作者丨皮特潘
编辑丨极市平台
导读
所谓“插件”,就是要能锦上添花,又容易植入、落地,即真正的即插即用。本文盘点的“插件”能够提升CNN平移、旋转、scale等变性能力或多尺度特征提取,感受野等能力,在很多SOTA网络中都会看到它们的影子。
前言
本文盘点一些CNN网络中设计比较精巧而又实用的“插件”。所谓“插件”,就是不改变网络主体结构, 可以很容易嵌入到主流网络当中,提高网络提取特征的能力,能够做到plug-and-play。网络也有很多类似盘点工作,都宣称所谓的即插即用、无痛涨点。不过根据笔者经验和收集,发现很多插件都是不实用、不通用、甚至不work的,于是有了这一篇。
首先,我的认识是:既然是“插件”,就要是锦上添花的,又容易植入,容易落地的,真正的即插即用。本文盘点的“插件”,在很多SOTA网络中会看到它们的影子。是值得推广的良心“插件”,真正能做到plug-and-play。总之一句话,就是能够work的“插件”。很多“插件”都为提升CNN能力而推出的,例如平移、旋转、scale等变性能力,多尺度特征提取能力,感受野等能力,感知空间位置能力等等。
入围名单:STN、ASPP、Non-local、SE、CBAM、DCNv1&v2、CoordConv、Ghost、BlurPool、RFB、ASFF
1 STN
出自论文:Spatial Transformer Networks
论文链接:https://arxiv.org/pdf/1506.02025.pdf
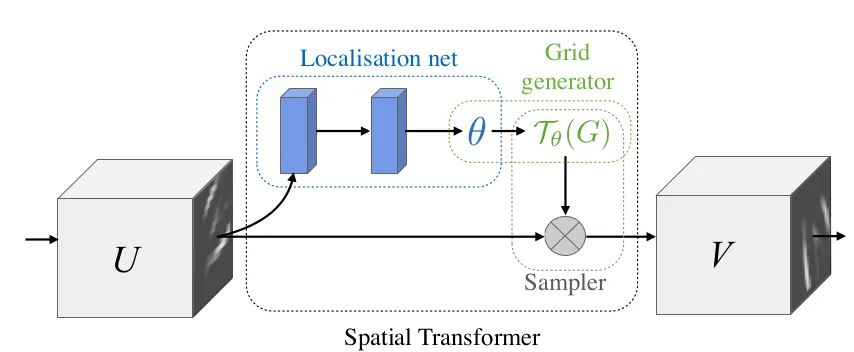
核心解析:
在OCR等任务中,你会经常看到它的身影。对于CNN网络,我们希望其具有对物体的姿态、位置等有一定的不变性。即在测试集上可以适应一定的姿态、位置的变化。不变性或等变性可以有效提高模型泛化能力。虽然CNN使用sliding-window卷积操作,在一定程度上具有平移不变性。但很多研究发现,下采样会破坏网络的平移不变性。所以可以认为网络的不变性能力非常弱,更不用说旋转、尺度、光照等不变性。一般我们利用数据增强来实现网络的“不变性”。
本文提出STN模块,显式将空间变换植入到网络当中,进而提高网络的旋转、平移、尺度等不变性。可以理解为“对齐”操作。STN的结构如上图所示,每一个STN模块由Localisation net,Grid generator和Sampler三部分组成。Localisation net用于学习获取空间变换的参数,就是上式中的 六个参数。Grid generator用于坐标映射。Sampler用于像素的采集,是利用双线性插值的方式进行。
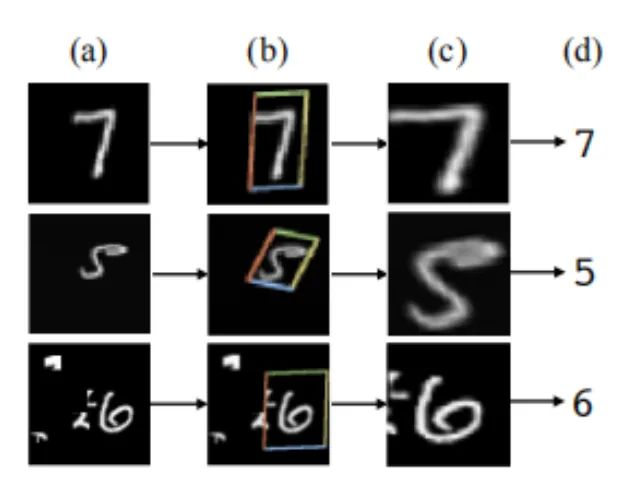
STN的意义是能够把原始的图像纠正成为网络想要的理想图像,并且该过程为无监督的方式进行,也就是变换参数是自发学习获取的,不需要标注信息。该模块是一个独立模块,可以在CNN的任何位置插入。符合本次“插件”的盘点要求。
核心代码:
class SpatialTransformer(nn.Module): def __init__(self, spatial_dims): super(SpatialTransformer, self).__init__() self._h, self._w = spatial_dims self.fc1 = nn.Linear(32*4*4, 1024) # 可根据自己的网络参数具体设置 self.fc2 = nn.Linear(1024, 6)
def forward(self, x): batch_images = x #保存一份原始数据 x = x.view(-1, 32*4*4) # 利用FC结构学习到6个参数 x = self.fc1(x) x = self.fc2(x) x = x.view(-1, 2,3) # 2x3 # 利用affine_grid生成采样点 affine_grid_points = F.affine_grid(x, torch.Size((x.size(0), self._in_ch, self._h, self._w))) # 将采样点作用到原始数据上 rois = F.grid_sample(batch_images, affine_grid_points) return rois, affine_grid_points
2 ASPP
插件全称:atrous spatial pyramid pooling
出自论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Conv
论文链接:https://arxiv.org/pdf/1606.00915.pdf

核心解析:
本插件是带有空洞卷积的空间金字塔池化模块,主要是为了提高网络的感受野,并引入多尺度信息而提出的。我们知道,对于语义分割网络,通常面临是分辨率较大的图片,这就要求我们的网络有足够的感受野来覆盖到目标物体。对于CNN网络基本是靠卷积层的堆叠加上下采样操作来获取感受野的。本文的该模块可以在不改变特征图大小的同时控制感受野,这有利于提取多尺度信息。其中rate控制着感受野的大小,r越大感受野越大。
