【CVPR2024】Few-Shot Object Detection with Foundation Models
机构:哥伦比亚大学、中佛罗里达大学
作者简介:Ser-Nam Lim,马里兰大学帕克分校博士学位,2018年-2023年在Meta(前身Facebook)参与计算机视觉、NLP和其他AI领域的研究,研究内容主要是确保航空和电力行业的安全、检测Meta平台上的错误信息,最近专注于AI用于对用户内容的推荐,包括大语言模型(LLM)和计算机视觉交叉点的搜索引擎,2023年秋季加入中佛罗里达大学。代表工作为Visual prompt tuning。
本文主要目的是提高小样本目标检测的精度,用DINOv2预训练的模型作为视觉backbone,使用大语言模型(LLM)来对类别、查询图像这两种输入信息进行上下文小样本学习。使用精心设计的语言指令提示LLM来为每个候选区(proposal)进行分类,所使用的上下文信息包括proposal-proposal关系、proposal-class关系、class-class关系。所提出的FM-FSOD方法在多个FSOD基准数据集上取得了SOTA性能。
文章贡献/创新点
- 文章研究基于基础模型的小样本目标检测,重点关注视觉特征提取和上下文proposal分类。
- 文章使用了基于DINOv2的全Transformer检测框架实现对大量样本和小样本类别的高泛化性。
- 使用大语言模型简化query和support之间的建模,自动学习丰富的上下文信息。
- 在PASCAL VOC和MSCOCO小样本评测基准上取得了SOTA性能。
小样本目标检测(FSOD)任务定义
FSOD任务有基类 C b a s e C_{base} Cbase和新类 C n o v e l C_{novel} Cnovel两种类别, C = C b a s e ∪ C n o v e l C=C_{base}\cup C_{novel} C=Cbase∪Cnovel并且 C b a s e ∩ C n o v e l = ∅ C_{base}\cap C_{novel}=\emptyset Cbase∩Cnovel=∅,基类有足够多的样本而新类只有少量样本。对于 K K K-shot小样本任务,数据集中的每个新类只有 K K K个检测框标注,通常 K = 1 , 3 , 5 , 10 , 30 K=1,3,5,10,30 K=1,3,5,10,30。
模型结构
模型采用元学习的训练架构,每次训练时会同时向网络输入单个query图片和多个support图片(包含 N N N个类别,每个类别 K K K个检测框标注,即 N N N-way- K K K-shot设置)。模型包含三个子模块,其中视觉特征提取器用于提取query和support的视觉特征,候选框生成器用于从query图片中生成支撑类别感知的proposal,小样本候选框分类基于原型信息来为每个proposal进行分类。
- 支撑类别感知:常规的检测直接提取query图片特征,基于提取的特征进行分类和检测。小样本学习会分别提取query和support图片的特征,并对这两种特征进行交互,得到support类别感知的query特征,将增强后的query特征进行分类和检测。
- 原型:相同类别的目标特征的平均,可以看作某个类别的全局特征。
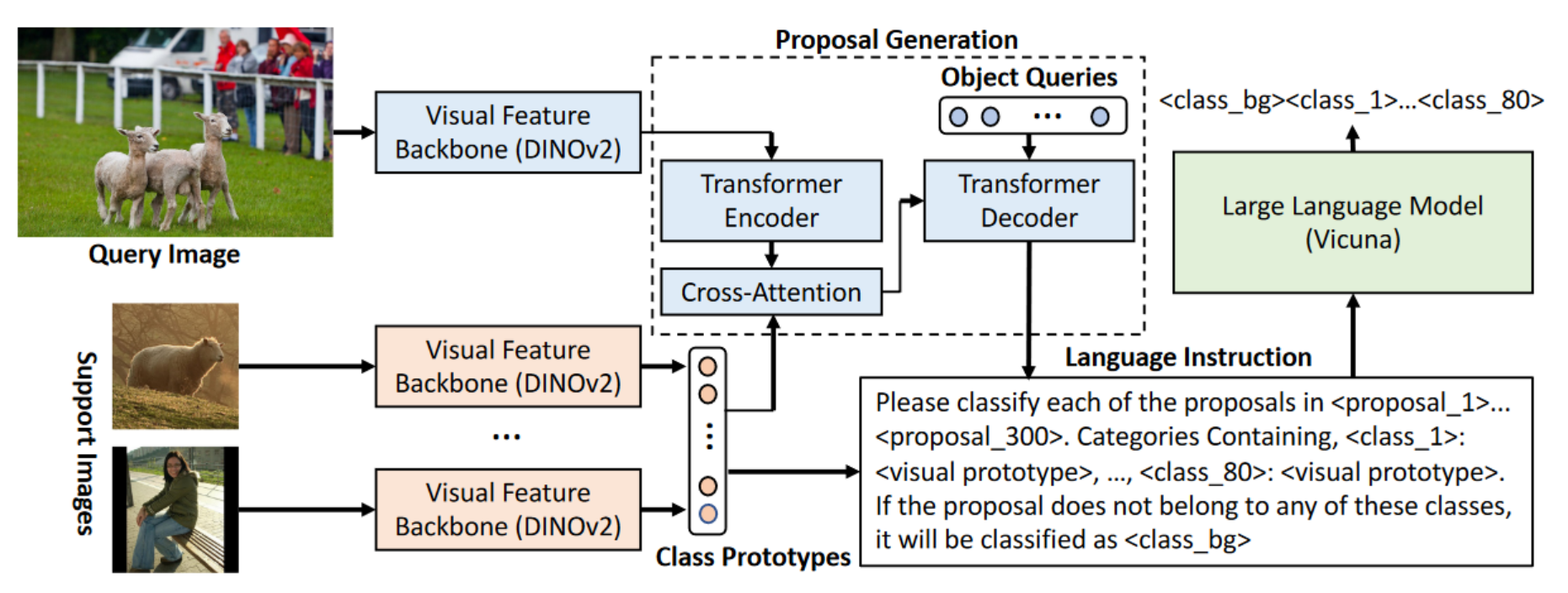
视觉特征提取器
特征提取器是DINOv2预训练得到的ViT,对于query图片 I q ∈ R H I q ∗ W I q ∗ 3 I_q\in\mathbb R^{H_{I_q}*W_{I_q}*3} Iq∈RHIq∗WIq∗3和相应的 N N N-way- K K K-shot支撑图片 { { I S j , i } i = 1 K } j = 1 N \left\{\{I_S^{j,i}\}_{i=1}^K\right\}_{j=1}^N {{ISj,i}i=1K}j=1N,分别提取特征表示 f q = F ( I q ) f_q=\mathcal F(I_q) fq=F(Iq)和 f S j , i = F ( I S j , i ) f_S^{j,i}=\mathcal F(I_S^{j,i}) fSj,i=F(ISj,i)。
其中支撑集图片特征是为了进一步构建类别原型,因此需要图片中的目标的类别信息和目标对应的特征。目标的类别信息来自真值标注,目标特征使用RoIAlign根据检测框位置标注从 f S j , i f_S^{j,i} fSj,i中切割下来 f ‾ S j , i = R o I A l i g n ( f S j , i , b o x S j , i ) \overline{f}_S^{j,i}=RoIAlign(f_S^{j,i},box_S^{j,i}) fSj,i=RoIAlign(fSj,i,boxSj,i)。最后得到 N N N个类别,每个类别 K K K个特征。将相同类别的特征求平均,得到 N N N个类别原型 { f ^ S j = ∑ i = 1 K f ‾ S j , i K } j = 1 N \{\hat{f}_S^j=\frac{\sum_{i=1}^K\overline{f}_S^{j,i}}{K}\}_{j=1}^N {f^Sj=K∑i=1KfSj,i}j=1N。
FSOD任务中,类别信息和特征都是针对具体的物体而不是整张图片。如果支撑图片存在多个物体,在输入网络时仅会保留单个标注用于RoIAlign提取特征。
文章选择DINOv2训练的backbone,主要有两个原因:
- DINOv2是仅针对视觉的自监督学习模型,包括全局图像级和局部patch级的两种监督。patch监督会让模型对定位敏感,有助于下游任务。
- DINOv2在大规模数据集上预训练,文章发现微调没有提升性能,因此冻结了全部参数。
这里存在一个问题是,有可能DINOv2在预训练时就已经见过了某些小样本数据,文章对此的解释是,即便DINOv2见过某些小样本数据,将知识从预训练迁移到下游任务也是比较有挑战的。
候选框生成
文章先使用DINOv2提取得到query图片的patch token,将这些特征输入Deformable Transformer Encoder,得到增强后的图片特征。作者计算它与DINOv2提取的类别原型 { f ^ S j } j = 1 N \{\hat{f}_S^j\}_{j=1}^N {f^Sj}j=1N之间的交叉注意力,得到增强后的图片特征。解码器阶段首先生成初始的物体query Q = { q i } i = 1 M Q=\{q_i\}_{i=1}^M Q={qi}i=1M,然后将其送入Transformer Decoder。Deocder每一层都会计算 Q Q Q之间的自注意力、 Q Q Q和图像特征之间的交叉注意力。经过Decoder之后,每个query会通过简单的线性层预测Bounding box坐标,其中query的数量 M = 300 M=300 M=300。
这里其实就是常规的Deformable DETR做法,只是作者在Encoder阶段增加了图像特征与类别原型之间的交叉注意力,可能是参考了MetaDETR。
小样本候选框分类
上面为每个query预测了bounding box坐标,但没有预测其分类结果。在分类过程上,传统的小样本学习方法是通过设计度量网络来度量proposal和支撑类别之间的相似性,将proposal分类成支撑类别中的某一类或“空”类别。
本文直接提出用大语言模型(LLM)来进行分类。首先为LLM tokenizer增加类别token(<class_1>到<class_80>)和背景类别token(<class_bg>),然后设计了下面语言指令送入大语言模型。
Please classify each of the proposals in <proposal 1>...<proposal 300>.
Categories Containing, <class 1>: <visual prototype>... <class 80>: <visual prototype>.
If the proposal does not belong to any of these classes, it will be classified as <class bg>.
其中的<proposal_l>替换为DETR提取出的proposal特征,<visual prototype>替换为DINOv2提取的类别原型。这两种特征在送入LLM之前需要使用单独的单层线性层将维度对齐。文章使用Vicuna作为大语言模型,根据上述指令会生成每个proposal相应的<class_id>token,在解码生成的token后,将其与候选框生成部分的预测结果融合,就可以得到最终的检测输出。
训练框架
模型训练分为三个阶段:
- 第一阶段在基类上预训练DINOv2作为backbone的Deformable DETR和,即候选框生成模块。
- 第二阶段,在基类上训练整个模型,其中Deformable DETR和DINOv2用第一阶段的权重进行初始化,LLM用Vicuna模型初始化。模型的损失有两部分,一部分是常规的Deformable DETR回归损失,另一部分是大语言模型的损失。本文首先用二分图匹配将label和proposal进行匹配,将匹配上的label作为proposal的真值。得到真值后,用next-token预测损失去训练大语言模型。
- 第三阶段,在新类上微调模型。文章首先在平衡数据集上(下采样的基类+新类)微调候选区域生成模块(与第一阶段相同),然后用平衡数据集(基类+上采样的新类)去微调LLM(与第二阶段相同)。
新类只有少量数据,而训练大语言模型需要大量样本,因此需要对新类数据进行上采样,扩充其数据量,再和基类组成平衡数据集。上采样方式参考下面论文:
[1] Jiawei Ma, Yulei Niu, Jincheng Xu, Shiyuan Huang, Guangxing Han, and Shih-Fu Chang. Digeo: Discriminative geometry-aware learning for generalized few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 32083218, 2023. 5, 6, 7
实验结果
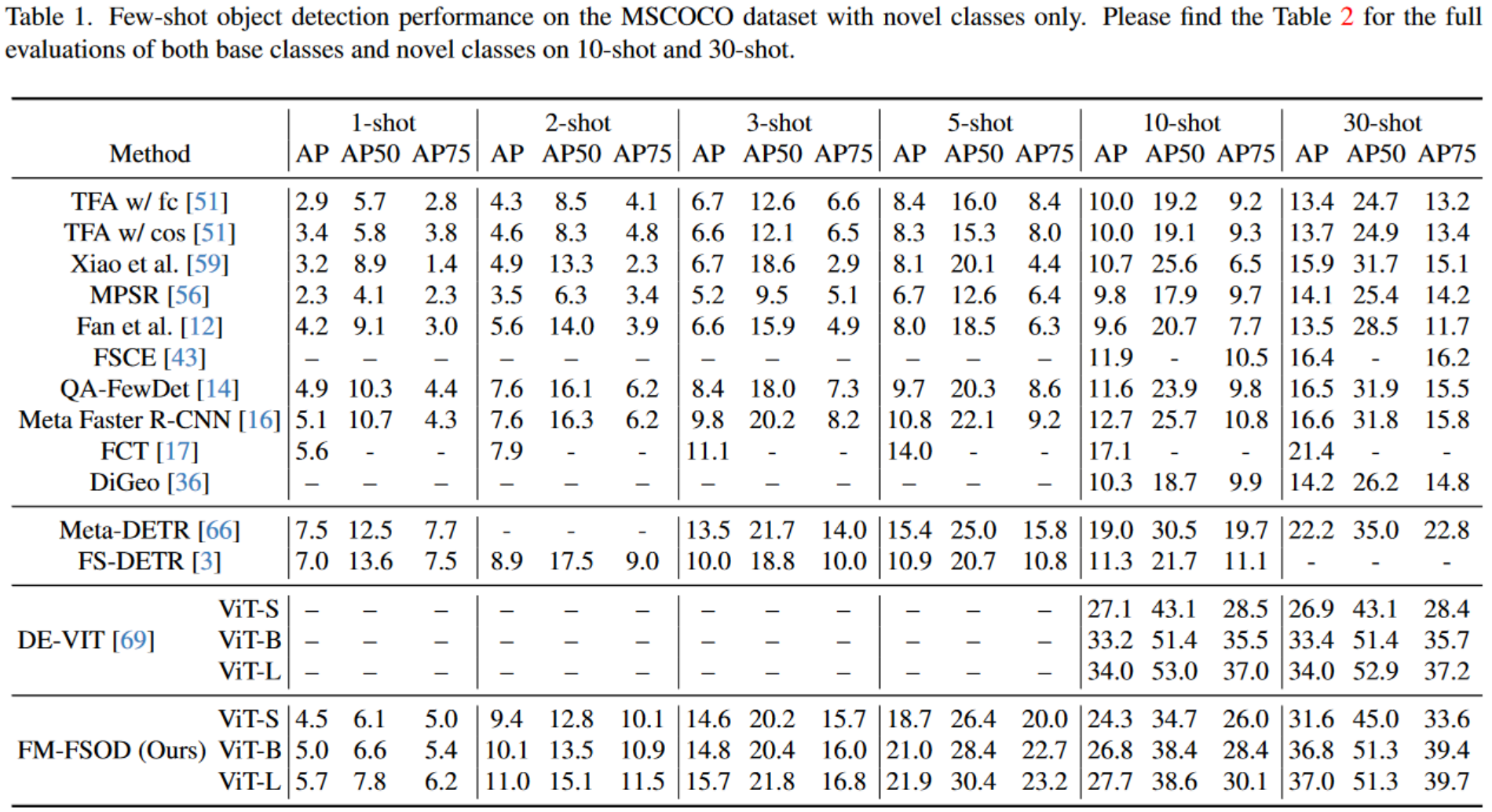
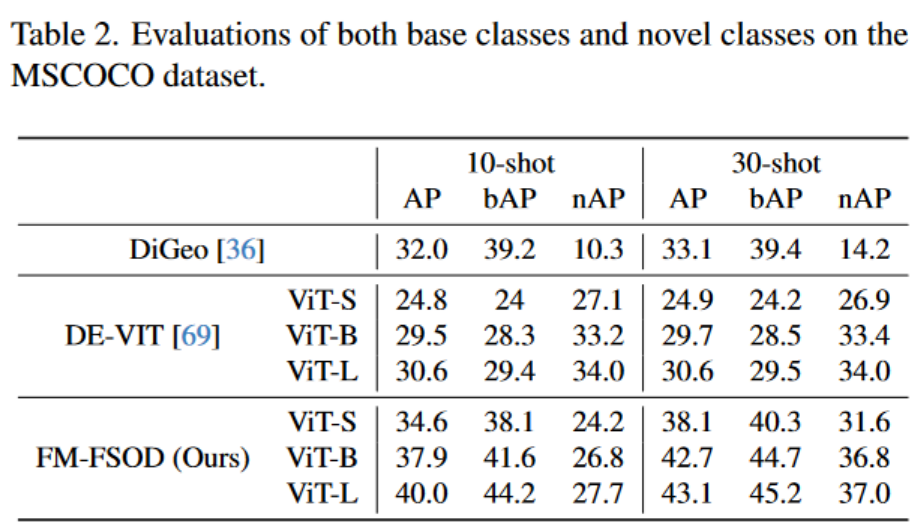
FM-FSOD在COCO数据集上测试了两种设置:FSOD和GFSOD。FSOD指仅评测新类上的mAP,GFSOD既评测新类与基类的综合mAP,后者更能强调综合性能。
在FSOD设置下,FM-FSOD在10-shot上性能略低于DE-VIT,在30-shot上性能高于DE-VIT。
在GFSOD设置下,FM-FSOD性能高于DE-VIT。
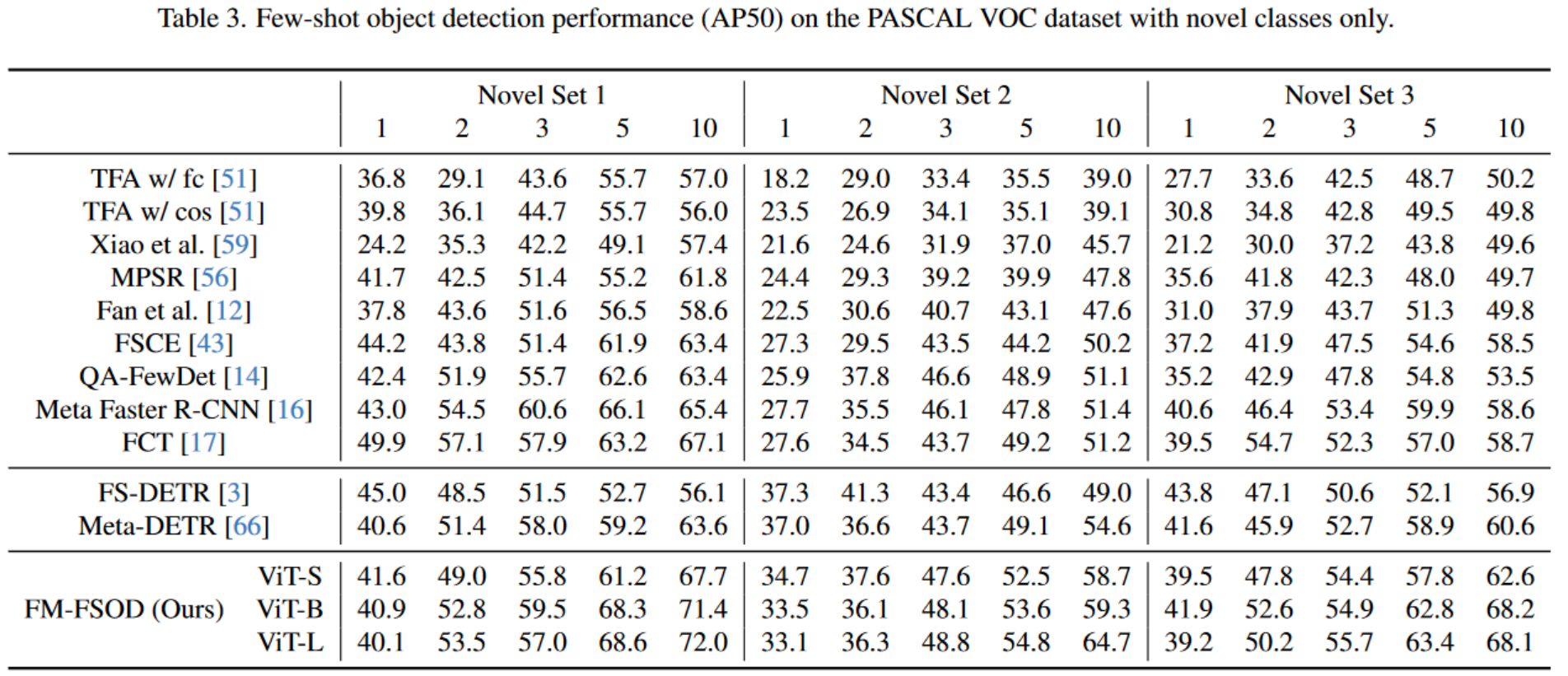
VOC数据集上FM-FSOD并没有和DE-VIT对比,从和其他方法的对比结果来看,FM-FSOD在 K K K较大时性能提升更多,在 K K K交小时比Meta-DETR性能差。可能时由于LLM需要较多的训练样本有关,仅通过上采样新类样本并不能充分满足LLM训练的需求。