文章目录
1 Generative Adversarial Nets
GAN原文:https://arxiv.org/pdf/1406.2661.pdf

1.1 Generative Model
机器学习模型可分为判别模型(Discriminative Model)与生成模型(Generative Model),判别模型一般构建一个决策面对数据进行分类,而生成模型则需要学习原始样本的数据分布。
GAN是一种生成模型,给定无标签的训练数据集
X
=
{
x
1
,
x
2
,
…
,
x
n
}
X=\left\{x_1,x_2,\ldots,x_n\right\}
X={x1,x2,…,xn}。他可以学习训练数据中的数据分布,生成预测数据
X
′
=
{
x
1
′
,
x
2
′
,
…
,
x
n
′
}
X^\prime=\left\{x_1^\prime,x_2^\prime,\ldots,x_n^\prime\right\}
X′={x1′,x2′,…,xn′}
1.2 Introduction of GAN
GAN的组成包括生成器(Generator)和判别器(Discriminator),Generator从噪声中生成数据,将生成数据送入Discriminator,判断生成数据与真实数据的相似程度,从而进一步优化生成器的生成能力和判别器的判断能力。
论文中给出训练算法:
训练判别器时,算法中采用了梯度上升,是因为对交叉熵损失去掉了负号。在我们写代码时,由于交叉熵默认带负号,因此等价于梯度下降。

训练生成器时,作者告诉我们,由于一开始生成器的生成能力较弱,因此 D ( G ( z ) ) D(G(z)) D(G(z))容易为0,导致 log ( 1 − D ( G ( z ) ) ) \log{(1-D(G(z)))} log(1−D(G(z)))趋向于0,造成梯度消失。作者考虑到了这个问题,并提供了一个方法:
换句话说,我们不去最大化假图和假标签的距离,而是最小化假图和真标签之间的距离。
对于生成器
G
G
G,我们令
y
t
r
u
e
=
1
y_{true}=1
ytrue=1,
y
f
a
k
e
=
0
y_{fake}=0
yfake=0,则我们的目标是:
min
[
L
C
r
o
s
s
E
n
t
r
o
p
y
(
D
(
G
(
z
)
)
,
y
t
r
u
e
)
]
=
min
[
−
log
(
D
(
G
(
z
)
)
)
]
⟺
max
[
log
(
D
(
G
(
z
)
)
)
]
\min{[L_{CrossEntropy}(D(G(z)), y_{true})]}=\min[-\log{(D(G(z)))}]\iff\max[\log(D(G(z)))]
min[LCrossEntropy(D(G(z)),ytrue)]=min[−log(D(G(z)))]⟺max[log(D(G(z)))]

1.3 a simple theory
从交叉熵看起:



2 代码实现
2.1 实验目标
搭建GAN,实现对MNIST数据集的生成,测试效果
2.2 GAN网络结构
Generator生成器,Discriminator判别器。为简化实验,采用简单的三层全连接网络实现。
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Linear(in_features=100, out_features=256),
nn.ReLU(),
nn.Linear(in_features=256, out_features=256),
nn.ReLU(),
nn.Linear(in_features=256, out_features=28*28),
nn.Sigmoid()
)
def forward(self, X):
return self.network(X)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Linear(in_features=28*28, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=1),
nn.Sigmoid()
)
def forward(self, X):
return self.network(X)
2.3 对抗训练
注意,针对Generator和Discriminator分别进行训练,两个网络的训练在一个循环中,即分别更新D和G。常见的误区是先把D更新好再去更新G,或者先把G更新好再去更新D,这样都是错的,因为GAN是一个对抗训练的过程,D和G水平应该相当,任何一方太强都不行。网络的训练代码如下:
def train():
for epoch in range(epochs):
print(f"epoch {epoch+1}\n-----------------")
for i, (X_real, _) in enumerate(real_dataloader):
length = X_real.shape[0]
y_real = torch.ones(length, 1)
y_fake = torch.zeros(length, 1)
X_real, y_real, y_fake = X_real.to(device), y_real.to(device), y_fake.to(device)
# 1 ------------更新Discriminator--------------
z_batch = torch.randn(length, 100).to(device)
X_fake = G(z_batch)
output_real = D(X_real.reshape(length, 28*28))
loss_real = bce_loss(output_real, y_real)
output_fake = D(X_fake)
loss_fake = bce_loss(output_fake, y_fake)
loss_D = loss_real + loss_fake
D.zero_grad()
loss_D.backward()
optimizer_D.step()
# 2 -------------更新Generator---------------
z_batch = torch.randn(length, 100).to(device)
X_fake = G(z_batch)
fake_output = D(X_fake)
loss_G = bce_loss(fake_output, y_real)
G.zero_grad()
loss_G.backward()
optimizer_G.step()
if i % 100 == 0:
print(f"loss_G: {loss_G.item()}, loss_D: {loss_D.item()}, D(x): {loss_real.item()}, D(G(z)): {loss_fake.item()}")
loss_G_list.append(loss_G.item())
loss_D_list.append(loss_D.item())
Dx_list.append(loss_real.item())
DGz_list.append(loss_fake.item())
global iter
iter += 1
# 保存最后的权重文件
torch.save(G.state_dict(), 'model_G.pth')
2.4 生成结果
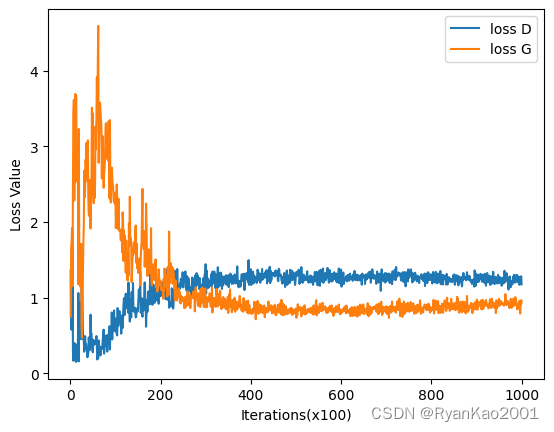
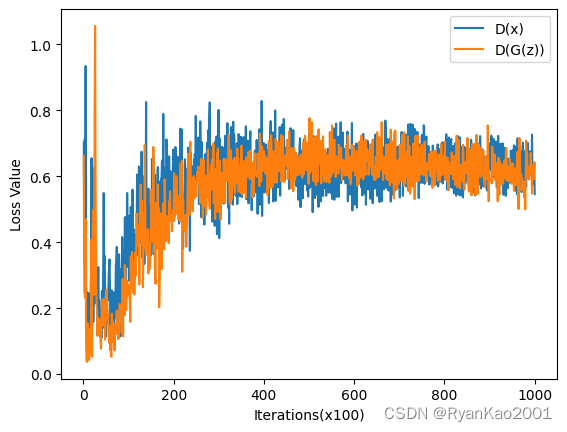

3 完整代码
完整代码已上传至github,地址:https://github.com/gwcrepo/GAN-MNIST,有帮助记得star