
特别声明:本文是作者在充分知晓著作权细则的情况下,经过个人付出或者翻译他人著作内容,并已注明翻译原文来源的情况下授权给《深度强化学习实验室》CSDN博客发布,内容仅供深度强化学习领域的爱好者分享与交流使用,无任何商业行为,出处解释权归深度强化学习实验室,内容版权和解释权归作者所有,如有任何侵犯他人利益,请联系我们立即删除。
利用神经网络近似值函数的方法表示为:
V
^
(
s
,
w
)
≈
V
π
(
s
)
q
^
(
s
,
a
,
w
)
≈
q
π
(
s
,
a
)
\hat{V}(s, w) \approx V_{\pi}(s) \\ \hat{q}(s, a, w) \approx q_{\pi}(s, a)
V^(s,w)≈Vπ(s)q^(s,a,w)≈qπ(s,a)
那么具体的工作过程是怎样实现的? 以及如何从端到端的过程,本文将讲解Deep Q Network(DQN, 而这正是由DeepMind于2013年和2015年分别提出的两篇论文《Playing Atari with Deep Reinforcement Learning》《Human-level Control through Deep Reinforcement Learning:Nature杂志》
其中DeepMind在第一篇中第一次提出Deep Reinforcement Learning(DRL)这个名称,并且提出DQN算法,实现从视频纯图像输入,完全通过Agent学习来玩Atari游戏的成果。之后DeepMind在Nature上发表了改进版的DQN文章(Human-level …), 这将深度学习与RL结合起来实现从Perception感知到Action动作的端到端的一种全新的学习算法。简单理解就是和人类一样,输入感知信息比如眼睛看到的东西,然后通过大脑(深度神经网络),直接做出对应的行为(输出动作)的学习过程。而后DeepMind提出了AlphaZero(完美的运用了DRL+Monte Calo Tree Search)取得了超过人类的水平!下文将详细介绍DQN:
一、DQN算法
DQN算法是一种将Q_learning通过神经网络近似值函数的一种方法,在Atari 2600 游戏中取得了超越人类水平玩家的成绩,下文通过将逐步深入讲解:
1.1、 Q_Learning算法
Q _ L e a r n i n g Q\_Learning Q_Learning 是Watkins于1989年提出的一种无模型的强化学习技术。它能够比较可用操作的预期效用(对于给定状态),而不需要环境模型。同时它可以处理随机过渡和奖励问题,而无需进行调整。目前已经被证明,对于任何有限的MDP,Q学习最终会找到一个最优策略,即从当前状态开始,所有连续步骤的总回报回报的期望值是最大值可以实现的。 学习开始之前,Q被初始化为一个可能的任意固定值(由程序员选择)。然后在每个时间t, Agent选择一个动作 a t a_{t} at,得到一个奖励 R t R_t Rt,进入一个新的状态 S t + 1 S_{t+1} St+1和Q值更新。其核心是值函数迭代过程,即:
Q ( s t , a t ) ← Q ( s t , a t ) + α ⋅ [ r t + γ max π Q ( s t + 1 , a t ) − Q ( s t , a t ) ] Q(s_{t},a_{t}) \leftarrow Q(s_{t},a_{t})+\alpha \cdot[r_{t}+\gamma \max\limits_{\pi}Q(s_{t+1},a_{t})-Q(s_{t},a_{t})] Q(st,at)←Q(st,at)+α⋅[rt+γπmaxQ(st+1,at)−Q(st,at)]
其中 α \alpha α是学习率, γ \gamma γ为折扣因子,具体的实现过程见下图伪代码:

首先初始化值函数矩阵,开始episode,然后选择一个状态state,同时智能体根据自身贪婪策略,选择action, 经过智能体将动作运用后得到一个奖励 R R R和 S ′ S^{'} S′,计算值函数,继续迭代下一个流程。
1.1.1、 Q _ L e a r n i n g Q\_Learning Q_Learning执行过程中有两个特点:异策略和时间差分
- 异策略:就是指行动策略和评估策略不是同一个策略,行动策略采用了贪心的 ϵ \epsilon ϵ- g r e e d y greedy greedy策略(第5行),而评估策略采用了 max π Q ( s , a ) \max\limits_{\pi}Q(s, a) πmaxQ(s,a)贪心策略(第7行)!
