完整代码参考添加链接描述
寒武纪cnnl实现卷积的库函数说明参考添加链接描述
cnnl调用卷积的函数这里我们使用的是cnnlConvolutionForward,这个函数的使用只是最后的计算过程,但是在计算之前,还有许多准备工作。下图展示了一个完整的cnnl调库实现卷积的全过程,事实上,cnnl调用其他库函数的过程也于此类似:
1:申明一个descriptor,比如说这里申明的是卷积的描述器convDesc
2:申明好相关的descriptor以后,调用create函数创建这个描述器
3:创建好descriptor以后,借助set函数往这个描述器里面填充相关的信息,比如说这个卷积描述器里面填充的是pad向量,strides以及dilations向量,这三个向量主要描述卷积过程的一些特征。
4:申明卷积过程使用的具体算法algo,在寒武纪调库里面,实现一个算子往往可以有多种算法,不同的算法在实现速度精度上可能有差异,因此需要人为指定具体调用的算法是什么。
5:申请一定的device端内存,这部分内存空间可以理解为在实际计算conv过程中可能带来的中间变量存储空间,计算好需要的内存空间convSize以后,就可以在device开辟内存
6:调用库函数计算
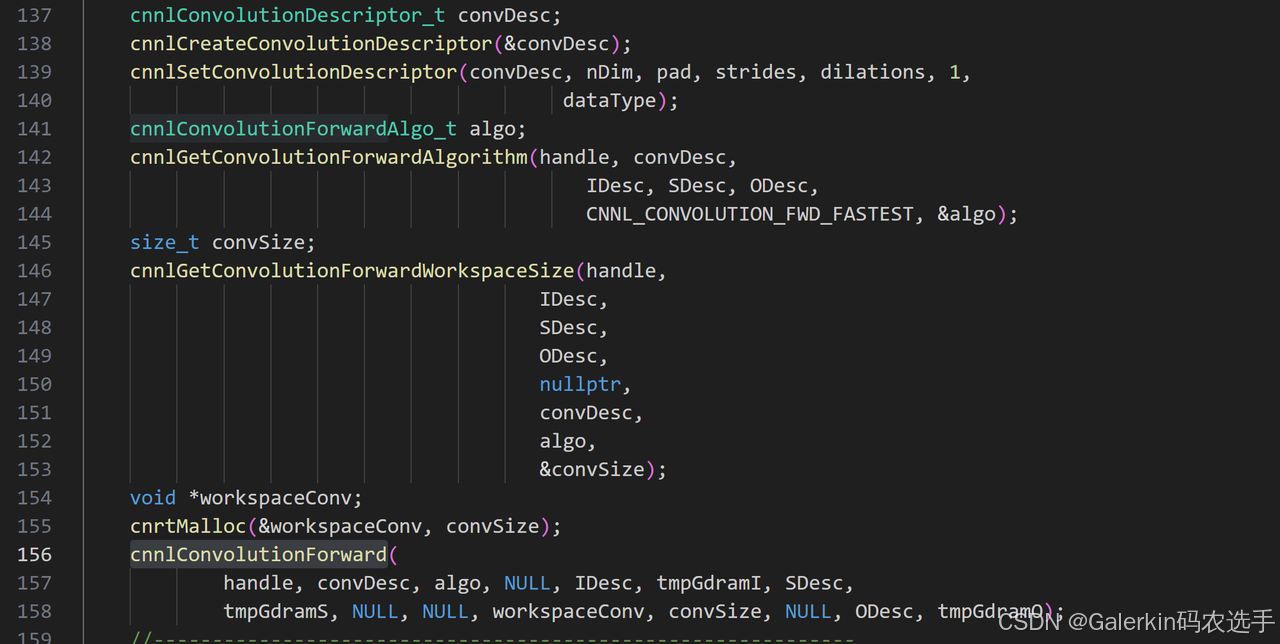
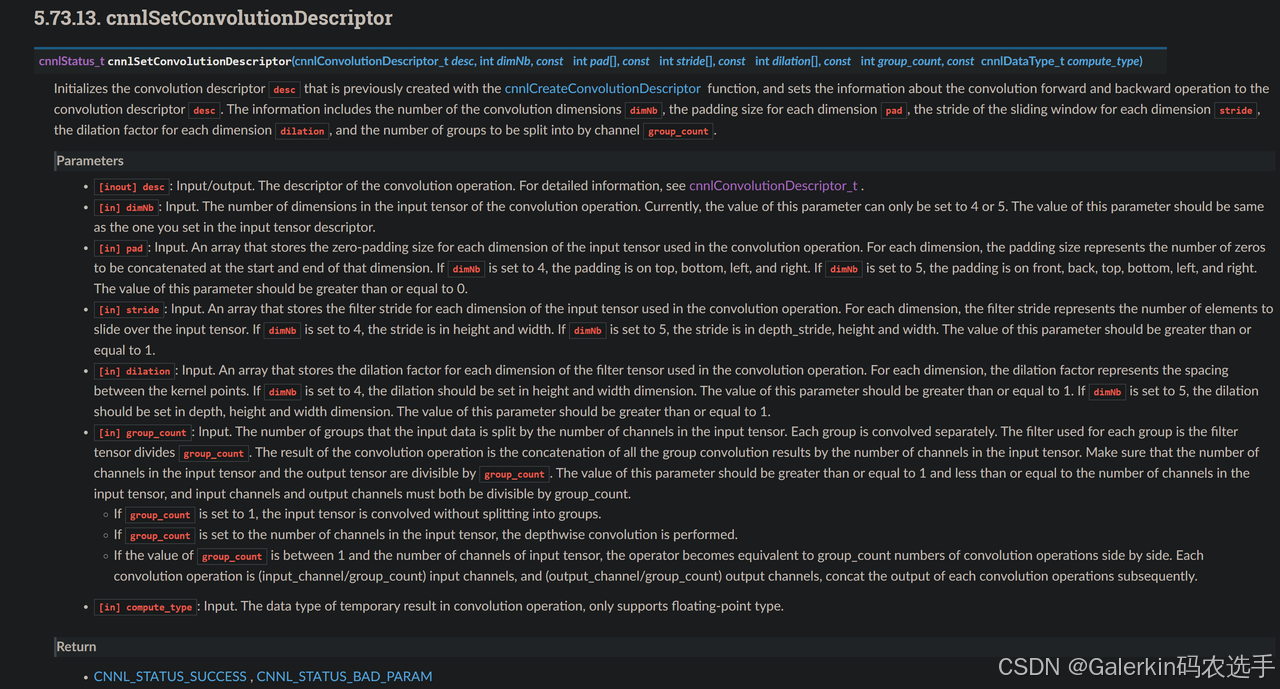
cnnlSetConvolutionDescriptor
上面这个过程遇到的第一个难点就在于convDesc的填充,这里参考官网的说明添加链接描述
我们稍微解释一下这个函数里面不同参数的意义以及使用方式。
dimNb:这个参数其实就是描述目前的卷积到底针对的是多少维的向量,目前cnnl的卷积算子仅仅支持4维或者5维向量的计算,因此这个dimNb目前只能选取4或者5.
