董付国老师Python系列教材(累计印刷超过200次)推荐与选用参考
==============
版权声明:由于公众号后台规则问题,本文暂时无法设置原创标记,但仍属原创内容,微信公众号“Python小屋”坚持只发原创技术文章。
=============
推荐教材:
董付国编著.Python程序设计(第4版·微课版·在线学习软件版),ISBN:9787302663799,清华大学出版社,2024年6月出版,2024年7月第2次印刷(本书前3版印刷34次),定价69.8元,山东省普通高等教育一流教材,国家级特色专业、国家级一流本科专业“计算机科学与技术”配套教材,山东省一流本科课程“Python应用开发”配套教材,2019、2020、2021、2022年清华大学出版社畅销教材,2022、2023年清华大学出版社科技类最受高校欢迎奖



图书内容:154个例题、140节微课视频(含课程思政),内容涉及Python基础、Office文件操作、GUI、图像处理、计算机图形学、音视频处理、数据分析与科学计算可视化、密码学、数据库、网络编程、多线程与多进程、逆向工程、Windows系统编程与安卓编程等领域。
页数:372
适用专业:计算机类所有专业
适用层次:研究生/本科/专科
配套资源:教学大纲、电子教案、课件、源码、数据文件、习题答案、题库,在线练习软件,支持课程思政,支持工程教育认证
适用学时:64/96/128
===============
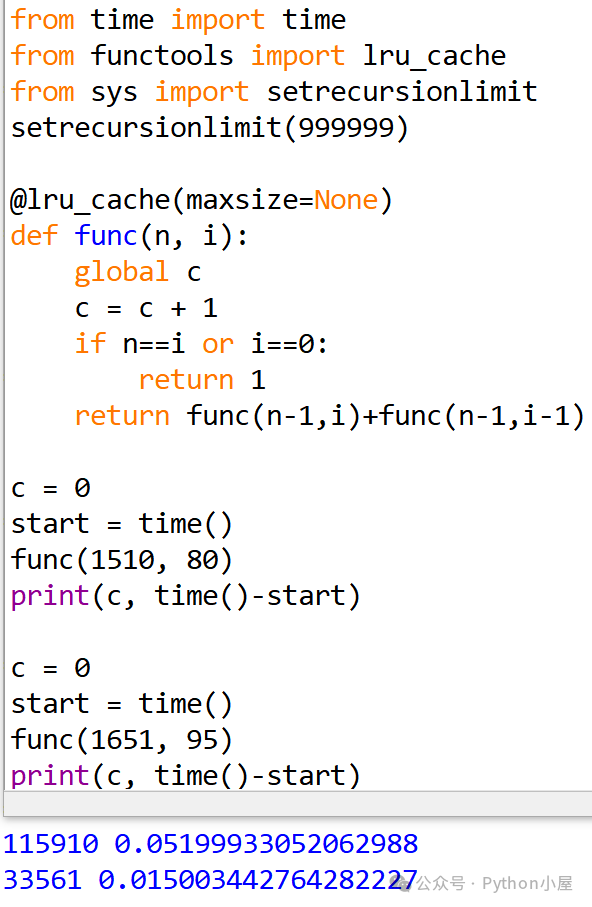
如果一个函数需要反复多次调用(尤其是递归调用),且后面调用中需要用到前面调用时已经计算过的值,可以使用修饰器函数functools.lru_cache()为被调函数增加一个全局缓存(或称记忆体)来临时记录这些数据。增加缓存之后,如果待计算的值之前已经计算过且仍在缓存中则直接返回,通过引入少量空间来避免大量重复计算,从而获得更高的效率。
使用修饰器函数functools.lru_cache()时可以设置缓存大小,通过参数maxsize设置最多缓存多少个数据,当缓存中的数据达到最大数量时会删除最近最少使用的一个,腾出空间存放新数据。设置参数maxsize为None表示不限制缓存大小,不删除旧值,缓存所有数据,此时等价于另一个修饰器函数cache()。