- 时间差分:从值函数迭代公式(2)可以看出时间差分, 其中 T D − t a r g e t = r t + max π ( s t + 1 , a t ) TD-target = r_{t}+\max\limits_{\pi}(s_{t+1}, a_{t}) TD−target=rt+πmax(st+1,at)
为了在学习过程中得到最优策略Policy,通常估算每一个状态下每一种选择的价值Value有多大。且每一个时间片的
Q
(
s
t
,
a
t
)
Q(s_{t},a_{t})
Q(st,at)和当前得到的Reward以及下一个时间片的
Q
(
s
t
+
1
,
a
t
+
1
)
Q(s_{t+1},a_{t+1})
Q(st+1,at+1)有关。
Q
_
L
e
a
r
n
i
n
g
Q\_Learning
Q_Learning通过不断的学习,最终形成一张矩阵来存储状态(state)和动作(action),表示为:
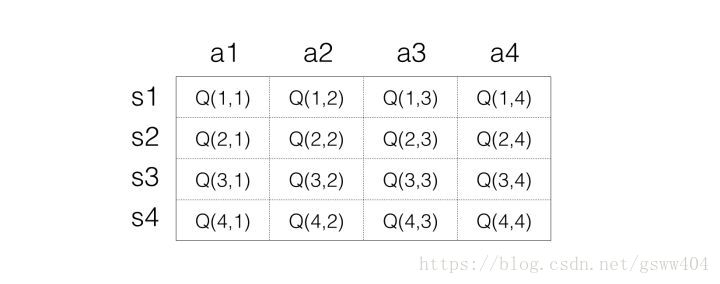
具体过程根据伪代码:首先初始化矩阵(所有都为0),第一次随机并采用贪婪策略选择action,假如选择action2后选择到了状态2,(
α
=
0
,
γ
=
0
\alpha=0,\gamma=0
α=0,γ=0),此时得到奖励1,则
Q
(
1
,
2
)
=
1
Q(1,2)=1
Q(1,2)=1
Q
(
s
t
,
a
t
)
←
r
t
+
max
π
Q
(
s
t
+
1
,
a
t
)
=
1
+
0
=
1
Q(s_{t},a_{t}) \leftarrow r_{t}+\max\limits_{\pi}Q(s_{t+1},a_{t})=1+0=1
Q(st,at)←rt+πmaxQ(st+1,at)=1+0=1
同样的道理,直到所有的值函数都是最优的,得出一个策略。解决小规模问题,可以说这是一个非常优秀的做法,但是如果遇到直升机飞行(连续过程,state大概有N个状态),或者围棋等状态空间(
1
0
70
10^{70}
1070)特别大的情况。无疑会出现维度灾难以及存储和检索困难,下面开始DQN神经网络近似值函数。
1.2 DQN algorithm
本文以Atati游戏例子(两篇论文)进行分析。
1.2.1 Introduction
Atari 2600游戏一款非常经典的游戏,本文以打砖块为例子,它是一个高维状态输入(原始图像像素输入),低维动作输出(离散的动作:上下左右,或者发射炮弹等),比如打砖块如图:
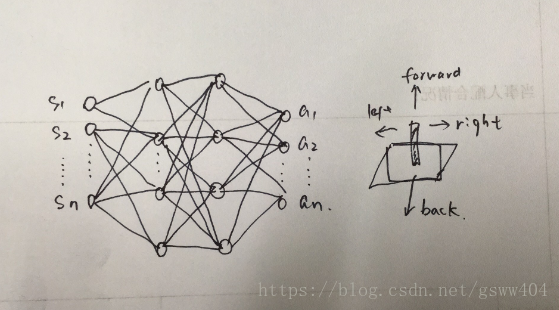
通常在计算机中处理,首先需要将图像读入,因此我们采用了卷积神经网络(CNN)读入图像,(卷积神经网络此处不详述)如图:

输入: 从 Atari 游戏的一帧RGB图像提取出代表亮度(luminance)的 Y 通道, 并resize成 84×84, 将这样图像的连续m帧作为输入, 论文里取m=4,即连续四帖图像作为游戏的输入信息.
经过卷积池化后得到n个state, 而最终我们将会输出K个离散的动作,在神经网络中可以表示为:
最后结合这两中思想得到论文中的图:
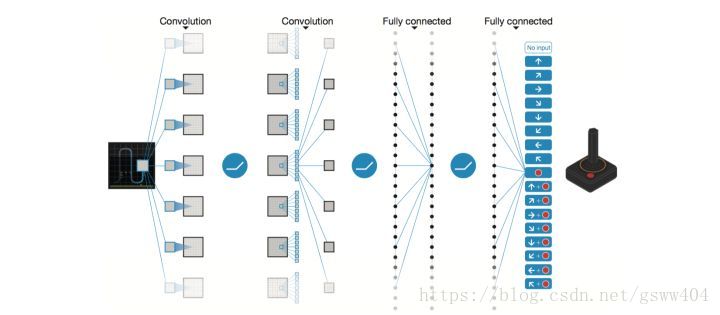
前文提到的K个离散的动作。其实是Q值函数,但此处的值函数Q不是一个具体的数值,而是一组向量,在神经网络中网路的权重为 θ \theta θ, 值函数表示为 Q ( s , a , θ ) Q(s,a,\theta) Q(s,a,θ),最终神经网络收敛后的 θ \theta θ 即为值函数。
1.2.2 奖励设置
reward r 的定义
将在当前时间 t, 状态 s 下采取行动 a 之后游戏的分值变化取值为 rt ,即
r
t
=
{
1
i
n
c
r
e
a
s
e
0
n
o
e
x
c
h
a
n
g
e
−
1
d
e
c
r
e
s
e
r_{t} =\left\{ \begin{aligned} 1 & & increase \\ 0 & & no exchange \\ -1 & & decrese \end{aligned} \right.
rt=⎩⎪⎨⎪⎧10−1increasenoexchangedecrese
长期累计折扣奖励则定义为:
R
t
=
∑
k
=
0
T
γ
k
r
t
+
k
+
1
R_{t} = \sum\limits_{k=0}^{T} \gamma^{k}r_{t+k+1}
Rt=k=0∑Tγkrt+k+1
1.2.3 近似和算法设置理论
因此整个过程的核心变为如何确定
θ
\theta
θ来近似值函数,最经典的做法就是采用梯度下降最小化损失函数来不断的调试网络权重
θ
\theta
θ, Loss function定义为:
L
i
(
θ
i
)
=
E
(
s
,
a
,
r
,
s
i
)
∼
U
(
D
)
[
(
r
+
γ
max
a
′
Q
(
s
′
,
a
i
;
θ
i
−
)
−
Q
(
s
,
a
;
θ
i
)
)
2
]
)
(3)
L_{i}(\theta_{i}) = E_{(s,a,r,s^{i})\sim U(D)}[(r+\gamma \max\limits_{a^{'}}Q(s^{'},a^{i};\theta_{i}^{-})-Q(s,a;\theta_{i}))^{2}] \tag{3})
Li(θi)=E(s,a,r,si)∼U(D)[(r+γa′maxQ(s′,ai;θi−)−Q(s,a;θi))2])(3)
其中,
θ
i
−
\theta_{i}^{-}
θi−是第i次迭代的target网络参数,
θ
i
\theta_{i}
θi是Q-network网络参数(后文会讲为什么使用Q网路和目标网路两种网络!),接下来就是对
θ
\theta
θ求梯度,如公式:
∂
L
i
(
θ
i
)
∂
θ
i
=
E
(
s
,
a
,
r
,
s
i
)
∼
U
(
D
)
[
(
r
+
γ
max
a
′
Q
^
(
s
′
,
a
i
;
θ
i
−
)
−
Q
(
s
,
a
;
θ
i
)
)
∇
θ
i
Q
(
s
,
a
;
θ
i
)
]
(4)
