4
7 root 5
7 /root 6数组
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) print i,"\t",a[i]}'
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) printf "%-20s %-10s %-5s \n", i,"\t",a[i]}'
9523 1
9929 1
LISTEN 6
7903 1
3038/cupsd 1
7913 1
10837 1
9833 1 应用1
awk -F: '{print NF}' helloworld.sh //输出文件每行有多少字段
awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh //输出前5个字段
awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //输出前5个字段并使用制表符分隔输出
awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //制表符分隔输出前5个字段,并打印行号应用2
awk -F'[:#]' '{print NF}' helloworld.sh //指定多个分隔符: #,输出每行多少字段
awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh //制表符分隔输出多字段应用3
awk -F'[:#/]' '{print NF}' helloworld.sh //指定三个分隔符,并输出每行字段数
awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh //制表符分隔输出多字段应用4
计算/home目录下,普通文件的大小,使用KB作为单位
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}'
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' //int是取整的意思应用5
统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少
netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'应用6
统计/home目录下不同用户的普通文件的总数是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
mysql 199
root 374
统计/home目录下不同用户的普通文件的大小总size是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'grep:文本搜集工具
对文件进行模式匹配查找。在进行模式匹配的时候使用单引号, 在使用变量或着字符串的时候使用双引号。
grep的三种变形:
- 正常型:grep
- 扩展型:egrep
- 快速型:fgrep 速度没有提升,而是允许查找一个字符串而不是一个模式
grep的匹配选项:
(可以复合使用哦)
1. -c 只输出匹配行的计数
2. -i 在匹配字符串的时候不区分大小写
3. -h 查询匹配多个文件的时候不显示文件名
4. -l 查询匹配多个文件的时候只输出包含匹配字符串的文件名
5. -n 显示匹配行以及行号
6. -s 不显示不存在或无匹配文本的错误信息
7. -v 显示不包含匹配文本的所有行
grep常用的正则匹配:
grep ‘48[34]’ file1 ##匹配文件file1里面包含48且下一个字母是3或着4结尾的
grep ‘^[^48]’ file1 ##匹配行首不是48的记录
grep ‘k…D’ file1 ##匹配L开头D结尾的代码, 且长度为5
grep ‘5{2, 6}3’ ##匹配5出现2-6次,并以3结尾
grep ‘^$’ ##匹配空行
匹配模式的类名模式:

egrep:
跟grep一样接受所有的正则表达式匹配, 一个特点是:它接受一个文件作为保存的字符串。
例如:
egrep file1 file2 ##表示输出file2中的匹配file1中记录的所有的记录。
当然我们也可以将文件file1中的记录使用`|` 隔开的方式:
egrep 'pattern1|pattern2' file2
或:
grep -E 'pattern1|pattern2' file2all