引言
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 --维基百科
网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
一般有两个步骤:1.获取网页内容 2.对获得的网页内容进行处理
准备
Linux开发环境
python3.61安装方法:https://www.cnblogs.com/kimyeee/p/7250560.html
安装一些必要的第三方库
其中requiests可以用来爬取网页内容,beautifulsoup4用来将爬取的网页内容分析处理
pip3 install requiests
pip3 install beautifulsoup4
第一步:爬取
使用request库中的get方法,请求url的网页内容
更多了解:http://docs.python-requests.org/en/master/
编写代码
[root@localhost demo]# touch demo.py
[root@localhost demo]# vim demo.py#web爬虫学习 -- 分析
#获取页面信息
#输入:url
#处理:request库函数获取页面信息,并将网页内容转换成为人能看懂的编码格式
#输出:爬取到的内容
import requests
def getHTMLText(url):
try:
r = requests.get( url, timeout=30 )
r.raise_for_status() #如果状态码不是200,产生异常
r.encoding = 'utf-8' #字符编码格式改成 utf-8
return r.text
except:
#异常处理
return " error "
url = "http://www.baidu.com"
print( getHTMLText(url) )[root@localhost demo]# python3 demo.py
第二步:分析
使用bs4库中BeautifulSoup类,生成一个对象。find()和find_all()方法可以遍历这个html文件,提取指定信息。
更多了解:https://www.crummy.com/software/BeautifulSoup/
编写代码
[root@localhost demo]# touch demo1.py
[root@localhost demo]# vim demo1.py#web爬虫学习 -- 分析
#获取页面信息
#输入:url
#处理:request库获取页面信息,并从爬取到的内容中提取关键信息
#输出:打印输出提取到的关键信息
import requests
from bs4 import BeautifulSoup
import re
def getHTMLText(url):
try:
r = requests.get( url, timeout=30 )
r.raise_for_status() #如果状态码不是200,产生异常
r.encoding = 'utf-8' #字符编码格式改成 utf-8
return r.text
except:
#异常处理
return " error "
def findHTMLText(text):
soup = BeautifulSoup( text, "html.parser" ) #返回BeautifulSoup对象
return soup.find_all(string=re.compile( '百度' )) #结合正则表达式,实现字符串片段匹配
url = "http://www.baidu.com"
text = getHTMLText(url) #获取html文本内容
res = findHTMLText(text) #匹配结果
print(res) #打印输出[root@localhost demo]# python3 demo1.py
一个例子:中国大学排名爬虫
参考链接:https://python123.io/index/notebooks/python_programming_basic_v2
#e23.1CrawUnivRanking.py
import requests
from bs4 import BeautifulSoup
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
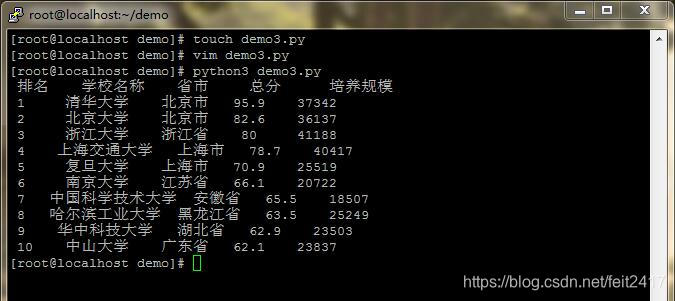
def printUnivList(num):
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","培养规模"))
for i in range(num):
u=allUniv[i]
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(u[0],u[1],u[2],u[3],u[6]))
def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
printUnivList(10)
main()展示