在2025年春节的科技盛宴上,DeepSeek因其在AI领域的卓越表现成为焦点,其开源的推理模型DeepSeek-R1擅长处理多种复杂任务,支持多语言处理,并通过搜索引擎获取实时信息。DeepSeek因其先进的自然语言处理技术、广泛的知识库和高性价比而广受欢迎。本文介绍了DeepSeek的功能、硬件和软件环境需求,并演示了如何在云服务器上快速部署DeepSeek,展示其在博客写作中的应用。未来,DeepSeek有望在AI智能体和AI应用方向取得更多突破。

DeepSeek崛起:如何在云端快速部署你的专属AI助手
1. DeepSeek及其应用场景
在2025年春节的科技盛宴上,尽管宇树科技的机器人以灵动的机械舞姿惊艳了春晚舞台,DeepSeek却凭借其引发的科技浪潮成为了众人瞩目的焦点。DeepSeek在AI领域中光芒四射,彻底吸引了西方资本市场的目光。如今,提起DeepSeek,可谓是家喻户晓,声名远扬。那么,DeepSeek究竟是什么?它具备哪些强大的功能?又是什么让它如此炙手可热?让我们一同回顾一下。
1.1 什么是DeepSeek?
- DeepSeek是一家专注通用人工智能(AGI)的中国科技公司,主攻大模型研发与应
用。 - DeepSeek-R1是其开源的推理模型,擅长处理复杂任务且开源,开源开放,支持免费商用。
1.2 DeepSeek能干什么?
- 支持处理多种复杂任务,包括文本理解、数据分析、知识问答及内容创作等。
- 具备跨语言处理能力,能够理解和生成多种语言的文本。
- 能够通过搜索引擎进行联网查询,获取实时信息并整合到回答中。
1.3 DeepSeek为什么这么火?
- 采用了先进的自然语言处理技术,能够更准确地理解用户意图,提供更贴合需求的服务。
- 知识库经过大规模数据训练,涵盖广泛的主题,能够提供多领域的专业信息。
- 不断通过机器学习和用户反馈进行自我优化,以提升交互质量和响应速度。
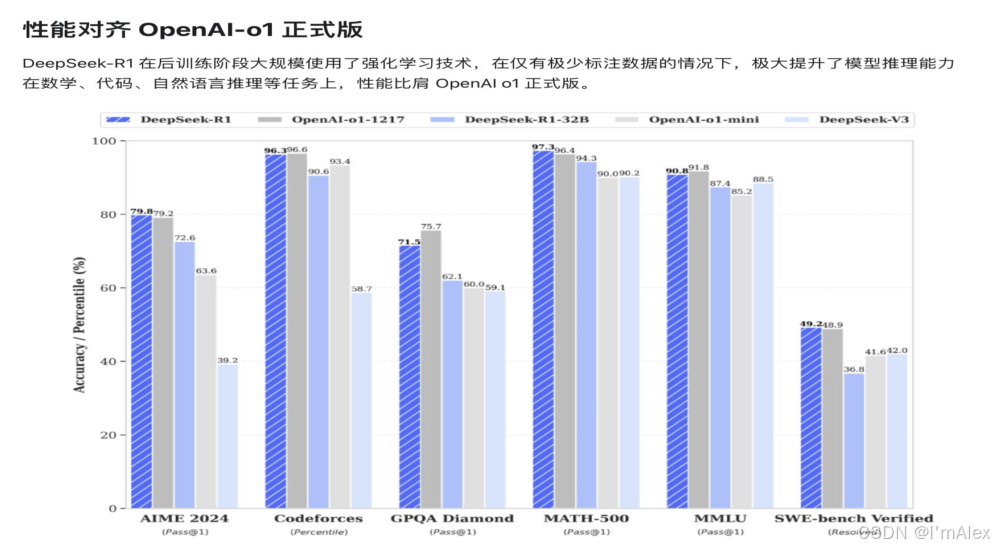
