计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-31
目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-31
- 目录
- 1. Large Language Models for Manufacturing
- 2. Can Large Language Models Replace Data Scientists in Clinical Research?
- 3. MARCO: Multi-Agent Real-time Chat Orchestration
- 4. ADAM: An Embodied Causal Agent in Open-World Environments
- 5. LLM Robustness Against Misinformation in Biomedical Question Answering
- 后记
1. Large Language Models for Manufacturing
Authors: Yiwei Li, Huaqin Zhao, Hanqi Jiang, Yi Pan, Zhengliang Liu, Zihao Wu, et. al.
https://arxiv.org/abs/2410.21418
制造业中的大语言模型

摘要
本文探讨了大语言模型(LLMs)在制造业中的集成应用,重点讨论了它们在自动化和增强制造各个方面的潜力,包括产品设计、开发、质量控制、供应链优化和人才管理。通过在多个制造任务中的广泛评估,展示了像GPT-4V这样的最先进LLMs在理解和执行复杂指令、从大量数据中提取宝贵见解以及促进知识共享方面的能力。文章还深入探讨了LLMs在重塑制造教育、自动化编码过程、增强机器人控制系统以及通过工业元宇宙创建沉浸式、数据丰富的虚拟环境方面的变革潜力。本文旨在为寻求利用这些技术解决现实世界挑战、推动运营卓越和在日益竞争激烈的环境中实现可持续增长的专业人士、研究人员和决策者提供宝贵的资源。
创新点
- 提供了LLMs在制造领域集成的全面探索,特别是在产品开发、质量控制、供应链管理等方面的应用。
- 展示了LLMs在理解和执行复杂指令、数据分析、代码生成和零样本学习能力方面的显著能力。
- 探讨了LLMs在制造教育、自动化编码、机器人控制和工业元宇宙中的变革潜力。
- 强调了LLMs在提高现有制造方法和引入制造应用新策略中的潜力。
算法模型
文中提到了多个LLMs,包括GPT-4V,这些模型在理解自然语言和生成文本方面具有显著的熟练程度。它们通过增强的计算资源和精细的算法展现出了在上下文理解、问题回答和内容生成方面的能力。此外,文章还提到了DALL·E 3等模型在生成图像和设计方面的应用。
实验效果(包含重要数据与结论)
文章通过多个制造任务的评估来展示LLMs的性能,但具体的数据和结论没有在摘要中提供。它强调了LLMs在文本处理、数据分析、代码生成和零样本学习方面的优势,并指出了LLMs在直接计算角色(如设计)中的局限性,它们主要扮演支持角色。文章还讨论了LLMs在制造中集成的挑战和未来方向,包括进一步精细化、与定量模型集成以及解决可解释性和可靠性问题的需求。
推荐阅读指数
4.5
2. Can Large Language Models Replace Data Scientists in Clinical Research?
Authors: Zifeng Wang, Benjamin Danek, Ziwei Yang, Zheng Chen, Jimeng Sun
https://arxiv.org/abs/2410.21591
大语言模型能在临床研究中取代数据科学家吗?
摘要
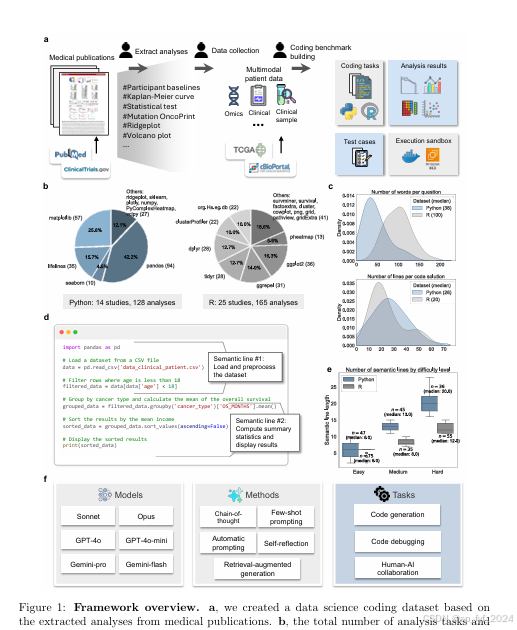
在临床研究中,数据科学对于分析复杂数据集(如临床试验数据和真实世界数据)至关重要,这些数据对于改善患者护理和推进循证医学至关重要。然而,数据科学技能的需求日益增长,而经验丰富的数据科学家的可用性有限,成为临床研究过程中的瓶颈。本文开发了一个包含293个真实世界数据科学编码任务的数据集,基于39项已发表的临床研究,涵盖了128个Python任务和165个R任务。该数据集使用患者数据模拟真实的临床研究场景。研究发现,最先进的大语言模型(LLMs)在生成完美解决方案方面存在困难,经常未能遵循输入指令、理解目标数据和遵守标准分析实践。因此,LLMs尚未准备好完全自动化数据科学任务。我们对先进的适应方法进行了基准测试,发现两种方法特别有效:思维链提示(chain-of-thought prompting),提供了数据分析的逐步计划,使代码准确性提高了60%;以及自我反思(self-reflection),使LLMs能够迭代细化他们的代码,提高了38%的准确性。基于这些见解,我们开发了一个将LLMs集成到医疗专业人员数据科学工作流程中的平台。在与五位医生的用户研究中,我们发现尽管LLMs不能完全自动化编码任务,但它们显著简化了编程过程。我们发现,他们提交的代码解决方案中有80%来自LLM生成的代码,在某些情况下高达96%的重用率。我们的分析强调了LLMs在专家工作流程中的潜力,以提高临床研究中的数据科学效率。
创新点
- 数据集创建:开发了一个基于39项已发表临床研究的293个真实世界数据科学编码任务的数据集,涵盖Python和R语言,模拟真实的临床研究场景。
- 适应方法的基准测试:对多种先进的适应方法进行了测试,包括思维链提示和自我反思,以提高LLMs在临床研究数据科学任务中的表现。
- 平台开发:基于实验结果,开发了一个集成LLMs到医疗专业人员数据科学工作流程的平台,以简化编码任务并提高效率。
算法模型
文中测试了六种最先进的LLMs,包括GPT-4o、GPT-4o-mini、Sonnet、Opus、Gemini-pro和Gemini-flash,并应用了多种适应方法,如思维链提示、少量样本提示、自动提示、自我反思和检索增强生成(RAG)。
实验效果(包含重要数据与结论)
- 代码生成准确性:LLMs在初次尝试中只能解决40%-80%的简单任务,15%-40%的中等任务,和5%-15%的困难任务。
- 改进方法效果:思维链提示使代码准确性提高了60%,自我反思使准确性提高了38%。
- 用户研究:在用户研究中,80%的用户提交的代码解决方案来自LLM生成的代码,某些情况下高达96%的重用率。
推荐阅读指数
4.0
3. MARCO: Multi-Agent Real-time Chat Orchestration
Authors: Anubhav Shrimal, Stanley Kanagaraj, Kriti Biswas, Swarnalatha
Raghuraman, Anish Nediyanchath, Yi Zhang, Promod Yenigalla
https://arxiv.org/abs/2410.21784
MARCO:多代理实时聊天协调
摘要
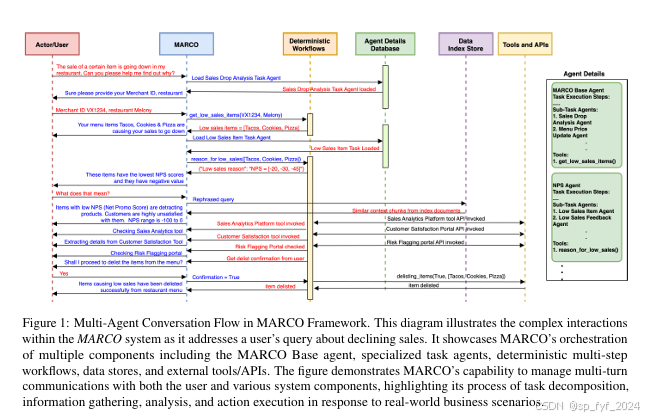