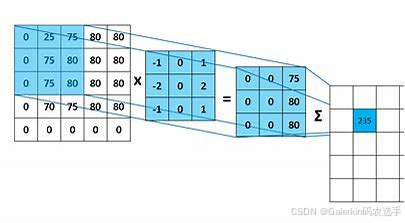
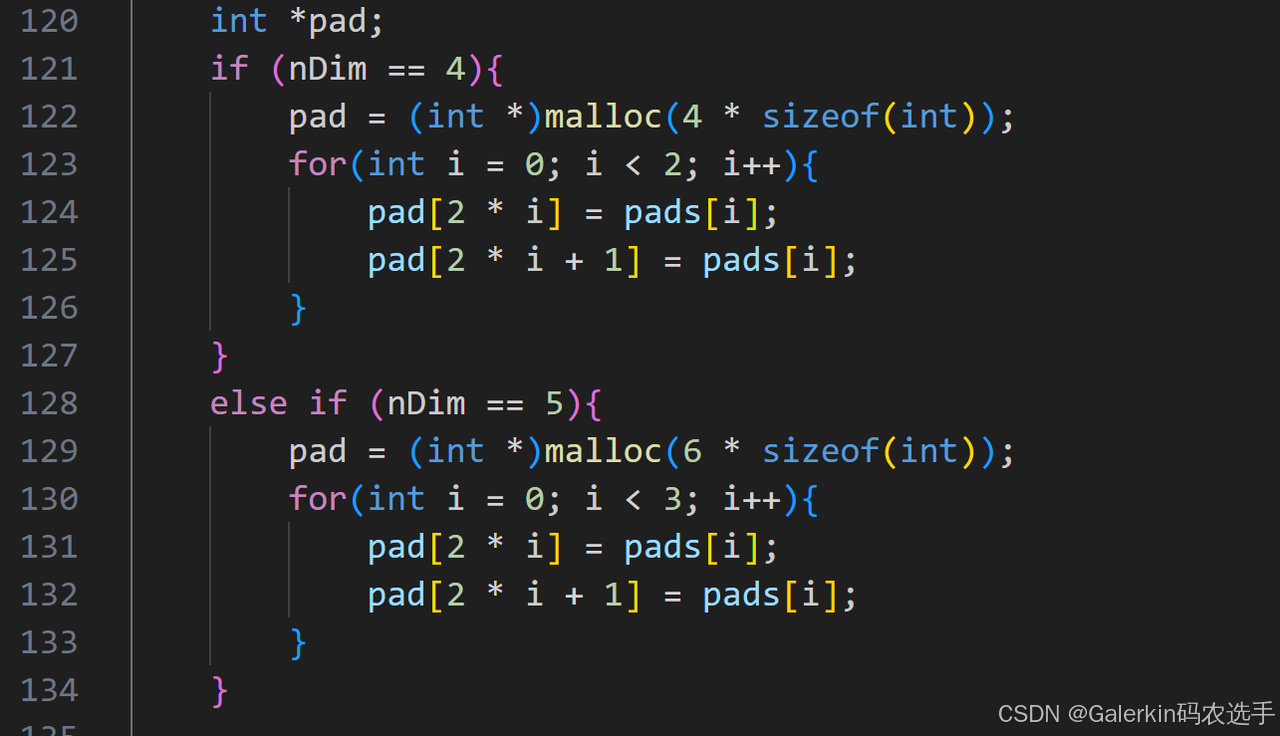
pad:这是一个整数向量,如果dimNb=4,那么pad长度也是4,表示四个方向的padding数目,如果dimNb=5,那么pad是一个长度为6的向量,表示6个方向的padding数目,但是我们看测试脚本里面,对于dimNb=4,我们传入的pad向量长度为2,这是因为我们默认padding是对称的,所以只提供两个方向的padding数目,因此实际编写cnnl代码的时候,这个地方需要针对pad做处理,处理方式如下图所示:
stride和dilations不需要特殊处理,直接从python端传入即可。
group_count:这个参数的用法暂时不详,这里默认使用group_count=1
compute_type:这个地方传入数据类型,可以是CNNL_DTYPE_HALF或者CNNL_DTYPE_FLOAT
后面的cnnlGetConvolutionForwardAlgorithm,cnnlGetConvolutionForwardWorkspaceSize以及cnnlConvolutionForward都相对简单,这里不赘述。
nchw和nhwc的相互转换
调用cnnlConv算子的时候,有一个特别值得注意的地方,cnnlConv默认支持的数据是4维或者5维向量,并且向量的形状为[N,H,W,C]或者是[N,D,H,W,C],这里就有一个问题,一般来说,我们接触的数据都是[N,C,H,W]或者是[N,C,D,H,W]的,为了保证结果正确,在调用卷积函数之前,我们首先需要把input,scale这两个向量做一个转换。比如说当ndim=4的时候,从python传入的input,scale形状都是[N,C,H,W]的,那么我们需要申请两份内存,构建两个向量tmpGdramI和tmpGdramS,针对input和scale做转置,并且把转置以后的结果存在tmpGdramI和tmpGdramS里面,此时tmpGdramI = [N,H,W,C],tmpGdramS=[N,H,W,C]。我们将tmpGdramI和tmpGdramS作为卷积函数的输入,得到结果也是[N,H,W,C],此时我们还需要申请一份内存,构建一个向量tmpGdramO=[N,H,W,C]作为前面的卷积计算结果,计算结束以后,最后再做一次转置,把tmpGdramO的结果转置到output里面。下面我们来看看这个转置过程是怎么操作的。
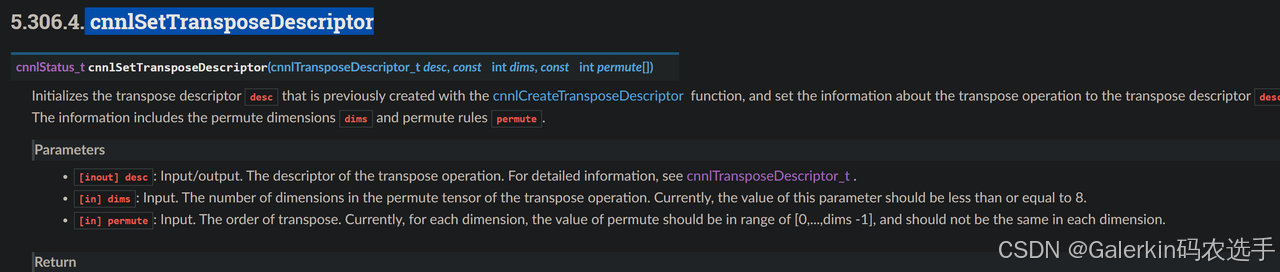
Transpose
寒武纪调库实现转置的函数是cnnlTranspose_v2,链接参考添加链接描述
和上面的卷积一样,transpose的难点也在于 cnnlSetTransposeDescriptor,参考下图。
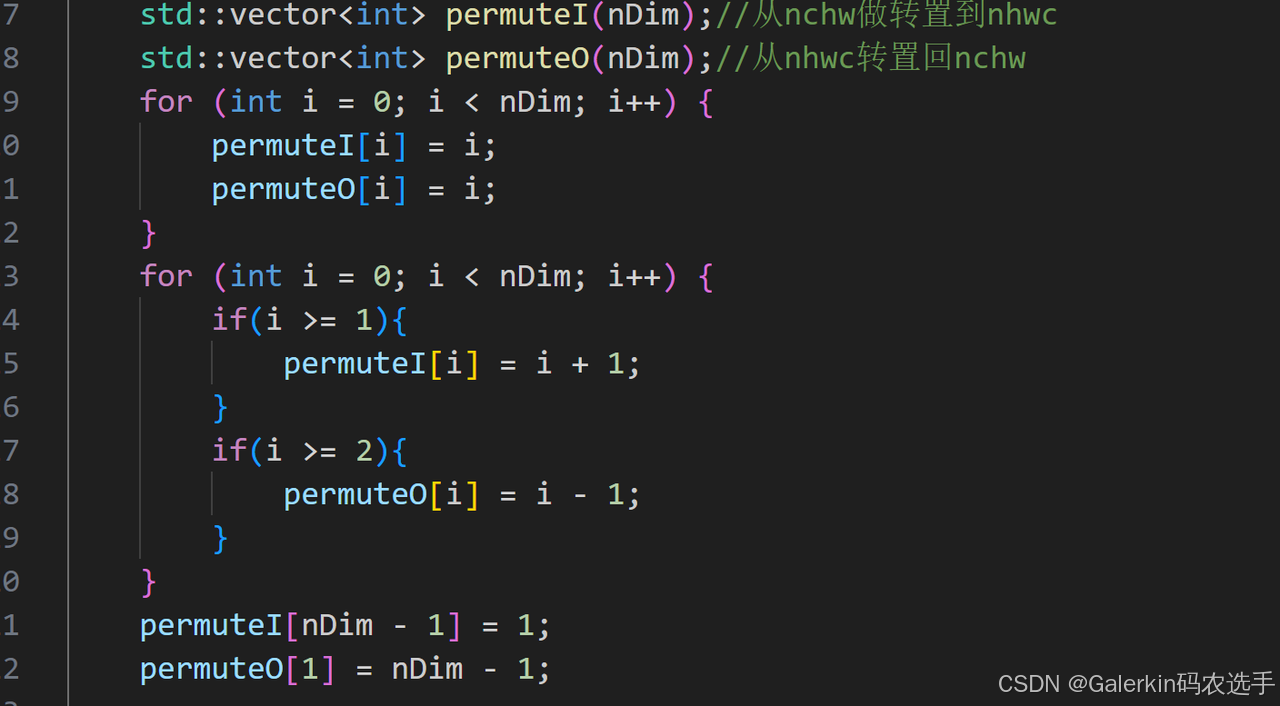
这里唯一需要注意的就是permute这个向量的选取了,我们考虑input和scale的转置过程,发现这个时候的操作是NCHW2NHWC,那么对应的permuteI=[0,2,3,1],如果是5维向量,对于input,scale来说操作是NCDHW2NDHWC,此时对应的permuteI=[0,2,3,4,1]。等到卷积结束以后,最后我们需要针对tmpGdramO转置回output,此时操作是NHWC2NCHW,那么对应的permuteO=[0,3,1,2],如果是5维向量,对应的permuteO=[0,4,1,2,3],这个permute计算参考下面这段代码,这个transpose总的来说实现相对简单,唯一的问题是里面涉及到input,scale,output三个向量的转置,而且input,scale的转置方向和output不一样,这里特别注意别搞错了。
为了避免转置出现混乱,这里我们引入了6个描述器:
x_desc:对应的是input的向量描述,数据排布方式是[N,C,H,W],对应的形状是[inputShape[0],inputShape[1],inputShape[2],inputShape[3]]
w_desc:对应的是scale的向量描述,数据排布方式是[N,C,H,W],对应的形状是[scaleShape[0],scaleShape[1],scaleShape[2],scaleShape[3]]
y_desc:对应的是output的向量描述,数据排布方式是[N,C,H,W],对应的形状是[outputShape[0],outputShape[1],outputShape[2],outputShape[3]]
IDesc:对应的是input的向量描述,数据排布方式是[N,H,W,C],对应的形状是[inputShape[0],inputShape[3],inputShape[1],inputShape[2]]
SDesc:对应的是scale的向量描述,数据排布方式是[N,H,W,C],对应的形状是[scaleShape[0],scaleShape[3],scaleShape[1],scaleShape[2]]
ODesc:对应的是output的向量描述,数据排布方式是[N,H,W,C],对应的形状是[outputShape[0],outputShape[3],outputShape[1],outputShape[2]]
ndim=3的处理方式
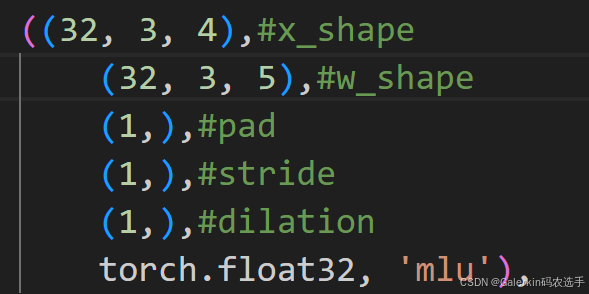
上面提到cnnlConv只能处理4维,5维向量,但是我们进一步想要测试三维向量的卷积,我们来看三维向量卷积传入的inputshape,scaleshape以及pad,stride,dilation的形状。