下面以计算组合数的帕斯卡公式cni(n,i) = cni(n-1,i) + cni(n-1,i-1)为例,演示这两个修饰器函数的用法。
首先来看一下不使用缓存的函数及其执行时间。从运行结果可以看出,计算一个并不太大的组合数居然需要那么长时间。这里的变量c是为了记录函数调用次数,这会引入一点额外的计算,删除变量c的相关代码后运行时间会略短一些。
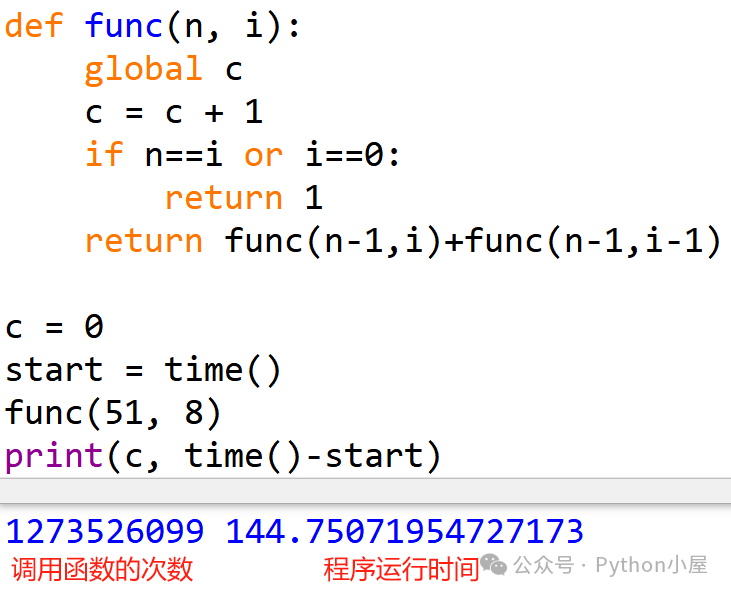
这是因为存在大量重复计算,如下图所示,树中存在两棵一模一样的节点,也就意味着两棵一模一样的子树。随着二叉树的不断扩展,还会出现很多类似的情况。
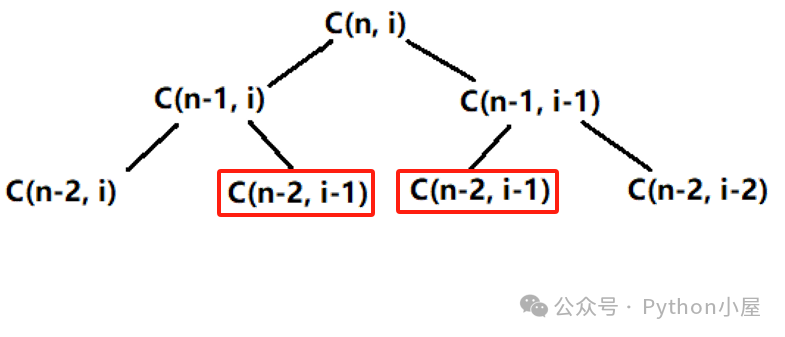
接下来,导入修饰器函数lru_cache()并为函数func()增加缓存,从运行结果可以看出,函数调用次数少了很多,同样的,程序运行时间也少了很多,瞬间就运行完成了。
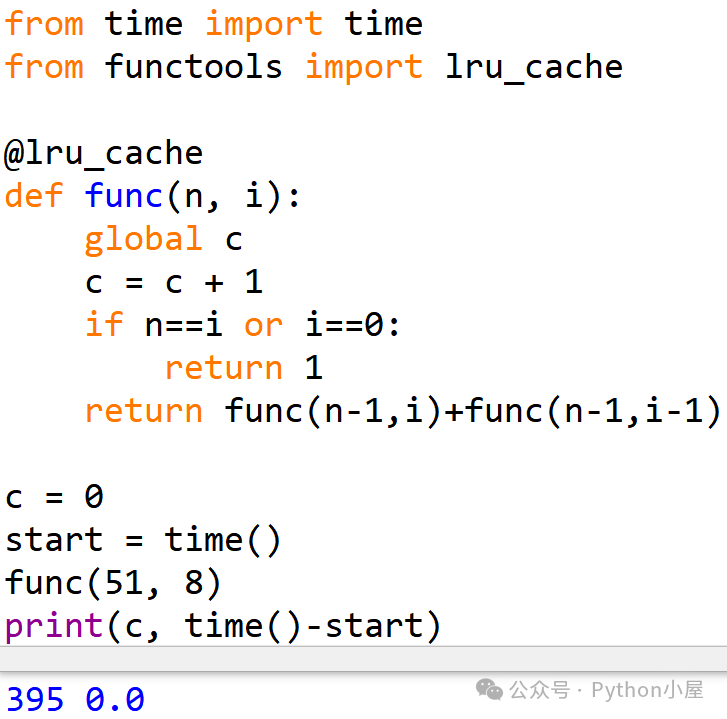
如果你认为这就展示了修饰器函数lru_cache()的全部威力,那就太小看它了。我们继续修改代码,把最后几行测试代码重复一次。可以看到,第二次调用函数时直接得到了结果,函数调用次数为0,这说明被修饰过的函数func()运行结束之后,修饰器函数设置的全局缓存仍然有效,其中缓存的数据仍然可用。

按照这个思路,如果我们第二次调用函数时计算更大的组合数时,是不是可以继续使用并根据需要扩展这个全局缓存,从而节约一些计算来提高速度呢?由于增加缓存后计算速度非常快,我们把参数设置的大一些,另外还修改了递归深度限制避免代码崩溃。从运行结果来看,似乎和想象的不太一样,第一次调用函数时缓存的数据并没有减少第二次调用函数时的计算量。
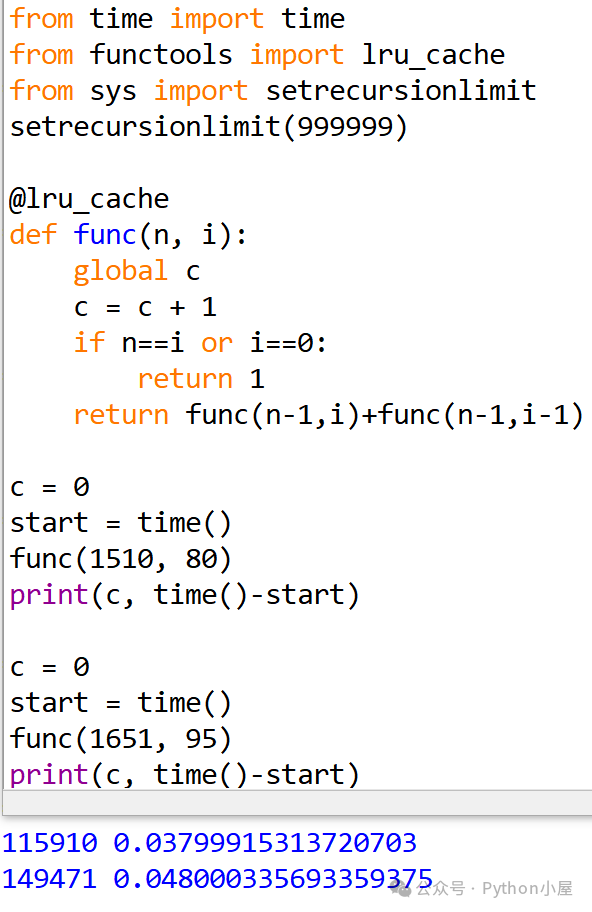
之所以出现这样的情况,是因为修饰器函数lru_cache()默认缓存大小为128,也就是最多缓存128个数据,当缓冲区已满且需要保存新数据时会删除最近最少使用的一个数据。
在上面的代码中,第二次调用函数时还没等用到第一次函数调用时缓存的数据,这些数据就被删除了。
为了解决这个问题,可以在使用修饰器函数lru_cache()时把缓冲区设置的大一些,但这个大小不好控制。这时可以把参数maxsize设置为None,表示不限制缓冲区大小,可以缓存所有数据。从下面的运行结果可以看出,第二次调用函数时充分利用了第一次调用函数时缓存的数据。这种情况下,可以把@lru_cache(maxsize=None)改写为@cache,二者功能相同,后者自Python 3.9开始支持,请自行测试。
众所周知,修饰器其实是一种特殊的函数,可以接收另一个函数作为参数进行修饰得到新函数,也就是说,上面的代码可以修改为下面的样子。由于lru_cache()函数作为函数使用时不能指定参数maxsize,只能使用默认值128,所以改用另一个不限制缓存大小的函数cache()进行演示。

好了,本文的另一个重点来了,把lru_cache()或cache()用作函数对另一个进行修饰增加缓存时,如果不使用原来的函数名而使用新的函数名,则设置的缓存并没有真正起作用,由于计算大组合数的时间非常非常长,所以使用小自然数进行测试。

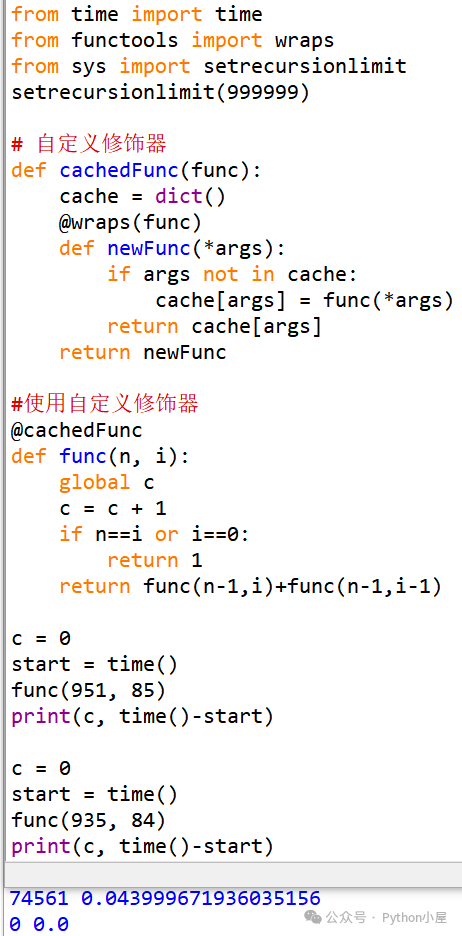
最后,熟悉嵌套函数定义的朋友肯定知道,其实我们也可以自定义修饰器函数来实现上面的功能。例如,
=================
温馨提示:
关注微信公众号“Python小屋”,在公众号后台发送消息“大事记”可以查看董付国老师与Python有关的重要事件;发送消息“教材”可以查看董付国老师出版的Python系列教材(已累计印刷超过215次)的适用专业详情;发送消息“历史文章”可以查看董付国老师推送的超过1400篇原创技术文章;发送消息“会议”可以查看近期董付国老师的培训安排;发送消息“微课”可以查看董付国老师免费分享的超过700节Python微课视频;发送消息“课件”可以查看董付国老师免费分享的Python教学资源;发送消息“小屋刷题”可以下载“Python小屋刷题神器”,免费练习5365道客观题和867道编程题,题库持续更新;发送消息“编程比赛”了解Python小屋编程大赛详情。