目录
布隆过滤器(Bloom Filter)是一种空间效率高的概率型数据结构,用于测试某个元素是否属于一个集合。它在存储空间上非常节省,适用于那些能够容忍一定错误的场景。布隆过滤器通常用于减少不必要的计算和查询,尤其在缓存穿透等场景下表现优异。
尽管布隆过滤器可以提供极高的查询效率,但它也有一个明显的缺点:它会出现假阳性(False Positive)。即它可能错误地报告某个元素存在于集合中,但实际上它并不在集合中。然而,它永远不会产生假阴性,即不会错过集合中已经存在的元素。
总之:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
1. 布隆过滤器的原理
布隆过滤器由多个哈希函数和一个位数组(Bit Array)组成,工作原理可以简述为以下几步:
-
初始化:创建一个位数组,所有位都初始化为
0。位数组的大小和哈希函数的数量是预先确定的,取决于需要存储的元素数量和可接受的误判率。 -
插入元素:
- 对每个待插入的元素,通过多个哈希函数计算出该元素的哈希值。
- 根据这些哈希值设置位数组中对应位置的值为
1。
-
查询元素:
- 对查询的元素,使用相同的哈希函数计算出哈希值。
- 检查位数组中相应位置的值。如果所有位置都为
1,则认为该元素存在于集合中;如果任一位置为0,则该元素肯定不在集合中。
举例说明:
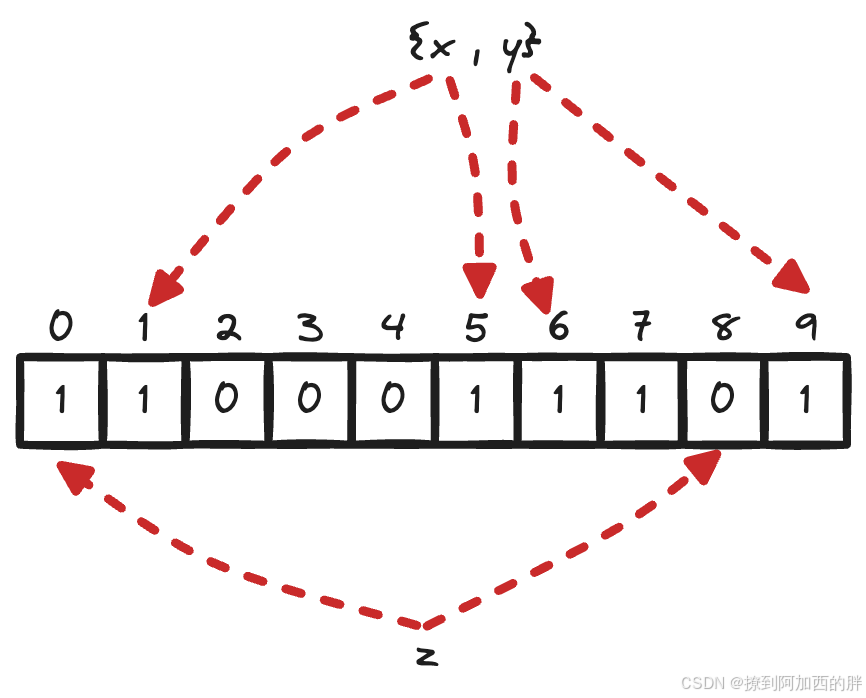
下图是一个布隆过滤器,共有10个比特位,2个哈希函数。集合中,两个元素x,y,通过两个哈希函数散列到不同的比特位,并将比特位置为1。当查询z时,通过2个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
1.1 布隆过滤器的优点和缺点
优点
- 空间高效:布隆过滤器能以极小的内存消耗来存储大量数据。
- 查询高效:布隆过滤器支持常数时间复杂度的查询操作(O(k),其中
k是哈希函数的数量)。 - 无假阴性:布隆过滤器不会错误地报告某个元素不在集合中。
缺点
- 假阳性:布隆过滤器可能错误地报告某个元素在集合中,但实际上它并不在集合中。误判率取决于哈希函数数量和位数组的大小。
- 无法删除元素:标准的布隆过滤器不支持删除操作。因为删除元素可能会影响其他元素的判断。
2. 布隆过滤器的应用场景
布隆过滤器非常适用于以下几种场景:
2.1 缓存穿透
在使用 Redis 等缓存系统时,缓存穿透是一个常见的问题。如果查询的键不存在于缓存中,并且该键在数据库中也没有相应的记录,直接查询数据库会给数据库带来不必要的压力。
布隆过滤器可以在查询数据库前,先通过布隆过滤器检查该数据是否存在。如果布隆过滤器判断数据不存在,则不需要查询数据库,避免了无效的数据库访问。
示例:使用布隆过滤器减少缓存穿透
假设我们有一个存储商品信息的缓存系统,当用户查询一个商品信息时,我们希望先通过布隆过滤器检查该商品是否存在。只有在布隆过滤器中查询到该商品的哈希值为 1 时,才从 Redis 缓存中读取数据,否则跳过 Redis 查询,直接返回空值或进行数据库查询。
import redis
import hashlib
from pybloom_live import BloomFilter
# 创建 Redis 连接
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 初始化布隆过滤器,设定预估数据量和误判率
bloom = BloomFilter(capacity=1000000, error_rate=0.001)
def query_product(product_id):
# 使用布隆过滤器判断商品是否存在
if product_id in bloom:
# 如果商品存在于布隆过滤器中,则查询 Redis
product_info = r.get(f"product:{product_id}")
if product_info:
return product_info
else:
# 缓存未命中,查询数据库
product_info = query_database(product_id)