\frac{\partial L_{i}(\theta_{i})}{\partial\theta_{i}} = E_{(s,a,r,s^{i})\sim U(D)}[(r+\gamma \max\limits_{a^{'}}\hat{Q}(s^{'},a^{i};\theta_{i}^{-})-Q(s,a;\theta_{i}))\nabla_{\theta_{i}}Q(s,a;\theta_{i})] \tag{4}
∂θi∂Li(θi)=E(s,a,r,si)∼U(D)[(r+γa′maxQ^(s′,ai;θi−)−Q(s,a;θi))∇θiQ(s,a;θi)](4)
另外,在学习过程中,将训练的四元组存进一个replay memory
D
D
D 中,在学习过程中以min-batch读取训练网络结构。(优点见后文)
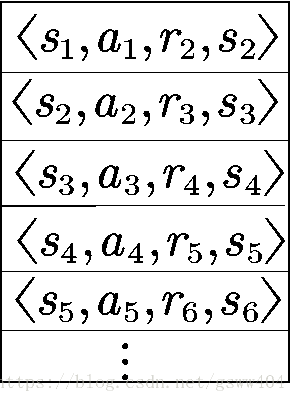
具体的伪代码见:

两个非常重要的思想:** 经验回放和 目标网络**
(1) Experience Replay,其将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。
Experience Replay的原因:
- 1、深度神经网络作为有监督学习模型,要求数据满足独立同分布
- 2、Q Learning 算法得到的样本前后是有关系的。为了打破数据之间的关联性,Experience Replay 方法通过存储-采样的方法将这个关联性打破了。
在这个问题中,之所以加入experience replay是因为样本是从游戏中的连续帧获得的,这与简单RL比如maze)相比,样本的关联性大了很多,如果没有experience replay,算法在连续一段时间内基本朝着同一个方向做梯度下降,那么同样的步长下这样直接计算gradient就有可能不收敛。因此experience replay是从一个memory pool中随机选取了一些 experience,然后再求梯度,从而避免了这个问题
Experience Replay优点:
- 1、数据利用率高,因为一个样本被多次使用。
- 2、连续样本的相关性会使参数更新的方差(variance)比较大,该机制可减少这种相关性。注意这里用的是均匀随机采样
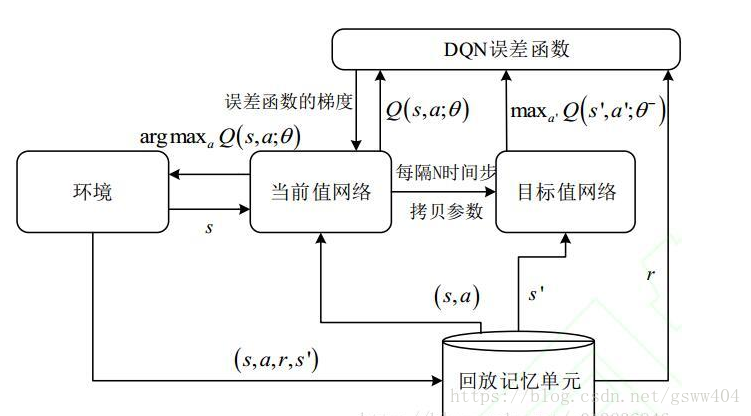
(2)TargetNet: 引入TargetNet后,在一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。用另一个TargetNet产生Target Q值。具体地, Q ( s , a ; θ i ) Q(s,a;θ_{i}) Q(s,a;θi) 表示当前网络MainNet的输出,用来评估当前状态动作对的值函数; Q ( s , a ; θ i ) Q(s,a;θ_{i}) Q(s,a;θi) 表示TargetNet的输出,代入上面求 TargetQ 值的公式中得到目标Q值。根据上面的Loss Function更新MainNet的参数,每经过N轮迭代,将MainNet的参数复制给TargetNet。
根据算法伪代码,运行结构如图,下文将对具体代码进行简单分析:
1.2.3 Training
DeepMind关于《DQN(2015)》的实现采用了pytorch写的源代码( https://github.com/deepmind/dqn ),本文以tensorflow进行分析,对devsisters的仓库的DQN代码进行讲解,文末致谢!