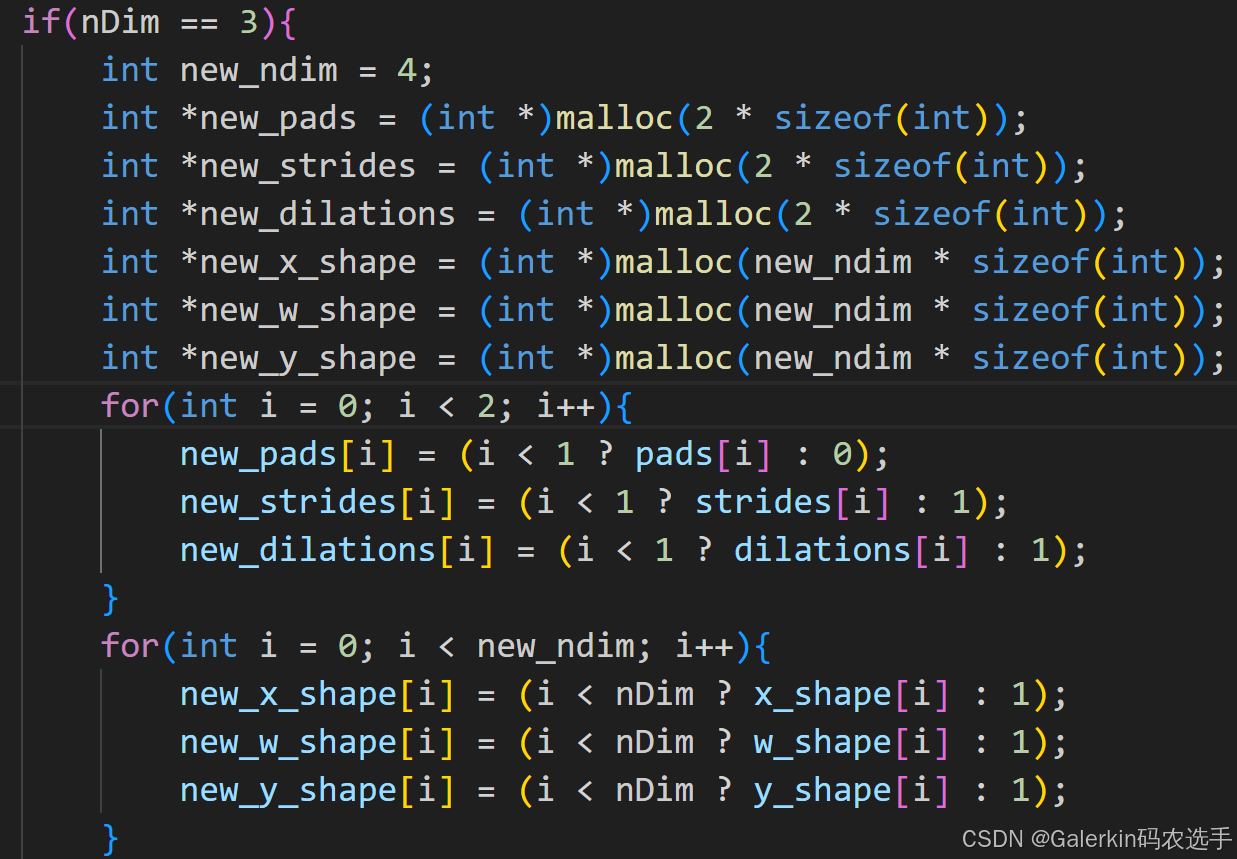
为了解决cnnlConv无法处理三维向量的问题,这个时候就需要手动填充,把3维向量对应的pad,stride,dilation,以及三个向量的shape全部重新修改,修改成四维向量。填充方式如下所示,这种填充其实就是在四维向量的基础上,保持一个对称方向不做任何修改即可。
convolution.cpp
#include "cnnl.h"
#include <vector>
template<typename T>
void convolutionCnnlDevice(void const *input, void const *scale, void *output, int *pads, int *strides, int *dilations, int *x_shape, int *w_shape, int *y_shape, int nDim, cnnlHandle_t &handle, cnrtQueue_t &queue){
//nDim = len(w_shape) = len(x_shape) = len(y_shape)
std::vector<int> permuteI(nDim);//从nchw做转置到nhwc
std::vector<int> permuteO(nDim);//从nhwc转置回nchw
for (int i = 0; i < nDim; i++) {
permuteI[i] = i;
permuteO[i] = i;
}
for (int i = 0; i < nDim; i++) {
if(i >= 1){
permuteI[i] = i + 1;
}
if(i >= 2){
permuteO[i] = i - 1;
}
}
permuteI[nDim - 1] = 1;
permuteO[1] = nDim - 1;
std::vector<int> inDim(nDim);//原始input的形状为[n,c,h,w]
std::vector<int> wDim(nDim);
std::vector<int> outDim(nDim);
int x_size = 1;//表示input的size
int w_size = 1;//表示scale的size
int y_size = 1;//表示output的size
for (int i = 0; i < nDim; i++) {
inDim[i] = x_shape[i];
outDim[i] = y_shape[i];
wDim[i] = w_shape[i];
x_size *= x_shape[i];
w_size *= w_shape[i];
y_size *= y_shape[i];
}
std::vector<int> x_tranDim(nDim);//tmpGdramI的形状
std::vector<int> w_tranDim(nDim);//tmpGdramS的形状
std::vector<int> y_tranDim(nDim);//tmpGdramO的形状
for(int i = 0; i < nDim; i++){
x_tranDim[i] = x_shape[permuteI[i]];
w_tranDim[i] = w_shape[permuteI[i]];
y_tranDim[i] = y_shape[permuteI[i]];
}
cnnlTensorLayout_t layoutI;//cnnlConv只支持nDim=4,5
cnnlTensorLayout_t layoutO;
if(nDim == 4){
layoutI = CNNL_LAYOUT_NCHW;
layoutO = CNNL_LAYOUT_NHWC;
}
else if(nDim == 5){
layoutI = CNNL_LAYOUT_NCDHW;
layoutO = CNNL_LAYOUT_NDHWC;
}
cnnlDataType_t dataType;
if(sizeof(T) == 2){
dataType = CNNL_DTYPE_HALF;
}
else if(sizeof(T) == 4){
dataType = CNNL_DTYPE_FLOAT;
}
//由于cnnl支持的操作是nhwc,所以需要提前对数据做permute
T *tmpGdramI, *tmpGdramS, *tmpGdramO;//conv库函数只能处理[n,h,w,c],tmpGdramI作为转置来变换input
CNRT_CHECK(cnrtMalloc((void **)&tmpGdramI, x_size * sizeof(T)));
CNRT_CHECK(cnrtMalloc((void **)&tmpGdramS, w_size * sizeof(T)));
CNRT_CHECK(cnrtMalloc((void **)&tmpGdramO, y_size * sizeof(T)));
cnnlTensorDescriptor_t x_desc, w_desc, y_desc, IDesc, SDesc, ODesc;
cnnlCreateTensorDescriptor(&x_desc);
cnnlCreateTensorDescriptor(&w_desc);
cnnlCreateTensorDescriptor(&y_desc);
cnnlCreateTensorDescriptor(&IDesc);
cnnlCreateTensorDescriptor(&SDesc);
cnnlCreateTensorDescriptor(&ODesc);
cnnlSetTensorDescriptor(
x_desc, layoutI, dataType,
inDim.size(), inDim.data());//原始input,nchw
cnnlSetTensorDescriptor(
IDesc, layoutO, dataType,
x_tranDim.size(), x_tranDim.data());//转置以后的input,nhwc
cnnlSetTensorDescriptor(
w_desc, layoutI, dataType,
wDim.size(), wDim.data());//原始scale, nchw
cnnlSetTensorDescriptor(
SDesc, layoutO, dataType,
w_tranDim.size(), w_tranDim.data());//转置以后的scale,nhwc
cnnlSetTensorDescriptor(
y_desc, layoutI, dataType,
outDim.size(), outDim.data());
cnnlSetTensorDescriptor(
ODesc, layoutO, dataType,
y_tranDim.size(), y_tranDim.data());
cnnlTransposeDescriptor_t desc;
cnnlCreateTransposeDescriptor(&desc);
cnnlSetTransposeDescriptor(desc, nDim, permuteI.data());
//然后针对input做转置nchw2nhwc
size_t tSizeI;
cnnlGetTransposeWorkspaceSize(handle, x_desc, desc, &tSizeI);
void *workspaceI;
cnrtMalloc(&workspaceI, tSizeI);
cnnlTranspose_v2(handle, desc, x_desc, input, IDesc,
tmpGdramI, workspaceI, tSizeI);
CNRT_CHECK(cnrtQueueSync(queue));
//然后针对scale做转置nchw2nhwc
size_t tSizeS;
cnnlGetTransposeWorkspaceSize(handle, w_desc, desc, &tSizeS);
void *workspaceS;
cnrtMalloc(&workspaceS, tSizeS);
cnnlTranspose_v2(handle, desc, w_desc, scale, SDesc,
tmpGdramS, workspaceS, tSizeS);
CNRT_CHECK(cnrtQueueSync(queue));
//------------------------------------------------------------
//上面成功对input, scale做好了nchw2nhwc,下面开始正式计算conv
int *pad;
if (nDim == 4){
pad = (int *)malloc(4 * sizeof(int));
for(int i = 0; i < 2; i++){
pad[2 * i] = pads[i];
pad[2 * i + 1] = pads[i];
}
}
else if (nDim == 5){
pad = (int *)malloc(6 * sizeof(int));
for(int i = 0; i < 3; i++){
pad[2 * i] = pads[i];
pad[2 * i + 1] = pads[i];
}
}
cnnlConvolutionDescriptor_t convDesc;
cnnlCreateConvolutionDescriptor(&convDesc);
cnnlSetConvolutionDescriptor(convDesc, nDim, pad, strides, dilations, 1,
dataType);
cnnlConvolutionForwardAlgo_t algo;
cnnlGetConvolutionForwardAlgorithm(handle, convDesc,
IDesc, SDesc, ODesc,
CNNL_CONVOLUTION_FWD_FASTEST, &algo);
size_t convSize;
cnnlGetConvolutionForwardWorkspaceSize(handle,
IDesc,
SDesc,
ODesc,
nullptr,
convDesc,
algo,
&convSize);
void *workspaceConv;
cnrtMalloc(&workspaceConv, convSize);
cnnlConvolutionForward(
handle, convDesc, algo, NULL, IDesc, tmpGdramI, SDesc,
tmpGdramS, NULL, NULL, workspaceConv, convSize, NULL, ODesc, tmpGdramO);
//------------------------------------------------------------
//下面开始提前对output做转置:nhwc2nchw,此时需要重新设置aDesc和cDesc,desc
size_t tSizeO;
