引言
在人工智能与多媒体技术迅猛发展的当下,数字人已从概念构想逐步走进现实应用,广泛渗透于娱乐、教育、医疗、金融等多个领域。搭建数字人源码系统是一项综合性的技术工程,融合了计算机图形学、人工智能、语音处理等多学科前沿技术。本文将深入剖析数字人源码搭建的技术细节,为开发者提供详尽的技术开发指南。
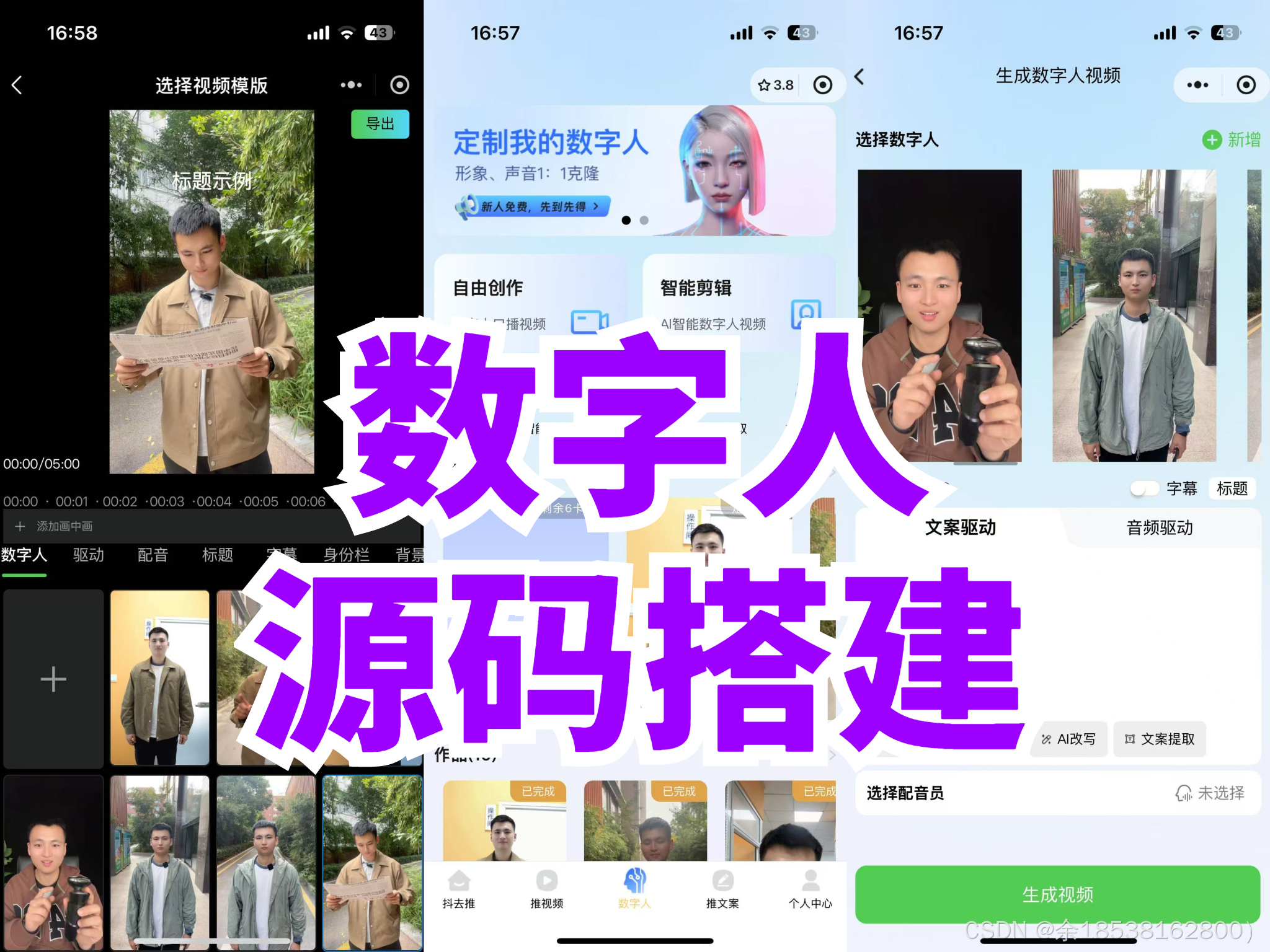
技术选型与架构设计
图形渲染技术
- 实时渲染引擎:
-
- Unity:作为一款跨平台的实时渲染引擎,Unity 在数字人开发领域应用广泛。其丰富的资源商店提供了大量现成的数字人模型资源,可大幅缩短开发周期。同时,Unity 具备强大的脚本编程能力,通过 C# 语言可方便地实现数字人的动作控制、表情驱动等功能。例如,利用 Unity 的 Animator 组件和动画状态机,能够轻松创建复杂的数字人动画逻辑,实现流畅的动作过渡。
-
- Unreal Engine:以其卓越的实时渲染效果著称,尤其在打造高度逼真的数字人形象方面表现突出。Unreal Engine 的蓝图可视化脚本系统,使非编程专业人员也能参与到数字人交互逻辑的开发中。此外,其先进的光照模型和材质系统,如基于物理的渲染(PBR)技术,能够渲染出极其真实的数字人皮肤、毛发和衣物效果,为用户带来沉浸式的视觉体验。
- 3D 建模软件:
-
- Blender:开源免费的 3D 建模软件,拥有全面且强大的建模工具集。在数字人建模过程中,可通过多边形建模方法构建数字人的基础形体,再利用雕刻工具精细雕琢面部表情细节,如皱纹、肌肉起伏等。Blender 还支持多种文件格式的导入与导出,方便与其他软件协同工作,在数字人模型制作流程中发挥着重要作用。
-
- Maya:专业的 3D 动画和建模软件,广泛应用于影视、游戏等行业。Maya 在角色动画制作方面具有显著优势,其丰富的骨骼系统和动画曲线编辑功能,能够为数字人赋予自然流畅的动作。同时,Maya 的材质编辑和渲染功能也十分强大,能够创建高质量的数字人材质和光影效果。
人工智能技术
- 自然语言处理(NLP):
-
- Transformer 架构模型:如 GPT - Neo、T5 等基于 Transformer 架构的模型,在自然语言理解和生成任务中表现卓越。这些模型通过大量文本数据的预训练,学习到了丰富的语言知识和语义表示。在数字人应用中,可利用这些模型实现智能对话功能,理解用户输入的文本,并生成合理、连贯的回复。例如,通过微调 GPT - Neo 模型,使其能够针对特定领域的问题提供专业准确的回答,增强数字人的交互能力。
-
- 开源 NLP 工具包:NLTK(Natural Language Toolkit)和 SpaCy 等开源 NLP 工具包,提供了丰富的文本处理功能,如词性标注、命名实体识别、文本分类等。在数字人开发中,可借助这些工具对用户输入文本进行预处理和分析,提取关键信息,为后续的对话决策和回复生成提供支持。
- 计算机视觉:
-
- 面部表情识别:基于卷积神经网络(CNN)的面部表情识别技术已较为成熟。通过在大规模面部表情数据集上进行训练,如 FER2013、CK + 等数据集,CNN 模型能够准确识别出人类面部的多种表情,如高兴、悲伤、愤怒、惊讶等。在数字人系统中,利用面部表情识别技术,可实现根据用户表情实时驱动数字人做出相应表情反应,增强交互的自然性和情感共鸣。
-
- 人体姿态估计:OpenPose、MediaPipe 等开源框架提供了高效的人体姿态估计算法。这些算法通过对视频图像中的人体关键点进行检测和跟踪,能够实时获取人体的姿态信息。将人体姿态估计技术应用于数字人开发,可实现数字人对用户动作的模仿,如在虚拟健身场景中,数字人能够实时跟随用户的健身动作进行演示,提升用户体验。
语音技术
- 语音合成(TTS):
-
- 商业 TTS 引擎:科大讯飞的星火语音合成、百度的 Deep Voice 等商业 TTS 引擎,在语音合成质量和自然度方面表现出色。这些引擎提供了多种音色选择,可根据数字人的角色定位和个性特点,选择合适的语音音色。例如,对于虚拟客服数字人,可选择清晰、亲切的语音音色;对于虚拟主播数字人,可选择富有感染力、表现力的语音音色。
-
- 开源 TTS 框架:如 Festival、MaryTTS 等开源 TTS 框架,为开发者提供了定制化语音合成的可能性。通过对开源框架的二次开发,可根据特定需求训练个性化的语音模型,实现具有独特风格的语音合成效果。
- 语音识别(ASR):
-