ASPP主要包含以下几个部分:1. 一个全局平均池化层得到image-level特征,并进行1X1卷积,并双线性插值到原始大小;2. 一个1X1卷积层,以及三个3X3的空洞卷积;3. 将5个不同尺度的特征在channel维度concat在一起,然后送入1X1的卷积进行融合输出。
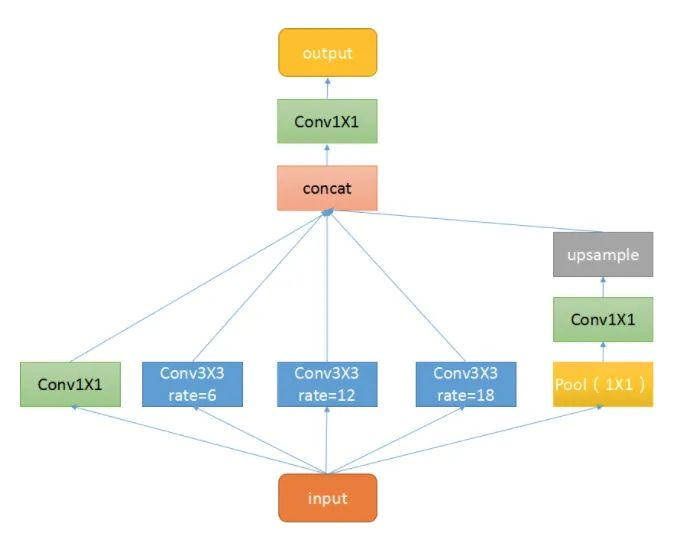
核心代码:
class ASPP(nn.Module): def __init__(self, in_channel=512, depth=256): super(ASPP,self).__init__() self.mean = nn.AdaptiveAvgPool2d((1, 1)) self.conv = nn.Conv2d(in_channel, depth, 1, 1) self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1) # 不同空洞率的卷积 self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6) self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12) self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18) self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x): size = x.shape[2:] # 池化分支 image_features = self.mean(x) image_features = self.conv(image_features) image_features = F.upsample(image_features, size=size, mode='bilinear') # 不同空洞率的卷积 atrous_block1 = self.atrous_block1(x) atrous_block6 = self.atrous_block6(x) atrous_block12 = self.atrous_block12(x) atrous_block18 = self.atrous_block18(x) # 汇合所有尺度的特征 x = torch.cat([image_features, atrous_block1, atrous_block6,atrous_block12, atrous_block18], dim=1) # 利用1X1卷积融合特征输出 x = self.conv_1x1_output(x) return net
3 Non-local
出自论文:Non-local Neural Networks
论文链接:https://arxiv.org/abs/1711.07971
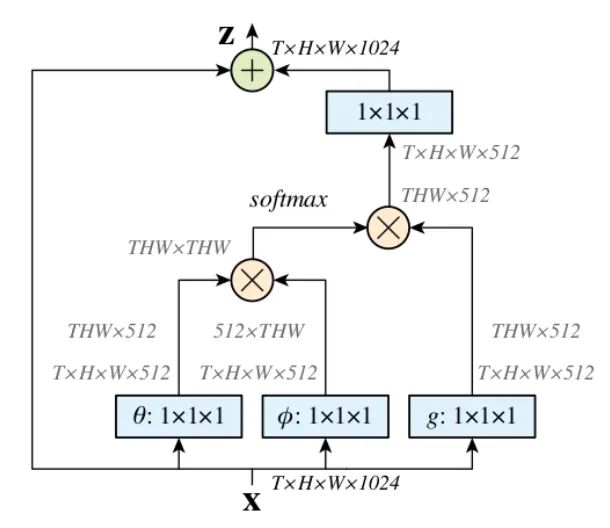
核心解析:
Non-Local是一种attention机制,也是一个易于植入和集成的模块。Local主要是针对感受野(receptive field)来说的,以CNN中的卷积操作和池化操作为例,它的感受野大小就是卷积核大小,而我们常用3X3的卷积层进行堆叠,它只考虑局部区域,都是local的运算。不同的是,non-local操作感受野可以很大,可以是全局区域,而不是一个局部区域。捕获长距离依赖(long-range dependencies),即如何建立图像上两个有一定距离的像素之间的联系,是一种注意力机制。所谓注意力机制就是利用网络生成saliency map,注意力对应的是显著性区域,是需要网络重点关注的区域。
首先分别对输入的特征图进行 1X1的卷积来压缩通道数,得到 特征。
通过reshape操作,转化三个特征的维度,然后对 进行矩阵乘操作,得到类似协方差矩阵, 这一步为了计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系。
然后对自相关特征进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention系数。
最后将 attention系数,对应乘回特征矩阵g上,与原输入 feature map X 残差相加输出即可。
这里我们结合一个简单例子理解一下,假设g为(我们暂时不考虑batch和channel维度):
g = torch.tensor([[1, 2], [3, 4]).view(-1, 1).float()
为:
theta = torch.tensor([2, 4, 6, 8]).view(-1, 1)
为:
phi = torch.tensor([7, 5, 3, 1]).view(1, -1)
那么, 和 矩阵相乘如下:
tensor([[14., 10., 6., 2.], [28., 20., 12., 4.], [42., 30., 18., 6.], [56., 40., 24., 8.]])
进过softmax(dim=-1)后如下,每一行代表着g里面的元素的重要程度,每一行前面的值比较大,因此希望多“注意”到g前面的元素,也就是1比较重要一点。或者这样理解:注意力矩阵代表着g中每个元素和其他元素的依赖程度。
tensor([[9.8168e-01, 1.7980e-02, 3.2932e-04, 6.0317e-06], [9.9966e-01, 3.3535e-04, 1.1250e-07, 3.7739e-11], [9.9999e-01, 6.1442e-06, 3.7751e-11, 2.3195e-16], [1.0000e+00, 1.1254e-07, 1.2664e-14, 1.4252e-21]])
注意力作用上之后,整体值向原始g中的值都向1靠拢:
tensor([[1.0187, 1.0003], [1.0000, 1.0000]])
核心代码:
class NonLocal(nn.Module): def __init__(self, channel): super(NonLocalBlock, self).__init__() self.inter_channel = channel // 2 self.conv_phi = nn.Conv2d(channel, self.inter_channel, 1, 1,0, False) self.conv_theta = nn.Conv2d(channel, self.inter_channel, 1, 1,0, False) self.conv_g = nn.Conv2d(channel, self.inter_channel, 1, 1, 0, False) self.softmax = nn.Softmax(dim=1) self.conv_mask = nn.Conv2d(self.inter_channel, channel, 1, 1, 0, False)
def forward(self, x): # [N, C, H , W] b, c, h, w = x.size() # 获取phi特征,维度为[N, C/2, H * W],注意是要保留batch和通道维度的,是在HW上进行的 x_phi = self.conv_phi(x).view(b, c, -1) # 获取theta特征,维度为[N, H * W, C/2] x_theta = self.conv_theta(x).view(b, c, -1).permute(0, 2, 1).contiguous() # 获取g特征,维度为[N, H * W, C/2] x_g = self.conv_g(x).view(b, c, -1).permute(0, 2, 1).contiguous() # 对phi和theta进行矩阵乘,[N, H * W, H * W] mul_theta_phi = torch.matmul(x_theta, x_phi) # softmax拉到0~1之间 mul_theta_phi = self.softmax(mul_theta_phi) # 与g特征进行矩阵乘运算,[N, H * W, C/2] mul_theta_phi_g = torch.matmul(mul_theta_phi, x_g) # [N, C/2, H, W] mul_theta_phi_g = mul_theta_phi_g.permute(0, 2, 1).contiguous().view(b, self.inter_channel, h, w) # 1X1卷积扩充通道数 mask = self.conv_mask(mul_theta_phi_g) out = mask + x # 残差连接 return out
4 SE
出自论文:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/pdf/1709.01507.pdf
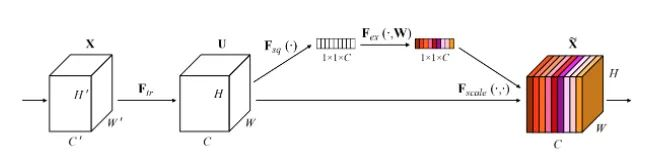
本文是ImageNet最后一届比赛的冠军作品,你会在很多经典网络结构中看到它的身影,例如Mobilenet v3。其实是一种通道注意力机制。由于特征压缩和FC的存在,其捕获的通道注意力特征是具有全局信息的。本文提出了一种新的结构单元——“Squeeze-and Excitation(SE)”模块,可以自适应的调整各通道的特征响应值,对通道间的内部依赖关系进行建模。有以下几个步骤:
Squeeze: 沿着空间维度进行特征压缩,将每个二维的特征通道变成一个数,是具有全局的感受野。
Excitation: 每个特征通道生成一个权重,用来代表该特征通道的重要程度。
Reweight:将Excitation输出的权重看做每个特征通道的重要性,通过相乘的方式作用于每一个通道上。
核心代码:
class SE_Block(nn.Module): def __init__(self, ch_in, reduction=16): super(SE_Block, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化 self.fc = nn.Sequential( nn.Linear(ch_in, ch_in // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(ch_in // reduction, ch_in, bias=False), nn.Sigmoid() )