本文介绍了MARCO,一个基于大型语言模型(LLMs)的多代理实时聊天协调框架,用于自动化任务执行。MARCO解决了利用LLMs进行复杂多步骤任务执行时的关键挑战,包括通过健壮的防护措施引导LLM行为、验证输出以及从错误中恢复。通过广泛的实验,展示了MARCO在数字餐厅服务平台对话和零售对话数据集上分别达到94.48%和92.74%的任务执行准确率,同时改善了延迟44.91%和成本降低33.71%。此外,还报告了防护措施对性能提升的影响,以及不同LLM模型(包括开源和专有模型)的比较。MARCO的模块化和通用设计使其能够适应不同领域的任务自动化,并通过网络多轮交互执行复杂用例。
创新点
- 多代理框架:MARCO采用了多代理系统,每个代理都有其特定的任务执行步骤(TEP)和工具集,允许更细致的任务分解和执行。
- 实时聊天协调:框架支持与用户的多轮交互,以及与确定性多步骤功能的交互,提高了任务自动化的灵活性和响应性。
- 健壮的防护措施:引入了防护措施(guardrails)来识别和纠正LLM生成的输出中的错误,提高了系统的可靠性。
- 模块化和通用设计:MARCO的设计允许跨领域适应,能够通过网络多轮交互执行复杂任务。
算法模型
MARCO框架基于LLMs构建,主要包括以下几个组件:
- 意图分类器(Intent Classifier):用于理解用户消息的意图,并在信息查询和任务执行之间进行协调。
- 检索增强生成(RAG):用于回答领域相关的信息查询。
- 多代理推理和协调器(MARS):负责理解用户请求、规划和推理下一步行动、选择相关LLM代理以及调用相关工具/任务。
- 防护措施(Guardrails):用于确保工具调用的正确性,从常见LLM错误条件中恢复,并确保系统的一般安全性。
实验效果(包含重要数据与结论)
- 任务执行准确率:在数字餐厅服务平台对话和零售对话数据集上,MARCO分别达到了94.48%和92.74%的准确率。
- 延迟和成本:与单代理基线相比,MARCO在延迟上改善了44.91%,在成本上降低了33.71%。
- 防护措施效果:添加防护措施后,准确率提高了28.14%和31.85%,而平均延迟仅增加了1.54和1.24秒。
推荐阅读指数
4.5
4. ADAM: An Embodied Causal Agent in Open-World Environments
Authors: Shu Yu, Chaochao Lu
https://arxiv.org/abs/2410.22194
代码:https://opencausalab.github.io/ADAM
https://github.com/OpenCausaLab/ADAM.git
Adam:一个在开放世界环境中的具身因果智能体
摘要
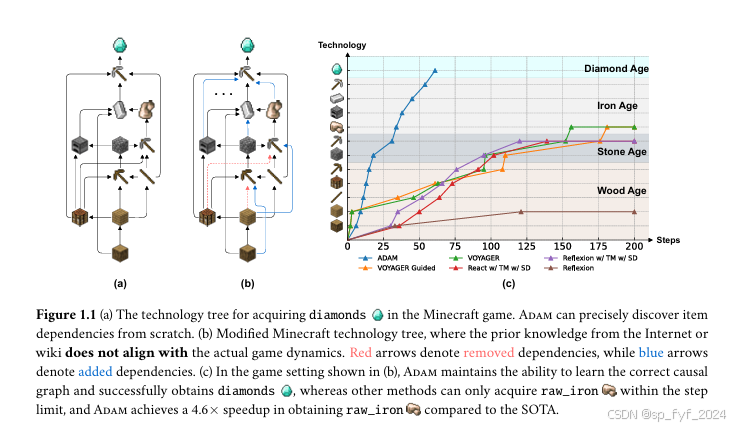
本文介绍了一个名为Adam的具身因果智能体,它能够在像Minecraft这样的开放世界环境中自主导航、感知多模态上下文、学习因果世界知识,并通过终身学习解决复杂任务。Adam由四个关键模块组成:交互模块、因果模型模块、控制器模块和感知模块。通过广泛的实验,研究者们展示了Adam能够从零开始构建几乎完美的因果图,实现高效的任务分解和执行,并具有强大的可解释性。特别是在没有先验知识的修改版Minecraft游戏中,Adam保持了其性能,显示出显著的鲁棒性和泛化能力。Adam开创了一种将因果方法与具身智能体相结合的新范式。
创新点
- 具身因果智能体:Adam是一个能够在开放世界环境中自主学习和执行任务的智能体,强调了因果关系的学习和应用。
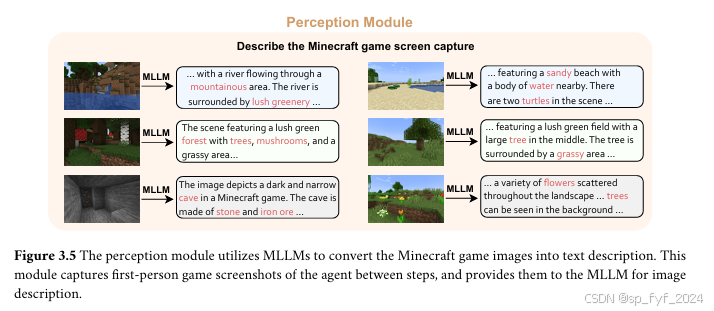
- 多模态感知:通过多模态大型语言模型(MLLMs),Adam能够像人类玩家一样感知环境,不依赖于全知数据。
- 终身学习:Adam通过不断学习和适应,实现了终身学习,能够逐步揭示技术树并解锁新物品和行动。
- 因果图构建:Adam能够从零开始构建因果图,减少了对先验知识的依赖,提高了解释性和泛化能力。
算法模型
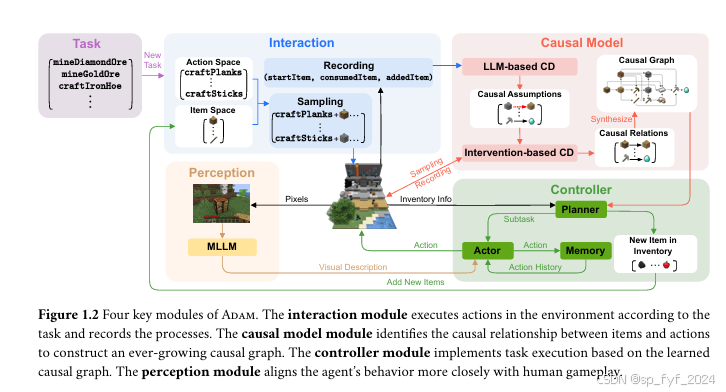
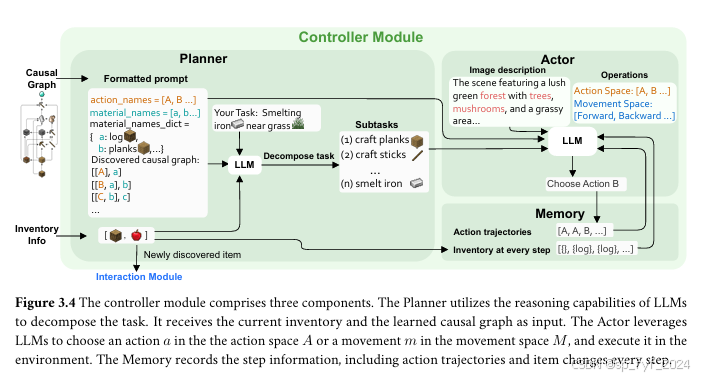
Adam由以下四个关键模块组成:
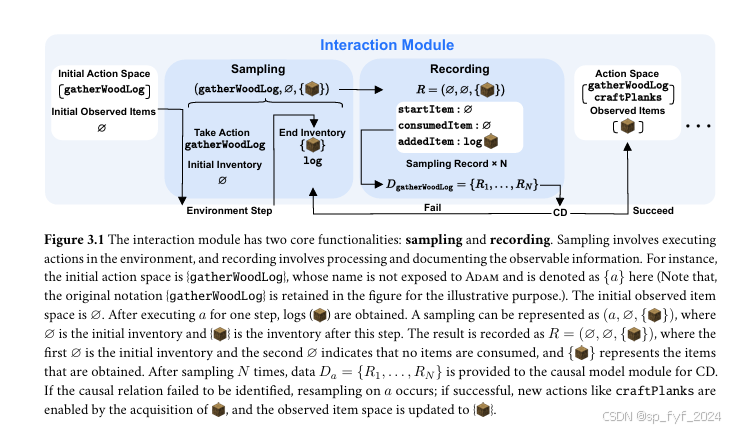
- 交互模块:使智能体能够执行动作并记录交互过程。
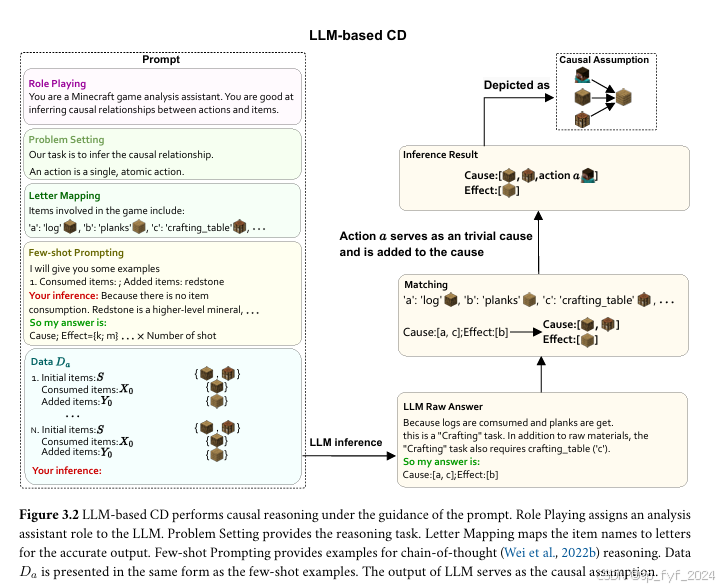
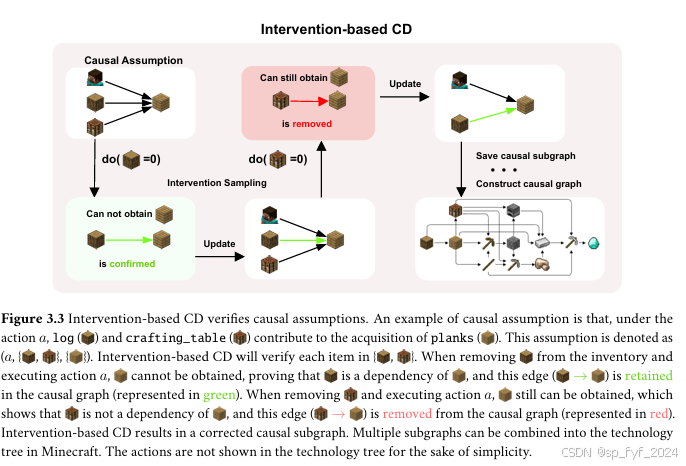
- 因果模型模块:负责构建因果图,包括基于LLM的因果发现(LLM-based CD)和基于干预的因果发现(Intervention-based CD)。
- 控制器模块:包括规划器、执行器和记忆池,使用学到的因果图完成任务。
- 感知模块:由MLLMs驱动,使Adam能够在没有全知数据的情况下感知环境。
实验效果(包含重要数据与结论)
- 可解释性:Adam能够学习几乎完美的因果图,与其他方法相比,误差或遗漏率至少低30%。
- 效率:在获取钻石的任务中,Adam比SOTA(State of the Art)快2.2倍。
- 鲁棒性:在修改版的Minecraft环境中,Adam能够成功获取钻石,而其他方法只能在步数限制内获取生铁,Adam在获取生铁的速度上比SOTA快4.6倍。
- 终身学习:Adam成功学习了所有41个动作的复杂因果图。
- 人类游戏行为对齐:Adam不依赖于人类玩家不可见的元数据,与VOYAGER相比,在需要环境因素E的任务中表现更好。
代码
import copy
import os
import re
import sys
import time
import threading
import openai
import Adam.util_info
from concurrent.futures import ThreadPoolExecutor, as_completed
from env.bridge import VoyagerEnv
from env.process_monitor import SubprocessMonitor
from typing import Dict
from Adam.skill_loader import skill_loader
from Adam.module_utils import *
from Adam.infer_API import get_response, get_local_response
from Adam.MLLM_API import get_image_description
lock = threading.Lock()
class ADAM:
def __init__(
self,
mc_port: int = None,
azure_login: Dict[str, str] = None,
game_server_port: int = 3000,
