在数据库管理中,合理地对数据进行分区可以提高查询性能和数据管理效率。
本文将详细介绍在Postgresql中对空间数据进行表分区的实践过程。
测试计算机容量有限,测试最大数据量为1,000,000条。
关键字: Postgresql PostGIS 表分区 空间数据
测试计算机配置如下:
内存(16G):
内存 1 名称为 3200 MHz,大小 8GB,频率 3200 MHz,数据宽度 64。
内存 2 名称为 3200 MHz,大小 8GB,频率 3200 MHz,数据宽度 64。
CPU(AMD 6 核 4600Hz):
- CPU 名称为超微半导体 AMD Ryzen 5 4600H with Radeon Graphics
- 六核,核心数 6,默认频率 3000 MHz,外频 100 MHz,当前频率 3000 MHz,
- 二级缓存为 512-KB,12-way set associative,64-byte line size,
- 三级缓存为 64-KB,18-way set associative,64-byte line size,
- CPU 电压 1.200 V,数据宽度 64。
硬盘(SSD): Micron MTFDHBA512TDV,大小 512GB。
一、Postgresql分区介绍
Postgresql的分区功能允许将一个大表按照特定的规则拆分成多个小的分区表。这样做的好处在于,在查询数据时,可以只扫描相关的分区,而不必扫描整个大表,从而大大提高查询速度。对于大规模数据的管理,分区还可以使得数据的维护和操作更加便捷,例如备份、恢复等操作可以针对单个分区进行,减少了资源消耗和时间成本。
二、对空间字段进行分区的基本思路
在对空间数据进行分区时,我们需要根据空间数据的特点来确定分区策略。这里我们采用了基于经纬度的分区方式。具体来说,通过计算每个数据点的经纬度与特定步长(这里是5度)的比值,然后取整,得到对应的分区索引。再根据分区索引构建分区表的名称,从而将数据划分到不同的分区中。这样的分区策略可以使得在查询时,能够快速定位到可能包含目标数据的分区,减少不必要的数据扫描。
三、基本步骤
(一)创建表和插入数据
- 首先创建了名为
public.t_partition的表,该表包含id(大整数类型)和geom(几何类型)两个字段:
DROP TABLE IF EXISTS public.t_partition;
CREATE TABLE IF NOT EXISTS public.t_partition
(
id bigint NOT NULL,
geom geometry NOT NULL
);
- 然后向表中插入了1000000条模拟数据。数据的生成通过
generate_series函数生成自增的id,并使用随机函数生成经纬度坐标,再将其转换为几何点类型并设置SRID为4326:
delete from public.t_partition;
INSERT INTO public.t_partition (id, geom)
SELECT
s.id,
ST_SetSRID(ST_MakePoint(random() * 360 - 180, random() * 180 - 90), 4326)
FROM
generate_series(1, 1000000) AS s(id);
- 插入数据后,通过以下语句查看了插入情况的前10条数据:
select * from t_partition limit 10;
(二)创建分区函数
创建了一个名为partition_function的函数,用于根据经纬度计算分区名称。该函数接受经纬度作为参数,首先计算经度和纬度分别除以5的整数值,然后根据这些值构建分区名称。分区名称的格式为p_<经度分区值>_<纬度分区值>,其中经度和纬度分区值在构建时将负号替换为下划线:
CREATE OR REPLACE FUNCTION partition_function(longitude double precision, latitude double precision)
RETURNS text AS $$
DECLARE
long_part int;
lat_part int;
partition_name text;
BEGIN
long_part := floor((longitude)/5);
lat_part := floor((latitude)/5);
partition_name := format('p_%s_%s',
replace((long_part*5)::varchar,'-','_'),
replace((lat_part*5)::varchar,'-','_'));
RETURN partition_name;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
可以通过以下语句测试分区函数:
SELECT partition_function(-122,-32);
(三)创建分区表模板
创建了一个名为public.t_partition_template的表作为分区表模板,它的结构与public.t_partition相同,并通过PARTITION BY LIST根据分区函数partition_function(ST_X(geom), ST_Y(geom))对数据进行分区:
CREATE TABLE IF NOT EXISTS public.t_partition_template
(
LIKE public.t_partition INCLUDING ALL
) PARTITION BY LIST (partition_function(ST_X(geom), ST_Y(geom)));
(四)创建实际分区
使用DO语句和循环创建了多个实际的分区表。循环遍历经度和纬度的范围,根据计算得到的分区名称创建对应的分区表。如果分区表已存在则不创建,以避免重复操作:
DO $$
DECLARE
long_idx int;
lat_idx int;
long_val varchar;
lat_val varchar;
BEGIN
FOR long_idx IN 0..72 LOOP
long_val := (long_idx*5-180)::varchar;
long_val := replace(long_val,'-','_');