def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) # squeeze操作 y = self.fc(y).view(b, c, 1, 1) # FC获取通道注意力权重,是具有全局信息的 return x * y.expand_as(x) # 注意力作用每一个通道上
5 CBAM
出自论文:CBAM: Convolutional Block Attention Module
论文链接:https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
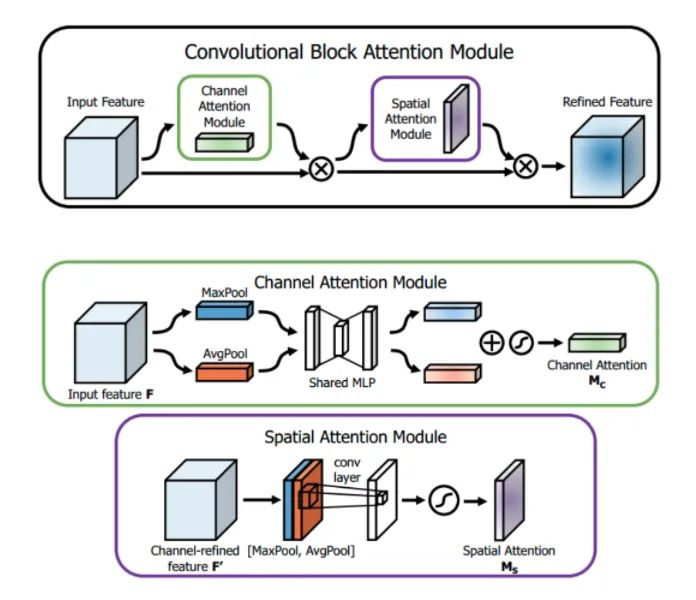
核心解析:
SENet在feature map的通道上进行attention权重获取,然后与原来的feature map相乘。这篇文章指出,该种attention方法法只关注了通道层面上哪些层会具有更强的反馈能力,但是在空间维度上并不能体现出attention。CBAM作为本文的亮点,将attention同时运用在channel和spatial两个维度上, CBAM与SE Module一样,可以嵌入在大部分的主流网络中,在不显著增加计算量和参数量的前提下能提升模型的特征提取能力。
通道注意力: 如上图所示,输入是一个 H×W×C 的特征F,我们先分别进两个空间的全局平均池化和最大池化得到 两个 1×1×C 的通道描述。再将它们分别送进一个两层的神经网络,第一层神经元个数为 C/r,激活函数为 Relu,第二层神经元个数为 C。注意,这个两层的神经网络是共享的。然后,再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc。最后,拿权重系数和 原来的特征 F 相乘即可得到缩放后的新特征。伪代码:
def forward(self, x): # 利用FC获取全局信息,和Non-local的矩阵相乘本质上式一样的 avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out)
空间注意力: 与通道注意力相似,给定一个 H×W×C 的特征 F‘,我们先分别进行一个通道维度的平均池化和最大池化得到两个 H×W×1 的通道描述,并将这两个描述按照通道拼接在一起。然后,经过一个 7×7 的卷积层, 激活函数为 Sigmoid,得到权重系数 Ms。最后,拿权重系数和特征 F’ 相乘即可得到缩放后的新特征。伪代码:
def forward(self, x): # 这里利用池化获取全局信息 avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x)
6 DCN v1&v2
插件全称:Deformable Convolutional
出自论文:
v1: [Deformable Convolutional Networks]
https://arxiv.org/pdf/1703.06211.pdf
v2: [Deformable ConvNets v2: More Deformable, Better Results]
https://arxiv.org/pdf/1811.11168.pdf
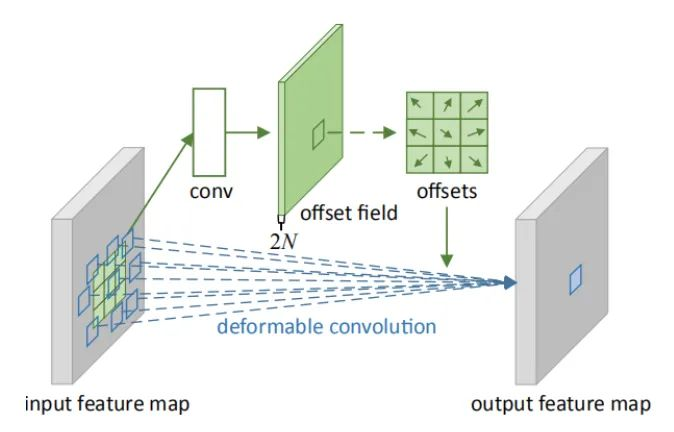
核心解析:
变形卷积可以看作变形+卷积两个部分,因此可以当作插件使用。在各大主流检测网络中,变形卷积真是涨点神器,网上解读也非常之多。和传统的固定窗口的卷积相比,变形卷积可以有效地对几何图形,因为它的“局部感受野”是可学习的,面向全图的。这篇论文同时提出了deformable ROI pooling,这两个方法都是增加额外偏移量的空间采样位置,不需要额外的监督,是自监督的过程。
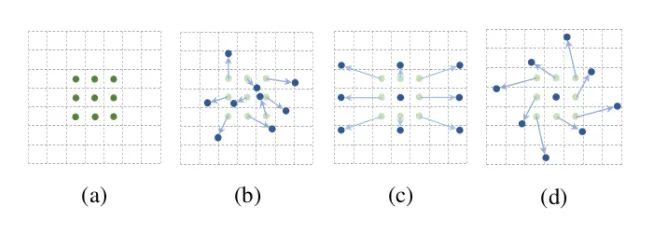
如上图所示,a为不同的卷积,b为变形卷积,深色的点为卷积核实际采样的位置,和“标准的”位置有一定的偏移。c和d为变形卷积的特殊形式,其中c为我们常见到的空洞卷积,d为具有学习旋转特性的卷积,也具备提升感受野的能力。
变形卷积和STN过程非常类似,STN是利用网络学习出空间变换的6个参数,对特征图进行整体变换,旨在增加网络对形变的提取能力。DCN是利用网络学习数整图offset,比STN的变形更“全面一点”。STN是仿射变换,DCN是任意变换。公式不贴了,可以直接看代码实现过程。
变形卷积具有V1和V2两个版本,其中V2是在V2的基础上进行改进,除了采样offset,还增加了采样权重。V2认为3X3采样点也应该具有不同的重要程度,因此该处理方法更具有灵活性和拟合能力。
核心代码:
def forward(self, x): # 学习出offset,包括x和y两个方向,注意是每一个channel中的每一个像素都有一个x和y的offset offset = self.p_conv(x) if self.v2: # V2的时候还会额外学习一个权重系数,经过sigmoid拉到0和1之间 m = torch.sigmoid(self.m_conv(x)) # 利用offset对x进行插值,获取偏移后的x_offset x_offset = self.interpolate(x,offset) if self.v2: # V2的时候,将权重系数作用到特征图上 m = m.contiguous().permute(0, 2, 3, 1) m = m.unsqueeze(dim=1) m = torch.cat([m for _ in range(x_offset.size(1))], dim=1) x_offset *= m out = self.conv(x_offset) # offset作用后,在进行标准的卷积过程 return out
7 CoordConv
出自论文:An intriguing failing of convolutional neural networks and the CoordConv solution
论文链接:https://arxiv.org/pdf/1807.03247.pdf
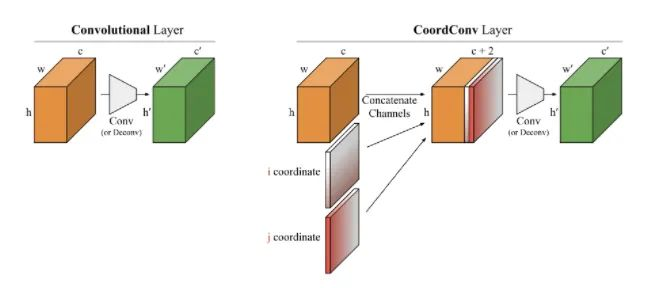
核心解析:
在Solo语义分割算法和Yolov5中你可以看到它的身影。本文从几个小实验为出发点,探究了卷积网络在坐标变换上的能力。就是它无法将空间表示转换成笛卡尔空间中的坐标。如下图所示,我们向一个网络中输入(i, j)坐标,要求它输出一个64×64的图像,并在坐标处画一个正方形或者一个像素,然而网络在测试集上却无法完成。虽然这项任务是我们人类认为极其简单的工作。分析原因是卷积作为一种局部的、共享权重的过滤器应用到输入上时,它是不知道每个过滤器在哪,无法捕捉位置信息的。因此我们可以帮助卷积,让它知道过滤器的位置。仅仅需要在输入上添加两个通道,一个是i坐标,另一个是j坐标。具体做法如上图所示,送入滤波器之前增加两个通道。这样,网络就具备了空间位置信息的能力,是不是很神奇?你可以随机在分类、分割、检测等任务中使用这种挂件。

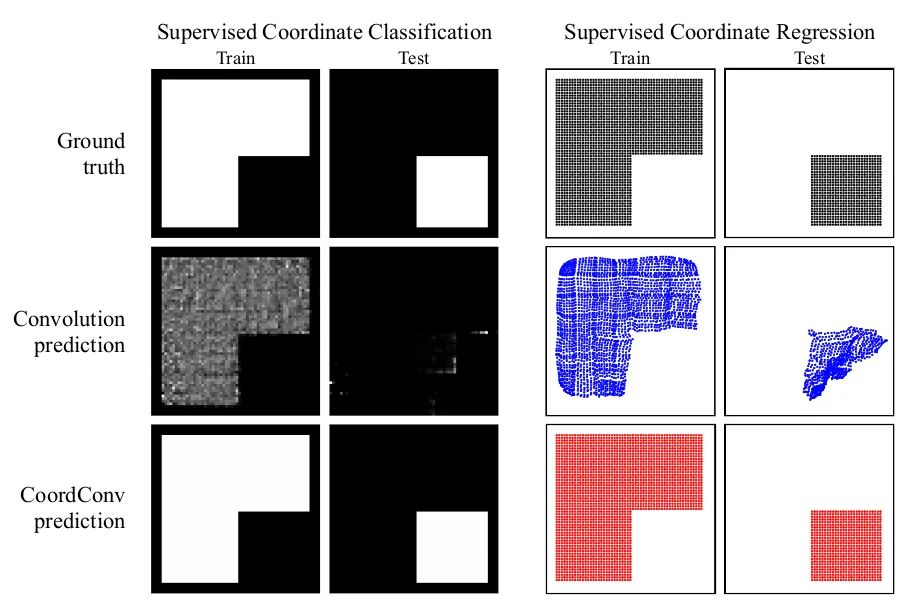
如上面第一组图片,传统的CNN在根据坐标数值生成图像的任务中,训练集很好,测试集一团糟。第二组图片增加了 CoordConv 之后可以轻松完成该任务,可见其增加了CNN空间感知的能力。
核心代码:
ins_feat = x # 当前实例特征tensor# 生成从-1到1的线性值x_range = torch.linspace(-1, 1, ins_feat.shape[-1], device=ins_feat.device)y_range = torch.linspace(-1, 1, ins_feat.shape[-2], device=ins_feat.device)y, x = torch.meshgrid(y_range, x_range) # 生成二维坐标网格y = y.expand([ins_feat.shape[0], 1, -1, -1]) # 扩充到和ins_feat相同维度x = x.expand([ins_feat.shape[0], 1, -1, -1])coord_feat = torch.cat([x, y], 1) # 位置特征ins_feat = torch.cat([ins_feat, coord_feat], 1) # concatnate一起作为下一个卷积的输入
8 Ghost
插件全称:Ghost module
出自论文:GhostNet: More Features from Cheap Operations
论文链接:https://arxiv.org/pdf/1911.11907.pdf
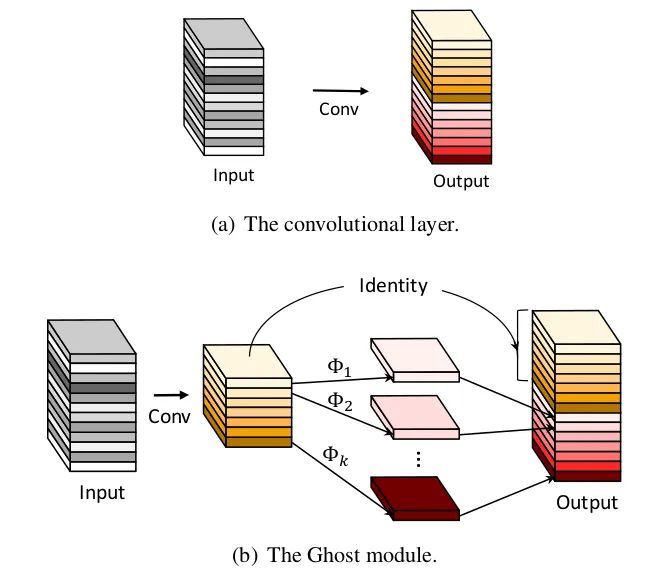
核心解析:
在ImageNet的分类任务上,GhostNet在相似计算量情况下Top-1正确率达75.7%,高于MobileNetV3的75.2%。其主要创新点就是提出了Ghost 模块。在CNN模型中,特征图是存在大量的冗余,当然这也是非常重要和有必要的。如下图所示,其中标“小扳手”的特征图都存在冗余的特征图。那么能否降低卷积的通道数,然后利用某种变换生成冗余的特征图?事实上这就是GhostNet的思路。

而本文就从特征图冗余问题出发,提出一个仅通过少量计算(论文称为cheap operations)就能生成大量特征图的结构——Ghost Module。而cheap operations就是线性变换,论文中采用卷积操作实现。具体过程如下:
使用比原始更少量卷积运算,比如正常用64个卷积核,这里就用32个,减少一半的计算量。
利用深度分离卷积,从上面生成的特征图中变换出冗余的特征。
上面两步获取的特征图concat起来输出,送入后续的环节。
核心代码:
class GhostModule(nn.Module): def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True): super(GhostModule, self).__init__() self.oup = oup init_channels = math.ceil(oup / ratio) new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential( nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False), nn.BatchNorm2d(init_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) # cheap操作,注意利用了分组卷积进行通道分离 self.cheap_operation = nn.Sequential( nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False), nn.BatchNorm2d(new_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(),)
def forward(self, x): x1 = self.primary_conv(x) #主要的卷积操作 x2 = self.cheap_operation(x1) # cheap变换操作 out = torch.cat([x1,x2], dim=1) # 二者cat到一起 return out[:,:self.oup,:,:]
9 BlurPool
出自论文:Making Convolutional Networks Shift-Invariant Again
论文链接:https://arxiv.org/abs/1904.11486
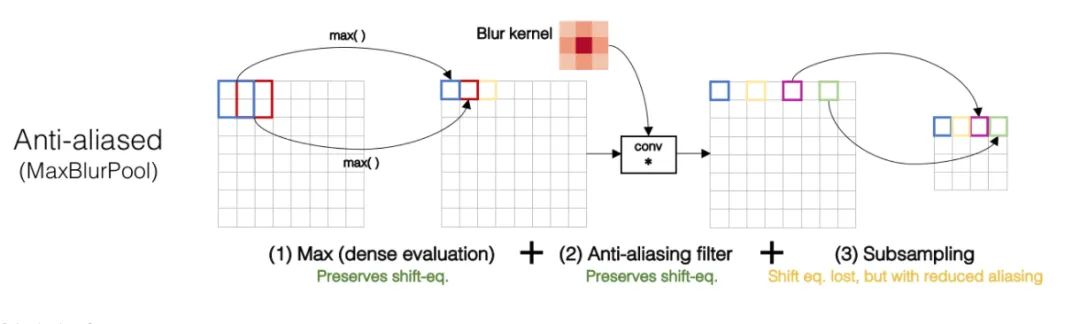
核心解析:
我们都知道,基于滑动窗口的卷积操作是具有平移不变性的,因此也默认为CNN网络具有平移不变性或等变性,事实上真的如此吗?实践发现,CNN网络真的非常敏感,只要输入图片稍微改一个像素,或者平移一个像素,CNN的输出就会发生巨大的变化,甚至预测错误。这可是非常不具有鲁棒性的。一般情况下我们利用数据增强获取所谓的不变性。本文研究发现,不变性的退化根本原因就在于下采样,无论是Max Pool还是Average Pool,抑或是stride>1的卷积操作,只要是涉及步长大于1的下采样,均会导致平移不变性的丢失。具体示例如下图所示,仅仅平移一个像素,Max pool的结果就差距很大。
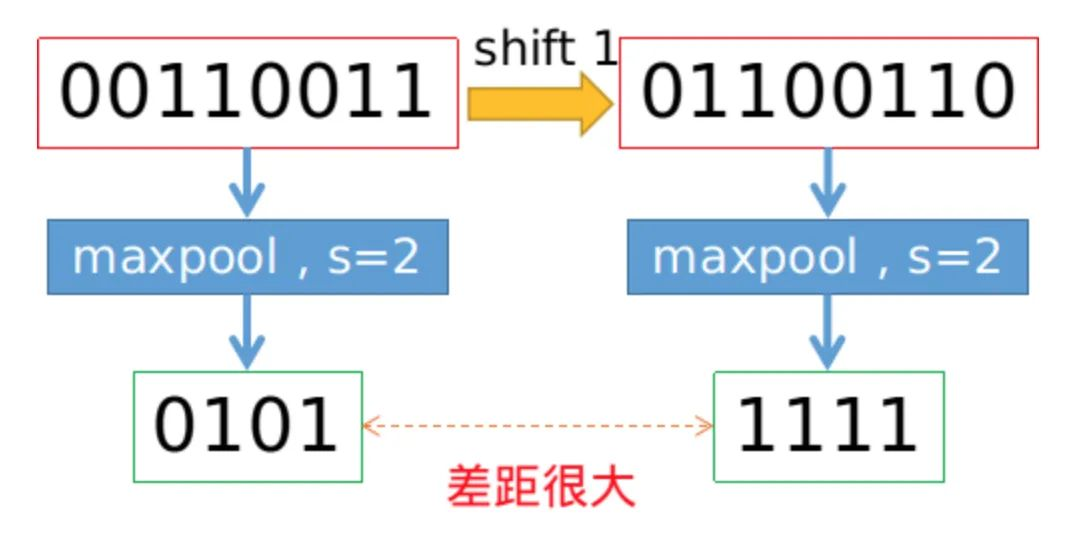
为了保持平移不变性,可以在下采样之前进行低通滤波。传统的max pool可以分解为两部分,分别是stride = 1的max + 下采样 。因此作者提出的MaxBlurPool = max + blur + 下采样来替代原始的max pool。实验发现,该操作虽然不能彻底解决平移不变性的丢失,但是可以很大程度上缓解。
核心代码:
class BlurPool(nn.Module): def __init__(self, channels, pad_type='reflect', filt_size=4, stride=2, pad_off=0): super(BlurPool, self).__init__() self.filt_size = filt_size self.pad_off = pad_off self.pad_sizes = [int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2)), int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2))] self.pad_sizes = [pad_size+pad_off for pad_size in self.pad_sizes] self.stride = stride self.off = int((self.stride-1)/2.) self.channels = channels # 定义一系列的高斯核 if(self.filt_size==1): a = np.array([1.,]) elif(self.filt_size==2): a = np.array([1., 1.]) elif(self.filt_size==3): a = np.array([1., 2., 1.]) elif(self.filt_size==4): a = np.array([1., 3., 3., 1.]) elif(self.filt_size==5): a = np.array([1., 4., 6., 4., 1.]) elif(self.filt_size==6): a = np.array([1., 5., 10., 10., 5., 1.]) elif(self.filt_size==7): a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = torch.Tensor(a[:,None]*a[None,:]) filt = filt/torch.sum(filt) # 归一化操作,保证特征经过blur后信息总量不变 # 非grad操作的参数利用buffer存储 self.register_buffer('filt', filt[None,None,:,:].repeat((self.channels,1,1,1))) self.pad = get_pad_layer(pad_type)(self.pad_sizes)
def forward(self, inp): if(self.filt_size==1): if(self.pad_off==0): return inp[:,:,::self.stride,::self.stride] else: return self.pad(inp)[:,:,::self.stride,::self.stride] else: # 利用固定参数的conv2d+stride实现blurpool return F.conv2d(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])
10 RFB
插件全称:Receptive Field Block
出自论文:Receptive Field Block Net for Accurate and Fast Object Detection
论文链接:https://arxiv.org/abs/1711.07767

核心解析:
论文发现目标区域要尽量靠近感受野中心,这会有助于提升模型对小尺度空间位移的鲁棒性。因此受人类视觉RF结构的启发,本文提出了感受野模块(RFB),加强了CNN模型学到的深层特征的能力,使检测模型更加准确。RFB可以作为一种通用模块嵌入到绝大多数网路当中。下图可以看出其和inception、ASPP、DCN的区别,可以看作是inception+ASPP的结合。
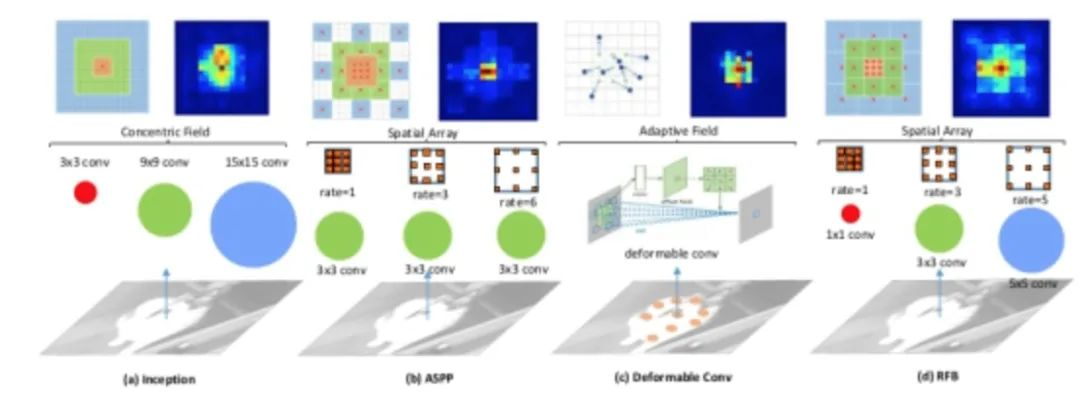
具体实现如下图,其实和ASPP类似,不过是使用了不同大小的卷积核作为空洞卷积的前置操作。
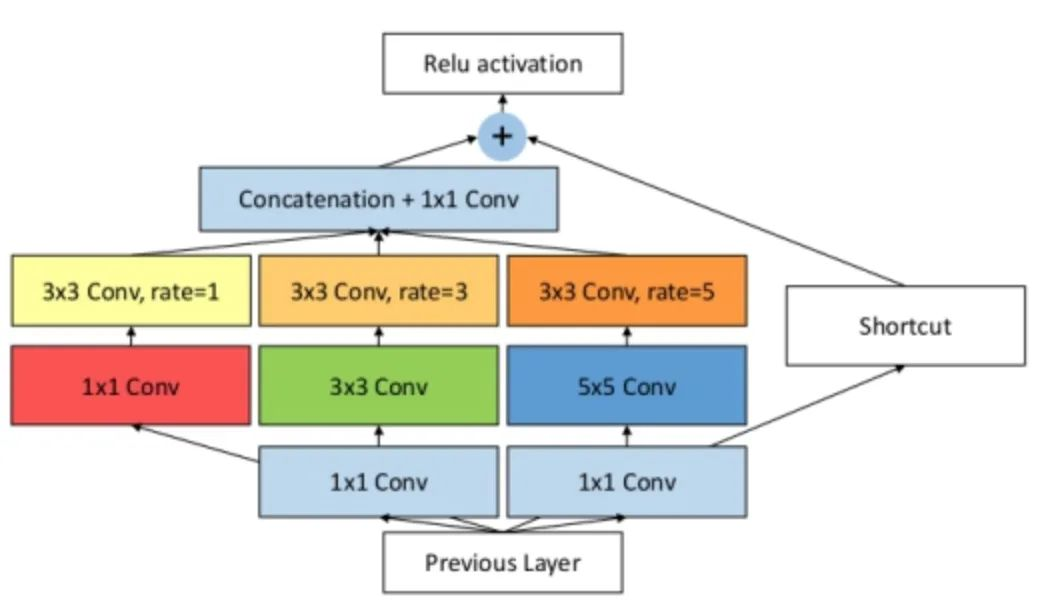
核心代码:
class RFB(nn.Module): def __init__(self, in_planes, out_planes, stride=1, scale = 0.1, visual = 1): super(RFB, self).__init__() self.scale = scale self.out_channels = out_planes inter_planes = in_planes // 8 # 分支0:1X1卷积+3X3卷积 self.branch0 = nn.Sequential(conv_bn_relu(in_planes, 2*inter_planes, 1, stride), conv_bn_relu(2*inter_planes, 2*inter_planes, 3, 1, visual, visual, False)) # 分支1:1X1卷积+3X3卷积+空洞卷积 self.branch1 = nn.Sequential(conv_bn_relu(in_planes, inter_planes, 1, 1), conv_bn_relu(inter_planes, 2*inter_planes, (3,3), stride, (1,1)), conv_bn_relu(2*inter_planes, 2*inter_planes, 3, 1, visual+1,visual+1,False)) # 分支2:1X1卷积+3X3卷积*3代替5X5卷积+空洞卷积 self.branch2 = nn.Sequential(conv_bn_relu(in_planes, inter_planes, 1, 1), conv_bn_relu(inter_planes, (inter_planes//2)*3, 3, 1, 1), conv_bn_relu((inter_planes//2)*3, 2*inter_planes, 3, stride, 1), conv_bn_relu(2*inter_planes, 2*inter_planes, 3, 1, 2*visual+1, 2*visual+1,False) ) self.ConvLinear = conv_bn_relu(6*inter_planes, out_planes, 1, 1, False) self.shortcut = conv_bn_relu(in_planes, out_planes, 1, stride, relu=False) self.relu = nn.ReLU(inplace=False) def forward(self,x): x0 = self.branch0(x) x1 = self.branch1(x) x2 = self.branch2(x) # 尺度融合 out = torch.cat((x0,x1,x2),1) # 1X1卷积 out = self.ConvLinear(out) short = self.shortcut(x) out = out*self.scale + short out = self.relu(out) return out
11 ASFF
插件全称:Adaptively Spatial Feature Fusion
出自论文:Adaptively Spatial Feature Fusion Learning Spatial Fusion for Single-Shot Object Detection
论文链接:https://arxiv.org/abs/1911.09516v1
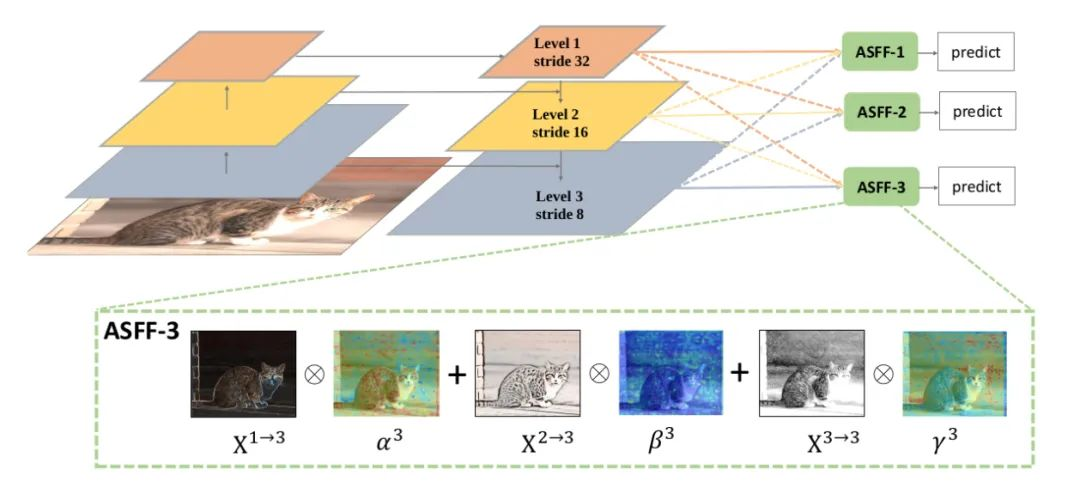
核心解析:
为了更加充分的利用高层语义特征和底层细粒度特征,很多网络都会采用FPN的方式输出多层特征,但是它们都多用concat或者element-wise这种融合方式,本论文认为这样不能充分利用不同尺度的特征,所以提出了Adaptively Spatial Feature Fusion,即自适应特征融合方式。FPN输出的特征图经过下面两部分的处理:
Feature Resizing:特征图的尺度不同无法进行element-wise融合,因此需要进行resize。对于上采样:首先利用1X1卷积进行通道压缩,然后利用插值的方法上采样特征图。对于1/2的下采样:利用stride=2的3X3卷积同时进行通道压缩和特征图缩小。对于1/4的下采样:在stride=2的3X3的卷积之前插入tride=2的maxpooling。
Adaptive Fusion:特征图自适应融合,公式如下
其中x n→l表示在(i,j)位置的特征向量,来自n特征图,经过上述resize到l尺度。Alpha。Beta,gamma为空间注意力权重,经过softmax处理,如下:
代码解析:
class ASFF(nn.Module): def __init__(self, level, rfb=False): super(ASFF, self).__init__() self.level = level # 输入的三个特征层的channels, 根据实际修改 self.dim = [512, 256, 256] self.inter_dim = self.dim[self.level] # 每个层级三者输出通道数需要一致 if level==0: self.stride_level_1 = conv_bn_relu(self.dim[1], self.inter_dim, 3, 2) self.stride_level_2 = conv_bn_relu(self.dim[2], self.inter_dim, 3, 2) self.expand = conv_bn_relu(self.inter_dim, 1024, 3, 1) elif level==1: self.compress_level_0 = conv_bn_relu(self.dim[0], self.inter_dim, 1, 1) self.stride_level_2 = conv_bn_relu(self.dim[2], self.inter_dim, 3, 2) self.expand = conv_bn_relu(self.inter_dim, 512, 3, 1) elif level==2: self.compress_level_0 = conv_bn_relu(self.dim[0], self.inter_dim, 1, 1) if self.dim[1] != self.dim[2]: self.compress_level_1 = conv_bn_relu(self.dim[1], self.inter_dim, 1, 1) self.expand = add_conv(self.inter_dim, 256, 3, 1) compress_c = 8 if rfb else 16 self.weight_level_0 = conv_bn_relu(self.inter_dim, compress_c, 1, 1) self.weight_level_1 = conv_bn_relu(self.inter_dim, compress_c, 1, 1) self.weight_level_2 = conv_bn_relu(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, 1, 1, 0)
# 尺度大小 level_0 < level_1 < level_2 def forward(self, x_level_0, x_level_1, x_level_2): # Feature Resizing过程 if self.level==0: level_0_resized = x_level_0 level_1_resized = self.stride_level_1(x_level_1) level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1) level_2_resized = self.stride_level_2(level_2_downsampled_inter) elif self.level==1: level_0_compressed = self.compress_level_0(x_level_0) level_0_resized =F.interpolate(level_0_compressed, 2, mode='nearest') level_1_resized =x_level_1 level_2_resized =self.stride_level_2(x_level_2) elif self.level==2: level_0_compressed = self.compress_level_0(x_level_0) level_0_resized =F.interpolate(level_0_compressed, 4, mode='nearest') if self.dim[1] != self.dim[2]: level_1_compressed = self.compress_level_1(x_level_1) level_1_resized = F.interpolate(level_1_compressed, 2, mode='nearest') else: level_1_resized =F.interpolate(x_level_1, 2, mode='nearest') level_2_resized =x_level_2 # 融合权重也是来自于网络学习 level_0_weight_v = self.weight_level_0(level_0_resized) level_1_weight_v = self.weight_level_1(level_1_resized) level_2_weight_v = self.weight_level_2(level_2_resized) levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1) levels_weight = self.weight_levels(levels_weight_v) levels_weight = F.softmax(levels_weight, dim=1) # alpha产生 # 自适应融合 fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\ level_1_resized * levels_weight[:,1:2,:,:]+\ level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced) return out
结语
本文盘点了近年来比较精巧而又实用的CNN插件,希望大家活学活用,用在自己的实际项目中。
◎作者档案
皮特潘,致力于AI落地而上下求索
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: