1. 大致步骤
上一步整理完数据集后,此步输入数据, 微调2个模型VITS和GPT,位置在 <<1-GPT-SoVITS-tts>>下的<<1B-微调训练>>
页面的两个按钮分别执行两个文件:
- <./GPT_SoVITS/s2_train.py>
这一步微调VITS的预训练模型,即微调SynthesizerTrn模型
- <./GPT_SoVITS/s1_train.py>
这一步微调GPT的预训练模型,这里采用的是google的soundstorm复现
模型结构文件在:’ ./GPT_SoVITS/AR/models/t2s_model.py’
注意,两个模型微调是独立的, 可分别完成
界面如下:
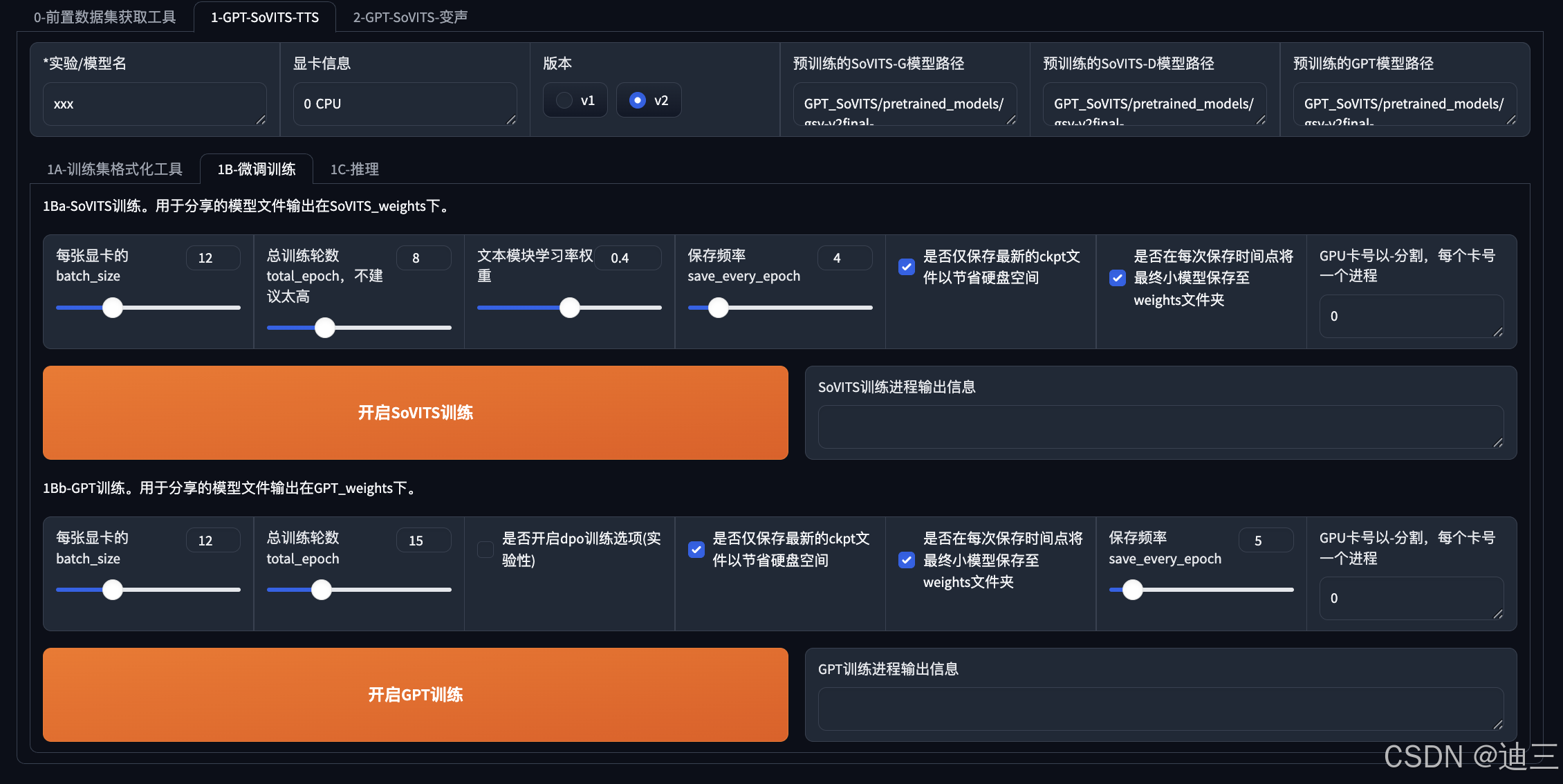
2. 微调过程
2.1执行SoVITS训练
-
这里webui.py中代码会用gradio框架将页面上的设置转换为python变量,并保存到‘。/TEMP’文件夹的‘tmp_s2.json’文件,用于送入s2_train.py作为训练参数
-
另外,‘./logs’下会生成 train.log 和 config.json文件,记录微调的配置信息。以及eval和logs_s2文件夹,同样记录训练过程数据。
-
微调后的模型保存到‘GPT_weights_v2’文件夹
-
配置记录:
train.log
2024-10-21 23:48:33,030 XXX INFO {'train': {'log_interval': 100, 'eval_interval': 500, 'seed': 1234, 'epochs': 2, 'learning_rate': 0.0001, 'betas': [0.8, 0.99], 'eps': 1e-09, 'batch_size': 6, 'fp16_run': False, 'lr_decay': 0.999875, 'segment_size': 20480, 'init_lr_ratio': 1, 'warmup_epochs': 0, 'c_mel': 45, 'c_kl': 1.0, 'text_low_lr_rate': 0.4, 'pretrained_s2G': 'GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth', 'pretrained_s2D': 'GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth', 'if_save_latest': True, 'if_save_every_weights': True, 'save_every_epoch': 4, 'gpu_numbers': '0'}, 'data': {'max_wav_value': 32768.0, 'sampling_rate': 32000, 'filter_length': 2048, 'hop_length': 640, 'win_length': 2048, 'n_mel_channels': 128, 'mel_fmin': 0.0, 'mel_fmax': None, 'add_blank': True, 'n_speakers': 300, 'cleaned_text': True, 'exp_dir': 'logs/xxx'}, 'model': {'inter_channels': 192, 'hidden_channels': 192, 'filter_channels': 768, 'n_heads': 2, 'n_layers': 6, 'kernel_size': 3, 'p_dropout': 0.1, 'resblock': '1', 'resblock_kernel_sizes': [3, 7, 11], 'resblock_dilation_sizes': [[1, 3, 5], [1, 3, 5], [1, 3, 5]], 'upsample_rates': [10, 8, 2, 2, 2], 'upsample_initial_channel': 512, 'upsample_kernel_sizes': [16, 16, 8, 2, 2], 'n_layers_q': 3, 'use_spectral_norm': False, 'gin_channels': 512, 'semantic_frame_rate': '25hz', 'freeze_quantizer': True, 'version': 'v2'}, 's2_ckpt_dir': 'logs/xxx', 'content_module': 'cnhubert', 'save_weight_dir': 'SoVITS_weights_v2', 'name': 'xxx', 'version': 'v2', 'pretrain': None, 'resume_step': None}
2024-10-04 17:02:30,480 xxx01 INFO loaded pretrained GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
2024-10-04 17:02:30,697 xxx01 INFO loaded pretrained GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth
2024-10-04 17:03:03,571 xxx01 INFO Train Epoch: 1 [0%]
2024-10-04 17:03:03,571 xxx01 INFO [2.700843572616577, 2.197847366333008, 5.394582748413086, 18.876893997192383, 0.0, 2.0498788356781006, 0, 9.99875e-05]
2024-10-04 17:03:08,853 xxx01 INFO ====> Epoch: 1
2024-10-04 17:03:14,537 xxx01 INFO ====> Epoch: 2
2024-10-04 17:03:19,520 xxx01 INFO ====> Epoch: 3
2024-10-04 17:03:24,553 xxx01 INFO Saving model and optimizer state at iteration 4 to logs/yc01/logs_s2\G_233333333333.pth
2024-10-04 17:03:26,369 xxx01 INFO Saving model and optimizer state at iteration 4 to logs/yc01/logs_s2\D_233333333333.pth
2024-10-04 17:03:32,288 xxx01 INFO saving ckpt xxx01_e4:Success.
- config.json
{"train": {"log_interval": 100, "eval_interval": 500, "seed": 1234, "epochs": 2, "learning_rate": 0.0001, "betas": [0.8, 0.99], "eps": 1e-09, "batch_size": 6, "fp16_run": false, "lr_decay": 0.999875, "segment_size": 20480, "init_lr_ratio": 1, "warmup_epochs": 0, "c_mel": 45, "c_kl": 1.0, "text_low_lr_rate": 0.4, "pretrained_s2G": "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth", "pretrained_s2D": "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth", "if_save_latest": true, "if_save_every_weights": true, "save_every_epoch": 4, "gpu_numbers": "0"}, "data": {"max_wav_value": 32768.0, "sampling_rate": 32000, "filter_length": 2048, "hop_length": 640, "win_length": 2048, "n_mel_channels": 128, "mel_fmin": 0.0, "mel_fmax": null, "add_blank": true, "n_speakers": 300, "cleaned_text": true, "exp_dir": "logs/xxx"}, "model": {"inter_channels": 192, "hidden_channels": 192, "filter_channels": 768, "n_heads": 2, "n_layers": 6, "kernel_size": 3, "p_dropout": 0.1, "resblock": "1", "resblock_kernel_sizes": [3, 7, 11], "resblock_dilation_sizes": [[1, 3, 5], [1, 3, 5], [1, 3, 5]], "upsample_rates": [10, 8, 2, 2, 2], "upsample_initial_channel": 512, "upsample_kernel_sizes": [16, 16, 8, 2, 2], "n_layers_q": 3, "use_spectral_norm": false, "gin_channels": 512, "semantic_frame_rate": "25hz", "freeze_quantizer": true, "version": "v2"}, "s2_ckpt_dir": "logs/xxx", "content_module": "cnhubert", "save_weight_dir": "SoVITS_weights_v2", "name": "xxx", "version": "v2"}
- tmp_s2.json
{"train": {"log_interval": 100, "eval_interval": 500, "seed": 1234, "epochs": 2, "learning_rate": 0.0001, "betas": [0.8, 0.99], "eps": 1e-09, "batch_size": 6, "fp16_run": false, "lr_decay": 0.999875, "segment_size": 20480, "init_lr_ratio": 1, "warmup_epochs": 0, "c_mel": 45, "c_kl": 1.0, "text_low_lr_rate": 0.4, "pretrained_s2G": "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth", "pretrained_s2D": "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth", "if_save_latest": false, "if_save_every_weights": true, "save_every_epoch": 2, "gpu_numbers": "0"}, "data": {"max_wav_value": 32768.0, "sampling_rate": 32000, "filter_length": 2048, "hop_length": 640, "win_length": 2048, "n_mel_channels": 128, "mel_fmin": 0.0, "mel_fmax": null, "add_blank": true, "n_speakers": 300, "cleaned_text": true, "exp_dir": "logs/wmd"}, "model": {"inter_channels": 192, "hidden_channels": 192, "filter_channels": 768, "n_heads": 2, "n_layers": 6, "kernel_size": 3, "p_dropout": 0.1, "resblock": "1", "resblock_kernel_sizes": [3, 7, 11], "resblock_dilation_sizes": [[1, 3, 5], [1, 3, 5], [1, 3, 5]], "upsample_rates": [10, 8, 2, 2, 2], "upsample_initial_channel": 512, "upsample_kernel_sizes": [16, 16, 8, 2, 2], "n_layers_q": 3, "use_spectral_norm": false, "gin_channels": 512, "semantic_frame_rate": "25hz", "freeze_quantizer": true, "version": "v2"}, "s2_ckpt_dir": "logs/xxx", "content_module": "cnhubert", "save_weight_dir": "SoVITS_weights_v2", "name": “xxx”, "version": "v2"}
以上3个文件的内容是冗余的,配置信息的参数一致, 只是‘train.log’会记录微调时命令行的输出。
生成文件后,s2_train.py首先加载VITS预训练模型,之后训练设置的epoch数。
2.2执行GPT训练
这一步和上一步时类似,执行s2_train.py文件,微调后的模型保存到‘SoVITS_weights_v2’
3.语音合成
这一步位置在 位置在 <<1-GPT-SoVITS-tts>>下的<<1C-推理>>,界面如下:

-
选择预训练
-
GPT模型列表选择
-
SoVITS模型列表选择
-
-
开启推理界面
点击开启TTS推理WebUi选项,就会弹出推理节目
这里执行的是’inference_webui.py’ 或 ‘inference_webui_fast.py’文件
4.推理界面(需要打开)
这里可以传一个参考音频,并填入对应语意文本,模型训练够好的话(数据+epoch够多),也可以不传。
界面如下:
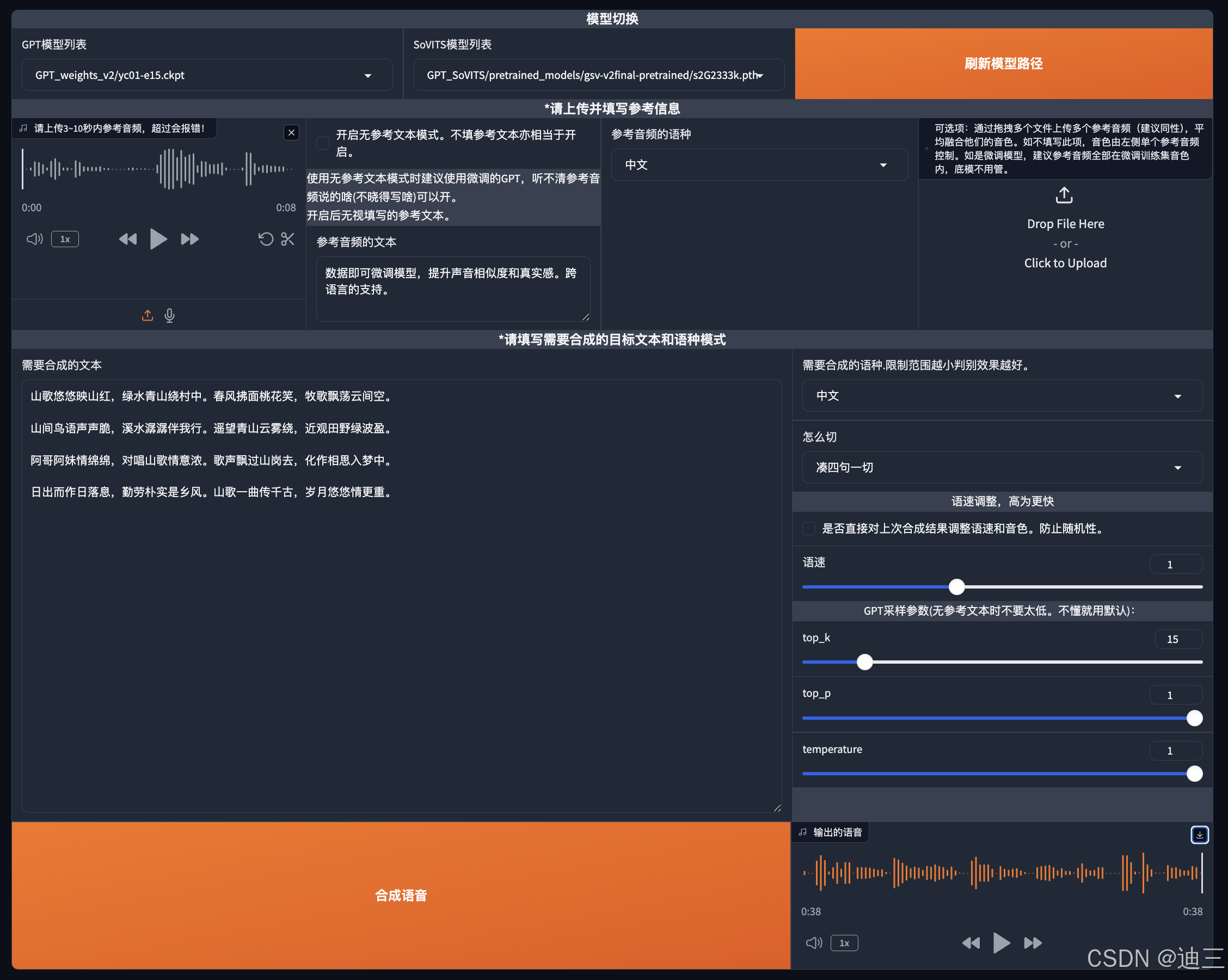
输出的语音就是克隆的声音了,由于版本还在更新,项目组可能后去还会更新改动页面和功能,因此这里只是大致流程。
Reference
- https://github.com/yangdongchao/SoundStorm/blob/master/soundstorm/s1/AR/models/t2s_model.py
- https://google-research.github.io/seanet/soundstorm/examples/