- DeepSeek-R1性能与OpenAI-o1相当但成本降低90%,并且被多个云服务商(如蓝耘、华为云、腾讯云)接入,具有超高性价比和广泛兼容性。
2. 为什么要部署私有DeepSeek
DeepSeek的爆火,导致官方访问,频繁出现服务器繁忙的提示。主要原因包括用户流量过大、技术性能瓶颈以及可能的一些外部恶意攻击。
虽然我们可以借助第三方平台(如硅基流动、纳米AI搜索、秘塔AI搜索等)实现平替,但是从数据安全、用户隐私、费用等角度考虑,我还是建议部署自己的私有DeepSeek,打造一个稳定性高、隐私性强、灵活性强的超强AI服务。
2.1 DeepSeek所需的硬件和软件环境
以下是部署DeepSeek不同规模模型所需的硬件和软件环境详细表格:
| 模型规模 | CPU建议 | GPU建议(显存) | 内存建议 | 存储空间 | 软件环境 | 适用场景 | 备注 |
|---|---|---|---|---|---|---|---|
| 1.5B | 4核以上 (i5/Ryzen5) | 可选:GTX 1650 (4GB+) 或 T4 (低功耗) | 8GB+ | 10GB+ SSD | Python 3.9+, CUDA 11.8+, PyTorch 2.1.0, Transformers 4.33.0 | 小型NLP任务、文本生成 | 低端GPU可运行,量化后显存需求更低 |
| 7B | 6核以上 (i7/Ryzen7) | RTX 3060 (12GB) / A100 (24GB+) | 16GB+ | 20GB+ SSD | 同1.5B,需加速库(如FlashAttention) | 中等NLP、对话系统 | 显存需求因量化差异大(16-32GB) |
| 14B | 8核以上 (i9/Ryzen9) | RTX 3090 (24GB) / A100 (40GB+) | 32GB+ | 50GB+ SSD | 需多GPU并行支持 | 复杂NLP、知识问答 | 单卡需高显存,多卡可降低单卡负载 |
| 32B | Xeon/EPYC (32核+) | 多卡A100/H100 (80GB+) | 128GB+ | 200GB+ NVMe | 分布式训练框架(如DeepSpeed) | 企业级复杂任务 | 需多卡并行或量化技术 |
| 67B | 服务器级CPU (64核+) | 4×A100-80G 或 H100集群 | 256GB+ | 300GB+ NVMe | CUDA 12+, 混合精度训练 | 科研级高复杂度生成 | 显存需求极高,需分布式推理 |
| 70B | 同67B | 同67B | 256GB+ | 300GB+ NVMe | 同67B | 超大规模AI研究 | 企业级部署需定制化优化 |
| 671B | 多节点服务器集群 | 8×A100-80G 或 H100 | 512GB+ | 1TB+ NVMe | 分布式框架(如Megatron-LM) | 超大规模训练/推理 | 仅适合专业机构 |
2.2 本地部署还是云服务部署
从表格中可以看出,当模型参数规模达到14B时,所需的硬件性能已经超出了普通个人电脑的能力范围。众所周知,大模型的参数规模越大,生成的内容通常越优质。因此,为了部署更聪明、更强大的AI大模型,我建议大家选择高性能云服务来进行部署。
3. 1分钟快速部署DeepSeek
接下来,给大家演示下如何在云服务器平台上部署DeepSeek。至于选择哪个云平台,大家可以根据自己的习惯自行选择。
本文中,我使用的蓝耘元生代智算云平台。为什么选择蓝耘呢,主要是下面几个点:
-
高性能与高性价比: 蓝耘GPU智算云平台基于Kubernetes,提供领先的基础设施和大规模GPU算力,速度比传统云服务快35倍,成本降低30%。
-
全流程支持: 平台支持AI客户在模型构建、训练和推理的全业务流程,并加速教科研客户的科研创新。
-
容器化与自动化管理: 通过将运行环境、模型和训练框架打包到容器中,并使用定制化Kubernetes工具进行管理,解决开发环境设置和运维管理问题。
-
开箱即用: 提供统一的环境模板,让算法工程师免除初期开发环境设置和新环境中管理算力资源的麻烦。应用市场已经内置了DeepSeek的1.5b、7b、8b、32b模型,支持快速部署。
-
自愈能力与高效利用: 针对大模型训练中的常见问题,平台提供自动化调度和自愈能力,提高开发和训练效率以及资源利用率。
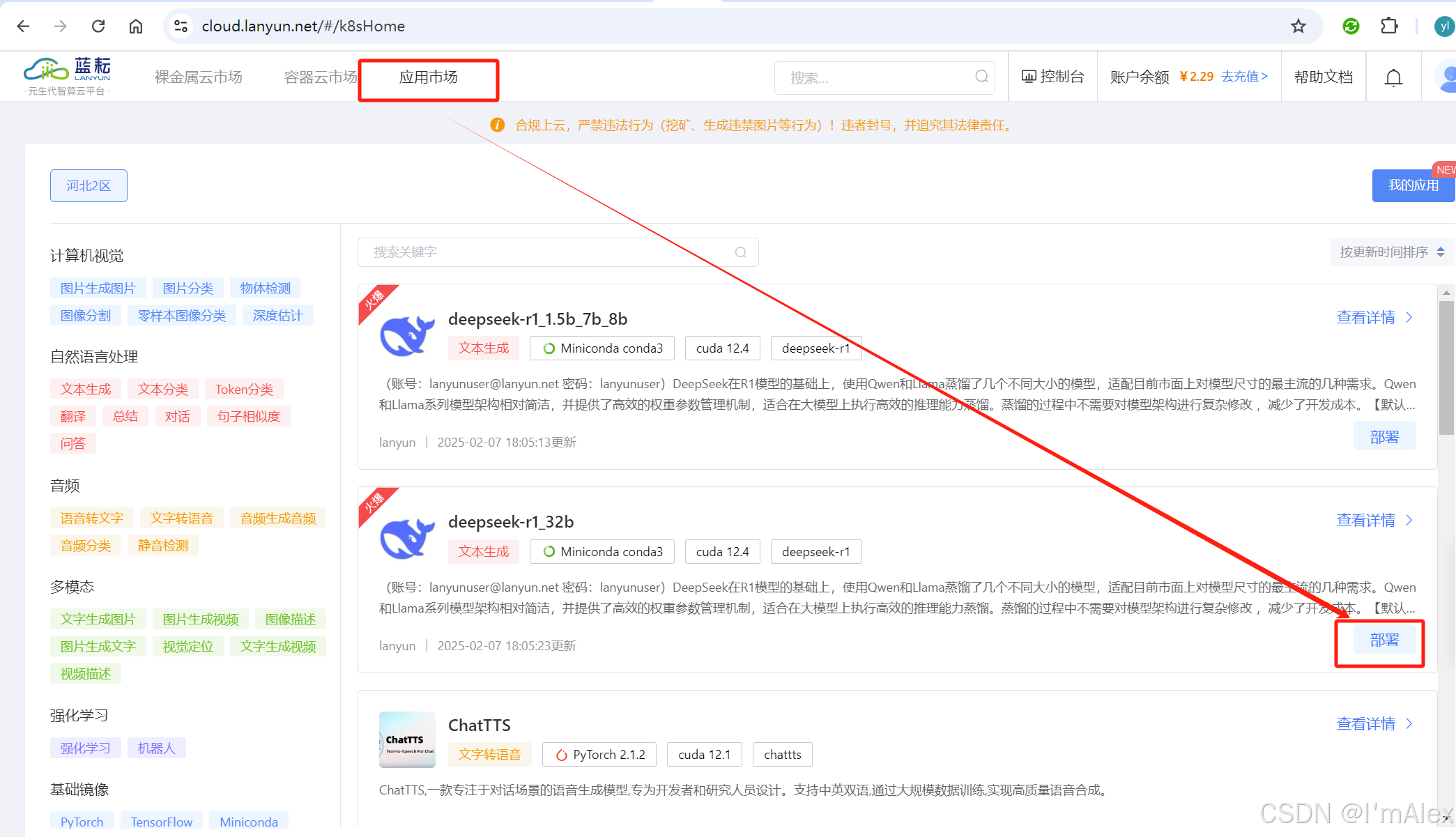
3.1 应用市场找到DeepSeek
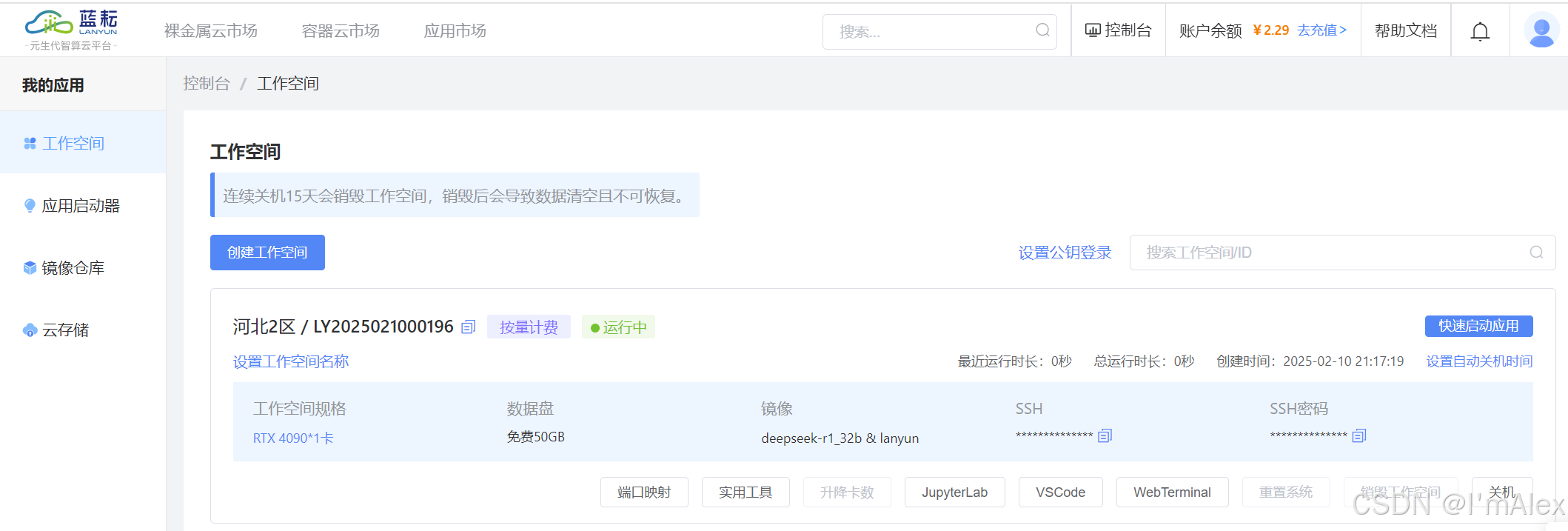
访问蓝耘官网完成账号注册,然后找到应用市场入口,就可以看到已经内置了DeepSeek模型并且置顶展示。为了更好的生成效果,我们选择第二个r1 32b版本。
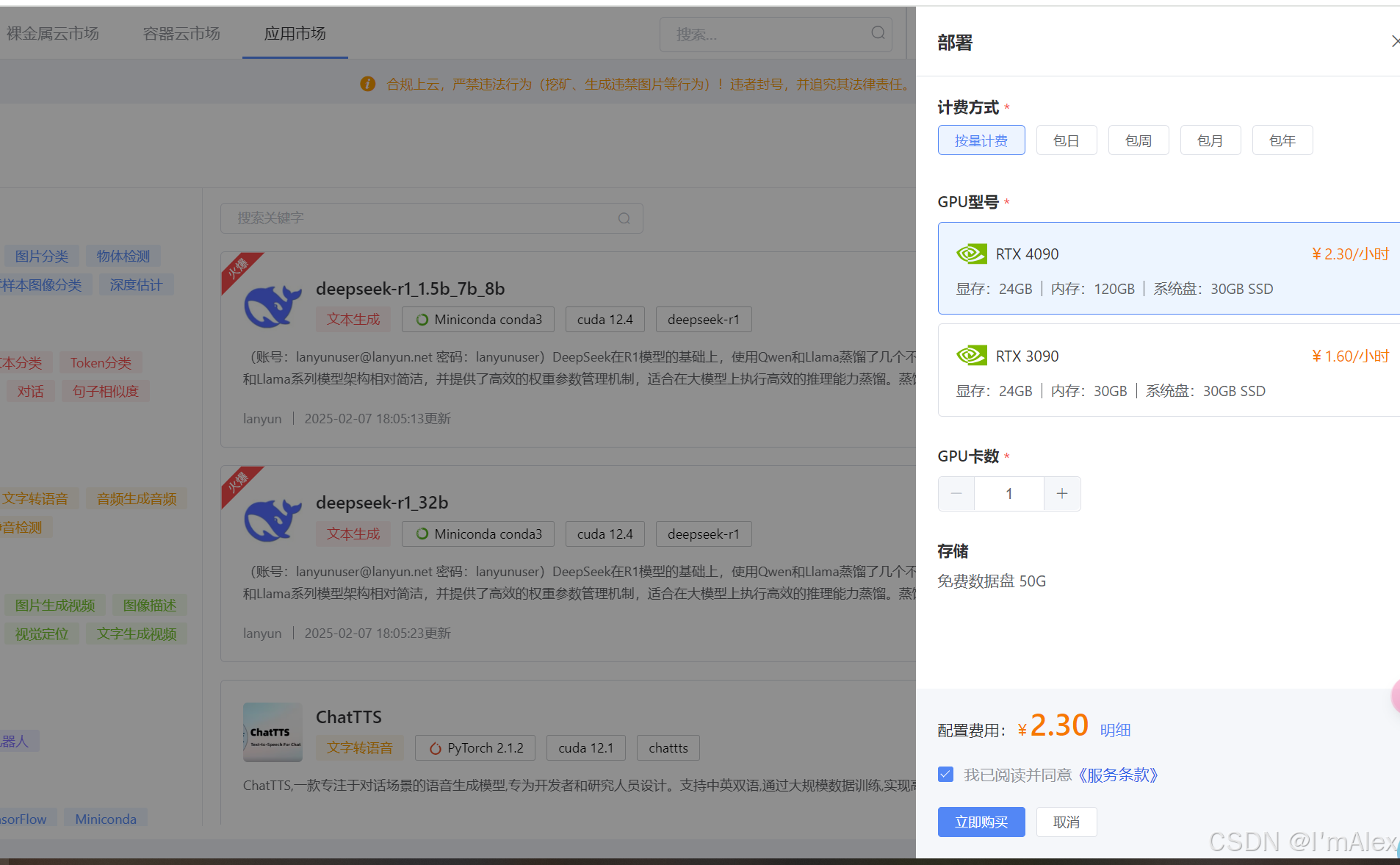
3.2 购买云服务器
点击模型右侧的部署按钮,购买云服务器。为了更快的执行速度,我选择的是4090显卡配置。
3.3 启动应用
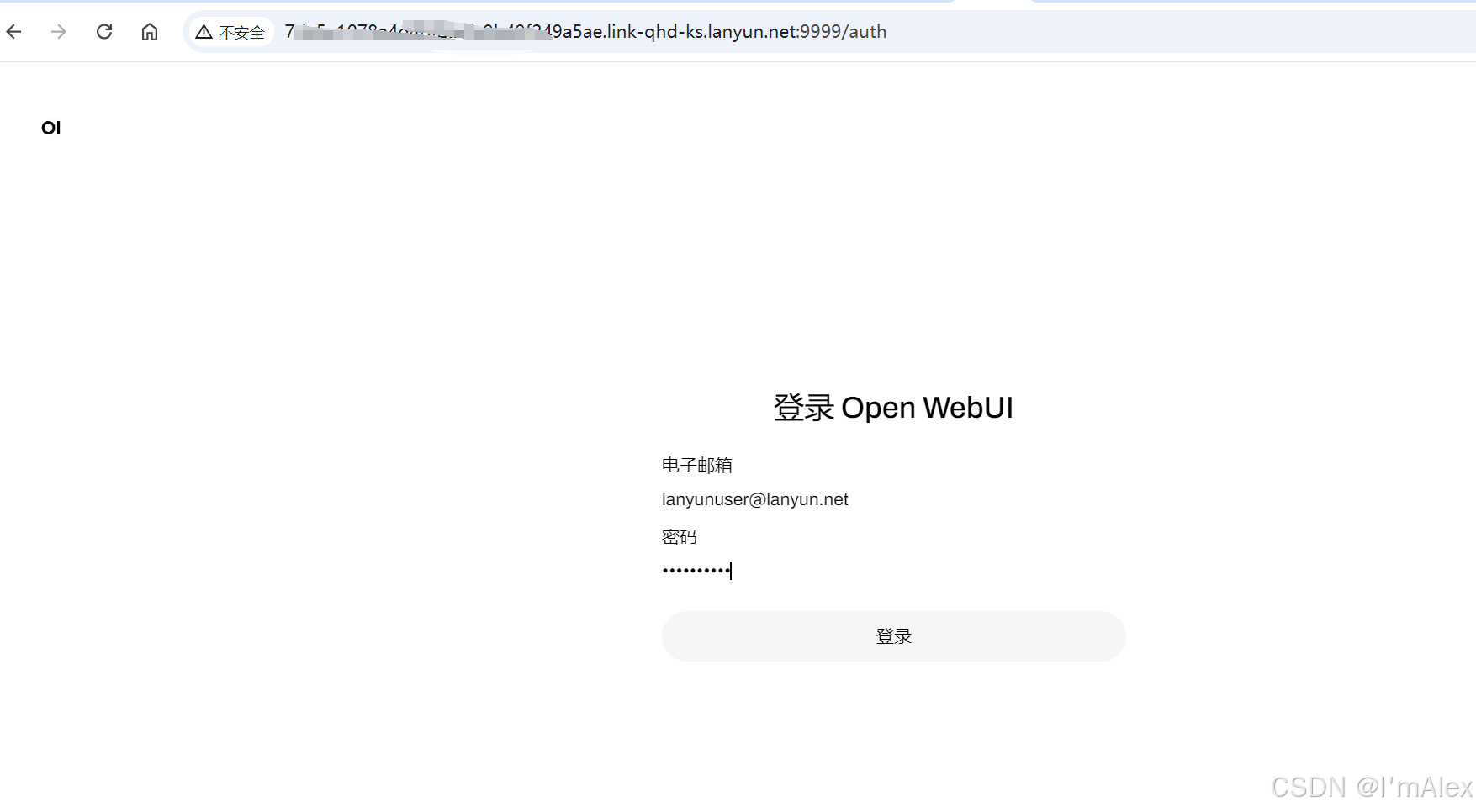
购买成功之后,会自动跳转到工作空间,并展示出新购买的云服务器,然后再次点击快速启动应用按钮就可以启动DeepSeek应用了。
在弹出的新页面中,使用默认账号:[email protected] 密码:lanyunuser即可登录。
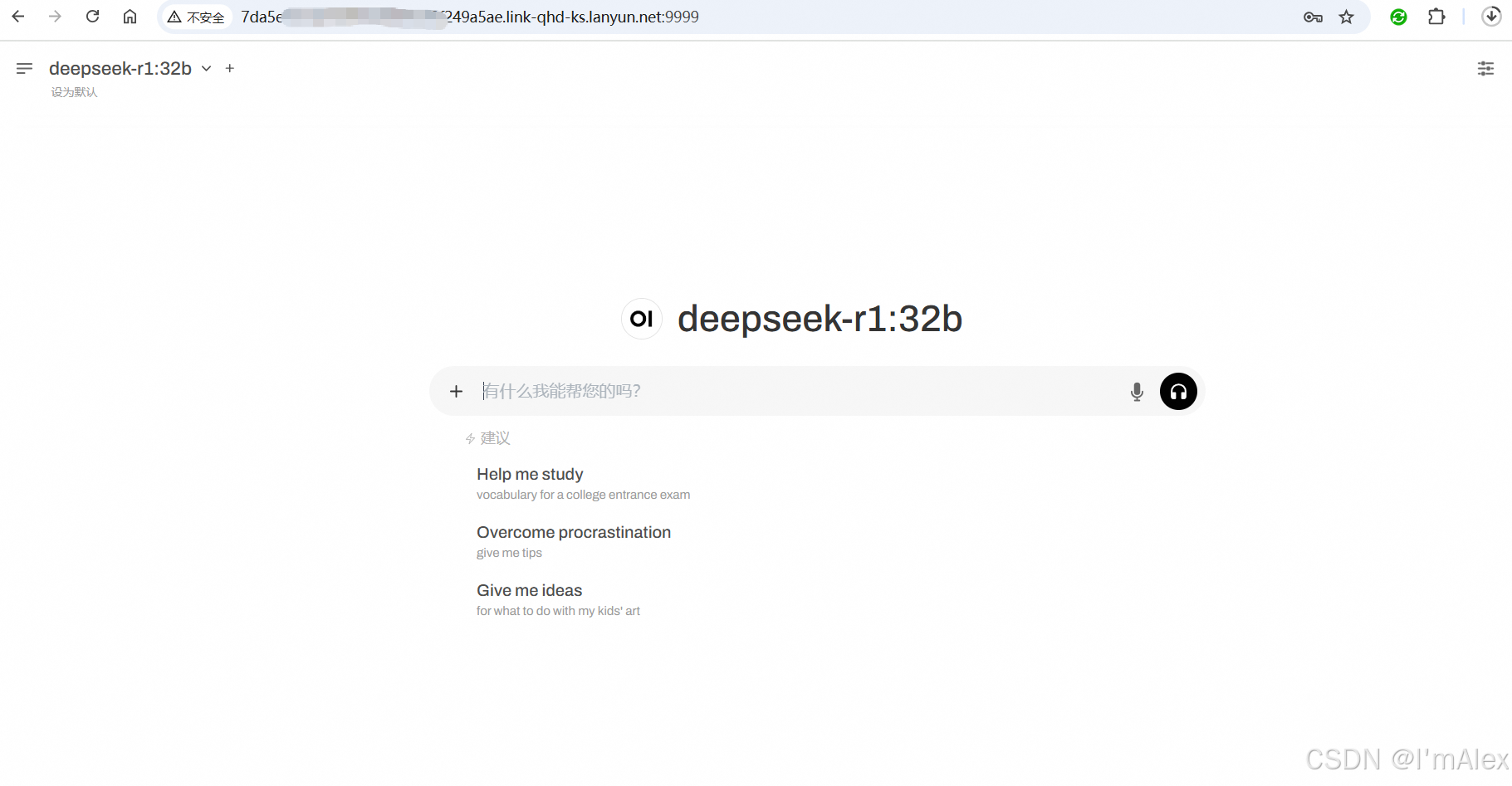
3.4 可以使用了
登录成功之后,就可以进入AI对话页面了。左上角可以看到目前模型规模是32b。
4. DeepSeek变身博客写作小助手
4.1 推荐博客选题

我:
是一名人工智能行业的大模型开发者,最近在写博客过程中,没有思路了。给我推荐5个选择。直接给出选题即可,不要说别的。
DeepSeek:
- “多模态大模型:未来AI发展的核心方向”
- “大模型与硬件结合:如何优化性能与效率”
- “AI在垂直行业的突破:医疗、金融与制造中的新应用”
- “模型压缩与量化:让大模型走向轻量化落地”
- “隐私保护与伦理挑战:大模型时代的必然议题”
4.2 构思博客大纲

我:
好的。以“模型压缩与量化:让大模型走向轻量化落地 ”为选题,构思下这篇文章的大纲。
DeepSeek:
大纲:模型压缩与量化——让大模型走向轻量化落地
一、引言
- 为什么需要模型压缩与量化?
- 大模型的优势与资源消耗矛盾。
- 模型轻量化的实际需求:从云端到边缘设备的广泛部署。
二、模型压缩与量化的基础概念
- 什么是模型压缩?
- 剪枝(Pruning)、蒸馏(Distillation)等技术的核心思想。
- 量化的基本原理:
- 从 FP32 到 INT8,精度与计算效率的平衡。
- 量化 vs 压缩:区别与联系。
三、模型压缩与量化的关键技术路径
- 模型剪枝(Network Pruning)
- 结构化剪枝 vs 非结构化剪枝。
- 剪枝策略与效果评估。
- 知识蒸馏(Knowledge Distillation)
- 大模型到小模型的知识迁移。
- 蒸馏损失的设计与优化。
- 量化技术(Quantization)
- 定点量化(Post-Training Quantization)。
- 动态量化 vs 静态量化。
- 量化感知训练(QAT)。
- 混合精度训练(Mixed Precision Training)
- 结合 FP16 和 INT8,平衡精度与效率。
四、模型压缩与量化的实际应用场景
- 移动设备上的 AI 模型部署:
- 如何在手机端实现高性能推理。
- 嵌入式设备的轻量化需求:
- 低功耗、低成本硬件上的高效运行。
- 物联网(IoT)中的模型应用:
- 资源受限环境下的实时推理。
- 自动驾驶与实时系统:
- 高效推理的必要性与实现路径。
五、面临的挑战与未来方向
- 精度损失与计算效率的平衡:
- 如何在压缩过程中保持模型性能。
- 复杂网络结构的压缩难点:
- Transformer 等深度网络的剪枝与量化技术。
- 跨平台部署与硬件适配:
- 不同硬件架构(如 ARM、GPU)下的优化策略。
六、总结与展望
- 模型压缩与量化的重要性与未来趋势。
- 自动化工具与框架的潜力。
- 推动大模型在更广泛场景中的落地应用。
4.3 撰写博客内容

我:
嗯,构思的不错,可以按照这个大纲补全这篇博客的内容吗?