注:源码使用gym环境,具体安装参考:
git clone https://github.com/openai/gym
cd gym
sudo pip install -e .[all]
# test install
import gym
env = gym.make('CartPole-v0')
env.reset() #reset environment
for _ in range(1000): #1000 frame
env.render()
env.step(env.action_space.sample()) # take a random action
# result
There is a swinging car
随机选取动作过程如:
def _random_step(self):
action = self.env.action_space.sample()
self._step(action)
经过action后获得的奖励:
def _step(self, action):
self._screen, self.reward, self.terminal, _ = self.env.step(action)
在运行过程中经过动作action后的 s t + 1 s_{t+1} st+1环境:
class SimpleGymEnvironment(Environment):
def __init__(self, config):
super(SimpleGymEnvironment, self).__init__(config)
def act(self, action, is_training=True):
self._step(action)
self.after_act(action)
return self.state
卷积过程:
def conv2d(x,
output_dim,
kernel_size,
stride,
initializer=tf.contrib.layers.xavier_initializer(),
activation_fn=tf.nn.relu,
data_format='NHWC',
padding='VALID',
name='conv2d'):
with tf.variable_scope(name):
if data_format == 'NCHW':
stride = [1, 1, stride[0], stride[1]]
kernel_shape = [kernel_size[0], kernel_size[1], x.get_shape()[1], output_dim]
elif data_format == 'NHWC':
stride = [1, stride[0], stride[1], 1]
kernel_shape = [kernel_size[0], kernel_size[1], x.get_shape()[-1], output_dim]
w = tf.get_variable('w', kernel_shape, tf.float32, initializer=initializer)
conv = tf.nn.conv2d(x, w, stride, padding, data_format=data_format)
b = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
out = tf.nn.bias_add(conv, b, data_format)
if activation_fn != None:
out = activation_fn(out)
return out, w, b
网路结构优化见:
# optimizer
with tf.variable_scope('optimizer'):
self.target_q_t = tf.placeholder('float32', [None], name='target_q_t')
self.action = tf.placeholder('int64', [None], name='action')
action_one_hot = tf.one_hot(self.action, self.env.action_size, 1.0, 0.0, name='action_one_hot')
q_acted = tf.reduce_sum(self.q * action_one_hot, reduction_indices=1, name='q_acted')
self.delta = self.target_q_t - q_acted
self.global_step = tf.Variable(0, trainable=False)
self.loss = tf.reduce_mean(clipped_error(self.delta), name='loss')
self.learning_rate_step = tf.placeholder('int64', None, name='learning_rate_step')
self.learning_rate_op = tf.maximum(self.learning_rate_minimum,
tf.train.exponential_decay(
self.learning_rate,
self.learning_rate_step,
self.learning_rate_decay_step,
self.learning_rate_decay,
staircase=True))
self.optim = tf.train.RMSPropOptimizer(
self.learning_rate_op, momentum=0.95, epsilon=0.01).minimize(self.loss)
网络训练函数:
def train(self):
start_step = self.step_op.eval()
start_time = time.time()
num_game, self.update_count, ep_reward = 0, 0, 0.
