一、问题描述:
当我们配置好MySQL主主同步时,是可以实现主主同步,但是重启机器后或者其他原因导致MySQL无法同步了。二、Slave两个关键进程
mysql replication 中slave机器上有两个关键的进程,死一个都不行,一个是slave_sql_running,一个是Slave_IO_Running,一个负责与主机的io通信,一个负责自己的slave mysql进程。三、如果是Slave_SQL_Running:no:
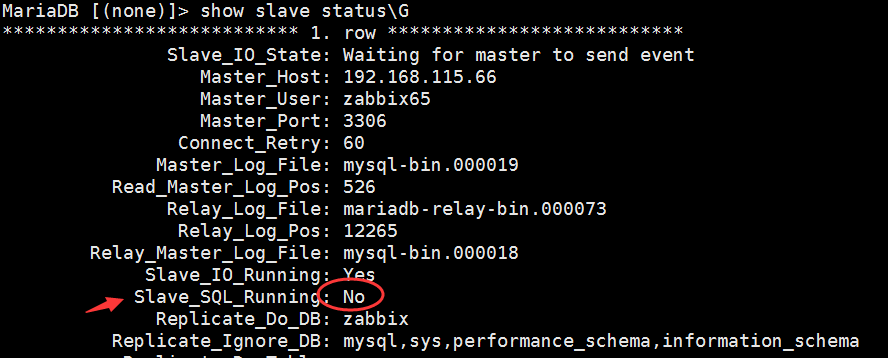
解决办法如下:
MariaDB [(none)]> stop slave;
MariaDB [(none)]> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G 
四、如果是slave_io_running:no
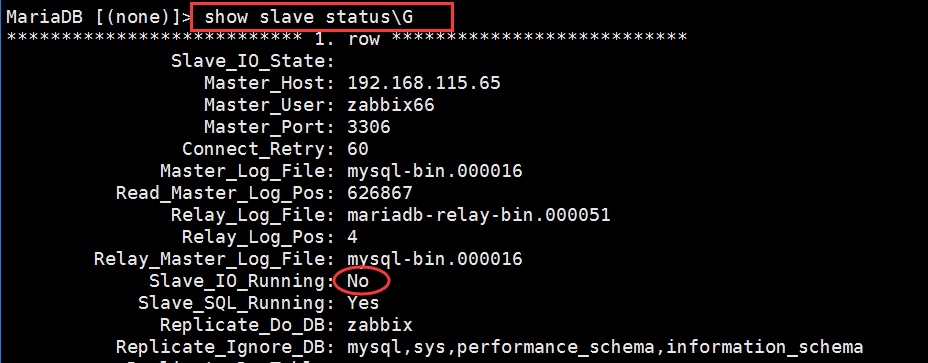
解决办法如下:
1、查看主服务器
MariaDB [(none)]> show master status\G 
2、在从服务器上查看
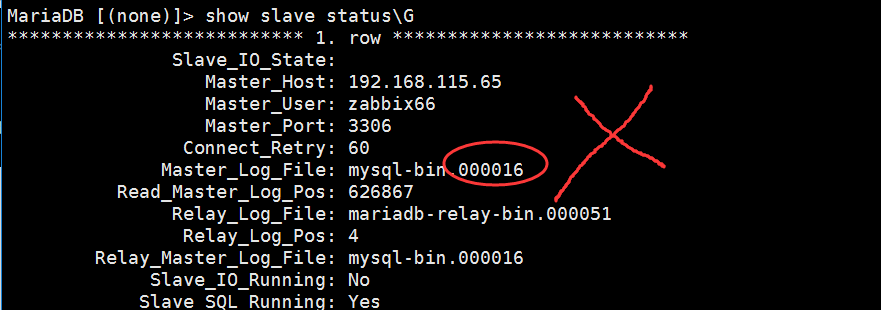
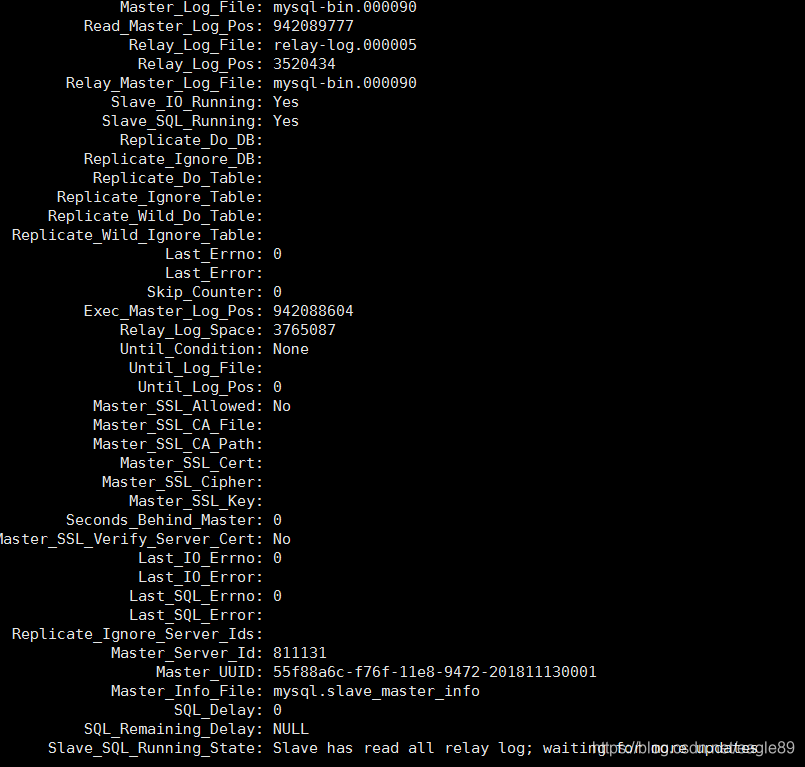
问题所在:发现Master_Log_File没有对应。
3、出现Slave_IO_Running: No的机器上操作
MariaDB [(none)]> slave stop;
MariaDB [(none)]>CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000026', MASTER_LOG_POS=0;
MariaDB [(none)]> slave start;
MariaDB [(none)]> show slave status\G 
到此问题就解决了!
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.11.22', MASTER_PORT = 3306, MASTER_USER = 'repl8', MASTER_PASSWORD = '1ZmE2HIx', MASTER_AUTO_POSITION = 1;
ERROR 3079 (HY000): Multiple channels exist on the slave. Please provide channel name as an argument.
mysql> reset slave all;
Query OK, 0 rows affected (0.01 sec)

stop slave;
change master to master_auto_position=0;

五、mysql主从同步报错,提示Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most
mysql主从不同步,提示Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction
昨天zabbix突然发送告警信息,告警说是mysql的slave停掉了,登录到数据库从库,进去看mysql的进程是正常的,然后去看下mysql的error日志
1,进入数据库查看主从状态 show slave status\G;
根据提示查询到的错误信息
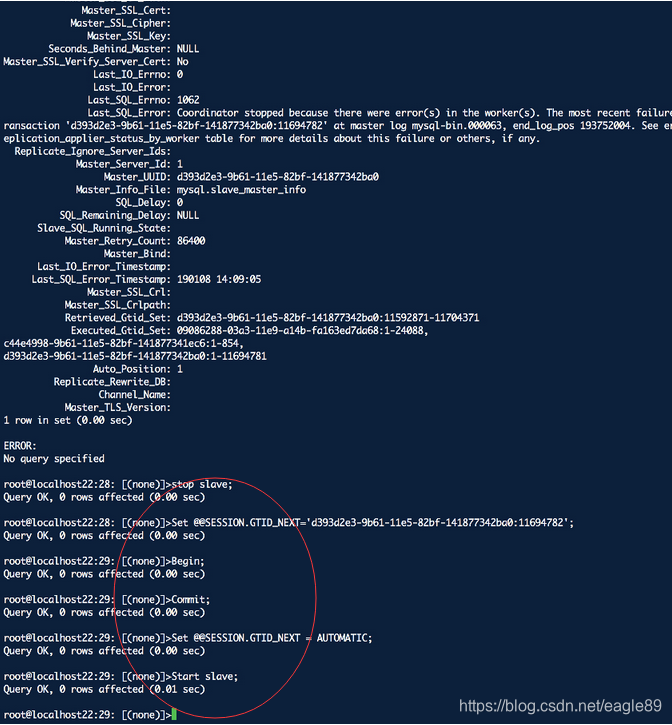
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction ‘d393d2e3-9b61-11e5-82bf-141877342ba0:171661170’ at master log mysql-bin.000063, end_log_pos 171661170. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
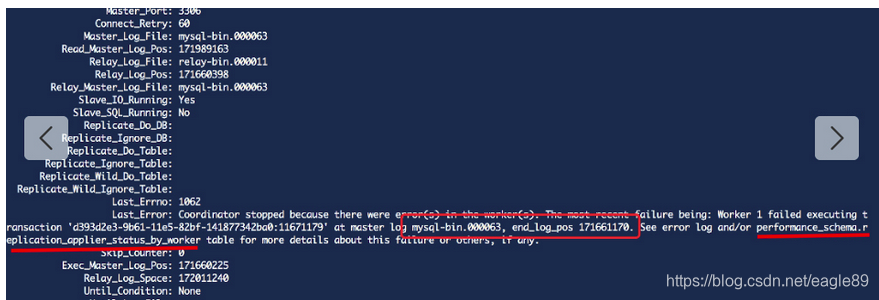
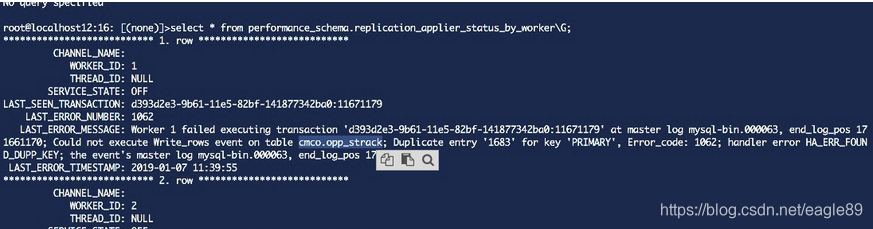
2,根据上图的提示,查询到的异常数据出现在opp_strack表中
select * from performance_schema.replication_applier_status_by_worker\G;
确定事务发生在表 opp_strack 上,定位到表,再去排查是哪一条记录
在这里插入图片描述
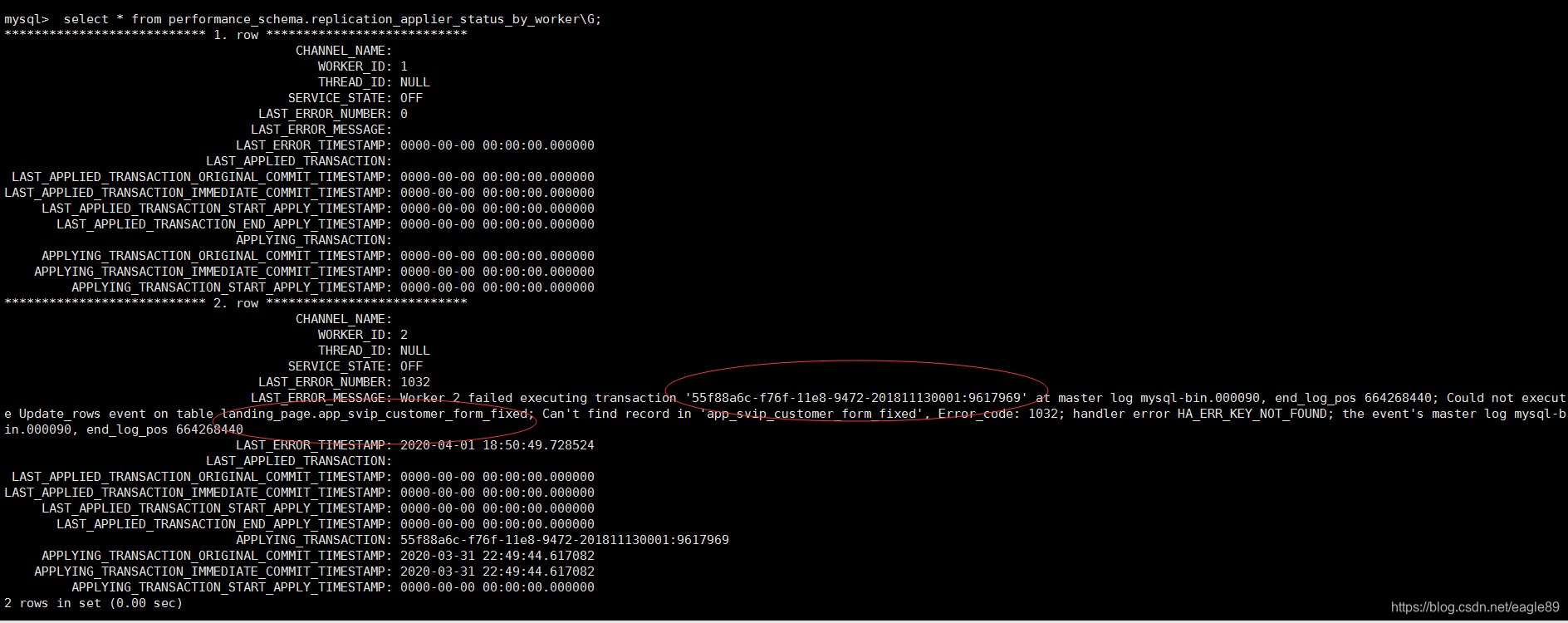
3,去主库的对应的binlog日志中去查找数据库操作记录
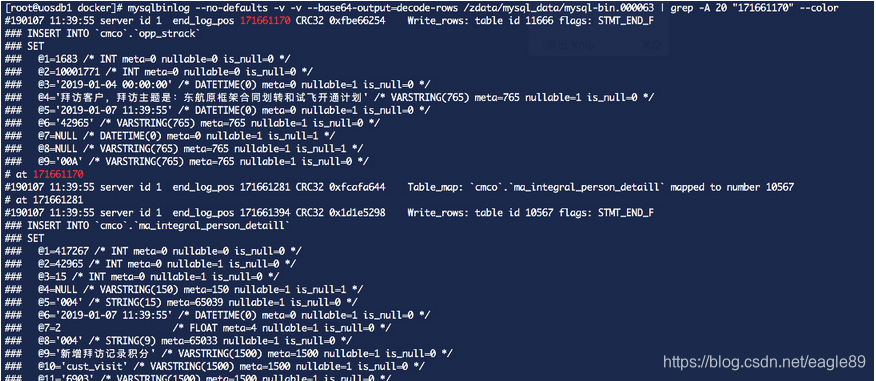
mysqlbinlog --no-defaults -v -v --base64-output=decode-rows /zdata/mysql_data/mysql-bin.000063 | grep -A 20 “171661170” --color
/home/pubsrv/mysql-8.0.12-3306/bin/mysqlbinlog -uroot -p /home/pubsrv/mysql-8.0.12-3306/log/mysql-bin.000090 --base64-output=decode-rows -v -v -d landing_page --start-datetime='2020-4-1 16:15:00' > bb.sql
–/zdata/mysql_data/mysql-bin.000063是在主从状态中查找的
binlog日志中查询到opp_strack表的更新操作,然后对比主从库opp_strack表中字段“1683”的数据,我这边得到的数据是不一致的,发现从库opp_strack中被插入进来三条数据,冲掉了主库的id值,然后将从库中的三条数据删除掉
4,主从数据恢复一致后需要在slave上跳过报错的事务
在从库中执行
Stop slave;
Set @@SESSION.GTID_NEXT=’ d393d2e3-9b61-11e5-82bf-141877342ba0:171661170’
Begin;
Commit;
Set @@SESSION.GTID_NEXT = AUTOMATIC;
Start slave;
再次查看从库状态,恢复正常即解决
Show slave status\G