DeepSeek:
模型压缩与量化:让大模型走向轻量化落地一、引言
随着深度学习技术的快速发展,大型神经网络模型(如BERT、GPT-3等)在自然语言处理、计算机视觉等领域取得了令人瞩目的成就。然而,这些大模型通常需要大量的计算资源和存储空间,限制了它们在实际场景中的广泛应用。尤其是在移动设备、嵌入式系统等资源受限的环境中,直接部署大型模型变得异常困难。
为了克服这一问题,模型压缩与量化技术应运而生。通过模型压缩与量化,我们可以在保持模型性能的同时,显著降低模型的计算复杂度和存储需求,从而实现大模型在边缘设备上的高效部署。本文将详细介绍模型压缩与量化的基础概念、关键技术路径以及实际应用场景,并探讨这一领域的未来发展方向。
二、模型压缩与量化的基础知识
- 什么是模型压缩?
模型压缩的目标是通过减少模型的参数数量或优化模型结构,降低模型的复杂度和计算需求。常见的压缩技术包括:
- 剪枝(Pruning):移除对模型贡献较小的神经元或权重。
- 蒸馏(Distillation):将大模型的知识迁移到一个更小、更轻量化的模型中。
- 量化的基本原理
量化是通过降低数值精度来减少模型的存储和计算开销。例如,传统的浮点数运算使用32位浮点数(FP32),而量化技术可以将这些参数压缩到8位整数(INT8)或更低精度。
- 定点量化:将权重和激活值转换为低精度表示。
- 动态量化 vs 静态量化:动态量化在推理过程中实时调整缩放因子,静态量化则在训练后固定缩放因子。
- 量化感知训练(QAT):在训练阶段引入量化操作,提升量化模型的性能。
- 量化 vs 压缩:区别与联系
压缩技术主要关注减少参数数量,而量化技术则是通过降低精度来优化计算效率。两者可以结合使用,以实现更高效的模型部署。
三、模型压缩与量化的关键技术路径
- 模型剪枝(Network Pruning)
剪枝是一种直接减少模型参数数量的方法。根据剪枝策略的不同,可分为以下两类:
- 结构化剪枝:移除整个神经元或通道(如Channel Pruning),保证剪枝后的模型仍具有规则的网络结构。
- 非结构化剪肢:随机移除部分权重,可能会导致不规则的稀疏矩阵。
- 知识蒸馏(Knowledge Distillation)
知识蒸馏的核心思想是将大模型的知识迁移到一个更小的学生模型中。具体步骤如下:
使用大模型(教师模型)对数据进行训练。
将学生模型在教师模型的指导下进行微调,使其模仿教师模型的输出。
量化技术
- 定点量化:直接将权重和激活值转换为低精度表示。例如,Post-Training Quantization(PTQ)是后训练量化,适用于已经训练好的模型。
- 量化感知训练(QAT):在训练过程中引入量化操作,通过反向传播优化量化后的参数。
- 混合精度训练
混合精度训练结合了FP16和INT8等不同精度的计算,可以在保持模型性能的同时显著提升计算效率。这种方法需要硬件支持(如NVIDIA的Tensor Core)。
四、模型压缩与量化的实际应用场景
- 移动设备上的 AI 模型部署
在移动设备上运行大模型通常会面临计算资源和存储空间的限制。通过模型压缩与量化,可以在手机端实现高性能推理。例如,苹果的Core ML框架就集成了多种压缩与量化技术。
- 嵌入式设备的轻量化需求
嵌入式设备(如智能家居、自动驾驶系统)通常具有严格的功耗和成本限制。通过剪枝和量化,可以将模型优化到满足这些设备的要求。
- 物联网中的实时推理
在物联网场景中,设备通常需要进行实时推理,但计算资源有限。压缩与量化技术可以帮助模型在低功耗设备上快速运行。
- 自动驾驶系统
自动驾驶系统对模型的实时性和准确性要求极高。通过压缩与量化技术,可以在保证性能的同时降低硬件成本。
五、未来发展方向
尽管模型压缩与量化已经取得了显著进展,但仍有许多值得探索的方向:
- 自动化压缩工具:开发更加智能化的压缩工具,能够根据具体场景自动选择最优的压缩策略。
- 端到端量化训练:将量化过程集成到模型训练中,进一步提升量化模型的性能。
- 稀疏计算硬件支持:随着稀疏计算技术的发展,硬件厂商可以为剪枝后的模型提供更好的支持。
六、总结
模型压缩与量化是推动深度学习技术落地的重要手段。通过减少模型的参数数量和计算复杂度,这一技术使得大模型能够在资源受限的环境中高效运行。未来,随着算法和硬件的不断进步,模型压缩与量化将在更多领域发挥重要作用。
4.4 优化博客内容
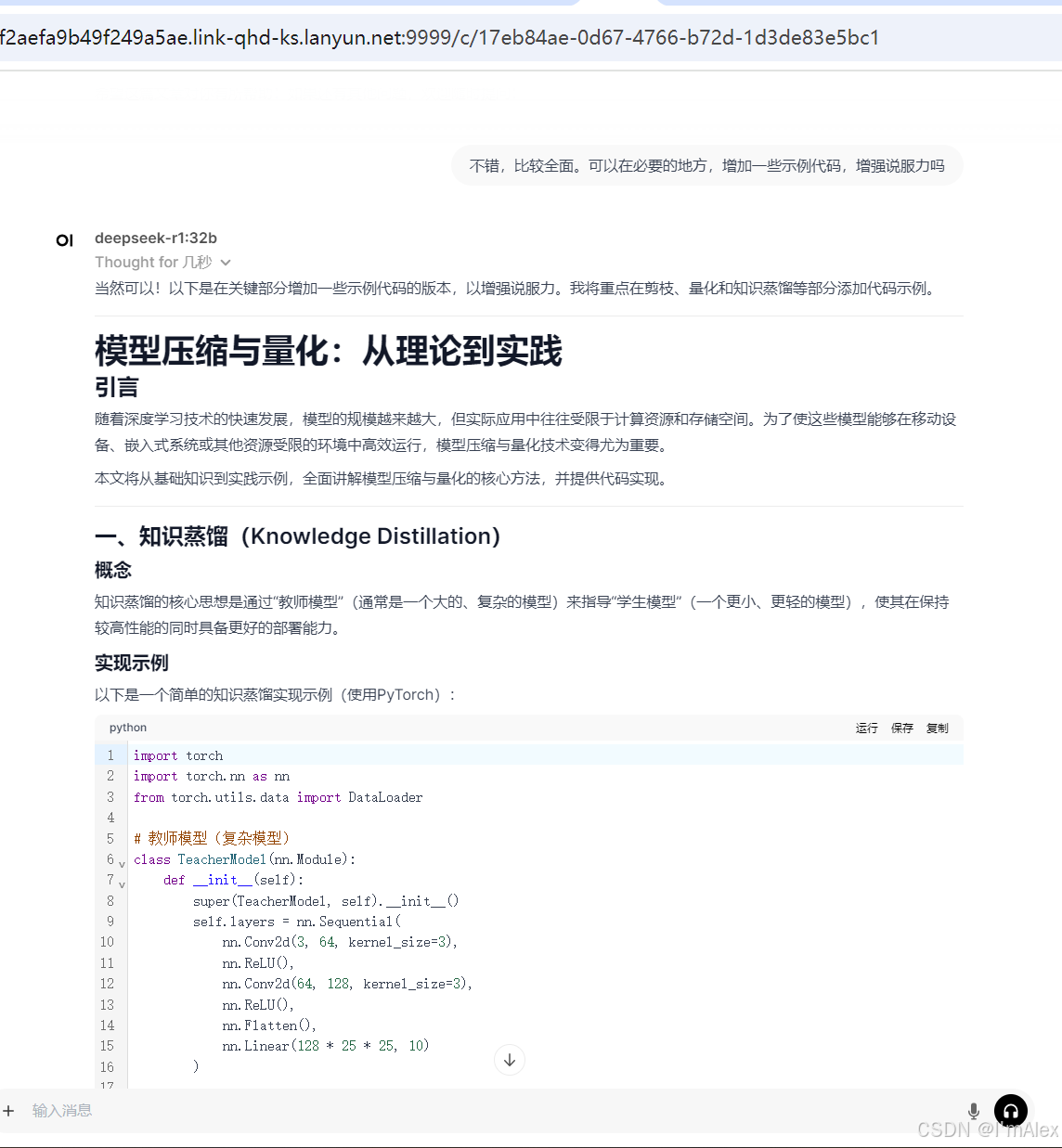
我:
不错,比较全面。可以在必要的地方,增加一些示例代码,增强说服力吗
DeepSeek:
模型压缩与量化:从理论到实践引言
随着深度学习技术的快速发展,模型的规模越来越大,但实际应用中往往受限于计算资源和存储空间。为了使这些模型能够在移动设备、嵌入式系统或其他资源受限的环境中高效运行,模型压缩与量化技术变得尤为重要。本文将从基础知识到实践示例,全面讲解模型压缩与量化的核心方法,并提供代码实现。
一、知识蒸馏(Knowledge Distillation)
概念
知识蒸馏的核心思想是通过“教师模型”(通常是一个大的、复杂的模型)来指导“学生模型”(一个更小、更轻的模型),使其在保持较高性能的同时具备更好的部署能力。实现示例
以下是一个简单的知识蒸馏实现示例(使用PyTorch):
import torch import torch.nn as nn from torch.utils.data import DataLoader # 教师模型(复杂模型) class TeacherModel(nn.Module): def __init__(self): super(TeacherModel, self).__init__() self.layers = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3), nn.ReLU(), nn.Conv2d(64, 128, kernel_size=3), nn.ReLU(), nn.Flatten(), nn.Linear(128 * 25 * 25, 10) ) def forward(self, x): return self.layers(x) # 学生模型(轻量化模型) class StudentModel(nn.Module): def __init__(self): super(StudentModel, self).__init__() self.layers = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3), nn.ReLU(), nn.Flatten(), nn.Linear(64 * 25 * 25, 10) ) def forward(self, x): return self.layers(x) # 损失函数(结合分类损失和蒸馏损失) def distillation_loss(student_logits, teacher_logits, labels, temperature=2.0): # 分类损失 ce_loss = nn.CrossEntropyLoss()(student_logits, labels) # 蒸馏损失(软目标) student_softmax = nn.functional.softmax(student_logits / temperature, dim=1) teacher_softmax = nn.functional.softmax(teacher_logits / temperature, dim=1) kl_divergence = nn.KLDivLoss(reduction='batchmean')(student_softmax.log(), teacher_softmax) return ce_loss + (kl_divergence * temperature ** 2) # 数据加载器(假设已有数据集) train_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 初始化模型和优化器 teacher_model = TeacherModel() student_model = StudentModel() optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001) # 训练过程 for epoch in range(num_epochs): for images, labels in train_loader: # 前向传播 teacher_outputs = teacher_model(images) student_outputs = student_model(images) # 计算损失 loss = distillation_loss(student_outputs, teacher_outputs, labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}") # 测试学生模型 student_model.eval() test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = student_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of student model: {correct / total * 100:.2f}%")
二、模型剪枝(Model Pruning)
概念
剪枝是通过移除模型中不重要的参数或结构,来减少模型的复杂度和计算量。剪枝分为“结构化剪枝”(如通道剪枝)和“非结构化剪枝”。实现示例
以下是一个简单的通道剪枝实现示例(使用Keras):
import tensorflow as tf from tensorflow.keras import layers, models # 加载预训练模型 model = models.VGG16(weights='imagenet', include_top=False) # 添加全连接层 flatten_layer = layers.Flatten() dense_layer1 = layers.Dense(4096, activation='relu') dense_layer2 = layers.Dense(4096, activation='relu') predictions = layers.Dense(1000, activation='softmax') model = models.Sequential([ model, flatten_layer, dense_layer1, dense_layer2, predictions ]) # 剪枝函数(通道剪枝) def prune_channels(model): # 遍历层,找到卷积层并剪枝 for layer in model.layers: if isinstance(layer, layers.Conv2D): # 获取权重和掩码 weights = layer.get_weights()[0] mask = tf.abs(weights) < 1e-3 # 剪枝阈值 # 更新权重 pruned_weights = weights * (1 - mask) layer.set_weights([pruned_weights] + layer.get_weights()[1:]) return model # 应用剪枝 pruned_model = prune_channels(model) # 重新编译模型并训练 pruned_model.compile( optimizer='adam', loss=tf.keras.losses.CategoricalCrossentropy(), metrics=['accuracy'] ) pruned_model.fit(train_dataset, epochs=10)
三、量化(Quantization)
概念
量化是通过将模型的浮点数权重压缩为低精度表示(如8位整数),从而减少存储空间和计算资源。实现示例
以下是一个简单的定点量化实现示例(使用PyTorch):
import torch from torch.quantization import QuantWrapper, default_qconfig # 加载预训练模型 model = MobileNetV2(pretrained=True) # 定义量化配置 qconfig = default_qconfig quantized_model = QuantWrapper(model) quantized_model.qconfig = qconfig # 量化准备和转换 torch.utils.quantization.prepare(quantized_model, inplace=True) torch.utils.quantization.convert(quantized_model, inplace=True) # 测试量化后的模型 test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = quantized_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of quantized model: {correct / total * 100:.2f}%")
四、量化感知训练(Quantization-Aware Training, QAT)
概念
QAT是在训练过程中模拟量化带来的精度损失,从而提高量化后模型的性能。实现示例
以下是一个简单的QAT实现示例(使用PyTorch):
import torch from torch.quantization import QuantWrapper, default_qat_qconfig # 加载预训练模型 model = MobileNetV2(pretrained=True) # 定义量化配置 qconfig = default_qat_qconfig quantized_model = QuantWrapper(model) quantized_model.qconfig = qconfig # 准备QAT torch.utils.quantization.prepare_qat(quantized_model, inplace=True) # 定义优化器和损失函数 optimizer = torch.optim.Adam(quantized_model.parameters(), lr=0.001) loss_fn = torch.nn.CrossEntropyLoss() # QAT训练过程 for epoch in range(num_epochs): for images, labels in train_loader: # 前向传播 outputs = quantized_model(images) loss = loss_fn(outputs, labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}") # 转换为量化模型 torch.utils.quantization.convert(quantized_model, inplace=True) # 测试最终模型 test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = quantized_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of QAT model: {correct / total * 100:.2f}%")
总结
通过以上方法,可以有效降低模型的计算复杂度和存储需求,同时保持较高的性能。这些技术在移动设备部署、边缘计算等领域具有重要意义。
DeepSeek生成的这篇文章,我也已经发表出来了,邀请大家观摩:模型压缩与量化:让大模型走向轻量化落地。大家可以看下它的质量怎么样?是不是非常棒!?
5. 注意事项
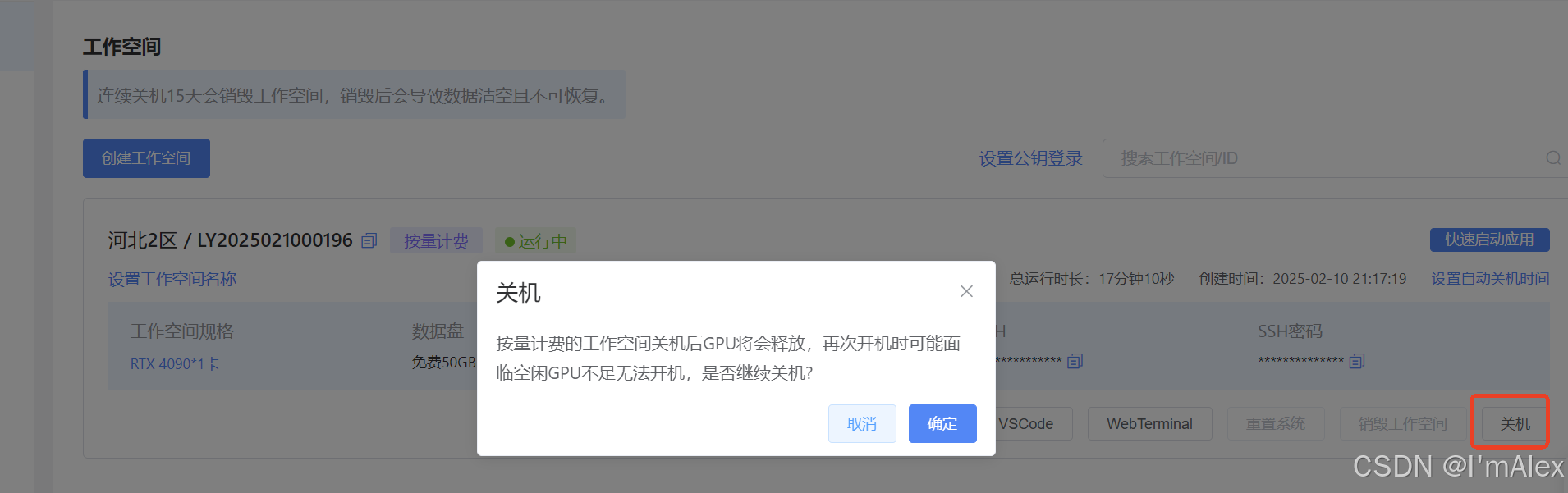
购买成功就自动开机开机计时了,如果你购买的是按量计费,使用过程中要注意时长问题,不用的时候记得及时关机节省费用。
6. 总结与展望
本文主要为大家展示了如何基于蓝耘云快速部署DeepSeek的步骤,最后又结合一个实际场景,演示了DeepSeek的妙用。希望能给大家带来帮助。如果你也想体验一下这个奇妙的过程,按照我这篇文章的教程,访问https://cloud.lanyun.net//#/registerPage?promoterCode=0131实践起来吧。
最近几年,人工智能领域生成式AI一直在高速发展。通用领域的AI已经逐渐趋于饱和,包括DeepSeek在内。其实单从效果来说,DeepSeek也并没有取得革命性的突破,它的创新更多的体现在降本上面。
关于DeepSeek的未来发展,从个人角度而言,希望可以参考Coze的路线,往AI智能体和AI应用的方向去发展,将DeepSeek的优势最大化。