0、概述
经过前面几篇数据库的数据库设计与优化的铺垫之后,一直想着开始进行真正的SQL的优化分析,但是细想下来,还有些工作没有做:其一,数据库管理系统的基本构成全貌,目前仍然缺失的,一直在细节内打转,难免陷入管窥蠡测的困境;其二,对动态的SQL执行大体情况,也是需要进行相应的补充。之后,才能更好地把握数据库的优化。
1、数据库管理系统的构成
首先,从整体上看下一个典型的数据库管理系统的构成:

关于这张图,不用太多地纠结其中的细节,只需要在脑海中有个大概得印象,在后续的不断优化实践中,逐步加深对该结构图的理解,甚至不断自己添加更多的细节,我觉得是更好的提升方式。
这里重点看左侧那一栏,前面几篇关于数据库的文章,主要介绍了索引、缓冲区、存储管理器、外存相关的概念。暂时缺失的部分,从用户/应用的提交到执行引擎执行之间的部分。
2、数据库查询的执行
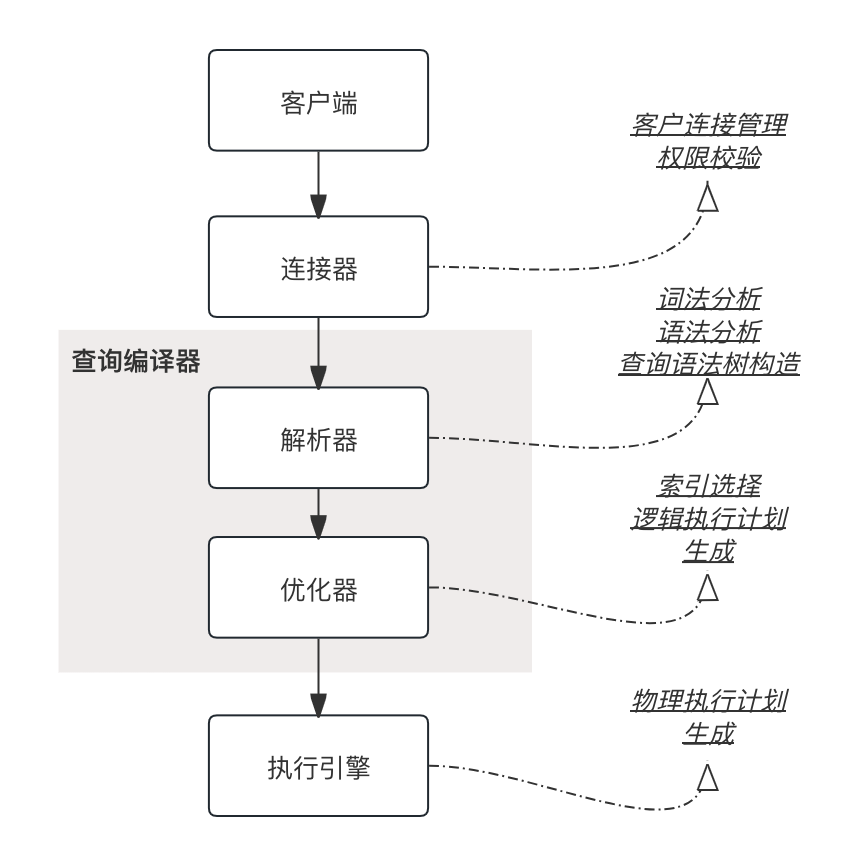
如图所示,主流的数据关于一条SQL查询语句的执行,一般要经过这些步骤:
-
客户端通过连接器完成客户连接的建立,连接器同时进行客户权限的校验与连接的管理
-
解析器需要将客户端提交的SQL语句进行词法分析与语法分析,构建查询语法树,校验是否SQL语句存在语法上的错误
-
优化器基于查询语法树,结合统计信息、元数据等进行索引的选择,生成逻辑执行计划
-
执行引擎基于逻辑执行计划生成物理执行计划,物理执行计划包括算法的选择,基本算子的转换组合等
需要注意的是,有些地方把解析器和优化器统称为查询编译器,类似于编程语言的编译,然后执行的叙述方法。
此外,对于类似于MySQL的数据库,分为Server层和存储引擎层,Server层中的执行器需要调用存储引擎来进行最终的物理查询计划的执行。
3、物理查询计划的基本算子
需要明确的,在我们当前的语境中,所谓的主流数据库管理系统一般指的是关系型数据库管理系统(RDBMS)。
而RDBMS的设计原理的核心是关系代数,所以在RDBMS中,每一条查询语句,都可以转换为一组基本关系代数运算的排列组合。常见的关系代数运算有:选择、投影、连接、积、交、并、差等。
物理查询计划中,则通过存储管理器的一些基本算子组合实现对应的关系代数运算,继而排列组合,最终构建出与查询SQL语句等价的物理查询计划。
物理查询计划中的基本算子主要有:
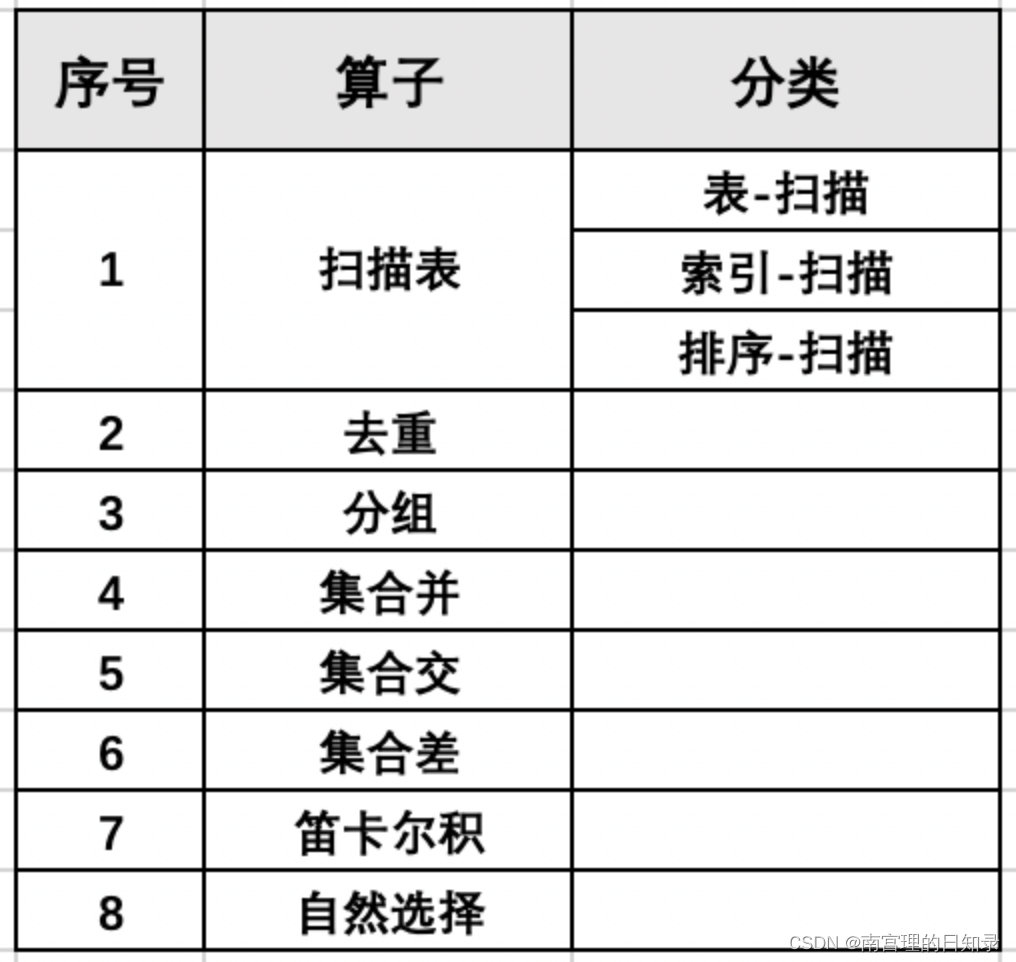
基本是与关系代数运算是一一对应的。其中,扫描表是最基础、最核心的算子,其他算子都需要基于该算子进行实现。
4、核心算法
迭代器
由于数据库表的存储通常是在外存中,而且是物理上是以数据块为单位进行连续存储的,所以主要的算子都可以使用迭代器的方式进行算法的实现。
通常意义上,迭代器由3个方法组成:
-
Open():用于启动获得数据元组(即表数据记录)的过程,但并不真正获得元组,主要执行需要获取元组的相关初始化
-
GetNext():返回下一个元组,并且对数据结构做必要的调整,以便进行后续的操作。如果过已经迭代完成,没有更多的元组了,这时可以返回一个特殊值NotFound,确保不会与任何元组混淆
-
Close():执行终结迭代相关的清理工作
两阶段多路归并排序(Two-Phase Multiway Merge-Sort, TPMMS)
虽然,我们在前面反复提到,数据库设计与优化的指导原则是尽量减少IO操作,但是在数据量过大,无法在内存中完成SQL所需的计算工作时,为了确保SQL能够被正确执行,反而需要更多的借助磁盘,不可避免地,自然会增加磁盘IO操作。
其中,TPMMS就是其中,最基础、最核心的算法:
-
阶段1:不断将数据库表中的每个元组子集放入内存缓冲区,利用主存排序算法对它们进行排序,然后将排序后得到的有序子表存储到外存中
-
阶段2:将多个排序好的子表进行归并操作,此时,为每个局部有序的子表各分配一个内存输入缓冲区,将数据按序分步加载到各自的输入缓冲区,从多个输入缓冲区中选择最小的(假设是进行升序排序),加载到输出缓冲区。输出缓冲区中的数据一定是全局有序的,可以立马返回给客户端的数据段。

基于TPMMS的两趟算法的扩展
虽然TPMMS是基于外存的多路归并排序而实现的排序算法,但是借助外存进行的多路归并的策略,可以更广泛地应用于数据库各种基本算子的二趟算法中。
算法分类:
基于能否借助内存只需要从磁盘读取每个数据一次,将相关的查询算子的实现算法分为一趟算法(one-pass)、两趟算法,以及多趟算法。通常两趟算法对大多数场景,已经够用,多趟算法基于二趟算法可以轻易推导出来。
在数据库基本算子的实现算法中,又可以按照具体实现,分为以下三类:
-
基于排序的算法
-
基于散列的算法
-
基于索引的算法
二趟排序中,基于排序的去重、基于排序的分组、基于排序的集合运算等,都类似于TPMMS的实现逻辑。
此外,基于散列的去重、基于散列的分组、基于散列的集合运算等,也类似于TPMMS的实现,只是各个子表不是进行排序,而是基于哈希操作,将数据分为多个子表,每个子表的哈希值相同而已。
关于数据库查询中,最常用的数据库连接操作的具体实现,也是基于一趟算法的嵌套循环、二趟排序、二趟散列等的组合实现,具体实现在这篇文章中就不再展开。
5、参考书籍
1、《数据库系统实现(第2版)》