FOR lat_idx IN 0..36 LOOP
lat_val := (lat_idx*5-90)::varchar;
lat_val := replace(lat_val,'-','_');
EXECUTE format('CREATE TABLE IF NOT EXISTS public.p_%s_%s PARTITION
OF public.t_partition_template FOR VALUES IN (''p_%s_%s'')',
long_val, lat_val, long_val, lat_val);
END LOOP;
END LOOP;
END $$;
(五)将数据插入分区表
将之前插入到public.t_partition表中的数据插入到分区表public.t_partition_template中:
INSERT INTO public.t_partition_template
SELECT * FROM public.t_partition;
这样表中的数据总量一样了。
(六)创建查询分区的函数
创建了一个名为query_partitions的函数,用于通过分区进行查询。该函数接受经纬度的最小值和最大值作为参数,首先计算可能包含目标数据的分区索引范围,然后构建分区名称数组。接着在循环中,对每个分区名称进行查询,如果分区表不存在则忽略异常并继续下一个分区的查询。最后将查询结果返回:
CREATE OR REPLACE FUNCTION query_partitions(long_min double precision, long_max double precision, lat_min double precision, lat_max double precision)
RETURNS TABLE (id bigint, geom geometry) AS $$
DECLARE
long_part int;
lat_part int;
partition_name text;
partition_names text[];
BEGIN
-- 计算可能存在的分区索引范围
FOR long_part IN greatest(floor((long_min)/5)*5, -180).. least(floor((long_max)/5)*5, 180) LOOP
FOR lat_part IN greatest(floor((lat_min)/5)*5, -90).. least(floor((lat_max)/5)*5, 90) LOOP
partition_name := format('p_%s_%s', long_part, lat_part);
partition_names = array_append(partition_names, partition_name);
END LOOP;
END LOOP;
-- 在找到的分区中进行查询
FOR i IN 1..array_length(partition_names, 1) LOOP
BEGIN
RETURN QUERY EXECUTE format('SELECT id, geom FROM public.%I WHERE ST_X(geom) > %L AND ST_X(geom) < %L AND ST_Y(geom) > %L AND ST_Y(geom) < %L',
partition_names[i], long_min, long_max, lat_min, lat_max);
EXCEPTION WHEN undefined_table THEN
-- 如果分区表不存在,忽略并继续下一个分区的查询
CONTINUE;
END;
END LOOP;
END;
$$ LANGUAGE plpgsql;
四、测试结论
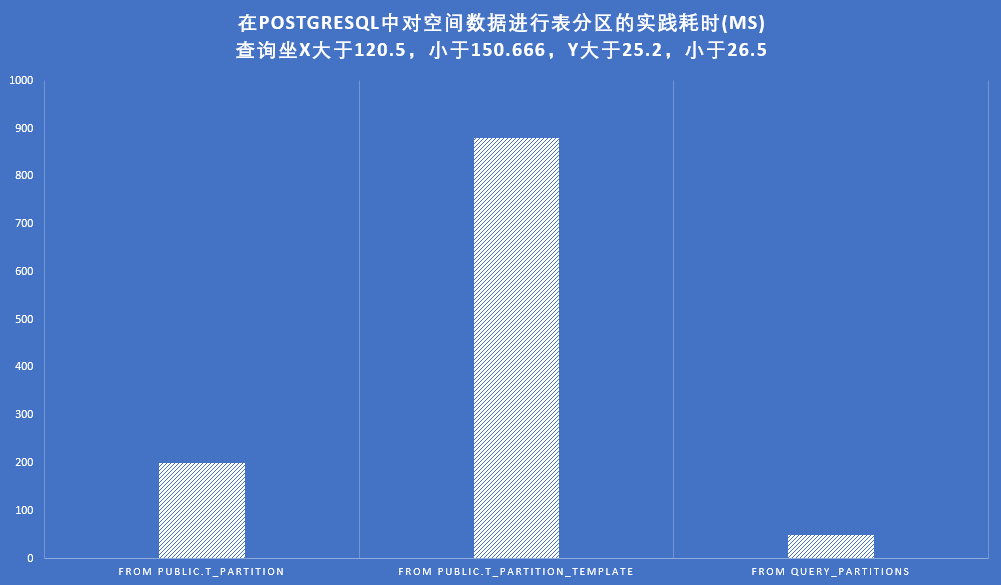
-- 在t_partition表中查询坐x大于120.5,小于150.666,y大于25.2,小于26.5
-- 耗时:180-220 ms
SELECT count(0)
FROM public.t_partition
WHERE ST_X(geom) > 120.5 AND ST_X(geom) < 150.666 AND ST_Y(geom) > 25.2 AND ST_Y(geom) < 26.5;
-- 在t_partition_template表中查询坐x大于120.5,小于150.666,y大于25.2,小于26.5
-- 耗时:耗时:700 - 850 ms
SELECT count(0)
FROM public.t_partition_template
WHERE ST_X(geom) > 120.5 AND ST_X(geom) < 150.666 AND ST_Y(geom) > 25.2 AND ST_Y(geom) < 26.5;
-- 通过函数在t_partition_template表中查询坐x大于120.5,小于150.666,y大于25.2,小于26.5
-- 耗时:45 - 65 ms
SELECT count(0) FROM query_partitions(120.5,150.666,25.2,26.5);
通过对不同查询方式的耗时测试,我们可以得出以下结论:
-
对未分区的
public.t_partition表进行查询,查询条件为ST_X(geom) > 120.5 AND ST_X(geom) < 150.666 AND ST_Y(geom) > 25.2 AND ST_Y(geom) < 26.5,耗时180-220 ms。 -
对分区表模板
public.t_partition_template进行相同条件的查询,耗时700-850 ms,相比未分区增大了。 -
通过创建的
query_partitions函数在分区表中进行查询,耗时仅为45-65ms,性能提升显著。这表明我们的分区策略以及查询函数的设计是有效的,能够大大提高对空间数据的查询效率。通过合理的分区和查询设计,可以为数据库应用提供更高效的数据访问和处理能力。
请注意,上述并未对任何表做索引。
希望本文的实践过程和结论能为大家在Postgresql中处理空间数据分区提供有益的参考和借鉴。在实际应用中,可以根据数据的特点和查询需求,进一步优化分区策略和查询函数,以获得更好的性能表现。