- 主流 ASR 平台:Google Cloud Speech - to - Text、Microsoft Azure Speech 等主流语音识别平台,具有较高的语音识别准确率和广泛的语言支持。在数字人应用中,接入这些平台可实现对用户语音输入的快速准确识别,将语音转换为文本,为后续的自然语言处理和对话交互奠定基础。
-
- 开源 ASR 工具:Kaldi 是一款开源的语音识别工具包,提供了丰富的语音识别模型训练和部署工具。通过利用 Kaldi 进行自定义语音识别模型的训练,可针对特定领域的语音数据进行优化,提高语音识别在该领域的准确率,如在医疗领域,训练专门识别医学术语的语音识别模型。
系统架构设计
- 分层架构:
-
- 感知层:负责采集和处理来自用户的输入信息,包括语音输入、图像输入(用于面部表情和姿态识别)等。通过语音识别、计算机视觉等技术,将原始输入数据转换为计算机能够理解的语义信息,如文本、表情标签、姿态数据等。
-
- 交互层:基于感知层获取的信息,进行自然语言处理和对话管理。利用 NLP 技术理解用户的意图,根据对话策略生成相应的回复文本,并结合语音合成技术将回复文本转换为语音输出。同时,根据用户的表情和姿态信息,驱动数字人做出相应的表情和动作反应,实现与用户的自然交互。
-
- 呈现层:主要负责数字人的图形渲染和展示。通过实时渲染引擎,将数字人的模型、动画、材质等资源进行整合和渲染,生成最终的可视化图像或视频,并输出到用户设备上。呈现层还需考虑与硬件设备的兼容性和性能优化,确保数字人在不同设备上都能流畅运行,呈现出高质量的视觉效果。
- 分布式架构:
-
- 随着数字人应用规模的扩大和功能的复杂化,分布式架构逐渐成为一种趋势。在分布式架构中,将数字人系统的各个功能模块,如语音识别、自然语言处理、图形渲染等,部署在不同的服务器节点上,通过网络进行通信和协作。这样可以充分利用分布式计算的优势,提高系统的处理能力和可扩展性。例如,将语音识别和自然语言处理模块部署在高性能的计算服务器上,以快速处理大量的语音和文本数据;将图形渲染模块部署在具有强大图形处理能力的 GPU 服务器上,确保数字人的高质量渲染效果。同时,通过负载均衡技术,合理分配各个服务器节点的任务,避免单点故障,提高系统的可靠性和稳定性。
核心模块开发与代码实现
数字人模型构建与动画驱动
- 3D 模型创建与导入:
-
- 使用 3D 建模软件(如 Blender 或 Maya)创建数字人的基础模型,包括身体、面部、头发等部分。在建模过程中,注重模型的拓扑结构,确保模型在动画制作和渲染时的高效性。例如,在面部建模时,合理分布顶点,以便在表情动画制作时能够准确地模拟肌肉运动。完成模型创建后,将模型导出为适合实时渲染引擎(如 Unity 或 Unreal Engine)导入的文件格式,如 FBX 格式。
-
- 在 Unity 中导入数字人模型的代码示例(C#):
using UnityEngine;
public class ModelImporter : MonoBehaviour
{
public string modelPath = "Assets/Models/DigitalHuman.fbx";
void Start()
{
GameObject digitalHuman = (GameObject)AssetDatabase.LoadAssetAtPath(modelPath, typeof(GameObject));
if (digitalHuman!= null)
{
Instantiate(digitalHuman, transform.position, transform.rotation);
}
else
{
Debug.LogError("无法加载数字人模型");
}
}
}
- 骨骼绑定与动画制作:
-
- 在 3D 建模软件中为数字人模型添加骨骼系统,并进行骨骼绑定。通过设置骨骼的层级关系、关节属性和权重,使模型能够跟随骨骼的运动而变形。例如,在 Maya 中,使用 Skin Cluster 工具进行模型蒙皮,将模型的顶点与骨骼进行关联,并调整权重以实现自然的变形效果。
-
- 制作数字人的动画,包括行走、奔跑、站立、表情变化等基本动画。可以通过关键帧动画、动作捕捉数据导入等方式创建动画。在 Unity 中,利用 Animator 组件和动画控制器创建动画状态机,实现动画的切换和混合。例如,以下代码实现了数字人在不同动画状态之间的切换:
using UnityEngine;
public class AnimationController : MonoBehaviour
{
private Animator animator;
void Start()
{
animator = GetComponent<Animator>();
}
void Update()
{
if (Input.GetKeyDown(KeyCode.W))
{
animator.SetBool("IsWalking", true);
}
else if (Input.GetKeyUp(KeyCode.W))
{
animator.SetBool("IsWalking", false);
}
if (Input.GetKeyDown(KeyCode.Space))
{
animator.SetTrigger("Jump");
}
}
}
- 表情驱动实现:
-
- 基于计算机视觉的面部表情识别技术,获取用户的表情信息。在 Unity 中,可使用 OpenCV for Unity 等库实现面部表情识别功能。例如,以下代码示例展示了如何使用 OpenCV for Unity 检测面部表情:
using UnityEngine;
using OpenCVForUnity;
public class FacialExpressionDetection : MonoBehaviour
{
private Mat frameMat;
private CascadeClassifier faceCascade;
private MatOfRect faceDetections;
void Start()
{
string faceCascadePath = Application.dataPath + "/StreamingAssets/haarcascade_frontalface_alt.xml";
faceCascade = new CascadeClassifier(faceCascadePath);
frameMat = new Mat();
faceDetections = new MatOfRect();
}
void Update()
{
// 假设这里从摄像头获取图像数据并转换为Mat格式
// 实际应用中需根据具体的摄像头插件实现
// 这里简单示例,假设已有图像数据存储在frameMat中
faceCascade.detectMultiScale(frameMat, faceDetections);
foreach (Rect face in faceDetections.toArray())
{
// 这里可进一步进行表情识别算法处理
// 简单示例,检测到人脸后打印提示信息
Debug.Log("检测到人脸");
}
}
void OnDestroy()
{
faceCascade.release();
frameMat.release();
faceDetections.release();
}
}
- 根据识别到的表情信息,驱动数字人的面部表情动画。在 Unity 中,可以通过修改面部骨骼的权重或使用 Blend Shape(混合形状)技术来实现表情驱动。例如,通过设置不同的 Blend Shape 权重值,实现数字人的高兴、悲伤、愤怒等表情变化:
using UnityEngine;
public class FacialExpressionDriver : MonoBehaviour
{
public SkinnedMeshRenderer skinnedMeshRenderer;
public int happyBlendShapeIndex = 0;
public int sadBlendShapeIndex = 1;
void Update()
{
// 假设这里根据表情识别结果获取表情标签
// 简单示例,假设表情标签为"happy"
string detectedExpression = "happy";
if (detectedExpression == "happy")
{
skinnedMeshRenderer.SetBlendShapeWeight(happyBlendShapeIndex, 100f);
skinnedMeshRenderer.SetBlendShapeWeight(sadBlendShapeIndex, 0f);
}
else if (detectedExpression == "sad")
{
skinnedMeshRenderer.SetBlendShapeWeight(happyBlendShapeIndex, 0f);
skinnedMeshRenderer.SetBlendShapeWeight(sadBlendShapeIndex, 100f);
}
}
}
自然语言处理与对话交互
- 自然语言处理模块集成:
-
- 以 Hugging Face 的 Transformers 库为例,在 Python 中集成自然语言处理模型实现文本分类功能。首先安装 Transformers 库,然后加载预训练的文本分类模型,如 BERT 模型:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained('bert - base - uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert - base - uncased')
def classify_text(text):
inputs = tokenizer(text, return_tensors='pt')
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim = 1)
return prediction.item()
- 在数字人系统中,将自然语言处理模块与对话管理模块相结合,实现对用户输入文本的理解和意图识别。例如,根据用户输入的文本,判断用户的问题类型(如咨询、指令、闲聊等),并根据问题类型调用相应的回答策略。
- 对话管理与回复生成:
-
- 构建对话状态跟踪器,记录对话历史和当前状态。对话状态跟踪器可以使用基于规则的方法或机器学习方法实现。例如,使用基于规则的对话状态跟踪器,根据用户的输入和当前对话状态,更新对话状态并生成相应的回复。以下是一个简单的基于规则的对话状态跟踪器示例:
class DialogueStateTracker:
def __init__(self):
self.state = "start"
def update_state(self, user_input):
if self.state == "start":
if "你好" in user_input:
self.state = "greeting"
return "你好!有什么我可以帮助你的?"
else:
self.state = "unknown"
return "不太明白你的意思,请重新表述。"
elif self.state == "greeting":
if "问题" in user_input:
self.state = "question"
return "请描述你的问题。"
else:
self.state = "unknown"
return "不太理解你的意图。"
elif self.state == "question":
# 这里可进一步实现根据问题类型调用相应的回答生成逻辑
return "已收到你的问题,正在处理中..."
else:
return "当前状态无法处理该输入。"
- 利用自然语言生成技术,根据对话状态和用户意图生成回复文本。可以使用基于模板的方法、序列到序列模型(如 GPT - Neo)等实现回复生成。例如,使用基于模板的回复生成方法,根据问题类型选择相应的回复模板,并填充模板中的变量:
reply_templates = {
"greeting": "你好!有什么我可以帮助你的?",
"question": "关于你的问题,答案是:{answer}"
}
def generate_reply(question_type, **kwargs):
if question_type in reply_templates:
template = reply_templates[question_type]
if "answer" in kwargs:
return template.format(answer = kwargs["answer"])
else:
return template
else:
return "无法生成回复。"
- 语音交互实现:
-
- 在 Unity 中集成语音识别和语音合成功能,实现数字人的语音交互。使用 Unity 的 Text - to - Speech(TTS)功能和第三方语音识别 SDK(如科大讯飞的语音识别 SDK)。以下是一个简单的语音交互实现示例,使用科大讯飞的语音识别 SDK 实现语音输入识别,并将识别结果发送到自然语言处理模块进行处理: