Attention成为了越来越来模型里绕不过去的坎,好像不过怎么样都加一个,那么注意力机制到底是什么以及计算流程和具体应用有哪些呢,今天来简单罗列一下。
注意力机制的由来
可以粗略地把注意力机制类比成一个可以专注于输入内容的某一子集(或特征)的神经网络,着力于占比不大但是格外重要的部分。
encoder-decoder
想要说明注意力机制的话首先要说明一下一种模型结构,就是nlp领域常用的编码-解码器架构(seq2seq的说话侧重点是输入输出的数据形式,虽然实际上这类问题常用编码-解码器结构,但是他们是不一样的)。
简单来说就是输入数据经过一个网络运算后得到一个语义向量c然后让解码器对其处理得到最后的输出。最大的局限性也就在于编码器和解码器之间的唯一联系就是一个语义向量C。有两点有待改进:1.c的长度限制了信息的表达;2.后输入的数据会覆盖带先输入的数据,除非记录每一个c(比如机器翻译的文章《Neural Machine Translation by Jointly Learning to Align and Translate》中引入attention就是为解码时每一步关注不同的c,充分利用序列信息)。
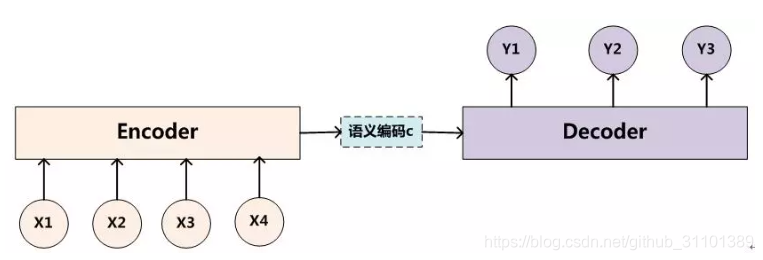
简单原理说明
注意力机制利用大致为输入一个query得到一个注意力,标志模型中输出对输入的侧重点,其流程如下。
- 用i时刻的解码器的隐状态 H i H_i Hi去一一和输入产生的编码器每个隐状态 h j h_j hj</