一、CIFAR-10介绍
CIFAR-10数据集包括6万张32*32大小的彩色图片,该数据集一共有10个类别,每个类别有6千张图片。其中训练数据集图片5万张,测试数据集1万张。
该训练数据集平均分成5个训练批次,每个训练批次1万张图。下载该数据集的链接:http://www.cs.toronto.edu/~kriz/cifar.html
由于本文是基于Python3.6的,所以选择“CIFAR-10 python version”下载。

下载后的文件:
二、卷积整体流程
- 5万张3通道训练图片的原始尺寸32*32
- 为了减少计算量把图像预处理成1通道24*24,当然在硬件配置较好的情况下,此步骤非必须
- 输入(?,24,24,1),经过conv1+pool1后,输出(?,12,12,64)
- 步骤三作为输入,经过conv2+pool2后,输出(?,6,6,64)
- 把输出值(?,6,6,64)转置成一维数组(?,6*6*64)
- 步骤五作为输入,经过FC1后,输出(?,1024)
- 步骤六作为输入,经过FC2后,输出(?,10)
三、代码实现
import pickle
def unpickle(file):
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='latin1')
fo.close()
return dict1、图像预处理:
# 图像预处理
import numpy as np
def clean(data):
# 图像预处理,32*32-->24*24,速度快
imgs = data.reshape(data.shape[0], 3, 32, 32)
grayscale_imgs = imgs.mean(1)
cropped_imgs = grayscale_imgs[:, 4:28, 4:28]
img_data = cropped_imgs.reshape(data.shape[0], -1)
img_size = np.shape(img_data)[1]
means = np.mean(img_data, axis=1)
meansT = means.reshape(len(means), 1)
stds = np.std(img_data, axis=1)
stdsT = stds.reshape(len(stds), 1)
adj_stds = np.maximum(stdsT, 1.0 / np.sqrt(img_size))
normalized = (img_data - meansT) / adj_stds
return normalized2、读取数据:
# 读取数据
def read_data(directory):
names = unpickle('{}/batches.meta'.format(directory))['label_names']
print('names', names)
data, labels = [], []
# 五批数据,data_batch_1...5
for i in range(1, 6):
filename = '{}/data_batch_{}'.format(directory, i)
batch_data = unpickle(filename)
if len(data) > 0:
# data labels拼加
data = np.vstack((data, batch_data['data']))
labels = np.hstack((labels, batch_data['labels']))
else:
data = batch_data['data']
labels = batch_data['labels']
print(np.shape(data), np.shape(labels))
data = clean(data)
data = data.astype(np.float32)
return names, data, labels3、显示数据:
%matplotlib inline
import matplotlib.pyplot as plt
import random
# 针对random.seed()、random.sample()函数的作用,可参考https://blog.csdn.net/duanlianvip/article/details/95214866
random.seed(1)
names, data, labels = read_data('./cifar-10-batches-py')
# 显示数据
def show_some_examples(names, data, labels):
# 创建一个显示窗口
plt.figure()
# 4行4列子图
rows, cols = 4, 4
# 从data中(5W张图)随机获取16个子图索引,并作为一个片段返回
random_idxs = random.sample(range(len(data)), rows * cols)
for i in range(rows * cols):
# 将窗口分为四行四列16个子图
plt.subplot(rows, cols, i + 1)
j = random_idxs[i]
# 图片标题
plt.title(names[labels[j]])
# 格式化图片数组大小
img = np.reshape(data[j, :], (24, 24))
# 绘制图片。cmap,使用灰度图进行表示
plt.imshow(img, cmap='Greys_r')
# 不显示坐标尺寸
plt.axis('off')
# 为多个子图(subplot)自动调整显示的布局
plt.tight_layout()
plt.savefig('cifar_examples.png')
show_some_examples(names, data, labels)输出:
4、查看卷积、RELU、池化的中间过程:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
names, data, labels = read_data('./cifar-10-batches-py')
# 卷积结果
def show_conv_results(data, filename=None):
plt.figure()
# 4行8列子图
rows, cols = 4, 8
for i in range(np.shape(data)[3]):
# 取当前图,图片h,图片w,展示所有图像的特征图
img = data[0, :, :, i]
plt.subplot(rows, cols, i + 1)
plt.imshow(img, cmap='Greys_r', interpolation='none')
plt.axis('off')
if filename:
plt.savefig(filename)
else:
plt.show()
# 权重参数
def show_weights(W, filename=None):
plt.figure()
# 4行8列子图
rows, cols = 4, 8
for i in range(np.shape(W)[3]):
#
img = W[:, :, 0, i]
plt.subplot(rows, cols, i + 1)
plt.imshow(img, cmap='Greys_r', interpolation='none')
plt.axis('off')
if filename:
plt.savefig(filename)
else:
plt.show()输出:
names ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
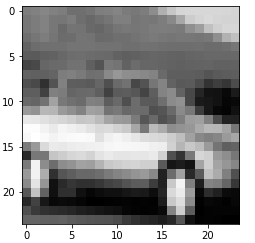
(50000, 3072) (50000,)4.1、 查看索引为4的图片:
raw_data = data[4, :]
raw_img = np.reshape(raw_data, (24, 24))
plt.figure()
plt.imshow(raw_img, cmap='Greys_r')
plt.show()输出:
4.2、查看索引为4的图片被处理的中间过程
x = tf.reshape(raw_data, shape=[-1, 24, 24, 1])
W = tf.Variable(tf.random_normal([5, 5, 1, 32]))
b = tf.Variable(tf.random_normal([32]))
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
conv_with_b = tf.nn.bias_add(conv, b)
conv_out = tf.nn.relu(conv_with_b)
k = 2
maxpool = tf.nn.max_pool(conv_out, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
W_val = sess.run(W)
print('weights:')
show_weights(W_val)
conv_val = sess.run(conv)
print('convolution results:')
print(np.shape(conv_val))
show_conv_results(conv_val)
conv_out_val = sess.run(conv_out)
print('convolution with bias and relu:')
print(np.shape(conv_out_val))
show_conv_results(conv_out_val)
maxpool_val = sess.run(maxpool)
print('maxpool after all the convolutions:')
print(np.shape(maxpool_val))
show_conv_results(maxpool_val)32个W矩阵的可视化输出:

索引为4的图像经过卷积后:

索引为4的图像经过卷积、偏置、RELU后:

索引为4的图像经过卷积、偏置、RELU、池化后:

5、 构建完整的网络模型
# 构建完整的网络模型
x = tf.placeholder(tf.float32, [None, 24 * 24])
y = tf.placeholder(tf.float32, [None, len(names)])
W1 = tf.Variable(tf.random_normal([5, 5, 1, 64]))
b1 = tf.Variable(tf.random_normal([64]))
W2 = tf.Variable(tf.random_normal([5, 5, 64, 64]))
b2 = tf.Variable(tf.random_normal([64]))
W3 = tf.Variable(tf.random_normal([6*6*64, 1024]))
b3 = tf.Variable(tf.random_normal([1024]))
W_out = tf.Variable(tf.random_normal([1024, len(names)]))
b_out = tf.Variable(tf.random_normal([len(names)]))def conv_layer(x, W, b):
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
conv_with_b = tf.nn.bias_add(conv, b)
conv_out = tf.nn.relu(conv_with_b)
return conv_out
def maxpool_layer(conv, k=2):
return tf.nn.max_pool(conv, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')def model():
x_reshaped = tf.reshape(x, shape=[-1, 24, 24, 1])
conv_out1 = conv_layer(x_reshaped, W1, b1)
maxpool_out1 = maxpool_layer(conv_out1)
# 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
# 局部响应层,详情参考:http://blog.csdn.net/banana1006034246/article/details/75204013
norm1 = tf.nn.lrn(maxpool_out1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
conv_out2 =conv_layer(norm1, W2, b2)
norm2 = tf.nn.lrn(conv_out2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
maxpool_out2 =maxpool_layer(norm2)
maxpool_reshaped = tf.reshape(maxpool_out2, [-1, W3.get_shape().as_list()[0]])
local = tf.add(tf.matmul(maxpool_reshaped, W3), b3)
local_out = tf.nn.relu(local)
out = tf.add(tf.matmul(local_out, W_out), b_out)
return out# 试水学习率0.001,可以调整此参数来优化模型训练的效果
learning_rate = 0.001
model_op = model()
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=model_op, labels=y))
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(model_op, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 标签1个值转换成10个概率
# 针对one_hot的使用,可以参考https://blog.csdn.net/duanlianvip/article/details/95184391
onehot_labels = tf.one_hot(labels, len(names), axis=-1)
onehot_vals = sess.run(onehot_labels)
batch_size = 64
print('batch size', batch_size)
# 1000个Epoch,1个Epoch有5W*64张图像
for j in range(0, 1000):
avg_accuracy_val = 0.
batch_count = 0.
for i in range(0, len(data), batch_size):
batch_data = data[i:i+batch_size, :]
batch_onehot_vals = onehot_vals[i:i+batch_size, :]
_, accuracy_val = sess.run([train_op, accuracy], feed_dict={x: batch_data, y: batch_onehot_vals})
avg_accuracy_val += accuracy_val
batch_count += 1.
avg_accuracy_val /= batch_count
print('Epoch {}. Avg accuracy {}'.format(j, avg_accuracy_val))部分输出结果:
batch size 64
Epoch 0. Avg accuracy 0.2292399296675192
Epoch 1. Avg accuracy 0.28380754475703324
Epoch 2. Avg accuracy 0.30570652173913043
Epoch 3. Avg accuracy 0.32149136828644503
Epoch 4. Avg accuracy 0.33320012787723785
Epoch 5. Avg accuracy 0.34800591432225064
Epoch 6. Avg accuracy 0.3562180306905371
Epoch 7. Avg accuracy 0.3654092071611253
Epoch 8. Avg accuracy 0.3759191176470588
Epoch 9. Avg accuracy 0.3850703324808184
Epoch 10. Avg accuracy 0.39695891943734013
Epoch 11. Avg accuracy 0.3998960997442455
Epoch 12. Avg accuracy 0.40025575447570333
Epoch 13. Avg accuracy 0.40988650895140666
Epoch 14. Avg accuracy 0.4163003516624041
Epoch 15. Avg accuracy 0.42451246803069054
Epoch 16. Avg accuracy 0.4205163043478261
Epoch 17. Avg accuracy 0.4351622442455243
Epoch 18. Avg accuracy 0.4343430306905371
Epoch 19. Avg accuracy 0.44027733375959077
Epoch 20. Avg accuracy 0.4500079923273657
Epoch 21. Avg accuracy 0.44888906649616367
Epoch 22. Avg accuracy 0.4554028132992327
Epoch 23. Avg accuracy 0.46117726982097185
Epoch 24. Avg accuracy 0.45818014705882354以上输出结果仅是前24批Epoch,通过观察accuracy值趋势,模型整体呈收敛趋势,1000批Epoch完成之后,模型的成功率可以达到90%以上。
由于我的电脑是ThinkPadX270,没有GPU,所以训练速度较慢,2个多小时才训练完24个Epoch。
由于训练率learning_rate设置的值较小,所以相邻Epoch之间的accuracy变化不大,当然读者可以设置不同的训练率参数,以此查看训练率对模型正确率的影响、收敛程度。