1. 模型架构
Contrastive Language-Image Pre-training(以下简称“CLIP”)是OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,可以说是近年来在多模态研究领域的经典之作。该模型直接使用大量的互联网数据进行预训练,在很多任务表现上达到了目前最佳表现(SOTA) 。
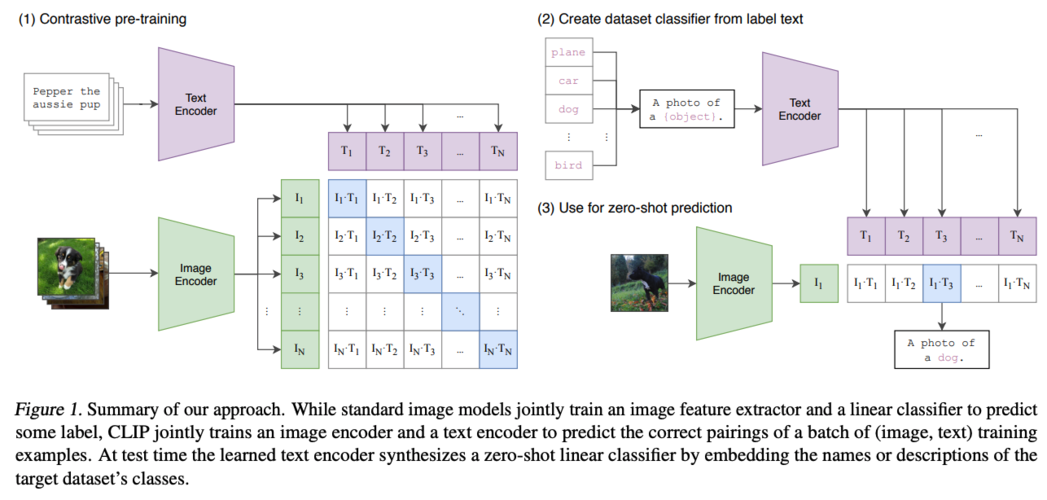
模型架构如上图所示,包括三个部分:
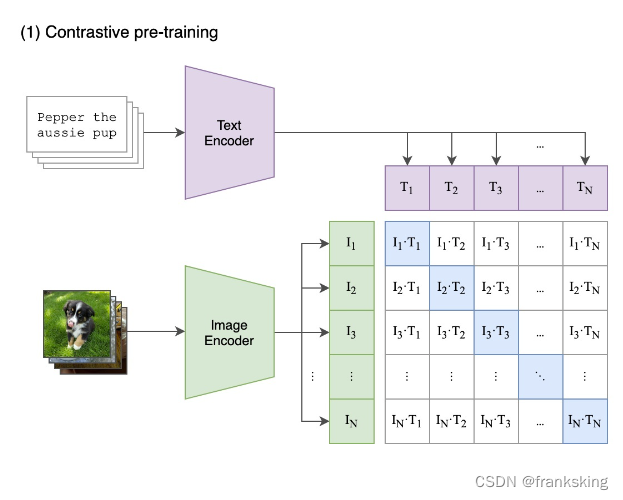
(1) 对比预训练(contrast pre-training):建立文本和图像的一一对应关系。文本和图像需要用Encoder转化为向量形式,文本通过TextEncoder转化为[T1,T2,T3.....,Tn],图像通过ImageEncoder转化为[I1,I2,I3.....,In]。文本向量和图像向量可以建立成N×N的矩阵关系,如下图所示,当处于对角线的向量乘积,因为i=j,余弦相似度是最大的(cos0为1);不在对角线上的向量成绩,因为i≠j,余弦相似度最小。
(2)提取预测类型的文本特征(create dataset from label text)
将待预测文本转换为向量,如下图所示:

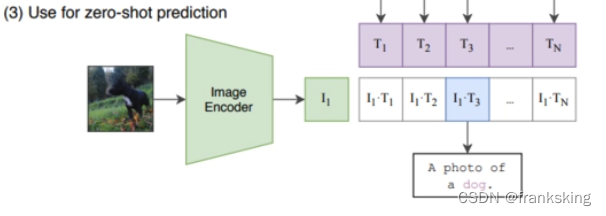
(3)zero-shot预测(use zero-shot prediction)
将待测图片进行编码,并与
2. 损失函数:交叉熵损失函数
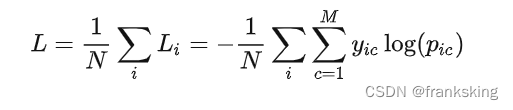
3. 训练方法
利用图文的特征 encoder 分别获取图像特征向量和文本特征向量,一个图像特征会对应一个文本特征,然后构成了一个 NxN 的一个相似度矩阵,其中对角线上的图文对是正样本,非对角部分 N^2 - N 是负样本。
训练过程中,通过对每行 image->text 做交叉熵 loss,每列 text->image 做交叉熵loss,目标就是优化这两个 loss 之和。
4. 推理方法
在推理阶段,首先将需要分类的图像经过ImageEncoder得到特征,然后对于目标任务数据集的每一个标签,或者你自己定义的标签,都构造一段对应的文本,例如,将 dog 改造成 “A photo of a dog”,以此类推。然后经过编码器得到文本和图像特征,接着将文本特征与图像特征做内积,内积最大对应的标签就是图像的分类结果。这就完成了目标任务上的 zero-shot 分类。
5. 优、缺点分析
CLIP在论文和它的官方网站上也说了CLIP的一些缺点,例如更细粒度的分类任务,数据集未覆盖到的任务上的表现。这些从本质上来看还是说明了CLIP还是一个有偏的模型。
目前看来仅仅通过它的4亿条数据以及对比学习预训练还不足以让模型学习到在NLP上那些通用的能力,这一方向也亟待提升。
优点不多说了,在当时比较新颖,有点aigc开篇的意思。