cnnlGetTransposeWorkspaceSize(handle, ODesc, desc, &tSizeO);
void *workspaceO;
cnrtMalloc(&workspaceO, tSizeO);
cnnlSetTransposeDescriptor(desc, nDim, permuteO.data());
cnnlTranspose_v2(handle, desc, ODesc, tmpGdramO, y_desc,
output, workspaceO, tSizeO);
CNRT_CHECK(cnrtQueueSync(queue));
free(pad);
cnrtFree(tmpGdramI);
cnrtFree(tmpGdramS);
cnrtFree(tmpGdramO);
cnrtFree(workspaceI);
cnrtFree(workspaceConv);
cnrtFree(workspaceS);
cnrtFree(workspaceO);
cnnlDestroyTensorDescriptor(IDesc);
cnnlDestroyTensorDescriptor(SDesc);
cnnlDestroyTensorDescriptor(ODesc);
cnnlDestroyTransposeDescriptor(desc);
cnnlDestroyTensorDescriptor(x_desc);
cnnlDestroyTensorDescriptor(w_desc);
cnnlDestroyTensorDescriptor(y_desc);
cnnlDestroyConvolutionDescriptor(convDesc);
}
template<typename T>
void convolutionCnnl(void const *input, void const *scale, void *output, int *pads, int *strides, int *dilations, int *x_shape, int *w_shape, int *y_shape, int nDim)
{
CNRT_CHECK(cnrtSetDevice(0));
cnnlHandle_t handle;
cnnlCreate(&handle);
cnrtQueue_t queue;
CNRT_CHECK(cnrtQueueCreate(&queue));
cnnlSetQueue(handle, queue); // 将队列绑定到 handle 中, 此接口也可用来更改句柄中的队列。
if(nDim == 3){
int new_ndim = 4;
int *new_pads = (int *)malloc(2 * sizeof(int));
int *new_strides = (int *)malloc(2 * sizeof(int));
int *new_dilations = (int *)malloc(2 * sizeof(int));
int *new_x_shape = (int *)malloc(new_ndim * sizeof(int));
int *new_w_shape = (int *)malloc(new_ndim * sizeof(int));
int *new_y_shape = (int *)malloc(new_ndim * sizeof(int));
for(int i = 0; i < 2; i++){
new_pads[i] = (i < 1 ? pads[i] : 0);
new_strides[i] = (i < 1 ? strides[i] : 1);
new_dilations[i] = (i < 1 ? dilations[i] : 1);
}
for(int i = 0; i < new_ndim; i++){
new_x_shape[i] = (i < nDim ? x_shape[i] : 1);
new_w_shape[i] = (i < nDim ? w_shape[i] : 1);
new_y_shape[i] = (i < nDim ? y_shape[i] : 1);
}
convolutionCnnlDevice<T>(input, scale, output, new_pads, new_strides, new_dilations, new_x_shape, new_w_shape, new_y_shape, new_ndim, handle, queue);
free(new_pads);
free(new_strides);
free(new_dilations);
free(new_x_shape);
free(new_w_shape);
free(new_y_shape);
}
else{
convolutionCnnlDevice<T>(input, scale, output, pads, strides, dilations, x_shape, w_shape, y_shape, nDim, handle, queue);
}
cnnlDestroy(handle);
CNRT_CHECK(cnrtQueueDestroy(queue));
}
extern "C" void convolution_cnnl_f32(void const *input, void const *scale, void *output, int *pads, int *strides, int *dilations, int *x_shape, int *w_shape, int *y_shape, int nDim){
convolutionCnnl<float>(input, scale, output, pads, strides, dilations, x_shape, w_shape, y_shape, nDim);
}
extern "C" void convolution_cnnl_f16(void const *input, void const *scale, void *output, int *pads, int *strides, int *dilations, int *x_shape, int *w_shape, int *y_shape, int nDim){
convolutionCnnl<uint16_t>(input, scale, output, pads, strides, dilations, x_shape, w_shape, y_shape, nDim);
}
convolution.py
import torch
import ctypes
import torch.nn.functional as F
from functools import partial
import argparse
from typing import List, Tuple
import math
import performance
# 添加上一层目录到模块搜索路径
import sys
import os
lib_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '.././build/lib/libmy_library.so')
lib = ctypes.CDLL(lib_path)
def conv(x, w, stride, padding, dilation):
match len(x.shape) - 2:
case 1:
return F.conv1d(
x, w, stride=stride, padding=padding, dilation=dilation
)
case 2:
return F.conv2d(
x, w, stride=stride, padding=padding, dilation=dilation
)
case 3:
return F.conv3d(
x, w, stride=stride, padding=padding, dilation=dilation
)
case _:
print("Error: Pytorch -> Unsupported tensor dimension")
return None
def inferShape(
x_shape: List[int],
w_shape: List[int],
pads: List[int],
strides: List[int],
dilations: List[int],
) -> Tuple[int, ...]:
assert (
len(x_shape) == len(w_shape) == len(pads) + 2 == len(dilations) + 2 == len(strides) + 2
), "x and w should have the same length; pads, strides, and dilatinos should have the same length; the length of pads should be that of x - 2"
output_dims = [
math.floor(
(x_shape[i+2] + 2 * pads[i] - dilations[i] * (w_shape[i+2] - 1) - 1)
/ strides[i]
+ 1
)
for i in range(len(pads))
]
return (x_shape[0], w_shape[0]) + tuple(output_dims)
def test(x_shape, w_shape, pads, strides, dilations, test_dtype, device):
print(
f"Testing Batchnorm on {device} with x_shape:{x_shape}, w_shape:{w_shape}, pads: {pads}, strides: {strides}, dilations: {dilations}, dtype:{test_dtype}"
)
ndim = len(x_shape)
x = torch.rand(x_shape, dtype=test_dtype).to(device)
w = torch.rand(w_shape, dtype=test_dtype).to(device)
y_shape = inferShape(x.shape, w.shape, pads, strides, dilations)
y = torch.zeros(y_shape, dtype=test_dtype).to(device)
x_ptr = ctypes.cast(x.data_ptr(), ctypes.POINTER(ctypes.c_void_p))
w_ptr = ctypes.cast(w.data_ptr(), ctypes.POINTER(ctypes.c_void_p))
y_ptr = ctypes.cast(y.data_ptr(), ctypes.POINTER(ctypes.c_void_p))
import numpy as np
x_array = np.array(x_shape, dtype=np.int32)
xShape = x_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
w_array = np.array(w_shape, dtype=np.int32)
wShape = w_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
y_array = np.array(y_shape, dtype=np.int32)
yShape = y_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
p_array = np.array(pads, dtype=np.int32)
pData = p_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
s_array = np.array(strides, dtype=np.int32)
sData = s_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
d_array = np.array(dilations, dtype=np.int32)
dData = d_array.ctypes.data_as(ctypes.POINTER(ctypes.c_int))
if test_dtype == torch.float32:
if device == "mlu":
torch_convolution_time = performance.BangProfile((conv, (x, w, strides, pads, dilations)))
lib.convolution_cnnl_f32.argtypes = [
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_int),#pads
ctypes.POINTER(ctypes.c_int),#strides
ctypes.POINTER(ctypes.c_int),#dilations
ctypes.POINTER(ctypes.c_int),#x_shape
ctypes.POINTER(ctypes.c_int),#w_shape
ctypes.POINTER(ctypes.c_int),#y_shape
ctypes.c_int
]
custom_convolution_time = \
performance.BangProfile((lib.convolution_cnnl_f32, (x_ptr, w_ptr, y_ptr, pData, sData, dData, xShape, wShape, yShape, ndim)))
if test_dtype == torch.float16:
if device == "mlu":
torch_convolution_time = performance.BangProfile((conv, (x, w, strides, pads, dilations)))
lib.convolution_cnnl_f16.argtypes = [
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_void_p),
ctypes.POINTER(ctypes.c_int),#pads
ctypes.POINTER(ctypes.c_int),#strides
ctypes.POINTER(ctypes.c_int),#dilations
ctypes.POINTER(ctypes.c_int),#x_shape
ctypes.POINTER(ctypes.c_int),#w_shape
ctypes.POINTER(ctypes.c_int),#y_shape
ctypes.c_int
]
custom_convolution_time = \
performance.BangProfile((lib.convolution_cnnl_f16, (x_ptr, w_ptr, y_ptr, pData, sData, dData, xShape, wShape, yShape, ndim)))
performance.logBenchmark(torch_convolution_time, custom_convolution_time)
# 将结果转换回 PyTorch 张量以进行比较
tmpa = conv(x, w, strides, pads, dilations).to('cpu').detach().numpy().flatten()
tmpb = y.to('cpu').detach().numpy().flatten()
atol = max(abs(tmpa - tmpb))
rtol = atol / max(abs(tmpb) + 1e-8)
print("absolute error:%.4e"%(atol))
print("relative error:%.4e"%(rtol))
# 解析命令行参数
parser = argparse.ArgumentParser(description="Test convolution on different devices.")
parser.add_argument('--device', choices=['cpu', 'cuda', 'mlu'], required=True, help="Device to run the tests on.")
