说明
这里研究的cutlass版本是3.5
gemm讲解
using CutlassGemm = cutlass::gemm::device::Gemm<float, // Data-type of A matrix
ColumnMajor, // Layout of A matrix
float, // Data-type of B matrix
ColumnMajor, // Layout of B matrix
float, // Data-type of C matrix
ColumnMajor>; // Layout of C matrix
CutlassGemm gemm_operator;
CutlassGemm::Arguments args({M , N, K}, // Gemm Problem dimensions
{A, lda}, // Tensor-ref for source matrix A
{B, ldb}, // Tensor-ref for source matrix B
{C, ldc}, // Tensor-ref for source matrix C
{C, ldc}, // Tensor-ref for destination matrix D (may be different memory than source C matrix)
{alpha, beta}); // Scalars used in the Epilogue
cutlass::Status status = gemm_operator(args);
上面是核心代码,可以看到首先要实例化一个类型CutlassGemm(编译期就要定下来),然后根据这个类型实例化一个对象gemm_operator(运行期),然后对象调用operator(args)做计算(运行期)。
编译期
using CutlassGemm = cutlass::gemm::device::Gemm<float, // Data-type of A matrix
ColumnMajor, // Layout of A matrix
float, // Data-type of B matrix
ColumnMajor, // Layout of B matrix
float, // Data-type of C matrix
ColumnMajor>; // Layout of C matrix
可以看到,编译期时候,程序员必须要定下输入矩阵的layout和数据类型。事实上真的是这样吗?我们来深究一下这个cutlass::gemm::device::Gemm,从这个名字就可以看出来,cutlass实现了一个gemm,有device, threadblock, warp, thread几个级别gemm,这个sample里面用的是device级别, 所谓的device级别就是在cpu端的代码可以调用的,这个其实和cub中的逻辑是一样的。
Gemm类
template <
typename ElementA_,
typename LayoutA_,
typename OperatorClass_ = arch::OpClassSimt,
typename ArchTag_ = arch::Sm70,
typename ThreadblockShape_ = typename DefaultGemmConfiguration<
OperatorClass_, ArchTag_, ElementA_, ElementB_, ElementC_,
ElementAccumulator_>::ThreadblockShape,
// Operation performed by GEMM
typename Operator_ = typename DefaultGemmConfiguration<
OperatorClass_, ArchTag_, ElementA_, ElementB_, ElementC_,
ElementAccumulator_>::Operator, //op的选择
>
Gemm{}
//偏特化一个
template<省略>
Gemm<layoutC=layout::ColumnMajor,>
{
using UnderlyingOperator = Gemm<bala>;
}
1、这里偏特化很奇怪,单独给layoutC为列优先时候准备了一个类,具体什么原因这里也不深究,因为测试例子给的就是个ColumnMajor的layoutC,所以我们直接看这个偏特化类型。
这里增加了一个小知识,就是偏特化的模板不需要再传入默认值,会自动复用原始模板的默认值,此外由于偏特化实例化了一个值,导致在类里使用的时候没有了形参,为此可以看到源码里在类的开头搞了一堆的 类似using LayoutC = LayoutC_;即使偏特化实例化后,也能在类中再搞一个形参使用,CPP这搞得的是真恶心。
2、在偏特化的类中,又实例化了一通用的Gemm类UnderlyingOperator,这里把C的layout又改成RowMajor来用通用模板实例化Gemm, 多以饶了一圈,偏特化就是空壳子,最后还是绕回去通用模板,为什么要这要搞?我理解为了对外接口统一做的牺牲。
UnderlyingOperator
接下来就看看这通用模板是如何被实例化的。
using UnderlyingOperator = Gemm<
ElementB,
typename layout::LayoutTranspose<LayoutB>::type,
ElementA,
typename layout::LayoutTranspose<LayoutA>::type,
ElementC,
layout::RowMajor,
ElementAccumulator,
OperatorClass,
ArchTag,
ThreadblockShape,
WarpShape,
InstructionShape,
EpilogueOutputOp,
ThreadblockSwizzle,
Stages,
kAlignmentB,
kAlignmentA,
SplitKSerial,
Operator,
GatherB,
GatherA,
ScatterD,
PermuteDLayout
>;
1、第一个有趣的现象是,把A,B, C的layout修改了,而且A和B的输入位置也变了,有点意思,来看看原理。
为了保证输出的数据不变,原来的列优先eading dimension=M的矩阵,我们也可以把他解读为行优先,leading dimension=M的矩阵。在计算机内存上没有任何变化,当时数学逻辑上由原来的MN的矩阵,变成了NM的矩阵(必须要理解)。 紧接着在数学逻辑上,原来的(MK) * (KN) = MN 需要变成(Nk) * (KM) = NM, 这里可以看到,当C的解读变化的时候,原来的A和B的位置调换了, 又由于A和B的计算机内存的数据不动,那么在解读时候,layout也要跟着掉换才对。
如此,就可以在A,B,C内存都不用动的情况来做计算,通过上述分析可以看到,框架还是想方设法的把C矩阵拉成行优先去处理,好处嘛我以为就是为了处理C的时候行连续更加符合人类对内存的直观感受,写代码的时候不至于一直别别扭扭,而且可以统一成一种优化模式,不管你C是什么layout,最终在不影响性能的情况下都转到一种C=RowMajor的逻辑下。
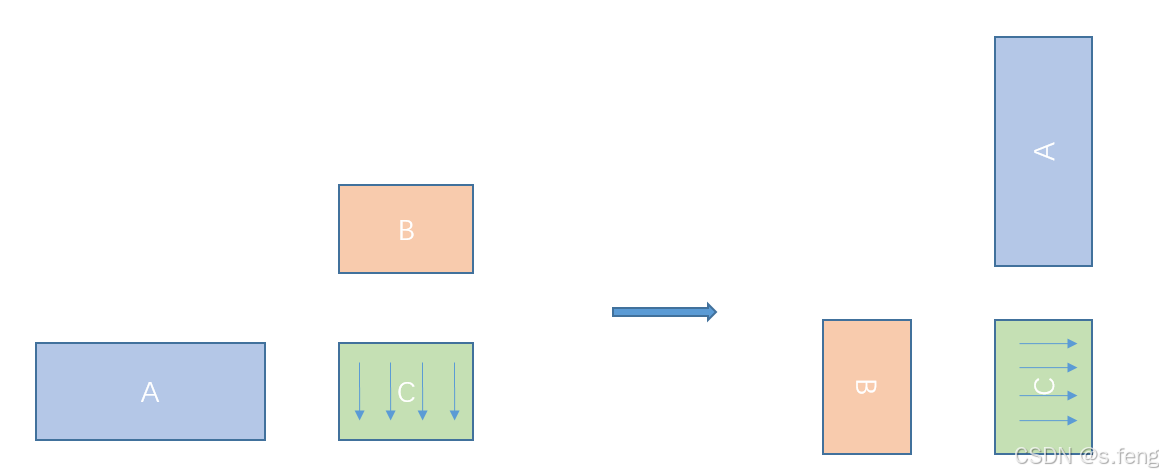
Gemm模板形参解读
上面我们搞清楚了一个矩阵的输入输出关系,位置关系,下面我们来看看一些默认形参分别是啥意思
OperatorClass
这个默认给了arch::OpClassSimt, 这个好理解,就是利用cuda core来做计算,如果是OpClassTensorOp的话就用tensorcore来做计算,OpClassWmmaTensorOp的话就是用一个分装好的wmma接口来调用tensorcore做计算,整个种类定义都在mma.h文件中,这里没啥好说的。
ArchTag
这里默认是arch::Sm70,这个也比较好理解,比如sm_50, sm_86的架构不一样,有的又sme异步,有的有tensor core, 有的sm大小不一样,反正每个架构不一样,各种feature也不一样,在编译期就明确,在编译期也就可以很具这些架构选择合适的算法。
ThreadblockShape
接下来是分级策略,这个需要去了解一下gemm的分块原理,这里不再详述,知乎一大堆,那么分块尺寸如何确定呢?这里用了DefaultGemmConfiguration这个类去萃取,依赖就是计算单元,架构,A,B, C的数据类型,以及累加的数据类型。
typename ThreadblockShape_ = typename DefaultGemmConfiguration<OperatorClass_, ArchTag_, ElementA_, ElementB_, ElementC_,ElementAccumulator_>::ThreadblockShape
所以需要好好看看DefaultGemmConfiguration是啥玩意:具体在default_gemm_configuration.h
template <
typename OperatorClass,
typename ArchTag,
typename ElementA,
typename ElementB,
typename ElementC,
typename ElementAccumulator
>
struct DefaultGemmConfiguration;
template <
typename ArchTag,
typename ElementA,
typename ElementB,
typename ElementC,
typename ElementAccumulator>
struct DefaultGemmConfiguration<
arch::OpClassSimt,
ArchTag,
ElementA,
ElementB,
ElementC,
ElementAccumulator> {
static int const kAlignmentA = 1;
static int const kAlignmentB = 1;
using ThreadblockShape = GemmShape<128, 128, 8>;
using WarpShape = GemmShape<32, 64, 8>;
using InstructionShape = GemmShape<1, 1, 1>;
static int const kStages = 2;
using EpilogueOutputOp = epilogue::thread::LinearCombination<
ElementC,
1,
ElementAccumulator,
ElementAccumulator
>;
using Operator = arch::OpMultiplyAdd;
};
上述代码可以看到就是定义了一个空类型,然后偏特化一堆的DefaultGemmConfiguration,上述代码就是偏特化一个参数arch::OpClassSimt,其实这个文件就是一个配置文件,你需要用啥shape,在这里搞个偏特化版本就行,我们目的是分析不是调优,所以就看看cutlass咋用的就行。
EpilogueOutputOp
就是gemm后面跟了一个计算,这里一下子给融合到计算里,这里的例子没有,所以可以先不看,看的也是在DefaultGemmConfiguration配置,不过还要依赖LinearCombinationClamp或者LinearCombination去配置。
ThreadblockSwizzle
这个就是share memory 避免bank冲突的一个策略,具体使用那种策略需要GemmIdentityThreadblockSwizzle去决策,此外还有七八种其他方案,可以自己根据实际情况进行选择,文件在threadblock_swizzle.h
Stages
这个也在DefaultGemmConfiguration中配置,主要是看gemm是用double buffer还是说多stage, 多stage需要sm80及以上的架构才行,本质就是share memory的数据读取可以不经过寄存器,没整明白的也需要先去知乎了解一下。
AlignmentA
不重要,后面需要的时候再看,反正目前对齐的数字也是1.
运行时分析
编译期都搞定了,开始进行运行时分析
cutlass::Status status = gemm_operator(args);
可以看到,这里没有给相应的workspace和stream。这里要稍微记一下。接下来我们知道由于走的是偏特化版本Gemm,所以在喂给原始Gemm类的时候,需要对参数重新整理,整理如下:
static UnderlyingArguments to_underlying_arguments(Arguments const &args) {
return UnderlyingArguments(
{args.problem_size.n(), args.problem_size.m(), args.problem_size.k()},
{args.ref_B.data(), args.ref_B.stride(0)},
{args.ref_A.data(), args.ref_A.stride(0)},
{args.ref_C.data(), args.ref_C.stride(0)},
{args.ref_D.data(), args.ref_D.stride(0)},
args.epilogue,
args.split_k_slices,
args.gather_B_indices,
args.gather_A_indices,
args.scatter_D_indices
);
}
这里不是重点,接下来看初始化代码:
Status initialize(Arguments const &args, void *workspace = nullptr, cudaStream_t stream = nullptr) {
// Determine grid shape
ThreadblockSwizzle threadblock_swizzle;
cutlass::gemm::GemmCoord grid_shape = threadblock_swizzle.get_tiled_shape(
args.problem_size, {ThreadblockShape::kM, ThreadblockShape::kN, ThreadblockShape::kK},args.split_k_slices);
// Initialize the Params structure
params_ = typename GemmKernel::Params{
args.problem_size,
grid_shape,
args.ref_A.non_const_ref(),
args.ref_B.non_const_ref(),
args.ref_C.non_const_ref(),
args.ref_D,
args.epilogue,
static_cast<int *>(workspace),
args.gather_A_indices,
args.gather_B_indices,
args.scatter_D_indices
};
return Status::kSuccess;
}
1、我们写kernel肯定需要grid size,就是说一个gemm需要多少个block呢?这里利用get_tiled_shape这个函数,这里ThreadblockShape::kK没有用到,目前还不清楚为啥shape有一个k值,初级选手不用关注,这个是后续split_k的时候才需要的骚操作。
2、算完grid后,就开始构造gemm的参数了,类型是GemmKernel::Params
3、初始化完后开始走到run函数,grid已经求好了,下面求block,block很好求,就是用ThreadblockShape和WarpShape算出warp的个数,然后乘32就等于线程个数
4、接下来算好需要多少share memory, 这里直接用的GemmKernel::SharedStorage,我们需要看看咋求的,GemmKernel来自于DefaultGemm,这个例子用的是arch::OpClassSimt,这里需要对偏特化选择有基础知识,优先匹配到第一个形参,所以我们看SIMT偏特化的DefaultGemm类型。
template <
/// Element type for A matrix operand
typename ElementA,
/// Layout type for A matrix operand
typename LayoutA,
/// Access granularity of A matrix in units of elements
int kAlignmentA,
/// Element type for B matrix operand
typename ElementB,
/// Layout type for B matrix operand
typename LayoutB,
/// Access granularity of A matrix in units of elements
int kAlignmentB,
/// Element type for C and D matrix operands
typename ElementC,
/// Layout type for C and D matrix operand
typename LayoutC,
/// Element type for internal accumulation
typename ElementAccumulator,
/// Tag indicating architecture to tune for
typename ArchTag,
/// Threadblock-level tile size (concept: GemmShape)
typename ThreadblockShape,
/// Warp-level tile size (concept: GemmShape)
typename WarpShape,
/// Epilogue output operator
typename EpilogueOutputOp,
/// Threadblock-level swizzling operator
typename ThreadblockSwizzle,
/// If true, kernel is configured to support serial reduction in the epilogue
bool SplitKSerial,
/// Operation performed by GEMM
typename Operator,
/// Use zfill or predicate for out-of-bound cp.async
SharedMemoryClearOption SharedMemoryClear,
/// Gather operand A by using an index array
bool GatherA,
/// Gather operand B by using an index array
bool GatherB,
/// Scatter result D by using an index array
bool ScatterD,
/// Permute result D
typename PermuteDLayout,
/// Permute operand A
typename PermuteALayout,
/// Permute operand B
typename PermuteBLayout
>
struct DefaultGemm<
ElementA,
LayoutA,
kAlignmentA,
ElementB,
LayoutB,
kAlignmentB,
ElementC,
LayoutC,
ElementAccumulator,
arch::OpClassSimt,
ArchTag,
ThreadblockShape,
WarpShape,
GemmShape<1, 1, 1>,
EpilogueOutputOp,
ThreadblockSwizzle,
2,
SplitKSerial,
Operator,
SharedMemoryClear,
GatherA,
GatherB,
ScatterD,
PermuteDLayout,
PermuteALayout,
PermuteBLayout,
//sm80有自己在特化版本
typename platform::enable_if< ! platform::is_same<ArchTag, arch::Sm80>::value >::type > {
static_assert((platform::is_same<LayoutC, layout::RowMajor>::value
|| platform::is_same<LayoutC, layout::AffineRankN<2>>::value),
"Epilogue in the kernel level must be row major");
/// Define the threadblock-scoped matrix multiply-accumulate
using Mma = typename cutlass::gemm::threadblock::DefaultMma<
ElementA,
LayoutA,
kAlignmentA,
ElementB,
LayoutB,
kAlignmentB,
ElementAccumulator,
LayoutC,
arch::OpClassSimt,
arch::Sm50,
ThreadblockShape,
WarpShape,
GemmShape<1, 1, 1>,
2,
Operator,
false,
SharedMemoryClear,
GatherA,
GatherB,
PermuteALayout,
PermuteBLayout>::ThreadblockMma;
static int const kEpilogueElementsPerAccess = EpilogueOutputOp::kCount;
static_assert(kEpilogueElementsPerAccess == 1, "simt epilogue must operate on scalars");
/// Define the epilogue
using RegularEpilogue = typename cutlass::epilogue::threadblock::DefaultEpilogueSimt<
ThreadblockShape,
typename Mma::Operator,
EpilogueOutputOp,
kEpilogueElementsPerAccess,
ScatterD,
PermuteDLayout
>::Epilogue;
using Affine2Epilogue = typename cutlass::epilogue::threadblock::DefaultEpilogueSimtAffineRankN<
2,
ThreadblockShape,
typename Mma::Operator,
EpilogueOutputOp,
kEpilogueElementsPerAccess
>::Epilogue;
using Epilogue = typename platform::conditional<platform::is_same<LayoutC, layout::RowMajor>::value,
RegularEpilogue,
Affine2Epilogue>::type;
/// Define the kernel-level GEMM operator.
using GemmKernel = kernel::Gemm<Mma, Epilogue, ThreadblockSwizzle, SplitKSerial>;
};
这里DefaultGemm相对于外层API有几个改变,第一个是加了SharedMemoryClearOption(默认给了个SharedMemoryClearOption::kNone), 第二个是InstructionShape参数没有用(我真是服了)偏特化的时候用了个GemmShape<1, 1, 1>,第三个是ArchTag=sm70直接被抛弃了,内部改用sm50,第四新增一个Mma的类型。
对于Mma而言,类似于矩阵计算里面的一个乘加操作,这里具体的GemmKernel = kernel::Gemm<Mma, Epilogue, ThreadblockSwizzle, SplitKSerial>核心依赖的就是这个玩意,所以必须分析清楚, 首先要搞清楚,这个玩意是block级别的类型,所以位于threadblock文件下。
/// Specialization for row-major output (OperatorClass Simt)
template <
/// Element type for A matrix operand
typename ElementA,
/// Layout type for A matrix operand
typename LayoutA,
/// Access granularity of A matrix in units of elements
int kAlignmentA,
/// Element type for B matrix operand
typename ElementB,
/// Layout type for B matrix operand
typename LayoutB,
/// Access granularity of B matrix in units of elements
int kAlignmentB,
/// Element type for internal accumulation
typename ElementAccumulator,
/// Layout type for C and D matrix operand
typename LayoutC,
/// Tag indicating architecture to tune for
typename ArchTag,
/// Threadblock-level tile size (concept: GemmShape)
typename ThreadblockShape,
/// Warp-level tile size (concept: GemmShape)
typename WarpShape,
/// Instruction-level tile size (concept: GemmShape)
typename InstructionShape,
/// Operation performed by GEMM
typename Operator,
/// Gather operand A by using an index array
bool GatherA,
/// Gather operand B by using an index array
bool GatherB,
/// Permute operand A
typename PermuteALayout,
/// Permute operand B
typename PermuteBLayout
>
struct DefaultMma<ElementA, LayoutA, kAlignmentA, ElementB, LayoutB,
kAlignmentB, ElementAccumulator, LayoutC,
arch::OpClassSimt, ArchTag, ThreadblockShape, WarpShape,
InstructionShape, 2, Operator, false, SharedMemoryClearOption::kNone,
GatherA, GatherB, PermuteALayout, PermuteBLayout> {
static_assert(platform::is_same<LayoutC, layout::RowMajor>::value
|| platform::is_same<LayoutC, layout::AffineRankN<2>>::value,
"simt epilogue must be row major");
// Define the MmaCore components
using MmaCore = typename cutlass::gemm::threadblock::DefaultMmaCore<
ThreadblockShape, WarpShape, InstructionShape, ElementA, LayoutA,
ElementB, LayoutB, ElementAccumulator, LayoutC,
arch::OpClassSimt, 2, Operator>;
// Define iterators over tiles from the A operand
using IteratorA =
cutlass::transform::threadblock::PredicatedTileIterator<
cutlass::MatrixShape<MmaCore::Shape::kM, MmaCore::Shape::kK>,
ElementA, LayoutA, 1, typename MmaCore::IteratorThreadMapA, kAlignmentA,
GatherA, PermuteALayout>;
// Define iterators over tiles from the B operand
using IteratorB =
cutlass::transform::threadblock::PredicatedTileIterator<
cutlass::MatrixShape<MmaCore::Shape::kK, MmaCore::Shape::kN>,
ElementB, LayoutB, 0, typename MmaCore::IteratorThreadMapB, kAlignmentB,
GatherB, PermuteBLayout>;
// Define the threadblock-scoped pipelined matrix multiply
using ThreadblockMma = cutlass::gemm::threadblock::MmaPipelined<
typename MmaCore::Shape, IteratorA, typename MmaCore::SmemIteratorA,
IteratorB, typename MmaCore::SmemIteratorB, ElementAccumulator,
LayoutC, typename MmaCore::MmaPolicy>;
};
/// Specialization for row-major output (OperatorClass TensorOp)
/// Specialization for row-major output (OperatorClass TensorOp),数据类型都是浮点数特化
/// Specialization for column-major-interleaved output
/// Specialization for SIMT IDP4A Kernels