环境准备
- 安装 JAVA 1.8
Java环境搭建之JDK下载及安装 - 下载 Hadoop 3.3.5 安装包
Hadoop 下载:https://archive.apache.org/dist/hadoop/common/
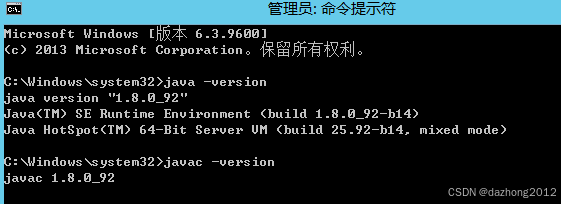
一、JAVA JDK 环境检查
二、Hadoop(HDFS)环境搭建
1. 解压安装文件 hadoop-3.3.5.tar
2. 配置环境变量
HADOOP_HOME:D:\Development\Hadoop
HADOOP_USER_NAME:root
Path:%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
3.配置Hadoop
检查 hadoop-3.3.5\etc\hadoop\hadoop-env.cmd 文件JDK的配置,通常无需改动
set JAVA_HOME=%JAVA_HOME%
如果报错的话配置为 JAVA 安装路径
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_92
windowsd的cmd不允许设置变量路径带有空格,所以Java的安装目录需要不带空格
修改 hadoop/etc/hadoop/core-site.xml
<configuration>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定 hadoop 存储临时文件的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>D:\Development\Hadoop\data\tmp</value>
</property>
</configuration>
修改 hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>D:\Development\Hadoop\data\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>D:\Development\Hadoop\data\datanode</value>
</property>
<!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
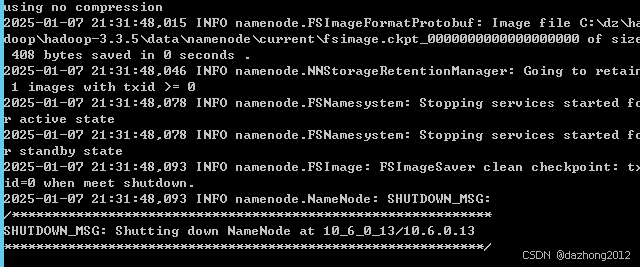
4. 格式化NameNode :
第一次启动 Hadoop 时需要进行初始化,进入 ${HADOOP_HOME}/bin/ 目录下,执行以下命令:
进入 hadoop-3.3.5\bin 目录,执行 以下命令
hdfs namenode -format
5. 启动 HDFS
- 进入 hadoop/sbin 目录,执行以下命令:
hadoop/sbin/start-dfs.cmd
hadoop/sbin/start-yarn.cmd
- 验证是否启动成功
方式一:执行jps查看 NameNode 和 DataNode 服务是否已经启动:
[../sbin]# jps
5988 Jps
1964 DataNode
4572 NameNode
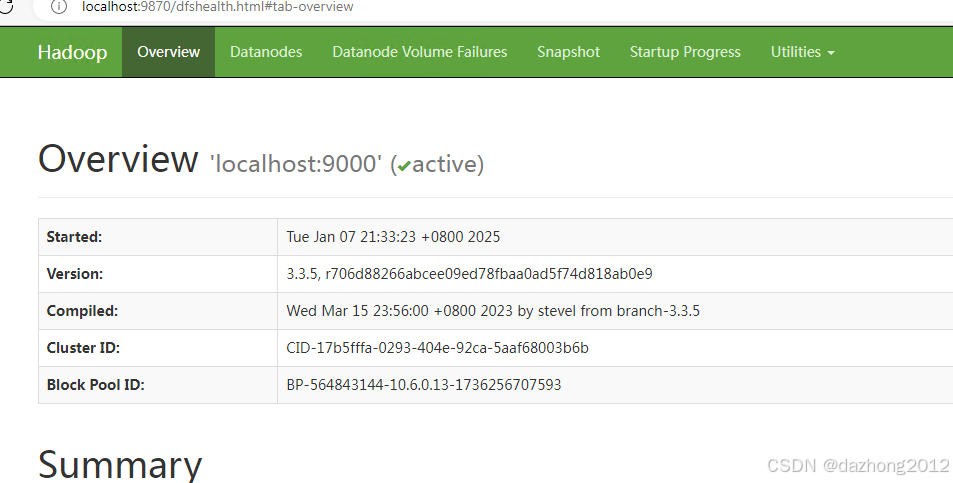
- 查看集群状态
http://localhost:9870/
三、Hadoop(YARN)环境搭建
1. 修改配置
进入 ${HADOOP_HOME}/etc/hadoop/ 目录下,修改以下配置:
- 修改 hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改 hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在 Yarn 上运行 MapReduce 程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
5. 启动服务
- 进入 hadoop/sbin 目录,执行以下命令:
hadoop/sbin/start-yarn.cmd
6. 验证是否启动成功
- 方式一:执行
jps查看ResourceManager和NodeManager服务是否已经启动:
4112 Jps
2100 ResourceManager
1964 DataNode
4572 NameNode
4668 NodeManager
- 方式二:查看 Web UI 界面,端口号为 8088,访问页面:
http://localhost:8088/
参考:
- Windows安装Hadoop3.x
https://blog.csdn.net/qq_38628046/article/details/124217768 - Windows环境下执行hadoop命令出现Error: JAVA_HOME is incorrectly set 解决办法
https://www.cnblogs.com/zlslch/p/8580446.html