前言
上一节联系了python提供http接口给外部调用,已经成功了。很简单的代码,但是返回内容还是需要优化,现在返回的是HTML的内容,我们应该返回字典数据更好,或者是JSON数据,这个放到以后练习,本节练习python读取文件操作
马上开干
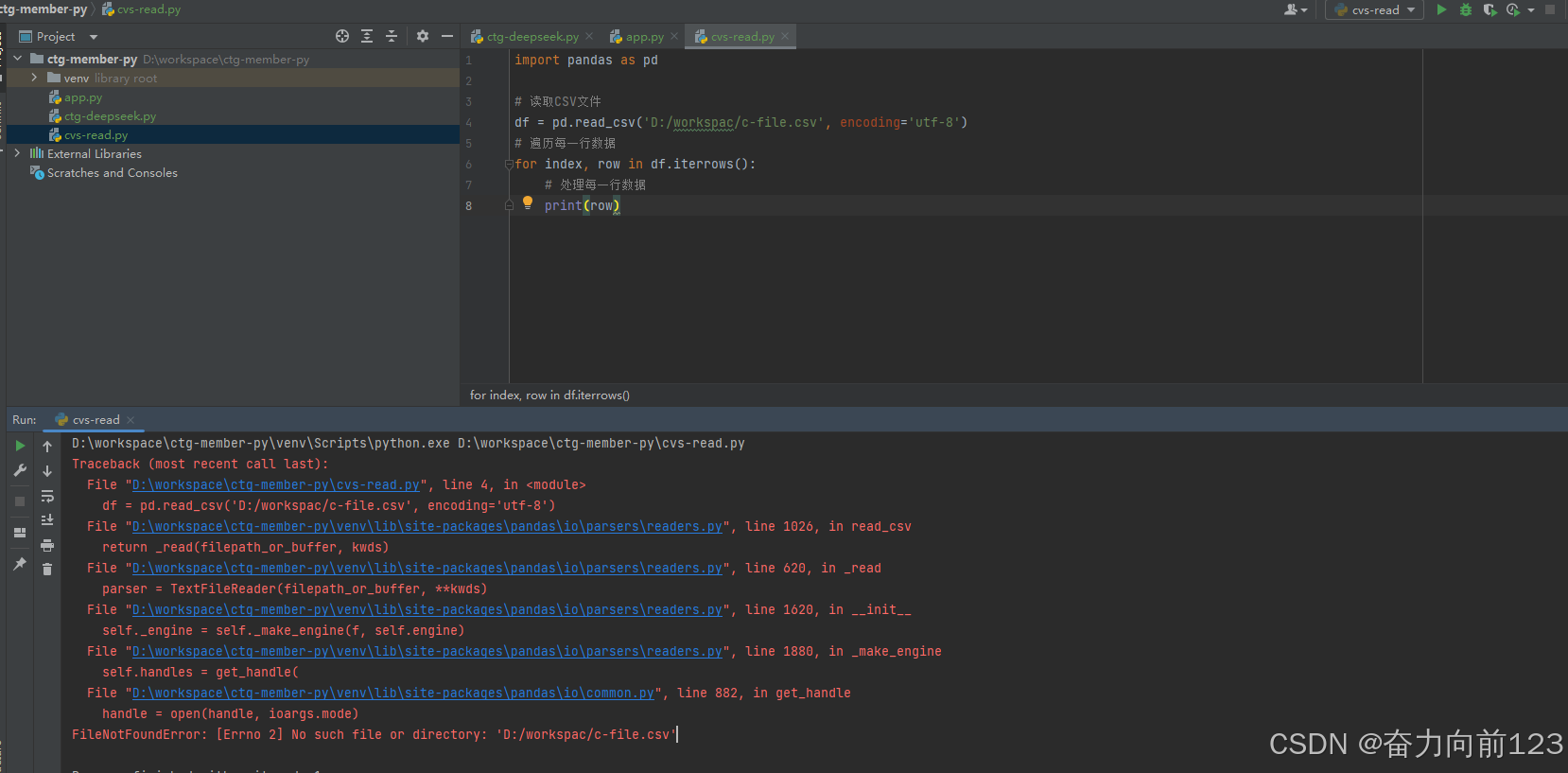
import pandas as pd
# 读取CSV文件
df = pd.read_csv('D:/workspace/c-file.csv', encoding='utf-8')
# 遍历每一行数据
for index, row in df.iterrows():
# 处理每一行数据
print(row)这里使用到了
pandas库。我们直接调用库里的方法就行。
运行一下看看
竟然报错
说找不到文件,我检查了路径,已经创建了文件,

那么python中读取文件的路径是怎么的,或者需要放在什么路径下? 于是搜索解决
说可能是转义的问题
示例:
