一.使用的技术栈
1). 用户层
本项目中在构建系统管理后台的前端页面,我们会用到H5、Vue.js、ElementUI等技术。而在构建移动端应用时,我们会使用到微信小程序。
2). 网关层
Nginx是一个服务器,主要用来作为Http服务器,部署静态资源,访问性能高。在Nginx中还有两个比较重要的作用: 反向代理和负载均衡, 在进行项目部署时,要实现Tomcat的负载均衡,就可以通过Nginx来实现。
3). 应用层
SpringBoot: 快速构建Spring项目, 采用 “约定优于配置” 的思想, 简化Spring项目的配置开发。
Spring: 统一管理项目中的各种资源(bean), 在web开发的各层中都会用到。
SpringMVC:SpringMVC是spring框架的一个模块,springmvc和spring无需通过中间整合层进行整合,可以无缝集成。
SpringSession: 主要解决在集群环境下的Session共享问题。
lombok:能以简单的注解形式来简化java代码,提高开发人员的开发效率。例如开发中经常需要写的javabean,都需要花时间去添加相应的getter/setter,也许还要去写构造器、equals等方法。
Swagger: 可以自动的帮助开发人员生成接口文档,并对接口进行测试。
4). 数据层
MySQL: 关系型数据库, 本项目的核心业务数据都会采用MySQL进行存储。
MybatisPlus: 本项目持久层将会使用MybatisPlus来简化开发, 基本的单表增删改查直接调用框架提供的方法即可。
Redis: 基于key-value格式存储的内存数据库, 访问速度快, 经常使用它做缓存(降低数据库访问压力, 提供访问效率), 在后面的性能优化中会使用。
5). 工具
git: 版本控制工具, 在团队协作中, 使用该工具对项目中的代码进行管理。
maven: 项目构建工具。
junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。
6). pom文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-core</artifactId>
<version>4.5.16</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-dysmsapi</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.4.5</version>
</plugin>
</plugins>
</build>
</project>
二.关于一些注解的使用
2.1启动类的注解
@Slf4j //是lombok中提供的注解, 用来通过slf4j记录日志。
@SpringBootApplication //标注是springboot项目的启动类,自动把配置组件等资源进行加载
@ServletComponentScan//在SpringBoot项目中, 在引导类/配置类上加了该注解后, 会自动扫描项目中(当前包及其子包下)的@WebServlet , @WebFilter , @WebListener 注解, 自动注册Servlet的相关组件 ;
@EnableTransactionManagement //开启对事物管理的支持,在service的实现类中加入@Transactional即可
public class ReggieApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieApplication.class,args);
log.info("项目启动成功...");
}
}
2.2处理全局异常类的注解
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import java.sql.SQLIntegrityConstraintViolationException;
/**
* 全局异常处理
*/
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
/**
* 异常处理方法
* @return
*/
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)//指定哪个异常类被处理
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.error(ex.getMessage());
if(ex.getMessage().contains("Duplicate entry")){
String[] split = ex.getMessage().split(" ");
String msg = split[2] + "已存在";
return R.error(msg);
}
return R.error("未知错误");
}
}
注解说明:
上述的全局异常处理器上使用了的两个注解 @ControllerAdvice , @ResponseBody , 他们的作用分别为:
@ControllerAdvice : 指定拦截那些类型的控制器;
@ResponseBody: 将方法的返回值 R 对象转换为json格式的数据, 响应给页面;
上述使用的两个注解, 也可以合并成为一个注解 @RestControllerAdvice
三.一些通用的封装方法以及配置
3.1application.yml
server:
port: 8080
spring:
application:
#应用名称 , 可选
name: reggie_take_out
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: root
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 address_book ---> AddressBook
map-underscore-to-camel-case: true
#日志输出
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
这个是springboot的核心配置文件,可以注明启动的端口,使用数据库的连接信息以及其他的一些配置信息
3.2 WebMvcConfig
@Slf4j
@Configuration //标明为注解类
public class WebMvcConfig extends WebMvcConfigurationSupport {
/**
* 设置静态资源映射
* @param registry
*/
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始进行静态资源映射...");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
}
用于在Springboot项目中, 默认静态资源的存放目录为 : “classpath:/resources/”, “classpath:/static/”, “classpath:/public/” ; 而在我们的项目中静态资源存放在 backend, front 目录中, 那么这个时候要想访问到静态资源, 就需要设置静态资源映射。
3.3返回通用结果集
/**
* 通用返回结果,服务端响应的数据最终都会封装成此对象
* @param <T>
*/
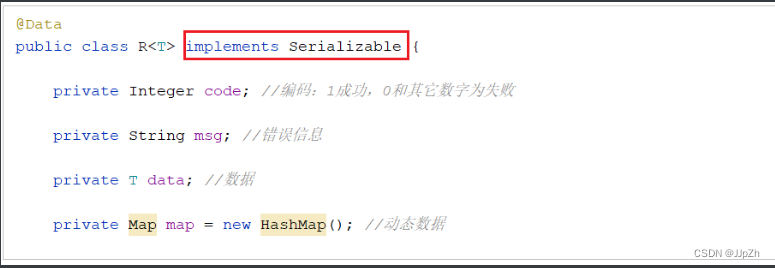
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
3.4登录校验过滤器
/**
* 检查用户是否已经完成登录
*/
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter{
//路径匹配器,支持通配符
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//1、获取本次请求的URI
String requestURI = request.getRequestURI();// /backend/index.html
log.info("拦截到请求:{}",requestURI);
//定义不需要处理的请求路径
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
//2、判断本次请求是否需要处理
boolean check = check(urls, requestURI);
//3、如果不需要处理,则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
//4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee") != null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;
}
log.info("用户未登录");
//5、如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配,检查本次请求是否需要放行
* @param urls
* @param requestURI
* @return
*/
public boolean check(String[] urls,String requestURI){
for (String url : urls) {
boolean match = PATH_MATCHER.match(url, requestURI);
if(match){
return true;
}
}
return false;
}
}
AntPathMatcher 拓展:
介绍: Spring中提供的路径匹配器 ;
通配符规则:
符号 含义 ? 匹配一个字符 * 匹配0个或多个字符 ** 匹配0个或多个目录/字符
3.5全局异常处理器
/**
* 全局异常处理
*/
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
/**
* 异常处理方法
* @return
*/
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.error(ex.getMessage());
if(ex.getMessage().contains("Duplicate entry")){
String[] split = ex.getMessage().split(" ");
String msg = split[2] + "已存在";
return R.error(msg);
}
return R.error("未知错误");
}
}
3.6MybatisPlus的分页插件配置(留坑,还有没有其他办法?)
/**
* 配置MP的分页插件
*/
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
}
3.7对消息转换器的功能进行拓展(解决int型超长的失去精度的问题)
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(BigInteger.class, ToStringSerializer.instance)
.addSerializer(Long.class, ToStringSerializer.instance)
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
该自定义的对象转换器, 主要指定了, 在进行json数据序列化及反序列化时, LocalDateTime、LocalDate、LocalTime的处理方式, 以及BigInteger及Long类型数据,直接转换为字符串。然后在WebMvcConfig配置类中扩展Spring mvc的消息转换器,在此消息转换器中使用提供的对象转换器进行Java对象到json数据的转换
/**
* 扩展mvc框架的消息转换器
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
//创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转换器,底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合中
converters.add(0,messageConverter);
}
3.8公共字段填充
1). 实体类的属性上加入@TableField注解,指定自动填充的策略。
2). 按照框架要求编写元数据对象处理器,在此类中统一为公共字段赋值,此类需要实现MetaObjectHandler接口。

/**
* 自定义元数据对象处理器
*/
@Component
@Slf4j
public class MyMetaObjecthandler implements MetaObjectHandler {
/**
* 插入操作,自动填充
* @param metaObject
*/
@Override
public void insertFill(MetaObject metaObject) {
log.info("公共字段自动填充[insert]...");
log.info(metaObject.toString());
metaObject.setValue("createTime", LocalDateTime.now());
metaObject.setValue("updateTime",LocalDateTime.now());
metaObject.setValue("createUser",new Long(1));
metaObject.setValue("updateUser",new Long(1));
}
/**
* 更新操作,自动填充
* @param metaObject
*/
@Override
public void updateFill(MetaObject metaObject) {
log.info("公共字段自动填充[update]...");
log.info(metaObject.toString());
metaObject.setValue("updateTime",LocalDateTime.now());
metaObject.setValue("updateUser",new Long(1));
}
}
特别提醒:
我们在MyMetaObjectHandler类中是不能直接获得HttpSession对象的,所以我们需要通过其他方式来获取登录用户id。解决方案看3.9
3.9ThreadLocal保存用户id
ThreadLocal并不是一个Thread,而是Thread的局部变量。当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问当前线程对应的值。
ThreadLocal常用方法:
A. public void set(T value) : 设置当前线程的线程局部变量的值
B. public T get() : 返回当前线程所对应的线程局部变量的值
C. public void remove() : 删除当前线程所对应的线程局部变量的值
我们可以在LoginCheckFilter的doFilter方法中获取当前登录用户id,并调用ThreadLocal的set方法来设置当前线程的线程局部变量的值(用户id),然后在MyMetaObjectHandler的updateFill方法中调用ThreadLocal的get方法来获得当前线程所对应的线程局部变量的值(用户id)。 如果在后续的操作中, 我们需要在Controller / Service中要使用当前登录用户的ID, 可以直接从ThreadLocal直接获取。
/**
* 基于ThreadLocal封装工具类,用户保存和获取当前登录用户id
*/
public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
/**
* 设置值
* @param id
*/
public static void setCurrentId(Long id){
threadLocal.set(id);
}
/**
* 获取值
* @return
*/
public static Long getCurrentId(){
return threadLocal.get();
}
}
4.0文件上传和下载
/**
* 文件上传和下载
*/
@RestController
@RequestMapping("/common")
@Slf4j
public class CommonController {
@Value("${pengge.path}")//从配置文件中找值
private String basePath;
/**
* 文件上传
* @param file
* @return
*/
@PostMapping("/upload")
public R<String> upload(MultipartFile file){
//file是一个临时文件,需要转存到指定位置,否则本次请求完成后临时文件会删除
log.info(file.toString());
//原始文件名
String originalFilename = file.getOriginalFilename();//abc.jpg
String suffix = originalFilename.substring(originalFilename.lastIndexOf("."));
//使用UUID重新生成文件名,防止文件名称重复造成文件覆盖
String fileName = UUID.randomUUID().toString() + suffix;//dfsdfdfd.jpg
//解决jar包运行时,文件上传路径问题,我部署的时候是这么写的,因为当时上传不了,
我就搜了一下,最后发现是启动权限不够,没有文件修改权限,用root用户启动了就好了。
我感觉注释掉的代码跟这个应该是一模一样的。
File dest = new File(basePath + fileName);
if(!dest.getParentFile().exists()){
dest.getParentFile().mkdirs();
}
try {
file.transferTo(dest);
return R.success(fileName);
} catch (Exception e) {
e.printStackTrace();
return R.error("文件上传失败");
}
// //创建一个目录对象
// File dir = new File(basePath);
// //判断当前目录是否存在
// if(!dir.exists()){
// //目录不存在,需要创建
// dir.mkdirs();
// }
//
// try {
// //将临时文件转存到指定位置
// file.transferTo(new File(basePath + fileName));
// } catch (Exception e) {
// e.printStackTrace();
// }
// return R.success(fileName);
}
/**
* 文件下载
* @param name
* @param response
*/
@GetMapping("/download")
public void download(String name, HttpServletResponse response){
try {
//输入流,通过输入流读取文件内容
FileInputStream fileInputStream = new FileInputStream(new File(basePath + name));
//输出流,通过输出流将文件写回浏览器
ServletOutputStream outputStream = response.getOutputStream();
response.setContentType("image/jpeg");
int len = 0;
byte[] bytes = new byte[1024];
while ((len = fileInputStream.read(bytes)) != -1){
outputStream.write(bytes,0,len);
outputStream.flush();
}
//关闭资源
outputStream.close();
fileInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
四。一些重要的或复杂或有特色的代码逻辑
4.1编写Redis的配置类RedisConfig
1). 在SpringBoot工程启动时, 会加载一个自动配置类 RedisAutoConfiguration, 在里面已经声明了RedisTemplate这个bean
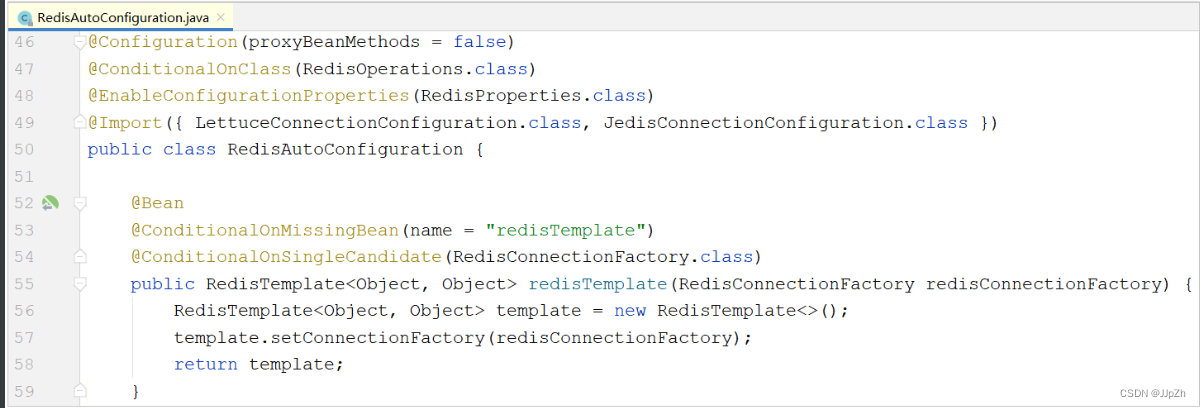
上述框架默认声明的RedisTemplate用的key和value的序列化方式是默认的 JdkSerializationRedisSerializer,如果key采用这种方式序列化,最终我们在测试时通过redis的图形化界面查询不是很方便,如下形式:
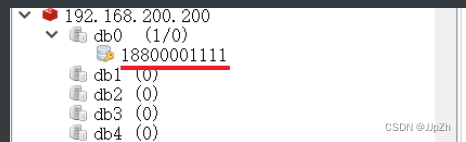
2). 如果使用我们自定义的RedisTemplate, key的序列化方式使用的是StringRedisSerializer, 也就是字符串形式, 最终效果如下:
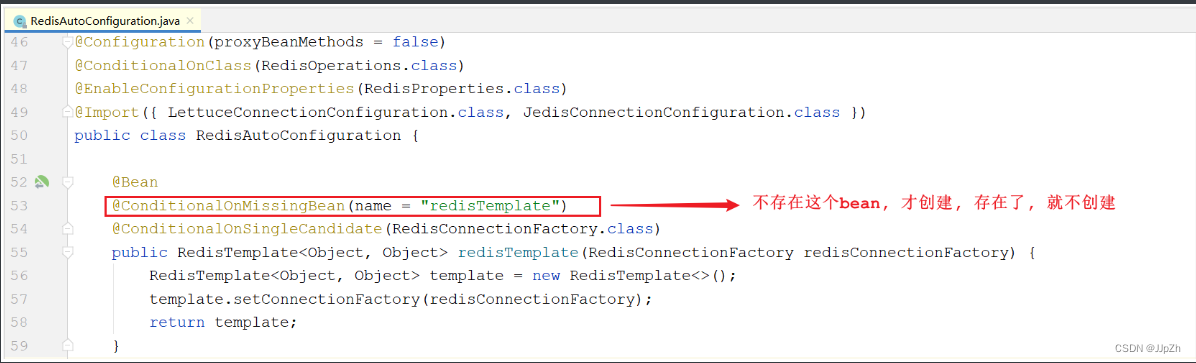
3). 定义了两个bean会不会出现冲突呢? 答案是不会, 因为源码如下:
配置代码如下:

@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
4.2 Spring cache的使用
Spring cache是代码级的缓存,一般是使用一个ConcurrentMap,也就是说实际上还是是使用JVM的内存来缓存对象的,这势必会造成大量的内存消耗。但好处是显然的:使用方便。
Redis 作为一个缓存服务器,是内存级的缓存。它是使用单纯的内存来进行缓存。
集群环境下,每台服务器的spring cache是不同步的,这样会出问题的,spring cache只适合单机环境。
Redis是设置单独的缓存服务器,所有集群服务器统一访问redis,不会出现缓存不同步的情况。
在SpringCache中提供了很多缓存操作的注解,常见的是以下的几个:
| 注解 | 说明 |
|---|---|
| @EnableCaching | 开启缓存注解功能 |
| @Cacheable | 在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中 |
| @CachePut | 将方法的返回值放到缓存中 |
| @CacheEvict | 将一条或多条数据从缓存中删除 |
在spring boot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。
例如,使用Redis作为缓存技术,只需要导入Spring data Redis的maven坐标即可。
4.2.1.@CachePut注解
@CachePut 说明:
作用: 将方法返回值,放入缓存
value: 缓存的名称, 每个缓存名称下面可以有很多key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
在save方法上加注解@CachePut
当前UserController的save方法是用来保存用户信息的,我们希望在该用户信息保存到数据库的同时,也往缓存中缓存一份数据,我们可以在save方法上加上注解 @CachePut,用法如下:
/**
* CachePut:将方法返回值放入缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@CachePut(value = "userCache", key = "#user.id")
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
key的写法如下:
#user.id : #user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ;
#user.name: #user指的是方法形参的名称, name指的是user的name属性 ,也就是使用user的name属性作为key ;
#result.id : #result代表方法返回值,该表达式 代表以返回对象的id属性作为key ;
#result.name : #result代表方法返回值,该表达式 代表以返回对象的name属性作为key ;
4.2.2.@CacheEvict注解
@CacheEvict 说明:
作用: 清理指定缓存
value: 缓存的名称,每个缓存名称下面可以有多个key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
/**
* CacheEvict:清理指定缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@CacheEvict(value = "userCache",key = "#p0") //#p0 代表第一个参数
//@CacheEvict(value = "userCache",key = "#root.args[0]") //#root.args[0] 代表第一个参数
//@CacheEvict(value = "userCache",key = "#id") //#id 代表变量名为id的参数
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
4.2.3.@Cacheable注解
@Cacheable 说明:
作用: 在方法执行前,spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
value: 缓存的名称,每个缓存名称下面可以有多个key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@Cacheable(value = "userCache",key = "#id")
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
* condition:条件,满足条件时才缓存数据
* unless:满足条件则不缓存
*/
@Cacheable(value = "userCache",key = "#id", unless = "#result == null")
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
@Cacheable(value = "userCache",key = "#user.id + '_' + #user.name")
@GetMapping("/list")
public List<User> list(User user){
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null,User::getName,user.getName());
List<User> list = userService.list(queryWrapper);
return list;
}
4.2.4 集成Redis
在使用上述默认的ConcurrentHashMap做缓存时,服务重启之后,之前缓存的数据就全部丢失了,操作起来并不友好。在项目中使用,我们会选择使用redis来做缓存,主要需要操作以下几步:
1). pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2). application.yml
spring:
redis:
host: 192.168.200.200
port: 6379
password: root@123456
database: 0
cache:
redis:
time-to-live: 1800000 #设置缓存过期时间,可选
因为 @Cacheable 会将方法的返回值R缓存在Redis中,而在Redis中存储对象,该对象是需要被序列化的,而对象要想被成功的序列化,就必须得实现 Serializable 接口。而当前我们定义的R,并未实现 Serializable 接口。所以,要解决该异常,只需要让R实现 Serializable 接口即可。如下: