如果是Standalone Cluster模式运行可以不依赖于Hadoop,直接下载对应版本即可。如果有时需要基于YARN来提交运行,则需要选择对应Hadoop版本的Flink安装部署。访问官网的下载页面Flink Downloads,可以看到如果是Flink 1.8版本与捆绑的Hadoop版本有Hadoop 2.4.1、Hadoop 2.6.5、Hadoop 2.7.5、Hadoop 2.8.3,将下载的对应捆绑的Hadoop jar包放到 $FLINK_HOME/lib 下即可,但如果Hadoop版本不同时也是要考虑对源码指定Hadoop版本进行编译获取分发包进行部署安装。同时如果想使用Blink新功能也是需要对源码进行编译。
目录
- 1 从源码构建Flink(译自官方文档)
- 2 编译部署
- 2.1 环境要求
- 2.2 获取源码
- 2.3 查看版本和分支
- 2.4 切换到对应的版本或分支
- 2.5 查看当前所处的分支
- 2.6 开始编译
- 2.6.1 指定Hadoop版本进行编译
- 2.6.2 基于供应商特定版(如Cloudera、Hortonworks等)
- 2.6.3 Blink
- 2.7 复制分发包到安装节点
- 2.8 配置环境变量
- 2.9 standalone模式启动
- 2.10 YARN模式
- 2.10.1 yarn-session模式
- 2.10.2 Per-Job模式
- 2.11 Blink
我们先阅读以下官方文档:Flink Development / Building Flink from Source
| 官方文档的目录 |
|---|
| Build Flink (构建 Flink) |
| Dependency Shading (遮蔽依赖) |
| Hadoop Versions (Hadoop 版本) |
| Packaging Hadoop into the Flink distribution (将Hadoop 打包到Flink发行版中) |
| Vendor-specific Versions (供应商特定版本) |
| Scala Versions (Scala版本) |
| Encrypted File Systems (加密文件系统) |
1 从源码构建Flink(官方文档)
1.1 Build Flink (构建 Flink)
为了构建 Flink,您需要源代码。下载发行版的源代码 或 克隆git存储库。
此外,您还需要 Maven 3 和 JDK(Java Development Kit)。 Flink至少需要 Java 8 才能构建。
注意:Maven 3.3.x 可以构建 Flink,但不会正确地遮蔽某些依赖项。 Maven 3.2.5正确创建了库。 要构建单元测试,请使用 Java 8u51 或更高版本来防止使用 PowerMock 运行程序的单元测试失败。
要从git克隆,请输入:
git clone https://github.com/apache/flink.git
构建Flink的最简单方法是运行:
mvn clean install -DskipTests
这指示 Maven(mvn)首先清除所有已构建的(clean),然后创建一个新的 Flink 二进制文件(install)。
要加快构建速度,您可以跳过测试,QA插件和JavaDocs:
mvn clean install -DskipTests -Dfast
默认构建为 Hadoop 2 添加了特定于 Flink的JAR,以允许将 Flink 与 HDFS 和 YARN 一起使用。
1.2 Dependency Shading (依赖 shading)
Flink 隐藏了它使用的一些库,以避免与使用这些库的不同版本的用户程序的版本冲突。 Shaded 库包括Google Guava,Asm,Apache Curator,Apache HTTP Components,Netty等。
最近在 Maven中 更改了依赖关系 shading 机制,并要求用户根据 Maven 版本略微不同地构建Flink:
-
Maven 3.0.x,3.1.x和3.2.x在Flink代码库的根目录中调用mvn clean install -DskipTests就足够了。
-
Maven 3.3.x构建必须分两步完成:首先在 base 目录中,然后在分发项目中:
mvn clean install -DskipTests
cd flink-dist
mvn clean install
注意:要检查Maven版本,请运行mvn --version。
1.3 Hadoop Versions (Hadoop 版本)
信息 大多数用户不需要手动执行此操作。 下载页面包含常见Hadoop版本的二进制包。
Flink 依赖于 HDFS 和 YARN,它们都是来自 Apache Hadoop 的依赖项。 存在许多不同版本的 Hadoop(来自上游项目和不同的Hadoop发行版)。 如果使用错误的版本组合,则可能发生异常。
Hadoop仅从2.4.0版本开始支持。 您还可以指定要构建的特定Hadoop版本:
mvn clean install -DskipTests -Dhadoop.version=2.6.1
1.3.1 Packaging Hadoop into the Flink distribution (将Hadoop 打包到Flink发行版中)
如果要构建一个在 lib 文件夹中预先打包 shaded Hadoop 的 Flink 发行版,则可以使用 include-hadoop 配置文件来执行此操作。您将如上所述构建 Flink,但包括配置文件:
mvn clean install -DskipTests -Pinclude-hadoop
1.3.2 Vendor-specific Versions (供应商特定版本)
要查看支持的供应商版本列表,请查看https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs?repo=cloudera
要针对特定于供应商的 Hadoop 版本构建 Flink,请执行以下命令:
mvn clean install -DskipTests -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.16.1
-Pvendor-repos激活 Maven 构建配置文件,其中包括 Cloudera,Hortonworks 或 MapR 等流行的 Hadoop 供应商的存储库。
1.4 Scala Versions (Scala版本)
信息 纯粹使用Java API 和 库的用户可以忽略此部分。
Flink 具有用 Scala 编写的 API,库和运行时模块。 Scala API 和库的用户可能必须将 Flink 的 Scala 版本与其项目的 Scala 版本匹配(因为Scala不是严格向后兼容的)。
从版本 1.7 开始,Flink使用Scala版本2.11和2.12构建。
1.5 Encrypted File Systems (加密文件系统)
如果您的主目录已加密,您可能会遇到java.io.IOException:File name too long exception。某些加密文件系统(如 Ubuntu 使用的 encfs)不允许长文件名,这是导致此错误的原因。
解决方法是添加:
<args>
<arg>-Xmax-classfile-name</arg>
<arg>128</arg>
</args>
在导致错误的模块的 pom.xml 文件的编译器配置中。 例如,如果错误出现在 flink-yarn 模块中,则应在 scala-maven-plugin 的 标记下添加上述代码。 有关更多信息,请参阅此问题。
2 编译部署
以下会对三种情况分别进行编译,指定Hadoop版本、Cloudera Hadoop版、Blink进行编译,以及Cloudera版本出现问题的解决方法,并对编译的发行包快速部署。最后对Standalone和YARN两种方式进行小的测试。
2.1 环境要求
- JDK 1.8
- Maven 3 (查看版本 mvn --version)
- Maven 3.0.x,3.1.x和3.2.x 只需调用
mvn clean install -DskipTestsFlink代码库的根目录即可。 - Maven 3.3.x 构建必须分两步完成:首先在基本目录中,然后在分发项目中:
mvn clean install -DskipTests cd flink-dist mvn clean install - Maven 3.0.x,3.1.x和3.2.x 只需调用
- Scala (默认Scala使用的是
2.11)。如果是纯粹使用Java API和库的用户可以忽略Scala的版本问题。
2.2 获取源码
获取源码
git clone https://github.com/apache/flink.git
#进入到源码根目录
cd flink
2.3 查看版本和分支
# 查看tag版本
git tag
#查看远程服务上的分支
git branch -r
2.4 切换到对应的版本或分支
#切换到 flink 1.8 发行版
git checkout tags/release-1.8.1
#切换到Blink分支
git checkout origin/blink
2.5 查看当前所处的分支
git branch
2.6 开始编译
hadoop版本选择可以访问mvn仓库地址:https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs。
编译过程需要一段时间,耐心等待,顺利的话是可以直接编译通过。如果是依赖包的问题,可以到Maven仓库中把对应的依赖清除之后再重新编译。
2.6.1 指定Hadoop版本进行编译
例如这里选择的Hadoop版本为 3.1.2,命令中添加 -Pinclude-hadoop 是为了将Hadoop的二进制包直接放入Flink发行版的lib里。如果是Standalone模式可以可以去掉这个参数,当需要往YARN上提交时,只需要将编译的源码包下的flink-shaded-hadoop/flink-shaded-hadoop2-uber/target/flink-shaded-hadoop2-uber-3.1.2-1.8.1.jar拷贝到$FLINK_HOME/lib/下即可。这里一定要使用flink-shaded-hadoop2-uber下的包,如果使用flink-shaded-hadoop2会缺少类。
#-T2C表示一个CPU核心启动两个线程进行编译,可以加快源码编译的速度。
mvn -T2C clean install -DskipTests -Dfast -Pinclude-hadoop -Pvendor-repos -Dhadoop.version=3.1.2
2.6.2 基于供应商特定版(如Cloudera、Hortonworks等)
如果YARN集群是CDH方式搭建,需要指定Cloudera供应商版本的Hadoop,这里使用3.0.0-cdh6.3.0 版本进行编译。
mvn -T2C clean install -DskipTests -Dfast -Pinclude-hadoop -Pvendor-repos -Dhadoop.version=3.0.0-cdh6.3.0
如果中间报某些包无法下载,可以访问对应供应商的仓库,手动导入到Maven本地仓库,例如 Cloudera ,可以访问 https://repository.cloudera.com/artifactory/cloudera-repos,执行如下的命令(例子,版本根据指定的确定)
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-hdfs/3.0.0-cdh6.3.2/hadoop-hdfs-3.0.0-cdh6.3.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-hdfs/3.0.0-cdh6.3.2/hadoop-hdfs-3.0.0-cdh6.3.2-tests.jar
mvn install:install-file -DgroupId=org.apache.hadoop -DartifactId=hadoop-hdfs \
-Dversion=3.0.0-cdh6.3.2 -Dpackaging=jar -Dfile=hadoop-hdfs-3.0.0-cdh6.3.2.jar
mvn install:install-file -DgroupId=org.apache.hadoop -DartifactId=hadoop-hdfs \
-Dversion=3.0.0-cdh6.3.2 -Dpackaging=test-jar -Dfile=hadoop-hdfs-3.0.0-cdh6.3.2-tests.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-common/3.0.0-cdh6.3.2/hadoop-common-3.0.0-cdh6.3.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-common/3.0.0-cdh6.3.2/hadoop-common-3.0.0-cdh6.3.2-tests.jar
mvn install:install-file -DgroupId=org.apache.hadoop -DartifactId=hadoop-common \
-Dversion=3.0.0-cdh6.3.2 -Dpackaging=jar -Dfile=hadoop-common-3.0.0-cdh6.3.2.jar
mvn install:install-file -DgroupId=org.apache.hadoop -DartifactId=hadoop-common \
-Dversion=3.0.0-cdh6.3.2 -Dpackaging=test-jar -Dfile=hadoop-common-3.0.0-cdh6.3.2-tests.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/hadoop/hadoop-mapreduce-client-core/3.0.0-cdh6.3.2/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar
mvn install:install-file -DgroupId=org.apache.hadoop -DartifactId=hadoop-mapreduce-client-core \
-Dversion=3.0.0-cdh6.3.2 -Dpackaging=jar -Dfile=hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar
当使用这个版本的Hadoop会报如下错误
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 08:18 min (Wall Clock)
[INFO] Finished at: 2019-07-27T13:18:30+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.0:testCompile (default-testCompile) on project flink-yarn_2.11: Compilation failure
[ERROR] /opt/flink2/flink-yarn/src/test/java/org/apache/flink/yarn/AbstractYarnClusterTest.java:[89,41] no suitable method found for newInstance(org.apache.hadoop.yarn.api.records.ApplicationId,org.apache.hadoop.yarn.api.records.ApplicationAttemptId,java.lang.String,java.lang.String,java.lang.String,java.lang.String,int,<nulltype>,org.apache.hadoop.yarn.api.records.YarnApplicationState,<nulltype>,<nulltype>,long,long,org.apache.hadoop.yarn.api.records.FinalApplicationStatus,<nulltype>,<nulltype>,float,<nulltype>,<nulltype>)
[ERROR] method org.apache.hadoop.yarn.api.records.ApplicationReport.newInstance(org.apache.hadoop.yarn.api.records.ApplicationId,org.apache.hadoop.yarn.api.records.ApplicationAttemptId,java.lang.String,java.lang.String,java.lang.String,java.lang.String,int,org.apache.hadoop.yarn.api.records.Token,org.apache.hadoop.yarn.api.records.YarnApplicationState,java.lang.String,java.lang.String,long,long,long,org.apache.hadoop.yarn.api.records.FinalApplicationStatus,org.apache.hadoop.yarn.api.records.ApplicationResourceUsageReport,java.lang.String,float,java.lang.String,org.apache.hadoop.yarn.api.records.Token) is not applicable
[ERROR] (actual and formal argument lists differ in length)
[ERROR] method org.apache.hadoop.yarn.api.records.ApplicationReport.newInstance(org.apache.hadoop.yarn.api.records.ApplicationId,org.apache.hadoop.yarn.api.records.ApplicationAttemptId,java.lang.String,java.lang.String,java.lang.String,java.lang.String,int,org.apache.hadoop.yarn.api.records.Token,org.apache.hadoop.yarn.api.records.YarnApplicationState,java.lang.String,java.lang.String,long,long,org.apache.hadoop.yarn.api.records.FinalApplicationStatus,org.apache.hadoop.yarn.api.records.ApplicationResourceUsageReport,java.lang.String,float,java.lang.String,org.apache.hadoop.yarn.api.records.Token,java.util.Set<java.lang.String>,boolean,org.apache.hadoop.yarn.api.records.Priority,java.lang.String,java.lang.String) is not applicable
[ERROR] (actual and formal argument lists differ in length)
[ERROR] method org.apache.hadoop.yarn.api.records.ApplicationReport.newInstance(org.apache.hadoop.yarn.api.records.ApplicationId,org.apache.hadoop.yarn.api.records.ApplicationAttemptId,java.lang.String,java.lang.String,java.lang.String,java.lang.String,int,org.apache.hadoop.yarn.api.records.Token,org.apache.hadoop.yarn.api.records.YarnApplicationState,java.lang.String,java.lang.String,long,long,long,org.apache.hadoop.yarn.api.records.FinalApplicationStatus,org.apache.hadoop.yarn.api.records.ApplicationResourceUsageReport,java.lang.String,float,java.lang.String,org.apache.hadoop.yarn.api.records.Token,java.util.Set<java.lang.String>,boolean,org.apache.hadoop.yarn.api.records.Priority,java.lang.String,java.lang.String) is not applicable
[ERROR] (actual and formal argument lists differ in length)
[ERROR]
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :flink-yarn_2.11
我们可以看到flink-yarn的测试项目发生了异常,在这个版本中org.apache.hadoop.yarn.api.records.ApplicationReport.newInstance方法是不可用的,因此我们需要在flink-yarn模块下的pom文件的build中添加如下插件,跳过本模块的测试代码的编译。这里在YARN集群运行时不会受到影响。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<!-- 略过测试代码的编译 -->
<skip>true</skip>
<!-- The semantics of this option are reversed, see MCOMPILER-209. -->
<useIncrementalCompilation>false</useIncrementalCompilation>
<compilerArgs>
<!-- Prevents recompilation due to missing package-info.class, see MCOMPILER-205 -->
<arg>-Xpkginfo:always</arg>
</compilerArgs>
</configuration>
</plugin>
说明:供应商版的不同版本的 hadoop 可能与 Apache hadoop 有明显改动,此时直接编译可能会报某些类、某些方法找不到的异常,如果是此类型的错误,就需要供应商提供对应版本的支持,当然也可以基于 Flink 源码,修复受影响的类或方法。
2.6.3 Blink
在2.4步骤中直接切换到origin/blink分支,然后同样的方式执行如下命令进行编译:
mvn -T2C clean package -DskipTests -Dfast -Pinclude-hadoop -Pvendor-repos -Dhadoop.version=3.1.2
2.7 复制分发包到安装节点
2.7.1 编译成功后提示如下
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] force-shading 1.8.1 ................................ SUCCESS [ 1.694 s]
[INFO] flink 1.8.1 ........................................ SUCCESS [ 2.068 s]
[INFO] flink-annotations 1.8.1 ............................ SUCCESS [ 2.552 s]
[INFO] flink-shaded-hadoop 1.8.1 .......................... SUCCESS [ 1.085 s]
[INFO] flink-shaded-hadoop2 3.0.0-cdh6.3.0-1.8.1 .......... SUCCESS [ 29.178 s]
[INFO] flink-shaded-hadoop2-uber 3.0.0-cdh6.3.0-1.8.1 ..... SUCCESS [ 58.203 s]
[INFO] flink-shaded-yarn-tests 1.8.1 ...................... SUCCESS [ 41.005 s]
[INFO] flink-shaded-curator 1.8.1 ......................... SUCCESS [ 4.035 s]
[INFO] flink-metrics 1.8.1 ................................ SUCCESS [ 0.781 s]
[INFO] flink-metrics-core 1.8.1 ........................... SUCCESS [ 3.267 s]
[INFO] flink-test-utils-parent 1.8.1 ...................... SUCCESS [ 0.831 s]
[INFO] flink-test-utils-junit 1.8.1 ....................... SUCCESS [ 2.805 s]
[INFO] flink-core 1.8.1 ................................... SUCCESS [ 16.670 s]
[INFO] flink-java 1.8.1 ................................... SUCCESS [ 5.010 s]
[INFO] flink-queryable-state 1.8.1 ........................ SUCCESS [ 0.556 s]
[INFO] flink-queryable-state-client-java 1.8.1 ............ SUCCESS [ 1.204 s]
[INFO] flink-filesystems 1.8.1 ............................ SUCCESS [ 0.613 s]
[INFO] flink-hadoop-fs 1.8.1 .............................. SUCCESS [ 8.472 s]
[INFO] flink-runtime 1.8.1 ................................ SUCCESS [01:15 min]
[INFO] flink-scala 1.8.1 .................................. SUCCESS [01:25 min]
[INFO] flink-mapr-fs 1.8.1 ................................ SUCCESS [ 5.098 s]
[INFO] flink-filesystems :: flink-fs-hadoop-shaded 1.8.1 .. SUCCESS [ 7.291 s]
[INFO] flink-s3-fs-base 1.8.1 ............................. SUCCESS [ 17.262 s]
[INFO] flink-s3-fs-hadoop 1.8.1 ........................... SUCCESS [ 20.488 s]
[INFO] flink-s3-fs-presto 1.8.1 ........................... SUCCESS [ 31.440 s]
[INFO] flink-swift-fs-hadoop 1.8.1 ........................ SUCCESS [ 39.563 s]
[INFO] flink-oss-fs-hadoop 1.8.1 .......................... SUCCESS [ 15.569 s]
[INFO] flink-optimizer 1.8.1 .............................. SUCCESS [ 2.131 s]
[INFO] flink-clients 1.8.1 ................................ SUCCESS [ 2.022 s]
[INFO] flink-streaming-java 1.8.1 ......................... SUCCESS [ 8.685 s]
[INFO] flink-test-utils 1.8.1 ............................. SUCCESS [ 7.446 s]
[INFO] flink-runtime-web 1.8.1 ............................ SUCCESS [ 5.302 s]
[INFO] flink-examples 1.8.1 ............................... SUCCESS [ 0.421 s]
[INFO] flink-examples-batch 1.8.1 ......................... SUCCESS [ 43.929 s]
[INFO] flink-connectors 1.8.1 ............................. SUCCESS [ 0.564 s]
[INFO] flink-hadoop-compatibility 1.8.1 ................... SUCCESS [ 16.530 s]
[INFO] flink-state-backends 1.8.1 ......................... SUCCESS [ 0.823 s]
[INFO] flink-statebackend-rocksdb 1.8.1 ................... SUCCESS [ 3.149 s]
[INFO] flink-tests 1.8.1 .................................. SUCCESS [ 57.885 s]
[INFO] flink-streaming-scala 1.8.1 ........................ SUCCESS [01:15 min]
[INFO] flink-table 1.8.1 .................................. SUCCESS [ 0.781 s]
[INFO] flink-table-common 1.8.1 ........................... SUCCESS [ 0.997 s]
[INFO] flink-table-api-java 1.8.1 ......................... SUCCESS [ 0.406 s]
[INFO] flink-table-api-java-bridge 1.8.1 .................. SUCCESS [ 1.527 s]
[INFO] flink-libraries 1.8.1 .............................. SUCCESS [ 0.542 s]
[INFO] flink-cep 1.8.1 .................................... SUCCESS [ 8.363 s]
[INFO] flink-table-planner 1.8.1 .......................... SUCCESS [04:18 min]
[INFO] flink-orc 1.8.1 .................................... SUCCESS [ 8.790 s]
[INFO] flink-jdbc 1.8.1 ................................... SUCCESS [ 5.401 s]
[INFO] flink-hbase 1.8.1 .................................. SUCCESS [ 45.025 s]
[INFO] flink-hcatalog 1.8.1 ............................... SUCCESS [ 20.901 s]
[INFO] flink-metrics-jmx 1.8.1 ............................ SUCCESS [ 3.721 s]
[INFO] flink-connector-kafka-base 1.8.1 ................... SUCCESS [ 19.666 s]
[INFO] flink-connector-kafka-0.9 1.8.1 .................... SUCCESS [ 7.921 s]
[INFO] flink-connector-kafka-0.10 1.8.1 ................... SUCCESS [ 6.931 s]
[INFO] flink-connector-kafka-0.11 1.8.1 ................... SUCCESS [ 5.260 s]
[INFO] flink-formats 1.8.1 ................................ SUCCESS [ 0.639 s]
[INFO] flink-json 1.8.1 ................................... SUCCESS [ 5.258 s]
[INFO] flink-connector-elasticsearch-base 1.8.1 ........... SUCCESS [ 11.332 s]
[INFO] flink-connector-elasticsearch 1.8.1 ................ SUCCESS [ 50.150 s]
[INFO] flink-connector-elasticsearch2 1.8.1 ............... SUCCESS [ 57.804 s]
[INFO] flink-connector-elasticsearch5 1.8.1 ............... SUCCESS [01:01 min]
[INFO] flink-connector-elasticsearch6 1.8.1 ............... SUCCESS [ 22.513 s]
[INFO] flink-connector-rabbitmq 1.8.1 ..................... SUCCESS [ 1.885 s]
[INFO] flink-connector-twitter 1.8.1 ...................... SUCCESS [ 4.839 s]
[INFO] flink-connector-nifi 1.8.1 ......................... SUCCESS [ 2.129 s]
[INFO] flink-connector-cassandra 1.8.1 .................... SUCCESS [ 16.521 s]
[INFO] flink-avro 1.8.1 ................................... SUCCESS [ 10.093 s]
[INFO] flink-connector-filesystem 1.8.1 ................... SUCCESS [ 6.873 s]
[INFO] flink-connector-kafka 1.8.1 ........................ SUCCESS [ 8.335 s]
[INFO] flink-sql-connector-elasticsearch6 1.8.1 ........... SUCCESS [ 28.862 s]
[INFO] flink-sql-connector-kafka-0.9 1.8.1 ................ SUCCESS [ 2.863 s]
[INFO] flink-sql-connector-kafka-0.10 1.8.1 ............... SUCCESS [ 2.771 s]
[INFO] flink-sql-connector-kafka-0.11 1.8.1 ............... SUCCESS [ 3.670 s]
[INFO] flink-sql-connector-kafka 1.8.1 .................... SUCCESS [ 6.913 s]
[INFO] flink-connector-kafka-0.8 1.8.1 .................... SUCCESS [ 5.247 s]
[INFO] flink-avro-confluent-registry 1.8.1 ................ SUCCESS [ 10.463 s]
[INFO] flink-parquet 1.8.1 ................................ SUCCESS [ 5.704 s]
[INFO] flink-sequence-file 1.8.1 .......................... SUCCESS [ 1.195 s]
[INFO] flink-csv 1.8.1 .................................... SUCCESS [ 5.268 s]
[INFO] flink-examples-streaming 1.8.1 ..................... SUCCESS [ 48.896 s]
[INFO] flink-table-api-scala 1.8.1 ........................ SUCCESS [ 0.343 s]
[INFO] flink-table-api-scala-bridge 1.8.1 ................. SUCCESS [ 1.233 s]
[INFO] flink-examples-table 1.8.1 ......................... SUCCESS [ 47.093 s]
[INFO] flink-examples-build-helper 1.8.1 .................. SUCCESS [ 0.287 s]
[INFO] flink-examples-streaming-twitter 1.8.1 ............. SUCCESS [ 1.148 s]
[INFO] flink-examples-streaming-state-machine 1.8.1 ....... SUCCESS [ 0.889 s]
[INFO] flink-container 1.8.1 .............................. SUCCESS [ 1.882 s]
[INFO] flink-queryable-state-runtime 1.8.1 ................ SUCCESS [ 4.483 s]
[INFO] flink-end-to-end-tests 1.8.1 ....................... SUCCESS [ 0.829 s]
[INFO] flink-cli-test 1.8.1 ............................... SUCCESS [ 1.406 s]
[INFO] flink-parent-child-classloading-test-program 1.8.1 . SUCCESS [ 1.587 s]
[INFO] flink-parent-child-classloading-test-lib-package 1.8.1 SUCCESS [ 1.895 s]
[INFO] flink-dataset-allround-test 1.8.1 .................. SUCCESS [ 0.294 s]
[INFO] flink-datastream-allround-test 1.8.1 ............... SUCCESS [ 5.243 s]
[INFO] flink-stream-sql-test 1.8.1 ........................ SUCCESS [ 4.549 s]
[INFO] flink-bucketing-sink-test 1.8.1 .................... SUCCESS [ 12.400 s]
[INFO] flink-distributed-cache-via-blob 1.8.1 ............. SUCCESS [ 1.512 s]
[INFO] flink-high-parallelism-iterations-test 1.8.1 ....... SUCCESS [ 10.873 s]
[INFO] flink-stream-stateful-job-upgrade-test 1.8.1 ....... SUCCESS [ 5.087 s]
[INFO] flink-queryable-state-test 1.8.1 ................... SUCCESS [ 3.373 s]
[INFO] flink-local-recovery-and-allocation-test 1.8.1 ..... SUCCESS [ 0.536 s]
[INFO] flink-elasticsearch1-test 1.8.1 .................... SUCCESS [ 6.442 s]
[INFO] flink-elasticsearch2-test 1.8.1 .................... SUCCESS [ 5.664 s]
[INFO] flink-elasticsearch5-test 1.8.1 .................... SUCCESS [ 6.762 s]
[INFO] flink-elasticsearch6-test 1.8.1 .................... SUCCESS [ 18.431 s]
[INFO] flink-quickstart 1.8.1 ............................. SUCCESS [ 1.859 s]
[INFO] flink-quickstart-java 1.8.1 ........................ SUCCESS [ 2.254 s]
[INFO] flink-quickstart-scala 1.8.1 ....................... SUCCESS [ 2.254 s]
[INFO] flink-quickstart-test 1.8.1 ........................ SUCCESS [ 0.616 s]
[INFO] flink-confluent-schema-registry 1.8.1 .............. SUCCESS [ 10.980 s]
[INFO] flink-stream-state-ttl-test 1.8.1 .................. SUCCESS [ 20.440 s]
[INFO] flink-sql-client-test 1.8.1 ........................ SUCCESS [ 3.704 s]
[INFO] flink-streaming-file-sink-test 1.8.1 ............... SUCCESS [ 1.489 s]
[INFO] flink-state-evolution-test 1.8.1 ................... SUCCESS [ 3.776 s]
[INFO] flink-e2e-test-utils 1.8.1 ......................... SUCCESS [ 14.975 s]
[INFO] flink-streaming-python 1.8.1 ....................... SUCCESS [ 14.727 s]
[INFO] flink-mesos 1.8.1 .................................. SUCCESS [ 57.098 s]
[INFO] flink-yarn 1.8.1 ................................... SUCCESS [ 4.752 s]
[INFO] flink-gelly 1.8.1 .................................. SUCCESS [ 8.741 s]
[INFO] flink-gelly-scala 1.8.1 ............................ SUCCESS [ 36.059 s]
[INFO] flink-gelly-examples 1.8.1 ......................... SUCCESS [ 27.027 s]
[INFO] flink-metrics-dropwizard 1.8.1 ..................... SUCCESS [ 0.581 s]
[INFO] flink-metrics-graphite 1.8.1 ....................... SUCCESS [ 0.421 s]
[INFO] flink-metrics-influxdb 1.8.1 ....................... SUCCESS [ 2.458 s]
[INFO] flink-metrics-prometheus 1.8.1 ..................... SUCCESS [ 1.203 s]
[INFO] flink-metrics-statsd 1.8.1 ......................... SUCCESS [ 0.516 s]
[INFO] flink-metrics-datadog 1.8.1 ........................ SUCCESS [ 1.316 s]
[INFO] flink-metrics-slf4j 1.8.1 .......................... SUCCESS [ 0.499 s]
[INFO] flink-python 1.8.1 ................................. SUCCESS [ 4.480 s]
[INFO] flink-cep-scala 1.8.1 .............................. SUCCESS [ 48.001 s]
[INFO] flink-ml 1.8.1 ..................................... SUCCESS [01:33 min]
[INFO] flink-ml-uber 1.8.1 ................................ SUCCESS [ 5.972 s]
[INFO] flink-table-uber 1.8.1 ............................. SUCCESS [ 6.276 s]
[INFO] flink-sql-client 1.8.1 ............................. SUCCESS [ 14.243 s]
[INFO] flink-scala-shell 1.8.1 ............................ SUCCESS [01:00 min]
[INFO] flink-dist 1.8.1 ................................... SUCCESS [ 22.946 s]
[INFO] flink-end-to-end-tests-common 1.8.1 ................ SUCCESS [ 1.660 s]
[INFO] flink-metrics-availability-test 1.8.1 .............. SUCCESS [ 0.446 s]
[INFO] flink-metrics-reporter-prometheus-test 1.8.1 ....... SUCCESS [ 0.415 s]
[INFO] flink-heavy-deployment-stress-test 1.8.1 ........... SUCCESS [ 39.937 s]
[INFO] flink-streaming-kafka-test-base 1.8.1 .............. SUCCESS [ 1.775 s]
[INFO] flink-streaming-kafka-test 1.8.1 ................... SUCCESS [ 33.772 s]
[INFO] flink-streaming-kafka011-test 1.8.1 ................ SUCCESS [ 26.880 s]
[INFO] flink-streaming-kafka010-test 1.8.1 ................ SUCCESS [ 27.664 s]
[INFO] flink-contrib 1.8.1 ................................ SUCCESS [ 0.619 s]
[INFO] flink-connector-wikiedits 1.8.1 .................... SUCCESS [ 1.773 s]
[INFO] flink-yarn-tests 1.8.1 ............................. SUCCESS [01:13 min]
[INFO] flink-fs-tests 1.8.1 ............................... SUCCESS [ 3.835 s]
[INFO] flink-docs 1.8.1 ................................... SUCCESS [ 1.896 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 13:18 min (Wall Clock)
[INFO] Finished at: 2019-07-28T11:13:20+08:00
[INFO] ------------------------------------------------------------------------
2.7.2 编译成功后目录如下
Su-yuexi:~ yoreyuan$# ls -l
total 832
lrwxrwxrwx 1 root root 61 Jul 28 11:04 build-target -> /opt/flink/flink-dist/target/flink-1.8.1-bin/flink-1.8.1
drwxr-xr-x 18 root root 4096 Jul 28 10:16 docs
drwxr-xr-x 4 root root 4096 Jul 28 10:54 flink-annotations
drwxr-xr-x 4 root root 4096 Jul 28 10:57 flink-clients
drwxr-xr-x 30 root root 4096 Jul 28 10:54 flink-connectors
drwxr-xr-x 6 root root 4096 Jul 28 10:58 flink-container
drwxr-xr-x 5 root root 4096 Jul 28 10:54 flink-contrib
drwxr-xr-x 4 root root 4096 Jul 28 10:54 flink-core
drwxr-xr-x 4 root root 4096 Jul 28 11:04 flink-dist
drwxr-xr-x 4 root root 4096 Jul 28 10:58 flink-docs
drwxr-xr-x 36 root root 4096 Jul 28 10:54 flink-end-to-end-tests
drwxr-xr-x 7 root root 4096 Jul 28 10:55 flink-examples
drwxr-xr-x 11 root root 4096 Jul 28 10:54 flink-filesystems
drwxr-xr-x 9 root root 4096 Jul 28 10:54 flink-formats
drwxr-xr-x 4 root root 4096 Jul 28 11:03 flink-fs-tests
drwxr-xr-x 4 root root 4096 Jul 28 10:55 flink-java
drwxr-xr-x 6 root root 4096 Jul 28 10:16 flink-jepsen
drwxr-xr-x 12 root root 4096 Jul 28 10:54 flink-libraries
drwxr-xr-x 4 root root 4096 Jul 28 10:58 flink-mesos
drwxr-xr-x 12 root root 4096 Jul 28 10:54 flink-metrics
drwxr-xr-x 4 root root 4096 Jul 28 10:57 flink-optimizer
drwxr-xr-x 5 root root 4096 Jul 28 10:54 flink-queryable-state
drwxr-xr-x 5 root root 4096 Jul 28 10:54 flink-quickstart
drwxr-xr-x 4 root root 4096 Jul 28 10:55 flink-runtime
drwxr-xr-x 5 root root 4096 Jul 28 10:58 flink-runtime-web
drwxr-xr-x 4 root root 4096 Jul 28 10:57 flink-scala
drwxr-xr-x 5 root root 4096 Jul 28 11:03 flink-scala-shell
drwxr-xr-x 4 root root 4096 Jul 28 10:54 flink-shaded-curator
drwxr-xr-x 6 root root 4096 Jul 28 10:54 flink-shaded-hadoop
drwxr-xr-x 4 root root 4096 Jul 28 10:54 flink-state-backends
drwxr-xr-x 4 root root 4096 Jul 28 10:57 flink-streaming-java
drwxr-xr-x 4 root root 4096 Jul 28 10:59 flink-streaming-scala
drwxr-xr-x 11 root root 4096 Jul 28 10:54 flink-table
drwxr-xr-x 4 root root 4096 Jul 28 10:59 flink-tests
drwxr-xr-x 5 root root 4096 Jul 28 10:54 flink-test-utils-parent
drwxr-xr-x 4 root root 4096 Jul 28 10:58 flink-yarn
drwxr-xr-x 4 root root 4096 Jul 28 11:04 flink-yarn-tests
-rw-r--r-- 1 root root 11357 Jul 28 09:57 LICENSE
drwxr-xr-x 2 root root 4096 Jul 28 10:16 licenses
drwxr-xr-x 2 root root 4096 Jul 28 10:16 licenses-binary
-rw-r--r-- 1 root root 2165 Jul 28 09:57 NOTICE
-rw-r--r-- 1 root root 596009 Jul 28 10:16 NOTICE-binary
-rw-r--r-- 1 root root 59071 Jul 28 10:16 pom.xml
-rw-r--r-- 1 root root 4531 Jul 28 10:16 README.md
drwxr-xr-x 3 root root 4096 Jul 28 10:54 target
drwxr-xr-x 6 root root 4096 Jul 28 10:16 tools
2.7.3 Flink的发行包
由上面我们可以看到build-target软连指向的就是我们的部署文件,因为在编译的时候我们已经将Hadoop编译到这个部署文件中了,所以这里直接将编译后的发行包cp或者scp到安装节点即可。
# 以软连接方式创建到安装目录
cp -r build-target ../opt/flink-1.8.1
# 或者,拷贝源分发文件到安装目录
cp -r /opt/flink/flink-dist/target/flink-1.8.1-bin/flink-1.8.1 /opt/flink-1.8.1
# 或者,scp到安装目录
scp -r /opt/flink/flink-dist/target/flink-1.8.1-bin/flink-1.8.1 root@chd3:/opt/flink-1.8.1
2.8 配置环境变量
vim ~/.bash_profile
添加如下配置,保存并退出,并生效. ~/.bash_profile
# Flink
export FLINK_HOME=/opt/flink-1.8.1
export PATH=$PATH:$FLINK_HOME/bin
2.9 standalone模式启动

2.9.1 启动
$FLINK_HOME/bin/start-cluster.sh
2.9.2 访问Flink UI
浏览器访问页面 http://localhost:8081/#/overview
2.9.3 测试
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/batch/WordCount.jar
2.9.4 停止
$FLINK_HOME/bin/stop-cluster.sh
2.10 YARN模式
YARN模式有两种方式:
- yarn-session:在yarn中初始化一个flink集群(共享集群),开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
- Per-Job 模式(推荐):目前只有 YARN 上实现了 Per-Job模式,Flink Job 与 YARN Application 生命周期绑定。每次提交都会创建一个新的flink集群,作业之间相互隔离(1 个作业对应一个 集群),互不影响,方便管理。任务执行完成之后创建的集群也会消失。优点是既充分利用了 YARN 的隔离性,又使资源高效的利用。
往 YARN 上提交应用,需要提交 Flink 任务的节点 有HADOOP 的一些环境变量,在flink 1.10 及后面的最新版本也是支持 Hadoop 3.x ,通过环境变量的引用可以避免 Flink 集成的 Hadoop 与环境的 Hadoop 冲突问题。on yarn 方式提交依赖于 YARN ,而不依赖于本地的 Flink 集群,如果提交flink 任务的节点没有 Hadoop 环境,可以将对应的包 和配置拷贝到这个节点,加入到环境变量中即可
HADOOP_HOME=/opt/module/hadoop-3.x.y
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
2.10.1 yarn-session模式
总体上可分为三个阶段
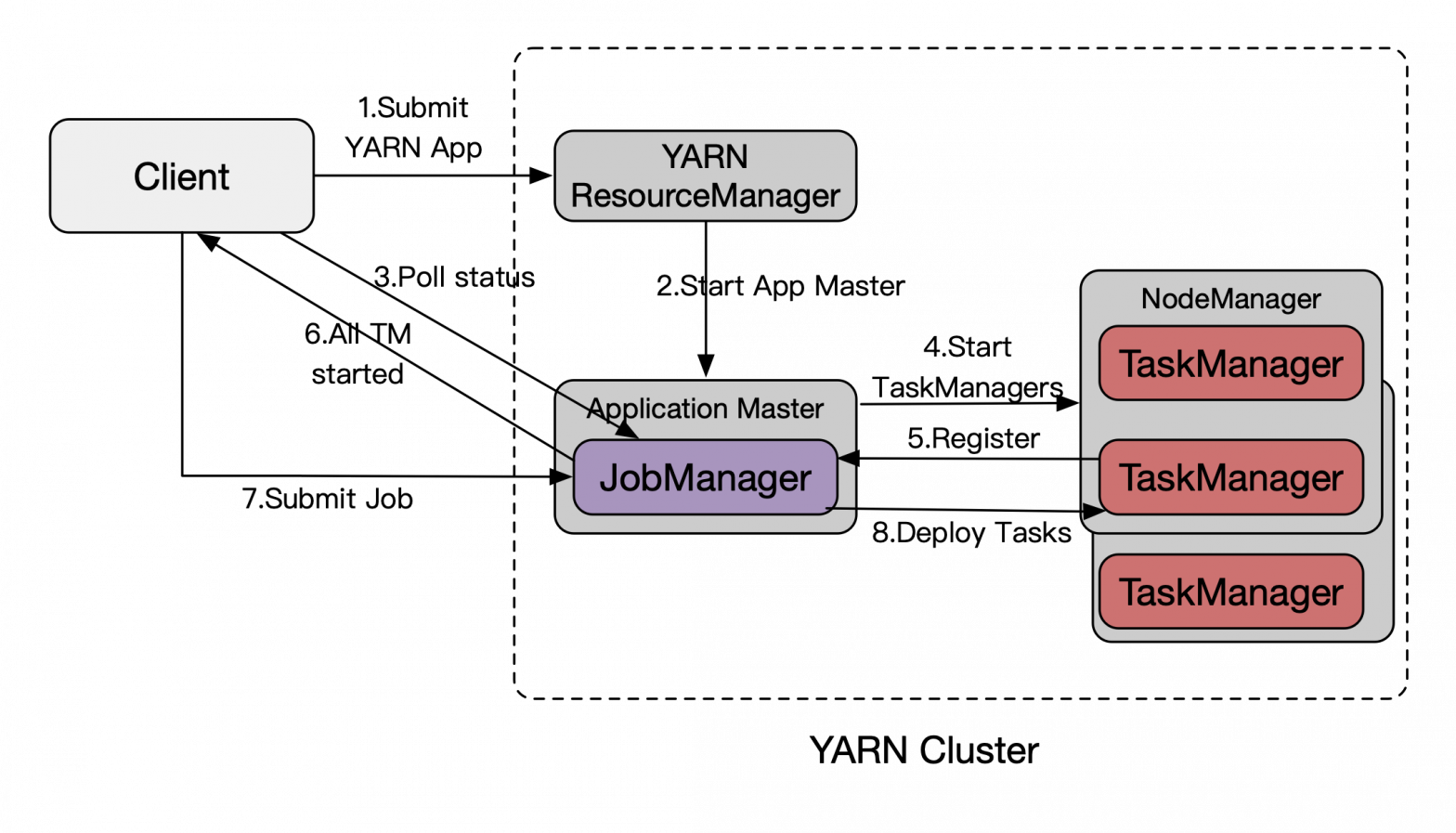
- 在 YARN 上启动 Flink Session 模式集群。如果集群已存在,则获取 YARN 集群信息、应用 ID,准备提交作业。如果集群不存在,则启动新的 yarn session 集群。
- 通过 Flink Client 提交作业。通过 Rest 向 Dispatcher 提交 JobGraph。
- 进行作业调度。
2.10.1.1 启动
这种模式不需要单独启动 Flink 集群,而是通过在YARN上申请Flink 集群资源启动:
# 查看参数的说明
$FLINK_HOME/bin/yarn-session.sh --help
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the application on YARN
-D <property=value> ▊使用给定的配置项值
-d,--detached ▊如果指定,则以分离模式运行,也就是不再与控制台保持连接
-h,--help ▊查看 Yarn session CLI 的帮助.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> ▊Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> ▊为 YARN 上的应用设置一个名字(Application-Name)
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> ▊ 指定每个 TaskManager 的 slots 数
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
# 申请资源,且指定,TaskManager 和 JobManager 内存大小
# 启动成功后控制台会打印出 Flink Web UI 地址,及 YARN 上的 application id
$FLINK_HOME/bin/yarn-session.sh -nm demo01 -jm 1024 -tm 2000
2.10.1.2 访问Flink UI
直接访问控制台输出的 Flink Web UI 地址 地址。或者访问YARN页面,然后在 Tracking UI列,可以看到启动了ApplicationMaster,点击可以看到访问 Flink UI
2.10.1.3 测试
# 方式 1:使用 Flink 示例程序内部测试数据集
# 通过打印的日志,可以看到其发下了已存在的集群,并获取到 yarn application id。
# 接着提交了 Job,并输出 JobID。经过调度执行,最终结果打印在了控制台。
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/batch/WordCount.jar
# 方式 2:使用自己的 HDFS 上的数据
#现在一份测试数据
wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt
#上传到HDFS
hadoop fs -mkdir hdfs://cdh1:8020/home/flink
hadoop fs -copyFromLocal LICENSE-2.0.txt hdfs:///home/flink
# Wordcount。在极少数问题的情况下,您还可以使用-m参数传递JobManager地址。JobManager地址在YARN控制台中可见。
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/batch/WordCount.jar --input hdfs:///home/flink/LICENSE-2.0.txt --output hdfs:///home/flink/wordcount-result.txt
# 查看执行的部分结果数据
hadoop fs -tail hdfs:///home/flink/wordcount-result.txt
提交之后可以在YARN的ApplicationMaster打开的Flink UI连接看到运行的job状态,同时在hdfs:///home/flink/wordcount-result.txt可以看到运行的结果
2.10.1.4 关闭
如果关闭,可以使用YARN命令:
# 查看YARN上运行的Application
yarn application -list
#yarn app -list
# 关闭
yarn application -kill ${Application-Id}
2.10.2 Per-Job模式
从图上看也是主要分为:
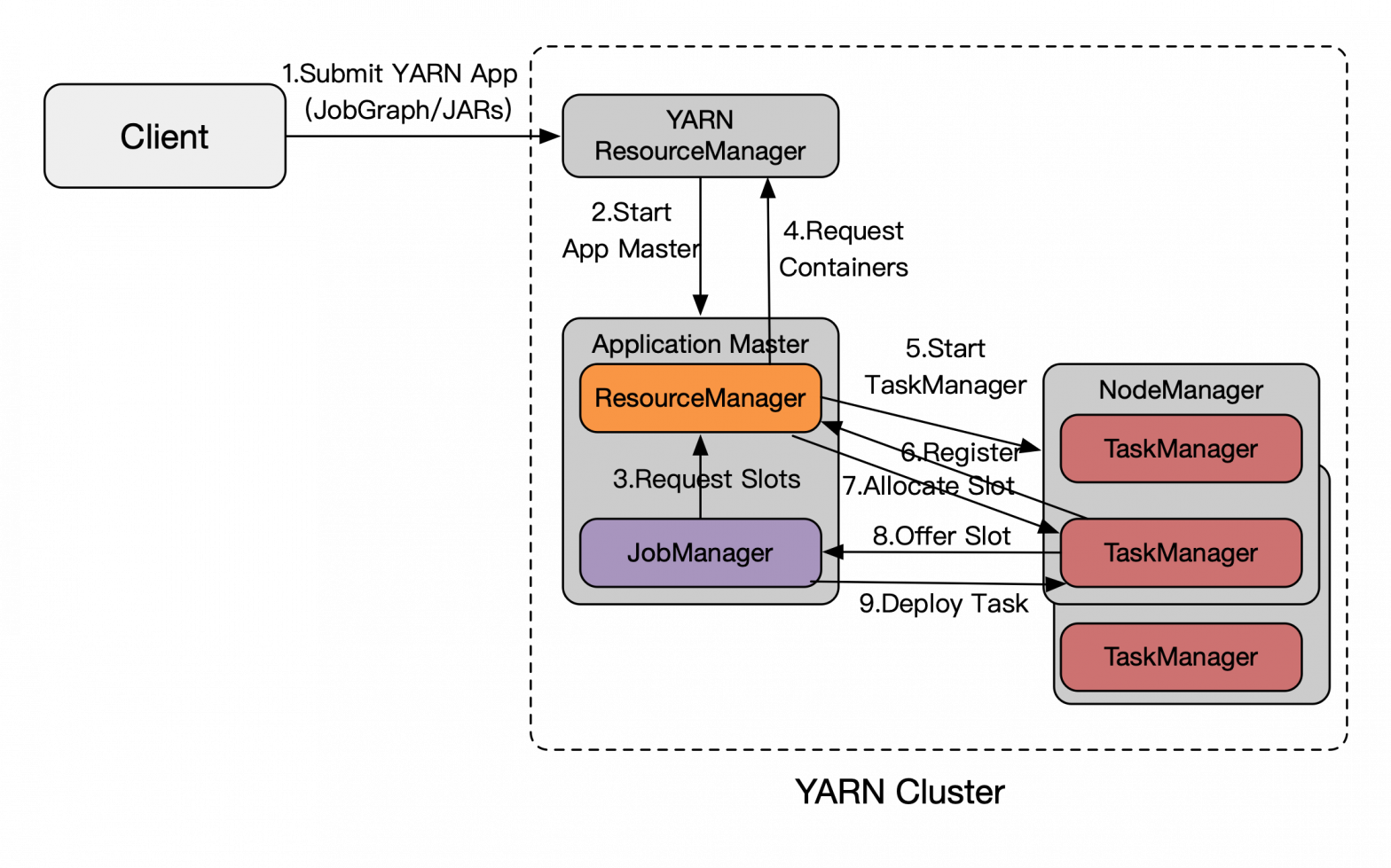
- 启动集群。Flink 集群的入口是 YarnJobClusterEntryPoint。
- 作业提交。通过 Dispatcher 从本地文件系统获取 JobGraph。
- 作业调度执行。作业调度部分与 yarn session 模式一致。
2.10.2.1 启动并运行Job
# 1 查看提交命令帮助
$FLINK_HOME/bin/flink run -m yarn-cluster --help
# 2 执行
$FLINK_HOME/bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
# 还可以指定参数:
# -p 并行度
# -c 程序入口的全限定名(可选,如果 jar 包 META-INF/MANIFEST.MF 包含了主类入口可省略)
# -ys TaskManager 的 slots 数
# -yjm 可选项的 JobManager Container 内存大小(default: MB)
# -ytm Memory per TaskManager Container with optional unit (default: MB)
# -ynm 设置 YARN 上应用的自定义名称
$FLINK_HOME/bin/flink run -m yarn-cluster \
-p 4 -ys 2 \
-yjm 1024 -ytm 2000 -ynm WordCount \
-c org.apache.flink.examples.java.wordcount.WordCount examples/batch/WordCount.jar
2.10.2.2 访问状态信息
这一步要快,提交之后可以在YARN的ApplicationMaster打开Flink UI,可以看到运行的job状态。当这个Job运行完毕之后,会马上释放资源,YARN页面上可以看到提交的Application已经FINISHED,Flink UI页面也会自动关闭。
2.11 Blink
将通过 2.6.3 步骤编译的发行包按照前面 Flink 方式配置和安装,注意端口,避免冲突。我这里修改了rest.port: 9081。运行一个
$BLINK_HOME/bin/flink run $BLINK_HOME/examples/batch/WordCount.jar
控制台会打印出结果,访问Flink UI如下图:
同样也可以yarn-session模式启动:
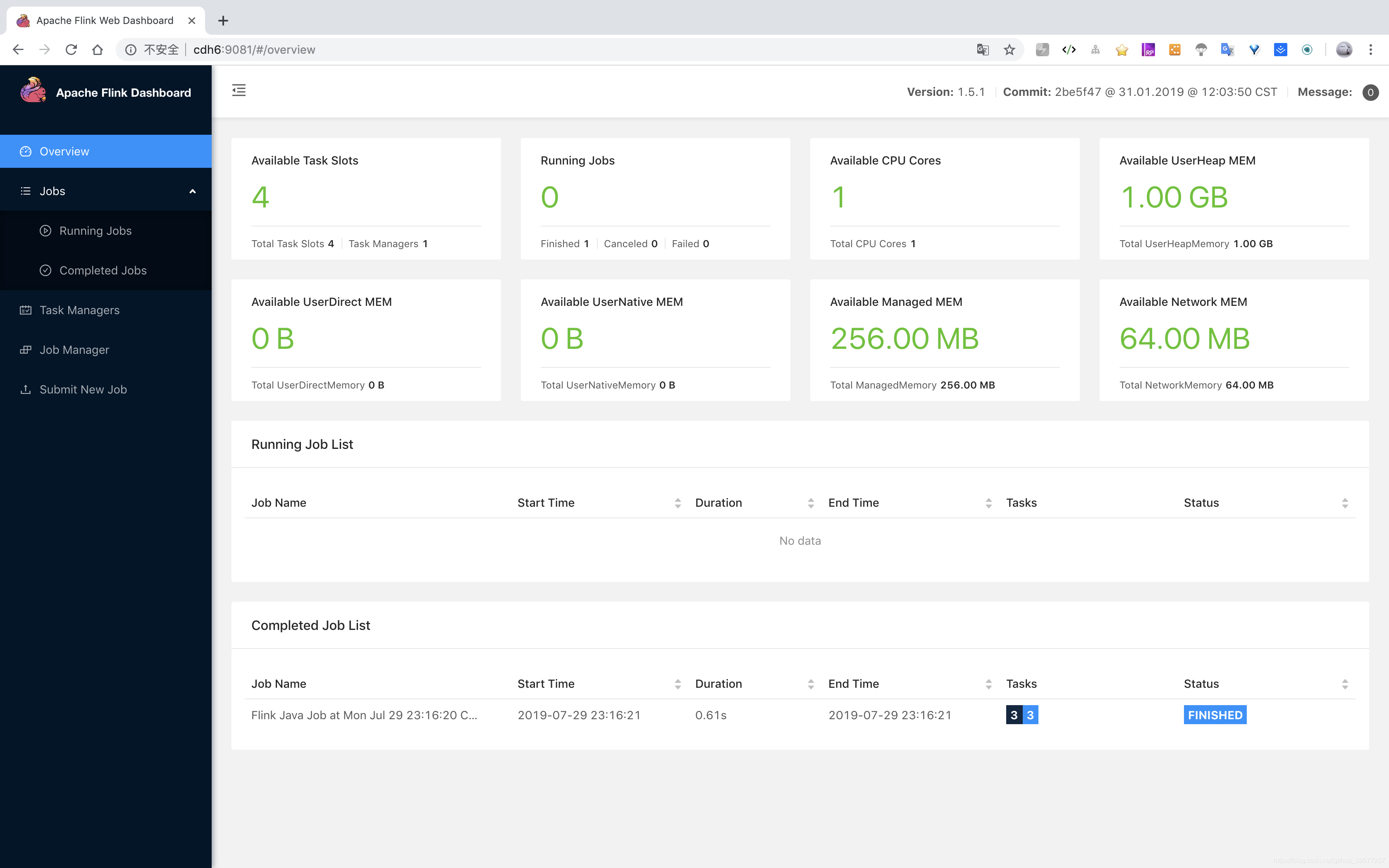
$BLINK_HOME/bin/yarn-session.sh -jm 1024 -tm 4096
#提交Wordcount
$BLINK_HOME/bin/flink run $BLINK_HOME/examples/batch/WordCount.jar --input hdfs:///home/flink/LICENSE-2.0.txt --output hdfs:///home/flink/wordcount-result2.txt
yarn-cluster模式提交Job
$BLINK_HOME/bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar