开发环境
python–3.7
torch–1.8+cu101
torchsummary
torchvision–0.6.1+cu101
PIL
numpy
opencv-python
pillow
准备工作
alexnet预训练模型,下载地址:
https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth
猫狗数据集,下载地址::
www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
项目代码结构
data文件存储了猫狗数据集(训练集和测试集)以及alexnet预训练模型,另外还有一些用于推理的测试图片和模型设置文件。
src存储了alexnet测试文件、可视化(卷积核和特征图)文件和训练文件。
tools存储了通用文件:数据集构建文件。
results存储了tensorboard的一些绘制结果文件。
关键函数
torch.topk
# 找出前k大的数据,及其索引序号。
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None)
"""
input: 输入张量
k : 决定选取前k个值
dim:索引维度
返回值:
Tensor:前k大的值
LongTensor:前k大的值所在的位置
"""
FiveCrop和TenCrop
import torchvision.transforms as transforms
transforms.FiveCrop(size)
transforms.TenCrop(size, vertical_flip=False)
"""
在图像的上下左右以及中心裁剪出尺寸为size的5张图片,TenCrop对这5张图片进行水平或者垂直镜像获得10张图片
size:所需裁剪图片尺寸
vertical_flip:是否垂直翻转,否则为水平翻转
TenCrop比FiveCrop多了翻转操作,得到2倍数量的图片
"""
torchvision.utils.make_grid
from torchvision.utils import make_grid
make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)
"""
功能:制作网格图像
tensor:图像数据,B*C*H*W形式
nrow:行数(列数自动计算)
padding:图像间距(像素单位)
normalize:是否将像素值标准化
range:标准化范围
scale_each:是否单张图维度标准化
pad_value:padding的像素值
"""
代码结构
alexnet_inference.py
- 加载图片
- 加载模型
- 模型推理
- 获取类别
- 分类结果可视化
注意事项:
- 模型接受4D张量,即(B, C, H, W);pytorch官网的alexnet弃用LRN;增加了adaptiveavgpool2d;卷积核数量有所改变。

import os
import time
import json
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' # 防止中文复制乱码
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件的文件夹绝对路径,
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL的image对象
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("\n找不到transform! 必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def load_class_names(p_clsnames, p_clsnames_cn):
"""
加载标签名
:param p_clsnames:
:param p_clsnames_cn:
:return:
"""
with open(p_clsnames, "r") as f:
class_names = json.load(f)
with open(p_clsnames_cn, encoding='UTF-8') as f:
class_names_cn = f.readlines()
return class_names, class_names_cn
def get_model(path_state_dict, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:param vis_model:
:return:
"""
model = models.alexnet()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
def process_img(path_img):
norm_mean = [0.485, 0.456, 0.406] # imagenet上三通道上像素值上的均值和标准差。
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)
])
img_rgb = Image.open(path_img).convert('RGB') # path-->img
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
if __name__ == "__main__":
# config
path_state_dict = os.path.join(BASE_DIR, "..", "data", "alexnet-owt-4df8aa71.pth")
# path_img = os.path.join(BASE_DIR, "..", "data", "Golden Retriever from baidu.jpg"
path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "data", "imagenet_classnames.txt")
# load class names
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
# 1/5 load img
img_tensor, img_rgb = process_img(path_img)
# 2/5 load model
alexnet_model = get_model(path_state_dict, True)
# 3/5 inference tensor --> vector
with torch.no_grad():
time_tic = time.time()
outputs = alexnet_model(img_tensor)
time_toc = time.time()
# 4/5 index to class names
_, pre_int = torch.max(outputs.data, 1)
_, top5_idx = torch.topk(outputs.data, 5, dim=1)
pre_idx = int(pre_int.cpu().numpy())
pred_str, pred_cn = cls_n[pre_idx], cls_n_cn[pre_idx]
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming: {:.2f}s".format(time_toc-time_tic))
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()
AlexNet代码实现
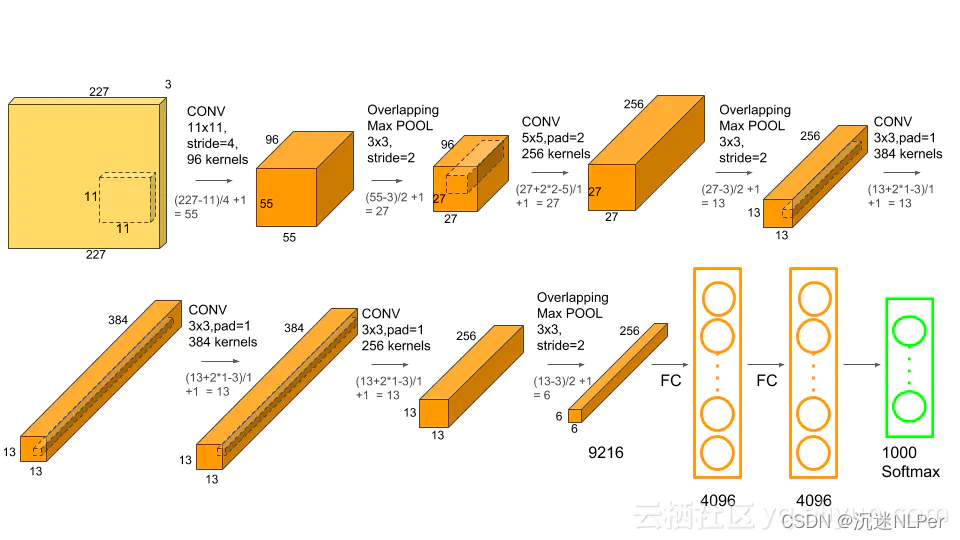
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# conv1
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 带重叠池化
# conv2
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# conv3
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# conv4
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# conv5
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
slef.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
alexnet_visualizaton.py
- 卷积核可视化
- 特征图可视化
import os
import torch
import torch.nn as nn
from PIL import Image
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torchvision.utils as vutils
import torchvision.models as models
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
log_dir = os.path.join(BASE_DIR, "..", "results")
writer = SummaryWriter(log_dir=log_dir, filename_suffix="_kernel")
path_state_dict = os.path.join(BASE_DIR, "..", "data", "alexnet-owt-4df8aa71.pth")
alexnet = models.alexnet()
pretrained_state_dict = torch.load(path_state_dict)
alexnet.load_state_dict(pretrained_state_dict)
kernel_num = -1
vis_max = 1
for sub_module in alexnet.modules():
if not isinstance(sub_module, nn.Conv2d):
continue
kernel_num += 1
if kernel_num > vis_max:
break
kernels = sub_module.weight
c_out, c_int, k_h, k_w = tuple(kernels.shape)
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1)
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=620)
kernel_all = kernels.view(-1, 3, k_h, k_w)
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8)
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=620)
writer = SummaryWriter(log_dir=log_dir, filename_suffix="_feature map")
path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0)
convlayer1 = alexnet.features[0]
fmap_1 = convlayer1(img_tensor)
fmap_1.transpose_(0, 1)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=620)
writer.close()
train_alexnet.py
- 构建DataLoader
- 构建模型
- 构建损失函数
- 构建优化器
- 迭代训练
猫狗大战数据集:
训练集:25000张图,有标签
测试集:12500张图,无标签
import os
import numpy as np
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
import torchvision.models as models
from tools.my_dataset import CatDogDataset
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def get_model(path_state_dict, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.alexnet()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
if __name__ == "__main__":
# config
data_dir = os.path.join(BASE_DIR, "..", "data", "train")
path_state_dict = os.path.join(BASE_DIR, "..", "data", "alexnet-owt-4df8aa71.pth")
num_classes = 2
MAX_EPOCH = 3 # 可自行修改
BATCH_SIZE = 128 # 可自行修改
LR = 0.001 # 可自行修改
log_interval = 1 # 可自行修改
val_interval = 1 # 可自行修改
classes = 2
start_epoch = -1
lr_decay_step = 1 # 可自行修改
# ============================ step 1/5 数据 ============================
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别
transforms.CenterCrop(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
normalizes = transforms.Normalize(norm_mean, norm_std)
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
# 构建MyDataset实例
train_data = CatDogDataset(data_dir=data_dir, mode="train", transform=train_transform)
valid_data = CatDogDataset(data_dir=data_dir, mode="valid", transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=4)
# ============================ step 2/5 模型 ============================
alexnet_model = get_model(path_state_dict, False)
num_ftrs = alexnet_model.classifier._modules["6"].in_features
alexnet_model.classifier._modules["6"] = nn.Linear(num_ftrs, num_classes)
alexnet_model.to(device)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
# 冻结卷积层
flag = 0
# flag = 1
if flag:
fc_params_id = list(map(id, alexnet_model.classifier.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, alexnet_model.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 0
{'params': alexnet_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(alexnet_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
alexnet_model.train()
for i, data in enumerate(train_loader):
# if i > 1:
# break
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = alexnet_model(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
alexnet_model.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
bs, ncrops, c, h, w = inputs.size() # [4, 10, 3, 224, 224]
outputs = alexnet_model(inputs.view(-1, c, h, w))
outputs_avg = outputs.view(bs, ncrops, -1).mean(1)
loss = criterion(outputs_avg, labels)
_, predicted = torch.max(outputs_avg.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().cpu().sum().numpy()
loss_val += loss.item()
loss_val_mean = loss_val/len(valid_loader)
valid_curve.append(loss_val_mean)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))
alexnet_model.train()
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
猫狗数据集构建程序
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
class CatDogDataset(Dataset):
def __init__(self, data_dir, mode="train", split_n=0.9, rng_seed=620, transform=None):
"""
分类任务的Dataset
:param data_dir: 数据集路径
:param mode: 训练集/验证集
:param split_n: 数据集划分比例
:param rng_seed: 随机种子
:param transform: torch.transform,数据预处理
"""
self.mode = mode
self.data_dir = data_dir
self.rng_seed = rng_seed
self.split_n = split_n
self.data_info = self._get_img_info() # data_info 存储所有图片路径和标签,在dataloader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0-255
if self.transform is not None:
img = self.transform(img) # 将img转化为tensor等
return img, label
def __len__(self):
if len(self.data_info) == 0:
raise Exception("\ndata_dir: {} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.data_info)
def _get_img_info(self):
img_names = os.listdir(self.data_dir)
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
random.seed(self.rng_seed)
random.shuffle(img_names)
img_labels = [0 if n.startswith('cat') else 1 for n in img_names]
split_idx = int(len(img_labels) * self.split_n)
if self.mode == "train":
img_set = img_names[:split_idx] # 数据集中90%作为训练集
label_set = img_labels[:split_idx]
elif self.mode == "valid":
img_set = img_names[split_idx:] # 数据集中10%作为验证集
label_set = img_labels[split_idx:]
else:
raise Exception("self.mode 无法识别,仅支持(train, valid)")
path_img_set = [os.path.join(self.data_dir, n) for n in img_set]
data_info = [(n, l) for n, l in zip(path_img_set, label_set)]
return data_info