# 使用原始字符串来避免转义字符的干扰
file_path = r"C:\example\myfile.txt"
# 打开文件
with open(file_path, 'r', encoding='utf-8') as file:
# 读取文件内容
content = file.read()
print(content)于是修改代码
import pandas as pd
# 读取CSV文件
file_path = r"D:\workspace\c-file.csv"
df = pd.read_csv(file_path, encoding='utf-8')
# 遍历每一行数据
for index, row in df.iterrows():
# 处理每一行数据
print(row)
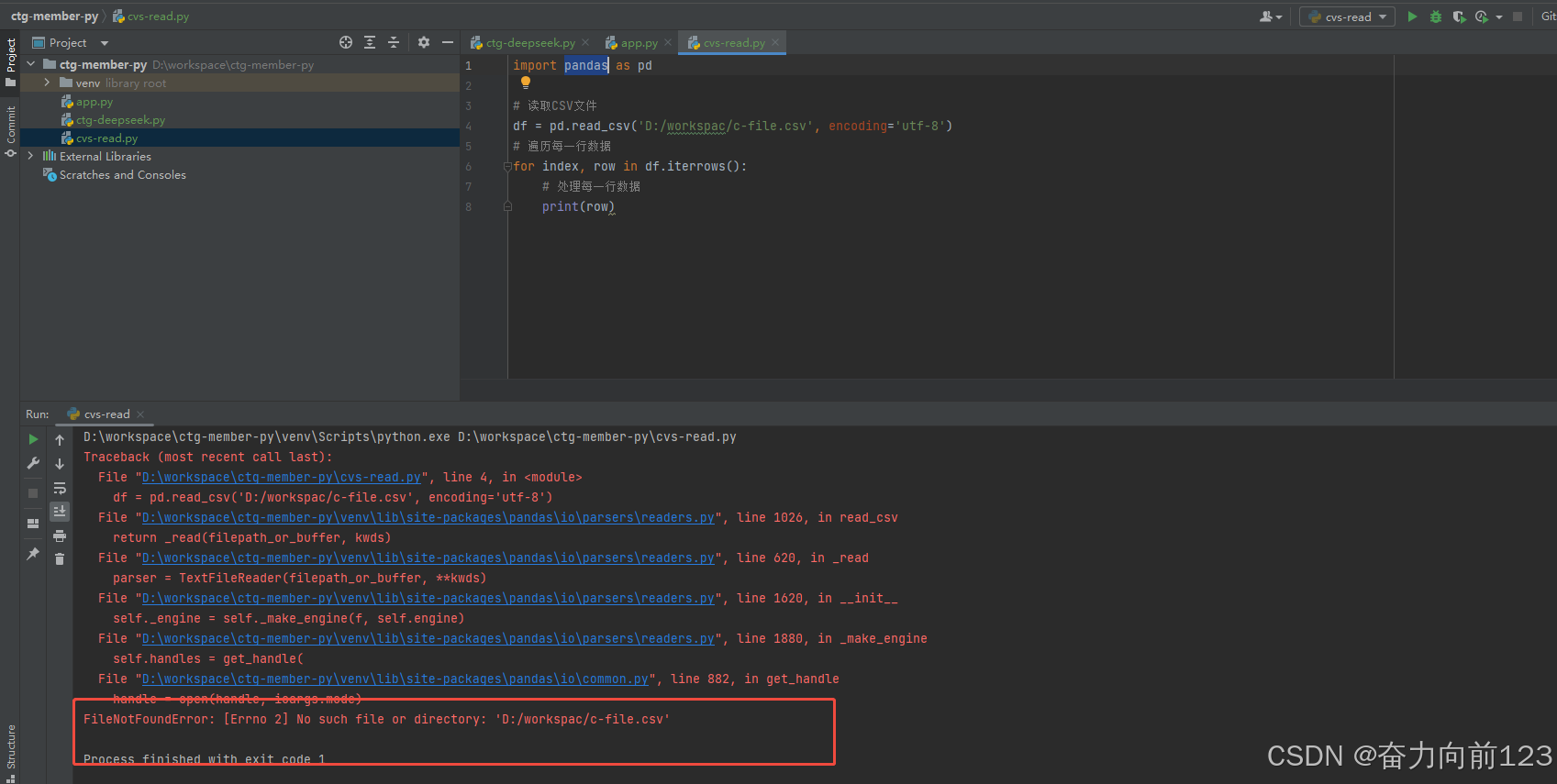
import pandas as pd
# 读取CSV文件
file_path = r"D:\workspace\c-file.csv"
df = pd.read_csv(file_path, encoding='utf-8')
# 遍历每一行数据
for index, row in df.iterrows():
# 处理每一行数据
print(row)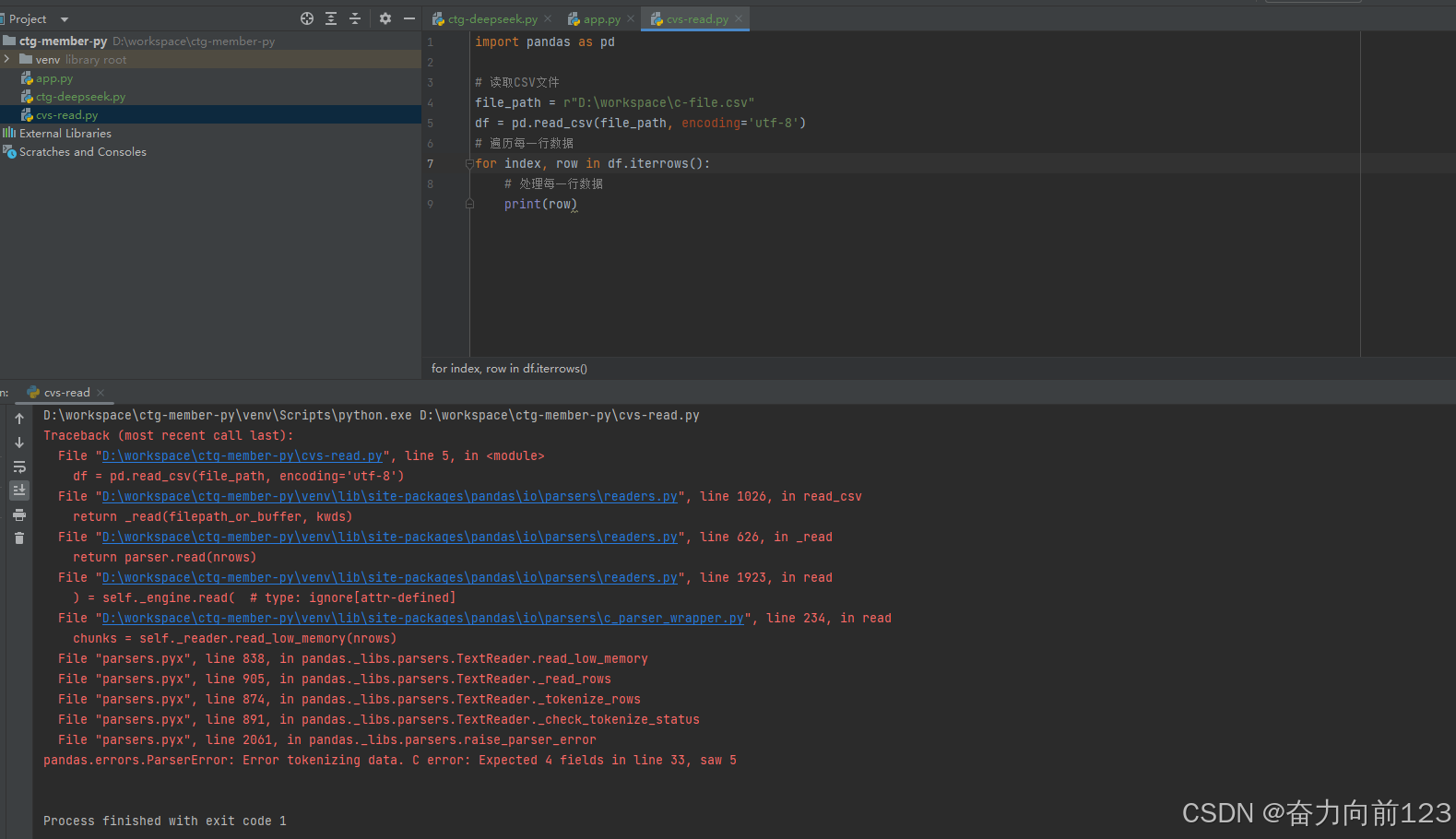
继续运行
没有报找不到文件错误,但是文件读取有问题
pandas.errors.ParserError: Error tokenizing data. C error: Expected 4 fields in line 30, saw 5
pandas.errors.ParserError: Error tokenizing data. C error: Expected 4 fields
在使用Pandas的read_csv函数读取CSV文件时遇到pandas.errors.ParserError: Error tokenizing data. C error: Expected 4 fields错误,通常是因为你的CSV文件中某些行的字段数量与预期不符。这可能是因为某些行缺失字段,或者在某些行中有额外的分隔符(如多余的逗号)。以下是一些解决这个问题的步骤:
1. 检查CSV文件
首先,你应该检查CSV文件,看看是否有行包含不正确的字段数量。你可以使用文本编辑器或Excel打开CSV文件,查看是否有明显的格式问题。
2. 指定正确的分隔符
确保你使用的分隔符与文件中的分隔符相匹配。例如,如果你的数据是用逗号分隔的,但在某些情况下使用了错误的分隔符(如分号或制表符),你可以在read_csv中指定正确的分隔符:
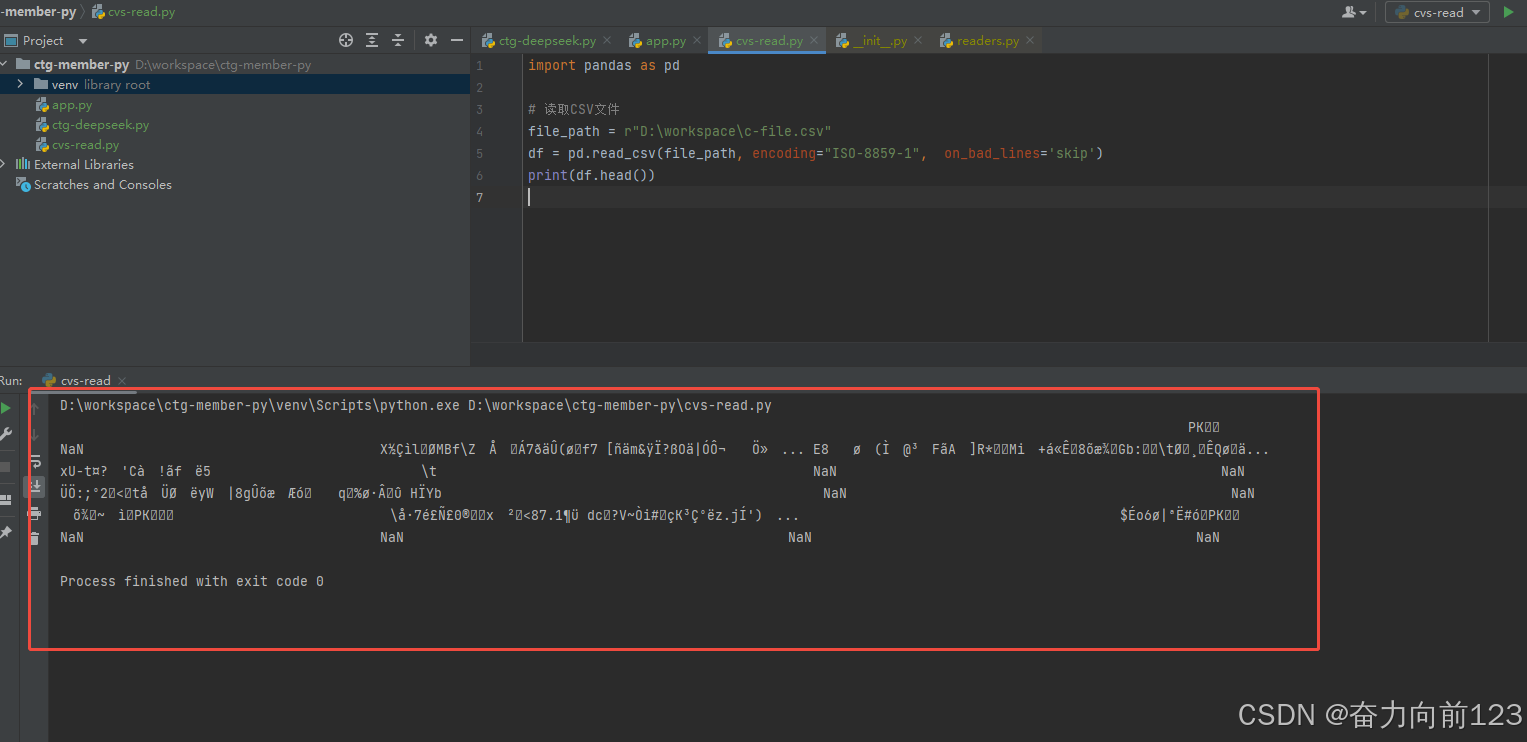
修改了代码,和编码,运行正常,但是是乱码,一时没搞懂
import pandas as pd
# 读取CSV文件
file_path = r"D:\workspace\c-file.csv"
df = pd.read_csv(file_path, encoding="ISO-8859-1", on_bad_lines='skip')
print(df.head())