数据准备
数据使用hive提取,此处不做说明
spark.sql读取hive表
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.enableHiveSupport() \
.appName("predict_sale") \
.getOrCreate()
sc = spark.sparkContext
log_data = spark.sql("select * from mytable").collect()
训练集,验证集和测试集X,y生成
import pandas as pd
##实际特征很多,此步骤只是样例
columns_str = ['id', 'x1', 'x2', 'x3', 'day_id','y']
log_data_df = pd.DataFrame(log_data, columns=columns_str)
##此处对y值做了一个log平滑
log_data_df['y'] = np.log1p(log_data_df['y'] + 1)
log_data_df_train = log_data_df[log_data_df.day_id >= 3]
log_data_df_val = log_data_df[log_data_df.day_id == 2]
log_data_df_test = log_data_df[log_data_df.day_id == 1]
feature_columns_str = ['id', 'x1', 'x2', 'x3', 'day_id']
X_train = log_data_df_train.loc[:, feature_columns_str]
y_train = log_data_df_train.loc[:, 'y']
X_val = log_data_df_val.loc[:, feature_columns_str]
y_val = log_data_df_val.loc[:, 'y']
X_test = log_data_df_test.loc[:, feature_columns_str]
xgboost算法参数设置和训练
from xgboost import XGBRegressor
n_estimators=1000
model = XGBRegressor(
silent=1,
max_depth=8,
n_estimators=n_estimators,
min_child_weight=200,
colsample_bytree=0.8,
subsample=0.8,
eta=0.3,
seed=42)
model.fit(
X_train,
y_train,
eval_metric="rmse",
eval_set=[(X_train, y_train), (X_val, y_val)],
verbose=True,
early_stopping_rounds=10)
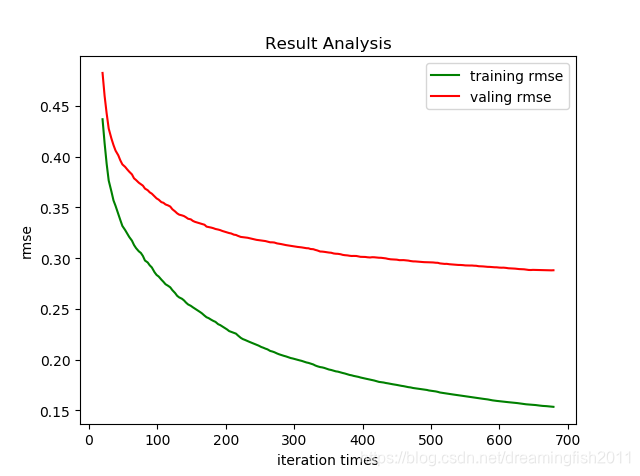
训练集合验证集rmse绘图
import numpy as np
import matplotlib.pyplot as plt
##模型训练每次的评估结果都保存在一个字典里,依据此绘图
eval_dict= model.evals_result()
val0 = eval_dict['validation_0']['rmse']
val1 = eval_dict['validation_1']['rmse']
# logger.error(cv_output)
x_list = np.linspace(20, len(val0), num=200, dtype=int, endpoint=False)
print(x_list)
y_val0 = [val0[x] for x in x_list]
y_val1 = [val1[x] for x in x_list]
# 开始画图
plt.title('Result Analysis')
plt.plot(x_list, y_val0, color='green', label='training rmse')
plt.plot(x_list, y_val1, color='red', label='valing rmse')
plt.legend() # 显示图例
plt.xlabel('iteration times')
plt.ylabel('rmse')
plt.show()
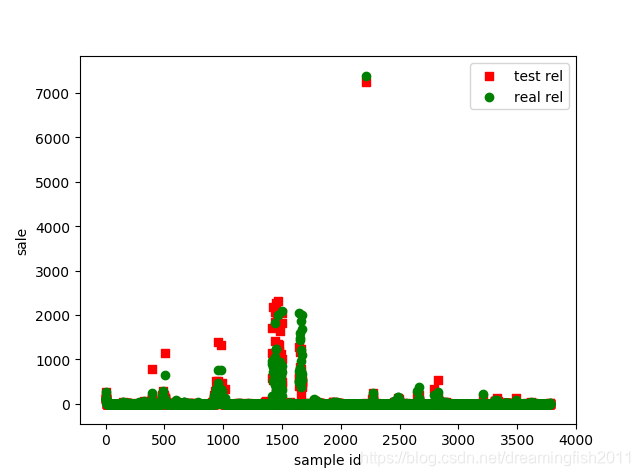
##预测并恢复y值
Y_pred = np.expm1(model.predict(X_val)).round() - 1
##实验中为了绘制测试样例的结果,测试样例也是存在真实值的
Y_test = np.expm1(model.predict(X_test)).round() - 1
Y_real = np.expm1(log_data_df_test.loc[:, 'y']).round() - 1
plt.scatter(range(Y_test.shape[0]),Y_test,marker=',',color='red', label='test rel')
plt.scatter(range(Y_real.shape[0]),Y_real,marker='o',color='green', label='real rel')
plt.legend()
plt.xlabel('sample id')
plt.ylabel('sale')
plt.show()
预测结果保存
submission = pd.DataFrame({
"id": X_test['id'],
"y": Y_test
})
#保存至csv,columns可以保证csv文件中的列顺序
submission.to_csv('xgb_submission.csv', index=False,columns=['id','y'])
# 保存至hive表
schemaRow = spark.createDataFrame(submission)
month_str = '2018_12_11'
temptablename = "temp_" + month_str
tablename = "last_" + month_str
schemaRow .createOrReplaceTempView(temptablename)
spark.sql("select * from " + temptablename).show(10)
spark.sql("drop table if exists " + tablename )
spark.sql("create table " + tablename + " as select id,y from " + temptablename)
待改进
本文只是一个初步尝试xgboost做预测。从图上看出,预测结果并不好,还有很多优化空间,后续慢慢研究改进