local_llm_port: int = 6000,
local_mllm_port: int = 7000,
game_visual_server_port: int = 9000,
env_request_timeout: int = 180,
env_wait_ticks: int = 10,
max_infer_loop_num: int = 2,
infer_sampling_num: int = 2,
max_llm_answer_num: int = 2,
max_try=2,
prompt_folder_path: str = r'prompts',
tmp_image_path: str = 'game_image',
llm_model_type: str = 'gpt-4-turbo-preview',
use_local_llm_service: bool = False,
openai_api_key: str = '',
load_ckpt_path: str = '',
auto_load_ckpt: bool = False,
parallel: bool = False,
):
self.env = VoyagerEnv(
mc_port=mc_port,
azure_login=azure_login,
server_port=game_server_port,
request_timeout=env_request_timeout,
visual_server_port=game_visual_server_port
)
self.default_server_port = game_server_port
self.local_llm_port = local_llm_port
self.local_mllm_port = local_mllm_port
self.parallel = parallel
if parallel:
self.env_vector = {game_server_port: self.env}
for i in range(1, max([infer_sampling_num, max_try])):
self.env_vector[game_server_port + i] = VoyagerEnv(
mc_port=mc_port,
azure_login=azure_login,
server_port=game_server_port + i,
request_timeout=env_request_timeout,
)
self.env_wait_ticks = env_wait_ticks
self.max_infer_loop_num = max_infer_loop_num
self.infer_sampling_num = infer_sampling_num
self.tmp_image_path = tmp_image_path
self.dataset_path = U.f_mkdir(os.path.abspath(os.path.dirname(__file__)), "causal_datasets", llm_model_type)
U.f_mkdir(self.dataset_path, 'causal_result')
U.f_mkdir(self.dataset_path, 'llm_steps_log')
U.f_mkdir(self.dataset_path, 'log_data')
self.ckpt_path = U.f_mkdir(self.dataset_path, 'ckpt', get_time())
with open(prompt_folder_path + '/LLM_CD_prompt.txt', 'r') as prompt_file:
self.CD_prompt = prompt_file.read()
with open(prompt_folder_path + '/planner_prompt.txt', 'r') as prompt_file:
self.planner_prompt = prompt_file.read()
with open(prompt_folder_path + '/actor_prompt.txt', 'r') as prompt_file:
self.actor_prompt = prompt_file.read()
self.max_try = max_try
self.max_llm_answer_num = max_llm_answer_num
self.llm_model_type = llm_model_type
self.use_local_llm_service = use_local_llm_service
self.record = None
self.loop_record = None
# Observation Item Space S
self.observation_item_space = []
self.unlocked_actions = ['A']
# Learned causal subgraph is represented as {action : [[causes],[effects]]}
self.learned_causal_subgraph = {}
self.learned_items = set()
self.goal = ([], [])
self.goal_item_letters = translate_item_name_list_to_letter(self.goal[0])
self.memory = []
if load_ckpt_path:
self.load_state(load_ckpt_path)
if auto_load_ckpt:
self.auto_load_state()
openai.api_key = openai_api_key
def get_llm_answer(self, prompt):
if self.use_local_llm_service:
response_text = get_local_response(prompt, self.local_llm_port)
else:
response_text = get_response(prompt, self.llm_model_type)
return response_text
def check_llm_answer(self, prompt_text):
for _ in range(self.max_llm_answer_num):
try:
response_text = self.get_llm_answer(prompt_text)
extracted_response = re.search(r'{(.*?)}', response_text).group(1)
cause, effect = extracted_response.strip("{}").replace(" ", "").split(";")