# 查询结果缓存到 Redis
r.setex(f"product:{product_id}", 3600, product_info)
return product_info
else:
# 如果商品不存在于布隆过滤器中,直接返回空
return None
def query_database(product_id):
# 模拟查询数据库
return f"Product {product_id} info from DB"
2.2 防止重复提交
布隆过滤器常被用于防止重复提交场景。比如在某些高并发的场景下,我们希望避免用户重复提交相同的订单或请求。可以使用布隆过滤器判断请求是否已经处理过,如果请求已经处理过,则不再处理。
示例:防止重复提交订单
# 初始化布隆过滤器
bloom = BloomFilter(capacity=1000000, error_rate=0.001)
def submit_order(order_id):
# 检查订单是否已经提交
if order_id in bloom:
print("Order already processed")
return
else:
# 订单未处理,进行处理
process_order(order_id)
# 将订单ID加入布隆过滤器,防止重复提交
bloom.add(order_id)
print(f"Order {order_id} submitted successfully")
def process_order(order_id):
# 模拟处理订单
print(f"Processing order {order_id}")
2.3 网络爬虫
在爬虫中,我们常常需要判断一个 URL 是否已经被爬取过,以避免重复爬取同一个页面。布隆过滤器非常适合用于这种场景,它能有效地减少内存占用,并快速判断 URL 是否已经爬取过。
示例:爬虫中的 URL 去重
# 初始化布隆过滤器
bloom = BloomFilter(capacity=1000000, error_rate=0.001)
def crawl_page(url):
# 检查 URL 是否已经爬取过
if url in bloom:
print(f"URL {url} already crawled")
return
else:
# 执行爬取
print(f"Crawling URL {url}")
# 将爬取的 URL 加入布隆过滤器
bloom.add(url)
# 模拟爬取页面
return f"Page content from {url}"
# 模拟爬取
crawl_page("http://example.com")
crawl_page("http://example.com") # 这个请求将被忽略,因为已经爬取过
2.4 分布式系统中的节点去重
在分布式环境下,多个节点可能会同时访问某些资源。布隆过滤器可以用于防止不同节点重复处理相同的数据或请求。例如,在分布式缓存系统中,布隆过滤器可以避免多个节点同时处理相同的请求或数据,减少重复计算。
3. 布隆过滤器的局限性与优化
3.1 假阳性率
布隆过滤器无法完全避免假阳性,即它可能会错误地报告某个元素在集合中。假阳性率是布隆过滤器的一个重要指标,它与位数组的大小和哈希函数的数量密切相关。在设计布隆过滤器时,我们需要根据预估的元素数量和接受的误判率,来调整位数组的大小和哈希函数的数量。
3.2 删除操作
标准的布隆过滤器不支持删除操作。删除元素可能会影响其他元素的判断,因此如果需要支持删除操作,可以使用 计数布隆过滤器(Counting Bloom Filter),该结构通过使用计数器来表示每个位置的元素个数,从而支持删除操作。
3.3 优化:使用多个布隆过滤器
在某些应用场景中,我们可以使用多个布隆过滤器(如分布式布隆过滤器),将不同的数据集合分布到多个布隆过滤器中,进一步减少误判率。
4. 总结
布隆过滤器是一种高效且节省空间的数据结构,适用于大规模数据集合的存在性检测。尽管它存在假阳性率,但在很多实际应用场景中,假阳性是可以容忍的,特别是在缓存穿透、重复提交防止、URL 去重等场景中,布隆过滤器能够有效地提高性能和减少资源消耗。