前几节学习了python的基础知识,包括数据结构和算法,函数,类,最终也通过python接入了deepseek.感觉非常简单。 我们学习python的最终目的就是构建人工神经网络,实现人工智能。万丈高楼平地起,人工智能是个抽象的概念,我们初步分解那就是,智能,推理,神经网络,神经元,函数,连接。翻译到编程语言,神经网络,就是成百上千上亿的函数和函数关系组成了神经元和神经网络,使整神经网络的输出像人一样有了智能一样,也就是人工智能。那么可以说人工智能就是人工神经网络,人工神经网络就是无数的python函数。
下面我们对python常用类库进行汇总学习和训练
一、pandas库
Pandas 是 Python 数据分析的核心技术库,可以进行数据的读取、清洗、过滤、统计、分析、汇总、透视、特征工程、数据可视化等各种处理和分析,是数据分析和机器学习等学科的重要基础技术。
Pandas的数据结构
Pandas主要有两种数据结构:Series和DataFrame。
Series:一维数组,具有标签。可以看作是一个一维数组,但每个元素都有一个标签。
DataFrame:二维的表格型数据结构,类似于Excel表格,可以存储不同数据类型的数据,并且支持缺失值。
Pandas的基本操作
位置索引访问:通过位置索引访问Series中的元素,例如s访问第一个元素。
标签索引访问:通过标签索引访问DataFrame中的行,例如df['column_name']访问某列。
查看数据信息:使用head()和tail()方法快速预览数据的前几行和后几行。
数据清洗:包括删除重复行、填充缺失值等操作。
Pandas的高级功能
聚合函数:Pandas支持多种聚合函数,如sum()、mean()、max()、min()等,用于计算统计指标。
数据透视表:使用pivot_table()方法创建数据透视表,用于数据的汇总和转换。
缺失值处理:Pandas提供了丰富的函数处理缺失值,如dropna()删除含有缺失值的行,fillna()填充缺失值。
开始练习
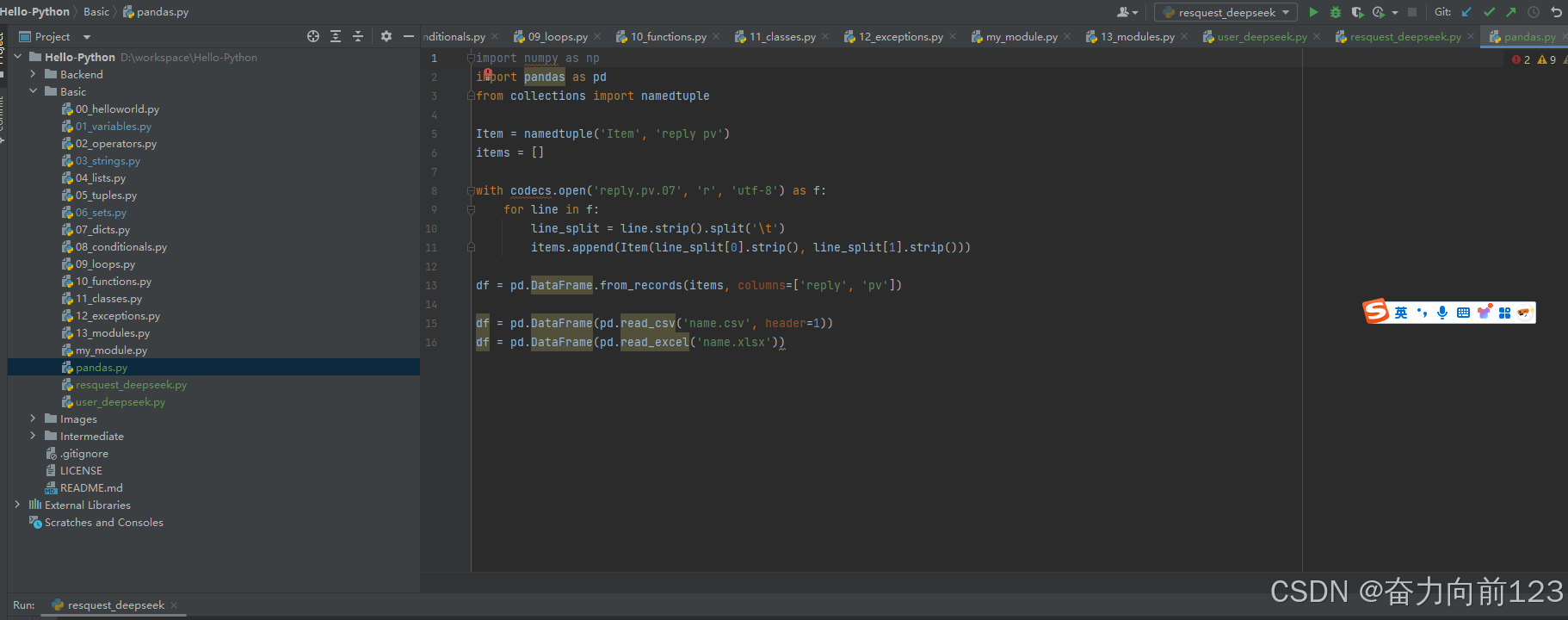
import numpy as np
import pandas as pd
from collections import namedtuple
Item = namedtuple('Item', 'reply pv')
items = []
with codecs.open('reply.pv.07', 'r', 'utf-8') as f:
for line in f:
line_split = line.strip().split('\t')
items.append(Item(line_split[0].strip(), line_split[1].strip()))
df = pd.DataFrame.from_records(items, columns=['reply', 'pv'])
df = pd.DataFrame(pd.read_csv('name.csv', header=1))
df = pd.DataFrame(pd.read_excel('name.xlsx'))二、Matplotlib库
python中的 Matplotlib模块主要用于数据可视化,这有点像几何学。用 图像来表示数据。
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
三、NumPy库
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
四、scikit-learn库
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库 [1]。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
以上类库的使用需要再实际项目多加训练