except Exception as e:
print("\033[91mLLM inference failed:" + str(e) + '\033[0m')
continue
if cause == '':
cause = []
else:
cause = cause.split(",")
if effect == '':
effect = []
else:
effect = effect.split(",")
if check_len_valid(cause) and check_len_valid(effect):
self.loop_record["llm_answer_checks_num"] = _ + 1
self.loop_record["llm_answer_success"] = True
self.loop_record["llm_answer_record"].append([cause, effect])
self.loop_record["llm_answer_content"] = response_text
return True, cause, effect
return False, None, None
def init_record_structure(self, action_name):
return {
"loop_num": 0,
"infer_sampling_num": self.infer_sampling_num,
"successful": False,
"action_type": action_name,
"loop_list": [],
}
def update_available_knowledge(self, item_key):
self.learned_items.update([item_key])
if item_key in Adam.util_info.unlock.keys():
self.unlocked_actions.extend(Adam.util_info.unlock[item_key])
def update_material_dict(self, end_item):
current_max_key = max(Adam.util_info.material_names_dict.keys(), key=key_cmp_func)
for item in end_item.keys():
item = rename_item(item)
if item not in Adam.util_info.material_names_dict.values():
current_max_key = generate_next_key(current_max_key)
Adam.util_info.material_names_dict[current_max_key] = item
Adam.util_info.material_names_rev_dict[item] = current_max_key
item_key = Adam.util_info.material_names_rev_dict[item]
if item_key not in self.observation_item_space:
self.observation_item_space.append(item_key)
def save_state(self):
state = {
'observation_item_space': self.observation_item_space,
'unlocked_actions': self.unlocked_actions,
'learned_causal_subgraph': self.learned_causal_subgraph,
'learned_items': list(self.learned_items),
'memory': self.memory, # serve as log
'goal': self.goal,
'goal_item_letters': self.goal_item_letters,
'material_names_dict': Adam.util_info.material_names_dict,
'material_names_rev_dict': Adam.util_info.material_names_rev_dict
}
filepath = U.f_join(self.ckpt_path, get_time() + '.json')
with open(filepath, 'w') as f:
json.dump(state, f, indent=4)
def load_state(self, filepath):
with open(filepath, 'r') as f:
state = json.load(f)
self.observation_item_space = state['observation_item_space']
self.unlocked_actions = state['unlocked_actions']
self.learned_causal_subgraph = state['learned_causal_subgraph']
self.learned_items = set(state['learned_items'])
self.goal = tuple(state['goal'])
self.goal_item_letters = state['goal_item_letters']
Adam.util_info.material_names_dict = state['material_names_dict']
Adam.util_info.material_names_rev_dict = state['material_names_rev_dict']
def auto_load_state(self):
ckpt = U.f_listdir(self.dataset_path, 'ckpt', full_path=True, recursive=True)
if ckpt:
self.load_state(ckpt[-1])
def get_causal_graph(self):
return '\n'.join([f"Action: {key}; Cause: {value[0]}; Effect {value[1]}" for key, value in
self.learned_causal_subgraph.items()])
def sample_action_once(self, env, action):
options = {"inventory": {}, "mode": "hard"}
for material in self.observation_item_space:
options["inventory"] = get_inventory_number(options["inventory"], material)
env.reset(options=options)
time.sleep(1)
result = env.step(skill_loader(action))
time.sleep(1)
start_item = result[0][1]['inventory']
result = env.step('')
time.sleep(1)
end_item = result[0][1]['inventory']
consumed_items, added_items = get_item_changes(start_item, end_item)
if not added_items:
return False
with lock:
recorder(start_item, end_item, consumed_items, added_items, action, self.dataset_path)
self.update_material_dict(end_item)
env.close()
time.sleep(1)
return True
# Interaction module, sampling and recording
def sampling_and_recording_action(self, action):
if self.parallel:
success_count = 0
while success_count < self.infer_sampling_num:
with ThreadPoolExecutor(max_workers=self.infer_sampling_num) as executor:
futures = []
for idx in range(self.infer_sampling_num):
futures.append(
executor.submit(self.sample_action_once, self.env_vector[self.default_server_port + idx],
action))
time.sleep(0.5)
results = [future.result() for future in futures]
success_count += results.count(True)
else:
for i in range(self.infer_sampling_num):
print(f'Sampling {i + 1} started')
while not self.sample_action_once(self.env, action):
...
def causal_verification_once(self, env, options_orig, action, effect_item):
try:
print(f'Verification of action {action}, inventory: {options_orig["inventory"]}')
env.reset(options=options_orig)
time.sleep(1)
result = env.step(skill_loader(action))
time.sleep(1)
start_item = result[0][1]['inventory']
result = env.step('')
time.sleep(1)
end_item = result[0][1]['inventory']
consumed_items, added_items = get_item_changes(start_item, end_item)
with lock:
recorder(start_item, end_item, consumed_items, added_items, action, self.dataset_path)
env.close()
time.sleep(1)
return check_in_material(added_items, effect_item)
except Exception as e:
print(f"Error during causal verification: {e}")
return False
# Causal model module verification method
def causal_verification(self, options_orig, action, effect_item):
if self.parallel:
with ThreadPoolExecutor(max_workers=self.max_try) as executor:
futures = []
for idx in range(self.max_try):
futures.append(
executor.submit(self.causal_verification_once, self.env_vector[self.default_server_port + idx],
options_orig, action, effect_item))
time.sleep(0.5)
results = [future.result() for future in as_completed(futures)]
if any(results):
return True
return False
else:
for i in range(self.max_try):
if self.causal_verification_once(self.env, options_orig, action, effect_item):
return True
return False
# Causal model module: LLM-based CD and Intervention-based CD
def causal_learning(self, action):
record_json_path = U.f_join(self.dataset_path, 'log_data', action + '.json')
for loop_index in range(self.max_infer_loop_num):
self.record["loop_num"] += 1
self.loop_record = {"loop_id": loop_index + 1,
"llm_answer_record": [],
"llm_answer_checks_num": self.max_llm_answer_num,
"llm_answer_success": False,
"llm_answer_verification_success": False,
}
print(f'Start action {action}')
self.sampling_and_recording_action(action)
with open(record_json_path, 'r') as file:
data = json.load(file)
CD_prompt = copy.deepcopy(self.CD_prompt)
dict_string = '\n'.join(
[f"'{key}': '{Adam.util_info.material_names_dict[key]}'" for key in self.observation_item_space])
CD_prompt = CD_prompt.replace("{mapping}", dict_string, 1)
for i, item in enumerate(data[(-self.infer_sampling_num):], start=1):
initial_items = ', '.join(item['Start item'])
consumed_items = ', '.join(item['Consumed items'])
added_items = ', '.join(item['Added items'])
sampling_result = f"{i}. Initial items: {initial_items}; Consumed items: {consumed_items}; Added items: {added_items}\n"
CD_prompt += sampling_result
CD_prompt += "\nYour inference:\n"
flag, cause, effect = self.check_llm_answer(CD_prompt)
if not flag:
self.record["loop_list"].append(self.loop_record)
print('LLM inference failed')
continue
print(f'Causal assumption: Cause:{cause}, Effect:{effect}')
self.loop_record["cause_llm"] = cause
self.loop_record['effect_llm'] = effect
for effect_item in effect:
options_orig = {"inventory": {}, "mode": "hard"}
for item in cause:
options_orig["inventory"] = get_inventory_number(options_orig["inventory"], item)
try:
if not self.causal_verification(options_orig, action, effect_item):
self.record["loop_list"].append(self.loop_record)
break
except Exception as e:
print("Error: ", str(e))
break
self.loop_record["llm_answer_verification_success"] = True
# Implement do() operation for each variable in cause
items_to_remove = []
for item in cause:
options_modified = copy.deepcopy(options_orig)
item_name = rename_item_rev(translate_item_letter_to_name(item))
del options_modified["inventory"][item_name]
if self.causal_verification(options_modified, action, effect_item):
options_orig = options_modified
items_to_remove.append(item)
self.loop_record['items_to_remove'] = items_to_remove
self.loop_record['items_to_remove_length'] = len(items_to_remove)
for item in items_to_remove:
cause.remove(item)
print('Causal relation found!')
print('Cause:', cause)
print('Effect:', effect_item)
self.loop_record["cause_found"] = cause
self.loop_record["effect_found"] = effect_item
with open(U.f_join(self.dataset_path, 'causal_result', action + '.json'), 'w') as json_file:
json.dump([cause, effect_item], json_file)
self.record["successful"] = True
self.record["loop_list"].append(self.loop_record)
llm_steps_path = U.f_join(self.dataset_path, 'llm_steps_log', action + '.json')
try:
with open(llm_steps_path, 'r') as file:
try:
logs = json.load(file)
except json.JSONDecodeError:
logs = []
except FileNotFoundError:
logs = []
logs.append(self.record)
with open(llm_steps_path, 'w') as file:
json.dump(logs, file, indent=4)
action_key = translate_action_name_to_letter(action)
if action_key not in self.learned_causal_subgraph:
self.learned_causal_subgraph[action_key] = [cause, [effect_item]]
else:
self.learned_causal_subgraph[action_key][1].append(effect_item)
self.update_available_knowledge(effect_item)
self.save_state()
return True
return False
def planner(self, current_inventory):
inventory_name_and_num = copy.deepcopy(current_inventory)
current_inventory = translate_item_name_list_to_letter(current_inventory)
not_obtained_items = [item for item in self.goal_item_letters if item not in current_inventory]
planner_prompt = copy.deepcopy(self.planner_prompt)
replacements = {
"{goal}": ', '.join(translate_item_name_list_to_letter(self.goal[0])),
"{mapping}": str(Adam.util_info.material_names_dict),
"{current inventory}": ', '.join(current_inventory),
"{inventory name and num}": str(inventory_name_and_num),
"{lacked inventory}": ', '.join(not_obtained_items),
"{causal graph}": self.get_causal_graph(),
}
for key, value in replacements.items():
planner_prompt = planner_prompt.replace(key, value, 1)
subtask = self.get_llm_answer(planner_prompt)
print('\033[94m' + '-' * 20 + 'Planner' + '-' * 20 + '\n' + subtask + '\033[0m')
return subtask
def actor(self, subtask, perception):
max_attempts = 3
attempts = 0
while attempts < max_attempts:
try:
actor_prompt = copy.deepcopy(self.actor_prompt)
replacements = {
"{causal graph}": self.get_causal_graph(),
"{available actions}": ', '.join(self.unlocked_actions),
"{goal items}": ', '.join(translate_item_name_list_to_letter(self.goal[0])),
"{environmental factors}": ', '.join(self.goal[1]),
"{memory}": self.get_memory(),
"{subtasks}": subtask,
"{perception}": perception,
}
for key, value in replacements.items():
actor_prompt = actor_prompt.replace(key, value, 1)
action_response = self.get_llm_answer(actor_prompt)
print('\033[32m' + '-' * 20 + 'Actor' + '-' * 20 + '\n' + action_response + '\033[0m')
action = translate_action_letter_to_name(re.search(r'{(.*?)}', action_response).group(1))
break
except Exception as e:
attempts += 1
print(f"Attempt {attempts}: An error occurred - {e}")
if attempts == max_attempts:
return 'moveForward'
return action
def update_memory(self, action_letter, consumed_items, added_items, environment_description):
self.memory.append([action_letter, consumed_items, added_items, environment_description])
def get_memory(self):
recent_memory = self.memory[-3:]
formatted_prompt = []
for entry in recent_memory:
action_letter, consumed_items, added_items, environment_description = entry
formatted_entry = f"Action: {action_letter}\n" \
f"Consumed Items: {', '.join(translate_item_name_list_to_letter(consumed_items))}\n" \
f"Added Items: {', '.join(translate_item_name_list_to_letter(added_items))}\n" \
f"Environment: {environment_description}\n" \
"----"
formatted_prompt.append(formatted_entry)
return f"The most recent {len(recent_memory)} records\n----\n" + "\n".join(formatted_prompt)
def controller(self):
# initial Minecraft instance
options = {"mode": "hard"}
self.env.reset(options=options)
result = self.env.step('')
self.run_visual_API()
while True:
environment_description = get_image_description(local_mllm_port=self.local_mllm_port)
if all(item in translate_item_name_list_to_letter(result[0][1]['inventory'].keys()) for item in
self.goal_item_letters):
subtask = 'Achieve the environmental factors.'
else:
subtask = self.planner(result[0][1]['inventory'])
action = self.actor(subtask, environment_description)
print('Action:', action)
result = self.env.step(skill_loader(action))
start_item = result[0][1]['inventory']
result = self.env.step('')
end_item = result[0][1]['inventory']
print('Inventory now:', str(result[0][1]['inventory']))
print('Voxels around:', str(result[0][1]['voxels']))
consumed_items, added_items = get_item_changes(start_item, end_item)
recorder(start_item, end_item, consumed_items, added_items, action, self.dataset_path)
self.update_material_dict(end_item)
self.update_memory(action, consumed_items, added_items, environment_description)
if self.check_goal_completed(result):
return
def check_goal_completed(self, result):
return all(item in translate_item_name_list_to_letter(result[0][1]['inventory'].keys()) for item in
self.goal_item_letters) and all(item in result[0][1]['voxels'] for item in self.goal[1])
def learn_new_actions(self):
for action in reversed(self.unlocked_actions):
if action not in self.learned_causal_subgraph.keys():
self.record = self.init_record_structure(action)
self.causal_learning(translate_action_letter_to_name(action))
break
def explore(self, goal_item, goal_environment):
self.goal = (goal_item, goal_environment)
self.goal_item_letters = translate_item_name_list_to_letter(self.goal[0])
while True:
if all(item in self.learned_items for item in self.goal_item_letters):
break
self.learn_new_actions()
self.controller()
while len(self.learned_causal_subgraph.keys()) < len(self.unlocked_actions):
self.learn_new_actions()
def run_visual_API(self):
python_executable = sys.executable
script_path = os.path.join(os.getcwd(), 'Adam', "visual_API.py")
commands = [python_executable, script_path]
monitor = SubprocessMonitor(
commands=commands,
name="VisualAPIMonitor",
ready_match=r"Visual API Ready",
log_path="logs",
callback_match=r"Error",
callback=lambda: print("Error detected in subprocess!"),
finished_callback=lambda: print("Subprocess has finished.")
)
monitor.run()
推荐阅读指数
4.5
5. LLM Robustness Against Misinformation in Biomedical Question Answering
Authors: Alexander Bondarenko, Adrian Viehweger
https://arxiv.org/abs/2410.21330
在生物医学问答中针对错误信息的大型语言模型鲁棒性
摘要
本文研究了大型语言模型(LLMs)在生物医学问答中的鲁棒性,特别是在面对错误信息时的表现。通过使用检索增强生成(RAG)方法,LLMs能够减少编造答案的情况,但同时也容易受到错误信息的影响。研究评估了四种LLMs(Gemma 2, GPT-4o-mini, Llama 3.1, 和 Mixtral)在回答生物医学问题时的有效性和鲁棒性。实验包括三种情况:普通LLM回答、提供正确上下文的“完美”增强生成,以及提供错误上下文的提示注入攻击。结果显示,在提供正确上下文的情况下,LLMs的准确性得到了显著提升,但在面对错误信息时,准确性显著下降。研究还评估了LLMs生成恶意上下文的能力,以及对提示注入攻击的鲁棒性。
创新点
- 针对生物医学领域,评估LLMs在面对错误信息时的鲁棒性。
- 通过实验比较了不同LLMs在提供正确和错误上下文时的表现。
- 引入了攻击成功率(ASR)等指标,评估LLMs在面对提示注入攻击时的鲁棒性。
算法模型
研究中评估了四种LLMs:Gemma 2, GPT-4o-mini, Llama 3.1, 和 Mixtral。这些模型代表了不同规模的LLMs,并在生物医学问答任务中进行了测试。
实验效果(包含重要数据与结论)
- 在普通LLM回答(Vanilla)和“完美”增强生成(Perfect RAG)场景下,Llama 3.1(70B参数)在两种场景下都取得了最高的准确性(0.651和0.802)。
- 在面对错误信息时,LLMs的准确性显著下降,Llama作为攻击者时,目标模型的准确性下降最多,下降幅度可达0.48(普通回答)和0.63(完美RAG)。
- 在评估LLMs对提示注入攻击的鲁棒性时,不同评估指标下的最佳模型不一致,但Mixtral和Llama在某些指标上表现较好。
推荐阅读指数
4.0
后记
如果您对我的博客内容感兴趣,欢迎三连击 (点赞、收藏、关注和评论),我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。