我用的是django4.2.14,前后端分离的项目前端用的是vue,先来看一下最终实现后的效果。
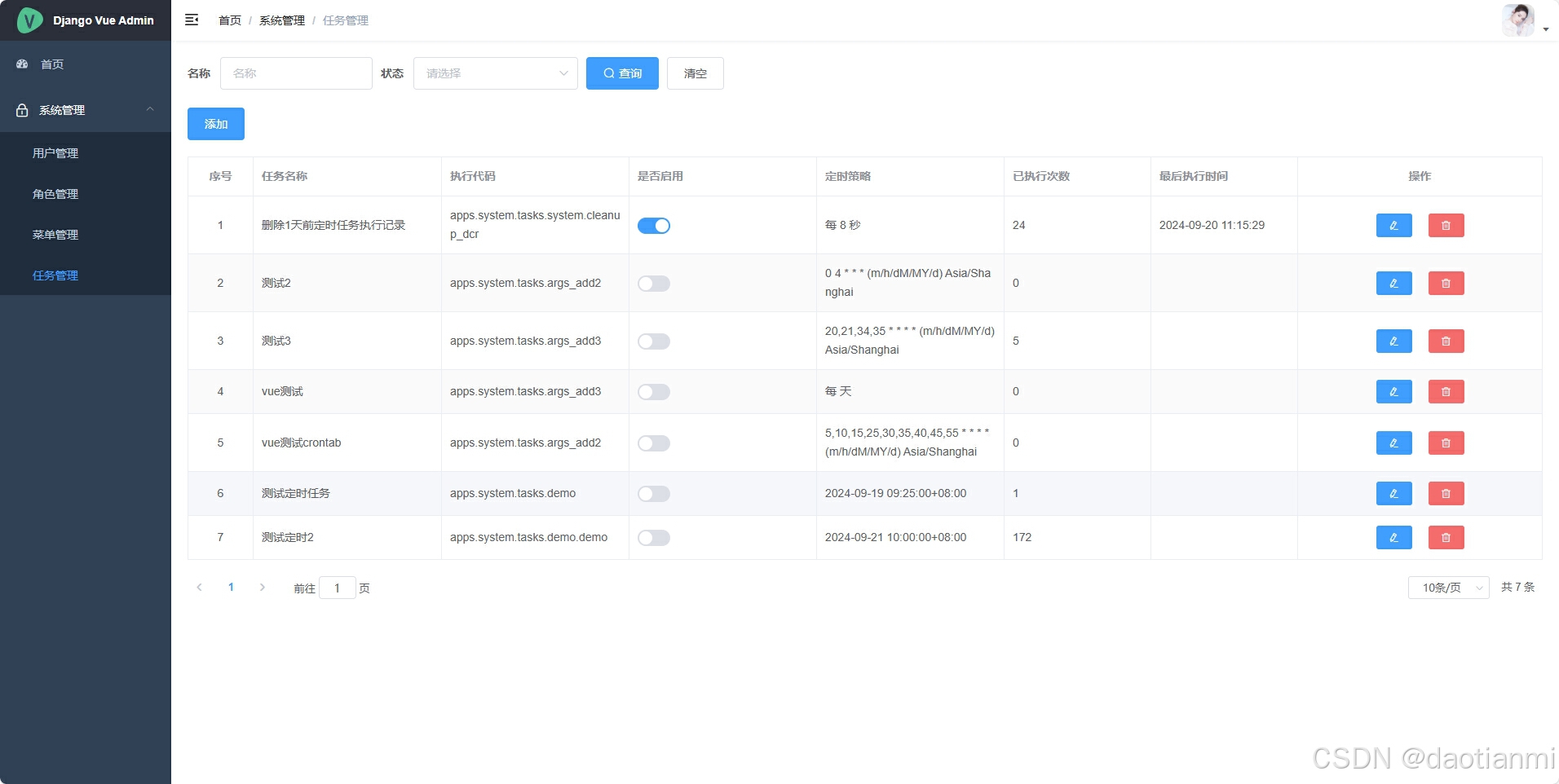
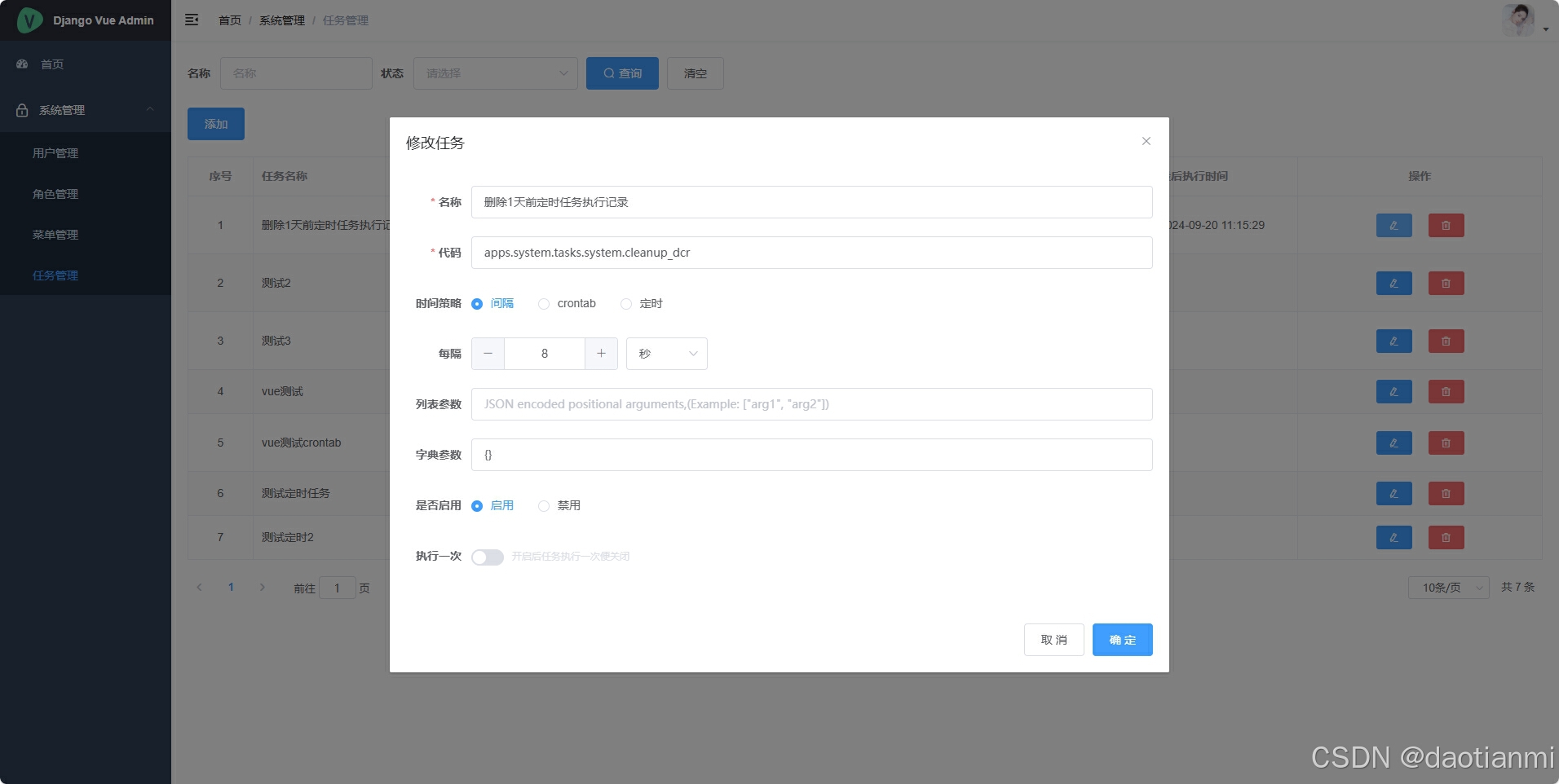
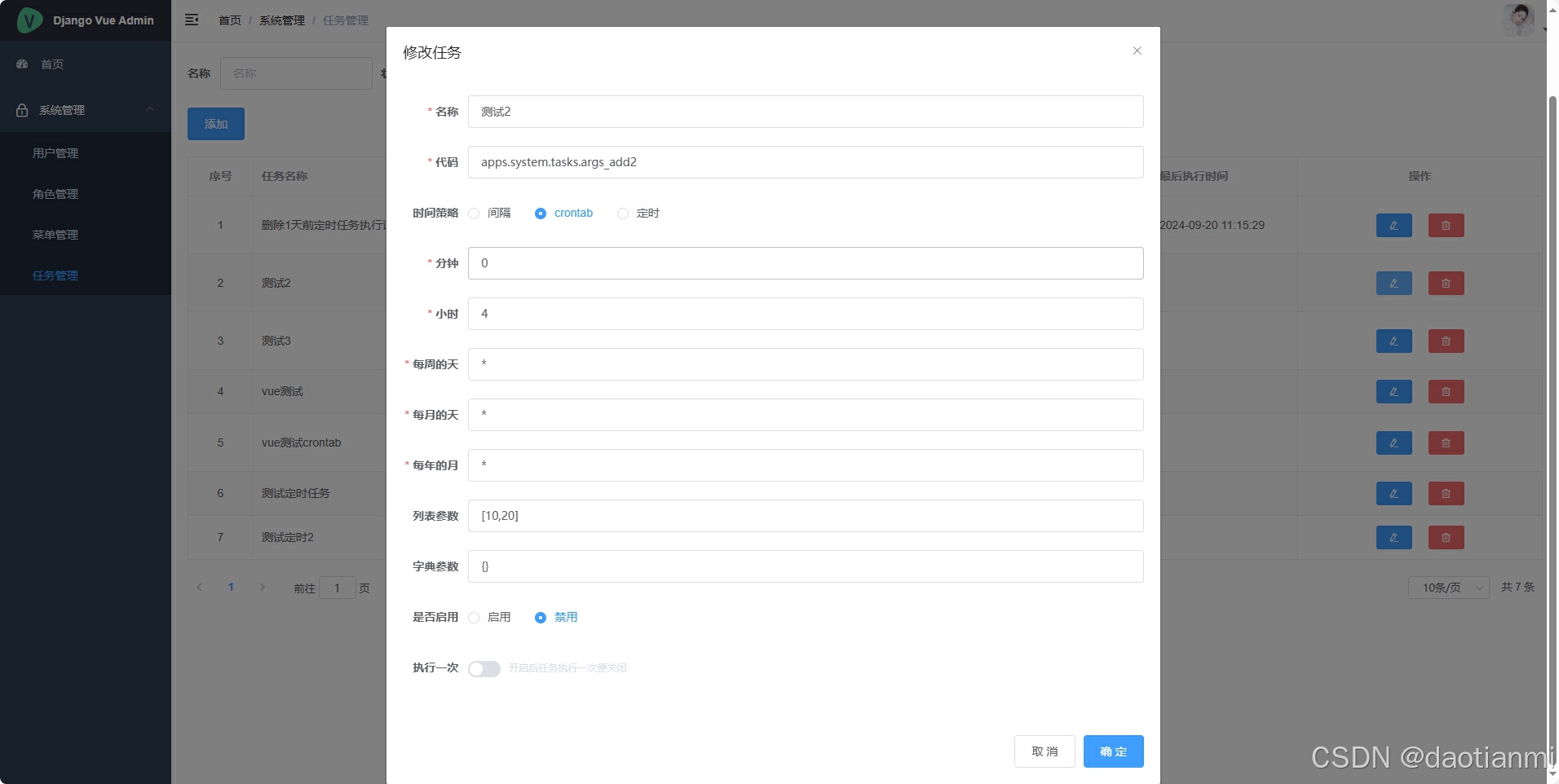
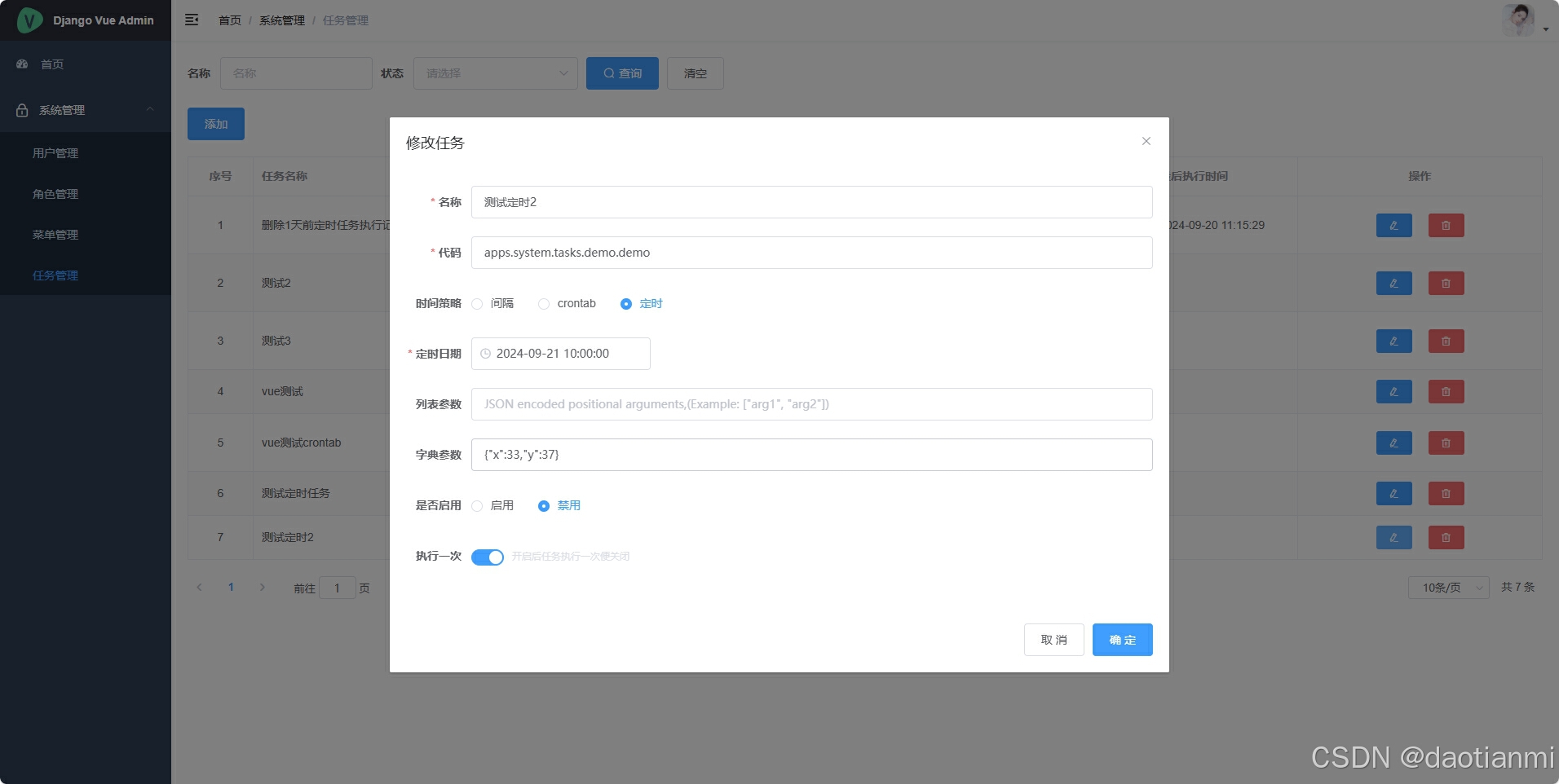
测试之后符合自己的预期,今天就写一下教程,做个记录。
一、安装对应的模块
celery==5.4.0
django-celery-beat==2.7.0
django-celery-results==2.5.1
eventlet==0.36.1(celery 4以后版本window下必须安装这个,其他系统不用)
命令是 pip install 模块名称
二、修改配置文件
1、设置settings.py
找到django项目对应的settings.py
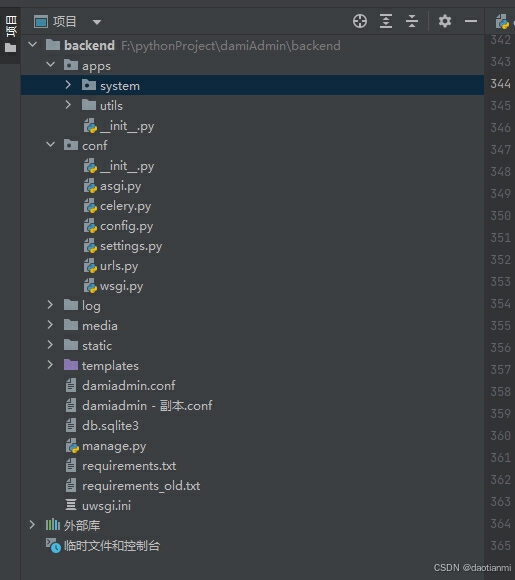
我的目录结构如下可以看到conf下的settings.py
在settings.py的最后添加如下代码
# celery app的名称
CELERY_APP_NAME = 'dami_admin'
# celery配置,celery正常运行必须安装redis
# 设置队列名称
# CELERY_TASK_DEFAULT_QUEUE = CELERY_APP_NAME
CELERY_BROKER_URL = "redis://127.0.0.1:6379/1" # 任务存储
CELERYD_MAX_TASKS_PER_CHILD = 100 # 每个worker最多执行300个任务就会被销毁,可防止内存泄露
CELERY_TIMEZONE = TIME_ZONE # 设置时区
CELERY_ENABLE_UTC = True # 启动时区设置
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
CELERY_RESULT_BACKEND = 'django-db'
# 序列化配置 并把任务的数据存入数据库
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
# 开启后会把扩展的一些字段添加进去
CELERY_RESULT_EXTENDED = True
CELERY_TASK_TRACK_STARTED = True这些代码是配置celery用的如有不懂得话请百度或去官方文档查看,我加了CELERY_前缀查询时请去掉CELERY_前缀,例如:BROKER_URL
并在INSTALLED_APPS 添加django_celery_beat和django_celery_results
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'django_filters', # 注册django-filters过滤器插件
'corsheaders', # 支持跨域
'rest_framework_simplejwt', # jwt token认证插件
'django_celery_beat',
'django_celery_results',
'apps.system',
然后在命令行依次执行python manage.py makemigrations 和 python manage.py migrate
打开数据库则会发现创建了一些表,红色的则是django-celery-beat创建的蓝色则是django-celery-result创建的。

2、配置celery
在settings.py同级目录下创建celery.py文件并添加如下代码(我的目录是第一步截图中conf)
import os
from . import settings
from celery import Celery
from celery.app.control import Control, Inspect
# 加载配置
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'conf.settings')
# 实例化
app = Celery(settings.CELERY_APP_NAME)
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
# namespace='CELERY'得作用是允许你在Django配置文件中对CELERY前缀的配置
# 如果没有前缀则省略,一般情况下Celery配置项必须以CELERY开头,防止冲突
app.config_from_object('django.conf:settings', namespace='CELERY')
# 自动发现项目中的tasks
app.autodiscover_tasks()
# celery_control: Control = Control(app=app)
#
# celery_inspect: Inspect = celery_control.inspect()
@app.task(bind=True)
def debug_task(self):
print(f'Request: {self.request!r}')
3、添加对Celery对象的引用并确保Django启动后能够初始化
找到settings.py同级目录下的__init__.py添加如下代码(我的目录是第一步截图中conf)
from .celery import app as celery_app
__all__ = ['celery_app']三、在应用中创建异步任务
1、创建对应的函数文件
我的应用目录是apps下system,所以要在system下创建tasks.py文件,代码如下
import random
from celery import shared_task
from apps.system.models import User
@shared_task
def demo2(x, y):
user = User.objects.filter(username='admin').update(first_name='admin' + str(random.randint(0, 9)))
print("start demo now!")
print("demo no.1 end!")
return x+y
2、创建触发对应的views函数
找到system目录下的views.py文件添加如下代码(我的项目把views做成了目录方便多人协同开发,我项目的路径是system/views/demo.py)
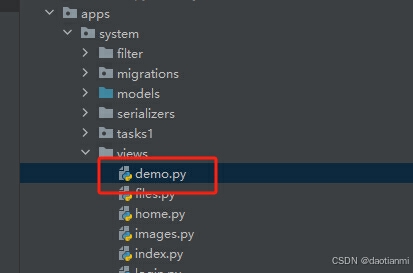
添加如下代码
from django.http import JsonResponse
from apps.system import tasks
from celery.result import AsyncResult
def celery(request):
res = tasks.demo2.delay(123, 456) #发送任务给celery
result = AsyncResult(res.task_id) #获取任务id
return JsonResponse({'status': result.status, 'task_id': result.task_id})3、添加链接
找到应用下的urls.py
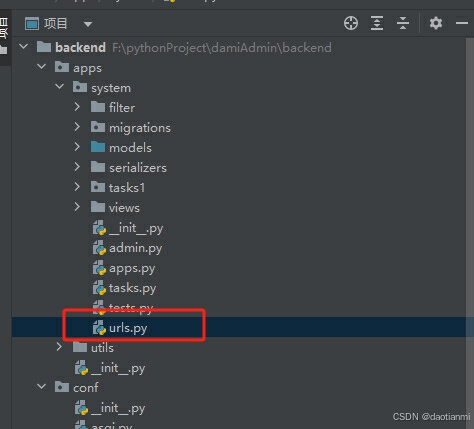
添加以下代码
from django.urls import path
from rest_framework import routers
from apps.system.views import demo
urlpatterns = [
path('celery/', demo.celery),
]4、启动Celery
在根目录下执行
celery -A conf worker -l info -P eventlet

启动成功
5、测试异步任务
打开postman这类的软件测试一下
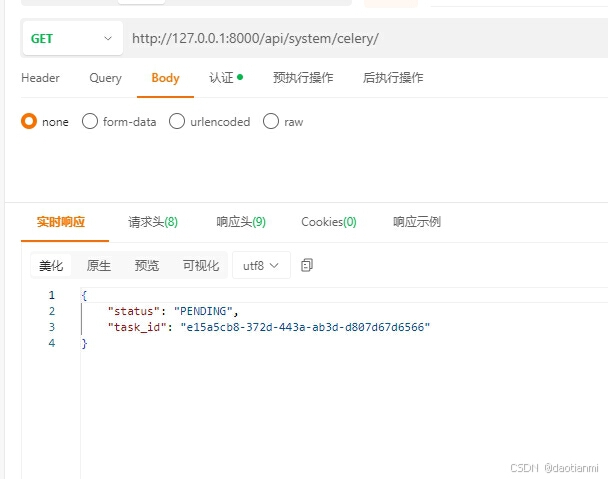
发现返回了task_id这个"e15a5cb8-372d-443a-ab3d-d807d67d6566"就是这次执行任务的id
去命令行查看一下信息

去user表查看一下demo2函数中如下代码执行情况
user = User.objects.filter(username='admin').update(first_name='admin' + str(random.randint(0, 9)))
ok结果成功,其实修改user这个表的代码不用添加,我这个画蛇添足的代码也算是是给大家多一个参考。
四、创建对应的自定义任务
1、序列化文件
1、创建文件
2、添加序列化对象
from rest_framework import serializers
from django_celery_beat.models import PeriodicTask, CrontabSchedule, IntervalSchedule, ClockedSchedule
class IntervalSerializer(serializers.ModelSerializer):
class Meta:
model = IntervalSchedule
fields = '__all__'
class CrontabSerializer(serializers.ModelSerializer):
class Meta:
model = CrontabSchedule
exclude = ['timezone']
class ClockedSerializer(serializers.ModelSerializer):
class Meta:
model = ClockedSchedule
fields = '__all__'
class TaskSerializer(serializers.ModelSerializer):
schedule = serializers.SerializerMethodField()
time_type = serializers.SerializerMethodField()
class Meta:
model = PeriodicTask
fields = '__all__'
def get_schedule(self, obj):
if obj.interval:
return obj.interval.__str__()
elif obj.crontab:
return obj.crontab.__str__()
elif obj.clocked:
return obj.clocked.__str__()
return ''
def get_time_type(self, obj):
if obj.interval:
return 'interval'
elif obj.crontab:
return 'crontab'
elif obj.clocked:
return 'clocked'
return 'interval'
2、创建自定义的views
添加如下代码
from django_celery_beat.models import PeriodicTask, IntervalSchedule, CrontabSchedule, ClockedSchedule
from rest_framework import status
from rest_framework.permissions import IsAuthenticated
from rest_framework.views import APIView
from rest_framework.viewsets import ModelViewSet
from apps.system.serializers.schedules import TaskSerializer, IntervalSerializer, CrontabSerializer, ClockedSerializer
from conf.celery import app as celery_app
from rest_framework.response import Response
# from apps.system.filter.schedules import SchedulesFilter
from rest_framework.exceptions import ParseError
class TaskList(APIView):
permission_classes = [IsAuthenticated]
def get(self, request):
"""
获取注册任务列表
"""
tasks = list(
sorted(name for name in celery_app.tasks if not name.startswith('celery.')))
return Response(tasks)
class TaskView(ModelViewSet):
queryset = PeriodicTask.objects.exclude(name__contains='celery.')
serializer_class = TaskSerializer
# 自定义搜索
# filterset_class = SchedulesFilter
def interval_save(self, data):
"""
保存间隔数据,移除id方便插入新的数据
规则如果有则采用之前的规则
没有则新建
此设计时为了保证数据更换规则之后不影响其他的数据
"""
try:
if 'id' in data:
data.pop('id')
is_interval = IntervalSchedule.objects.filter(**data).exists()
if is_interval:
interval = IntervalSchedule.objects.get(**data)
else:
interval, _ = IntervalSchedule.objects.get_or_create(**data, defaults=data)
return interval
except Exception as e:
raise ParseError({'msg': '时间策略数据错误!'})
def crontab_save(self, data):
try:
if 'id' in data:
data.pop('id')
is_crontab = CrontabSchedule.objects.filter(**data).exists()
if is_crontab:
crontab = CrontabSchedule.objects.get(**data)
else:
crontab, _ = CrontabSchedule.objects.get_or_create(**data, defaults=data)
return crontab
except Exception as e:
print(e)
raise ParseError({'msg': '时间策略数据错误!'})
def clocked_save(self, data):
try:
if 'id' in data:
data.pop('id')
is_clocked = ClockedSchedule.objects.filter(**data).exists()
if is_clocked:
clocked = ClockedSchedule.objects.get(**data)
else:
clocked, _ = ClockedSchedule.objects.get_or_create(**data, defaults=data)
return clocked
except Exception as e:
raise ParseError({'msg': '时间策略数据错误!'})
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
data = serializer.data
if data['time_type'] == 'interval':
data['interval_info'] = IntervalSerializer(
IntervalSchedule.objects.filter(id=data['interval']).first()).data
else:
data['interval_info'] = {'every': 1, 'period': 'days'}
if data['time_type'] == 'crontab':
data['crontab_info'] = CrontabSerializer(CrontabSchedule.objects.filter(id=data['crontab']).first()).data
else:
data['crontab_info'] = {}
if data['time_type'] == 'clocked':
data['clocked_info'] = ClockedSerializer(ClockedSchedule.objects.filter(id=data['clocked']).first()).data
else:
data['clocked_info'] = {}
return Response(data)
def create(self, request, *args, **kwargs):
data = request.data
# return Response({'msg': '数据格式有误!'}, status=status.HTTP_400_BAD_REQUEST)
# interval_info = data.get('interval_info', {})
# crontab_info = data.get('crontab_info', {})
print(data)
if 'name' not in data:
return Response({'msg': '请输入用户名称!'}, status=status.HTTP_400_BAD_REQUEST)
elif 'task' not in data:
return Response({'msg': '请输入任务名称!'}, status=status.HTTP_400_BAD_REQUEST)
elif 'time_type' not in data or 'interval_info' not in data or 'crontab_info' not in data:
return Response({'msg': '数据不正确!'}, status=status.HTTP_400_BAD_REQUEST)
elif 'clocked_info' not in data:
return Response({'msg': '数据不正确!'}, status=status.HTTP_400_BAD_REQUEST)
if data['time_type'] == 'interval' and data['interval_info']:
interval = self.interval_save(data['interval_info'])
data['interval'] = interval.id
if data['time_type'] == 'crontab' and data['crontab_info']:
crontab = self.crontab_save(data['crontab_info'])
data['crontab'] = crontab.id
if data['time_type'] == 'clocked' and data['clocked_info']:
clocked = self.clocked_save(data['clocked_info'])
data['clocked'] = clocked.id
serializer = self.get_serializer(data=data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response({'msg': '成功!'}, status=status.HTTP_201_CREATED)
def update(self, request, *args, **kwargs):
data = request.data
time_type = request.data.get('time_type')
interval_info = request.data.get('interval_info')
crontab_info = request.data.get('crontab_info')
clocked_info = request.data.get('clocked_info')
# 修改状态的判断,大于2是非状态修改
if len(data) > 2:
if time_type == 'interval' and interval_info:
interval = self.interval_save(interval_info)
data['interval'] = interval.id
data['interval_info'] = IntervalSerializer(interval).data
else:
data['interval'] = None
data['interval_info'] = {'every': 1, 'period': 'days'}
if time_type == 'crontab' and crontab_info:
crontab = self.crontab_save(crontab_info)
data['crontab'] = crontab.id
else:
data['crontab'] = None
if time_type == 'clocked' and clocked_info:
clocked = self.clocked_save(clocked_info)
data['clocked'] = clocked.id
else:
data['clocked'] = None
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(data)
3、添加urls
from django.urls import path
from rest_framework import routers
from apps.system.views import demo, schedules
# 引入schedules
urlpatterns = [
path('celery/', demo.celery),
]
# 添加web url
route = routers.SimpleRouter()
route.register('tasks', schedules.TaskView)
urlpatterns += route.urls4、添加数据
json 格式的数据
{
"time_type": "interval",
"enabled": true,
"interval_info": {
"every": 5,
"period": "seconds"
},
"crontab_info": {},
"clocked_info": {},
"one_off": false,
"name": "教程示例1",
"task": "apps.system.tasks.demo2",
"args": "[20,30]"
}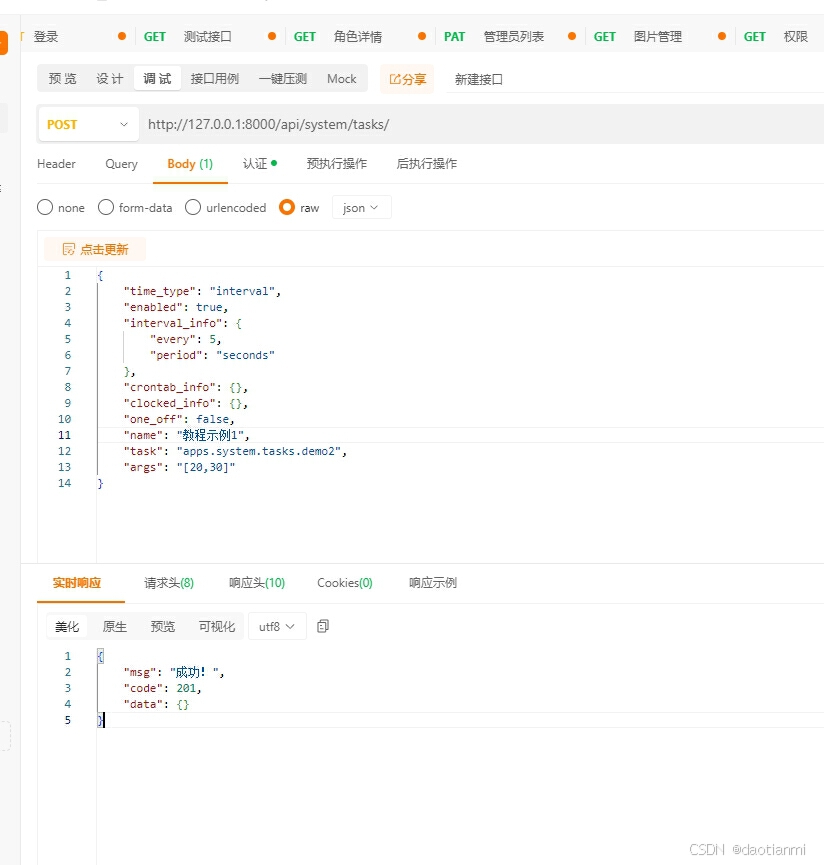
添加成功
interval_info数据类型格式
periodOptions: [
{
value: "days",
label: "天",
},
{
value: "hours",
label: "小时",
},
{
value: "minutes",
label: "分钟",
},
{
value: "seconds",
label: "秒",
},
],
crontab_info的json格式
crontab_info:{
minute:"",
hour:"",
day_of_week:"",
day_of_month:"",
month_of_year:"",
}
// minute表示分钟,hour表示小时,day_of_week表示每周的天,day_of_month表示每月的天,
// month_of_year表示每年的月
// 多参数用,号隔,全部用*表示 例如:
crontab_info:{
minute:"5,15",
hour:"*",
day_of_week:"*",
day_of_month:"*",
month_of_year:"*",
}
// 表示每小时的第5分钟和15分钟执行任务
clocked_info的json格式
clocked_info:{
clocked_time:"2024-09-21 00:00:00"
}五、测试
1、启动工作者worker
celery -A conf worker -l info -P eventlet
2、再打开一个命令行启动生产者beat
celery -A conf beat -l info 3、beat命令行结果
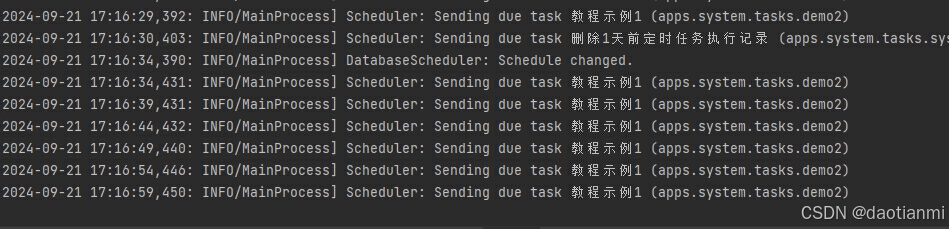
4、工作者worker命令行结果

完美通过。
六、tasks文件优化
如果多人协同开发怎么办?都用一个tasks很容易代码冲突,有的人说一个人负责一个应用这没问题,每个应用下都有自己的tasks互不影响,但是几个人同时开发一个模块呢?如果你也有同样的疑问的话可以跟着如下操作。
1、删除或者更改之前的tasks.py文件名称并创建tasks文件夹
2、创建对应的任务文件
demo.py代码如下
import random
from celery import shared_task
@shared_task
def demo(x, y):
print("start tasks.demo now!")
print("tasks.demo no.1 end!")
return x+y
3、tasks文件夹下创建__init__.py并添加内容
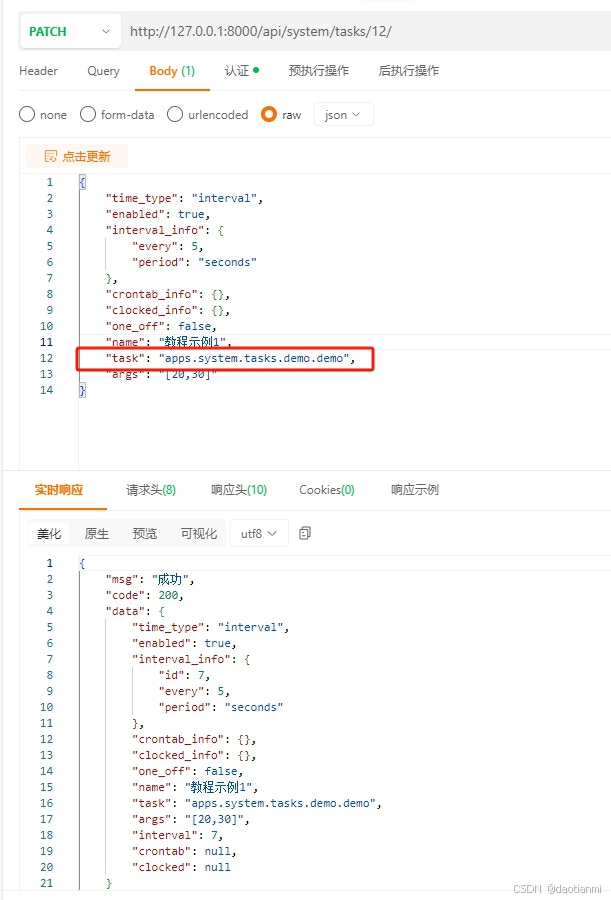
from .demo import *4、修改之前添加的内容只是修改了task
{
"time_type": "interval",
"enabled": true,
"interval_info": {
"every": 5,
"period": "seconds"
},
"crontab_info": {},
"clocked_info": {},
"one_off": false,
"name": "教程示例1",
"task": "apps.system.tasks.demo.demo",
"args": "[20,30]"
}
url地址哪儿不要忘记填写任务的id,从django_celery_beat_periodictask数据表查看id
5、重复第五步测试
beat结果
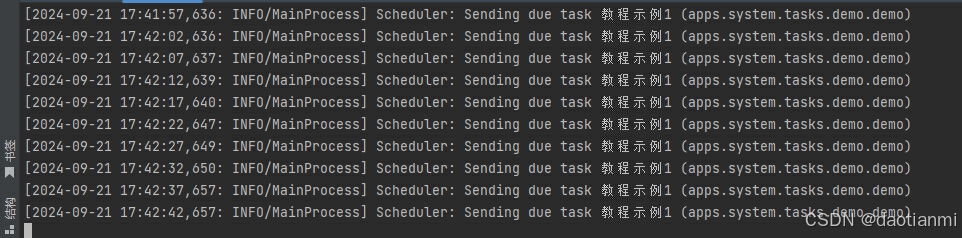
worker结果

可以发现完美运行。
七、django-celery-beat 对应表说明
django_celery_beat_periodictask 是任务表,所有创建的任务都会在此表中记录,只要在此表中记录才会执行。(enabled字段必须是1)
django_celery_beat_clockedschedule 是定时规则的表,表示在指定的那天运行,并且用此规则的话只能执行一次。也就是说django_celery_beat_periodictask表中的one_off的值必须是1
django_celery_beat_crontabschedule 是指定某个时间执行定时任务的规则表 (例:每年的12月星期三的2:30)
django_celery_beat_intervalschedule 指按时间间隔频率执行定时任务的规则表(例:每隔5小时执行一次)
django_celery_beat_periodictasks 是索引和跟踪任务更改状态的表(基本用不到)
django_celery_beat_solarschedule 是根据天文时间的任务表,经纬度表示的(黄昏,正午,日出,日落等)
八、django-celery-result对应表说明
django_celery_results_taskresult 是存储Celery任务执行结果的表,扩展的一些字段例如task_name、periodic_task_name等需要设置才行,例如我的项目中setting.py中CELERY_RESULT_EXTENDED = True就是开启的状态。
django_celery_results_chordcounter 是存储Celery的chord任务的状态一般用不到
django_celery_results_groupresult 是存储Celery的group任务的结果一般也是用不到
如果看到此,你对django-celery-beat还有有些不了解,我建议可以通过django自带的admin后台了解一下。自己多填写测试测试,不要怕写错就怕你不写。
写在最后:项目源代码 在最后,时间苦短,我用python。在现在经济特殊的环境里,愿天下程序员心想事成,万事如意,一切都顺顺顺!!!顺便也对自己说一句:加油!!!文章中如有不足之处还希望提出指正,特此谢谢各位!