total_reward, self.total_loss, self.total_q = 0., 0., 0.
max_avg_ep_reward = 0
ep_rewards, actions = [], []
screen, reward, action, terminal = self.env.new_random_game()
for _ in range(self.history_length):
self.history.add(screen)
for self.step in tqdm(range(start_step, self.max_step), ncols=70, initial=start_step):
if self.step == self.learn_start:
num_game, self.update_count, ep_reward = 0, 0, 0.
total_reward, self.total_loss, self.total_q = 0., 0., 0.
ep_rewards, actions = [], []
# 1. predict
action = self.predict(self.history.get())
# 2. act
screen, reward, terminal = self.env.act(action, is_training=True)
# 3. observe
self.observe(screen, reward, action, terminal)
if terminal:
screen, reward, action, terminal = self.env.new_random_game()
num_game += 1
ep_rewards.append(ep_reward)
ep_reward = 0.
else:
ep_reward += reward
actions.append(action)
total_reward += reward
if self.step >= self.learn_start:
if self.step % self.test_step == self.test_step - 1:
avg_reward = total_reward / self.test_step
avg_loss = self.total_loss / self.update_count
avg_q = self.total_q / self.update_count
try:
max_ep_reward = np.max(ep_rewards)
min_ep_reward = np.min(ep_rewards)
avg_ep_reward = np.mean(ep_rewards)
except:
max_ep_reward, min_ep_reward, avg_ep_reward = 0, 0, 0
print('\navg_r: %.4f, avg_l: %.6f, avg_q: %3.6f, avg_ep_r: %.4f, max_ep_r: %.4f, min_ep_r: %.4f, # game: %d' \
% (avg_reward, avg_loss, avg_q, avg_ep_reward, max_ep_reward, min_ep_reward, num_game))
if max_avg_ep_reward * 0.9 <= avg_ep_reward:
self.step_assign_op.eval({self.step_input: self.step + 1})
self.save_model(self.step + 1)
max_avg_ep_reward = max(max_avg_ep_reward, avg_ep_reward)
if self.step > 180:
self.inject_summary({
'average.reward': avg_reward,
'average.loss': avg_loss,
'average.q': avg_q,
'episode.max reward': max_ep_reward,
'episode.min reward': min_ep_reward,
'episode.avg reward': avg_ep_reward,
'episode.num of game': num_game,
'episode.rewards': ep_rewards,
'episode.actions': actions,
'training.learning_rate': self.learning_rate_op.eval({self.learning_rate_step: self.step}),
}, self.step)
num_game = 0
total_reward = 0.
self.total_loss = 0.
self.total_q = 0.
self.update_count = 0
ep_reward = 0.
ep_rewards = []
actions = []
完整代码见仓库:(https://github.com/devsisters/DQN-tensorflow ),在此表示对devsisters的诚挚感谢
第三篇:
本文后续会以单独的blog讲解DQN的各种变体i:
- Distribute DQN
- Double DQN
- Dueling DQN
- Prioritized Experience Replay DQN
- Rainbow
等
参考文献:
[1]. Richard S.Sutton and Andrew G. Barto,Reinforcement learning: An Introduction,second edition.2017.
[2]. Lucian Busontu et al, Reinforcement learning and dynamic programming using function approximators.
[3]. 郭宪 方勇纯, 深入浅出强化学习:原理入门
[4]. David Sliver, Introduction to Reinforcement learning
(UCL:https://www.youtube.com/channel/UCP7jMXSY2xbc3KCAE0MHQ-A)
[5].https://zhuanlan.zhihu.com/reinforce
[6].https://zhuanlan.zhihu.com/p/21421729
[7].https://blog.csdn.net/u013236946/article/details/72871858
[8].http://jikaichen.com/2016/11/18/notes-on-atari/