args = parser.parse_args()
test_cases = [
((32, 3, 4),
(32, 3, 5),
(1,),
(1,),
(1,),
torch.float32, 'mlu'),
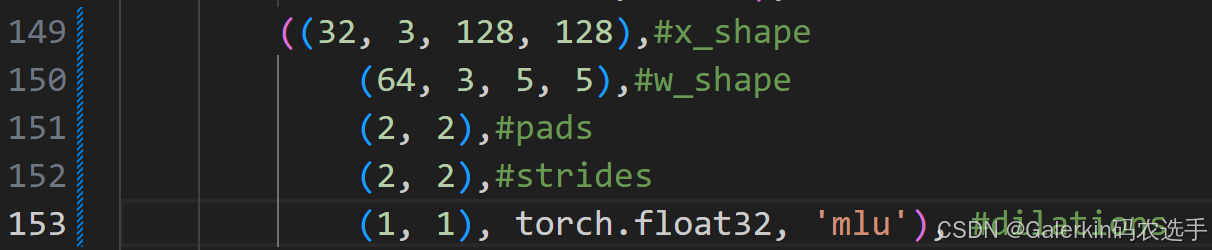
((32, 3, 128, 128),
(64, 3, 5, 5),
(2, 2),
(2, 2),
(1, 1), torch.float32, 'mlu'),
((1, 1, 4, 4, 4),
(1, 1, 5, 5, 5),
(1, 1, 1),
(1, 1, 1),
(1, 1, 1), torch.float32, 'mlu'),
((32, 3, 32, 32, 32),
(64, 3, 5, 5, 5),
(3, 2, 2),
(4, 3, 3),
(2, 2, 1), torch.float32, 'mlu'),
((32, 3, 4),
(32, 3, 5),
(1,),
(1,),
(1,),
torch.float16, 'mlu'),
((32, 3, 128, 128),
(64, 3, 5, 5),
(2, 2),
(2, 2),
(1, 1), torch.float16, 'mlu'),
((1, 1, 4, 4, 4),
(1, 1, 5, 5, 5),
(1, 1, 1),
(1, 1, 1),
(1, 1, 1), torch.float16, 'mlu'),
((32, 3, 32, 32, 32),
(64, 3, 5, 5, 5),
(3, 2, 2),
(4, 3, 3),
(2, 2, 1), torch.float16, 'mlu'),
]
filtered_test_cases = [
(x_shape, w_shape, pads, strides, dilations, test_dtype, device)
for x_shape, w_shape, pads, strides, dilations, test_dtype, device in test_cases
if device == args.device
]
if args.device == 'mlu':
import torch_mlu
# 执行过滤后的测试用例
for x_shape, w_shape, pads, strides, dilations, test_dtype, device in filtered_test_cases:
test(x_shape, w_shape, pads, strides, dilations, test_dtype, device)
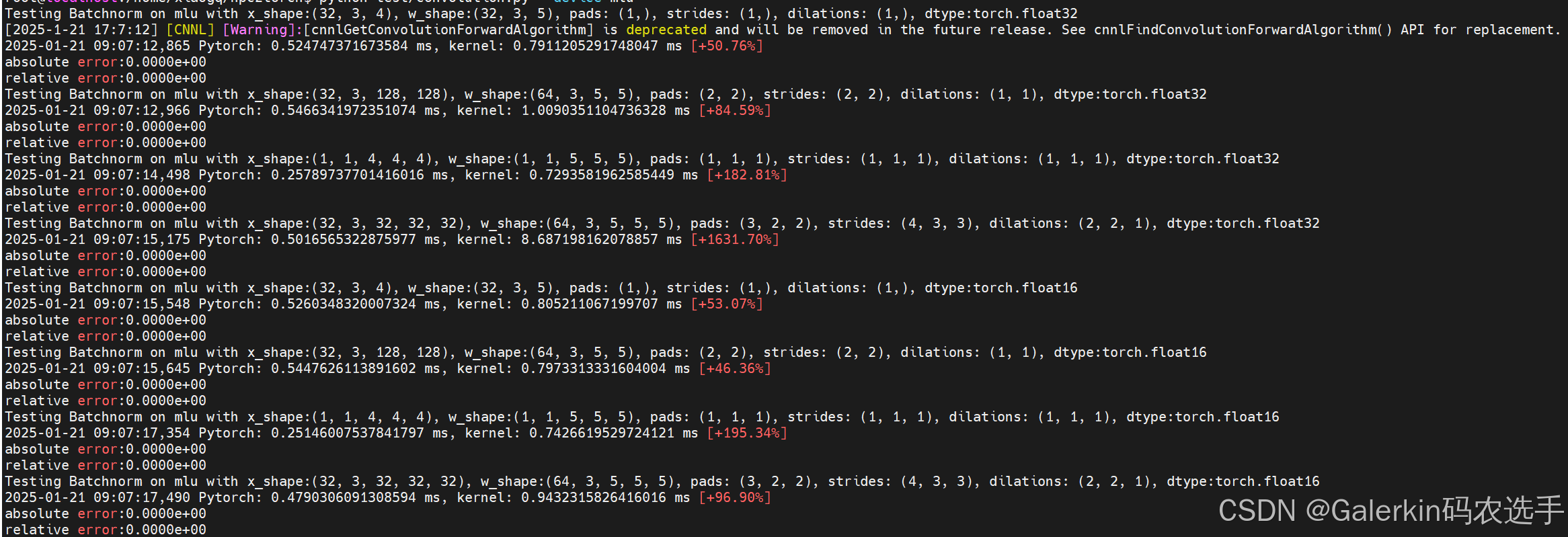
测试结果如下所示: