CrowdHuman数据集是旷世发布的用于行人检测的数据集,图片数据大多来自于google搜索。
CrowdHuman 数据集数据量比较大,训练集15000张,测试集5000张,验证集4370张。训练集和验证集中共有 470K 个实例,约每张图片包含23个人,同时存在各种各样的遮挡。每个人类实例都用头部边界框、人类可见区域边界框和人体全身边界框注释。
数据集可以在 http://www.crowdhuman.org/ 进行下载,其中测试数据集没有公开标注。

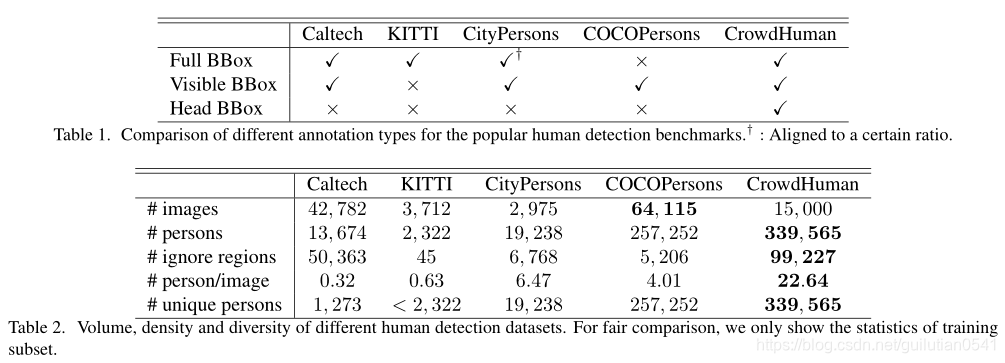
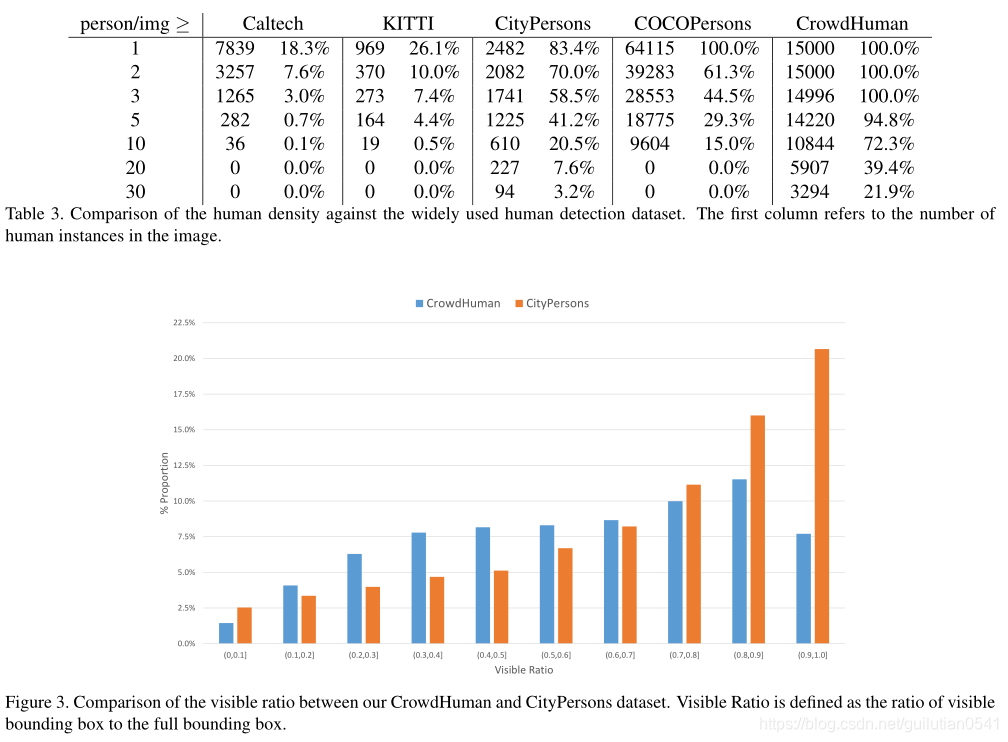
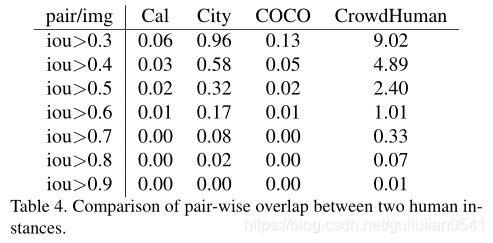
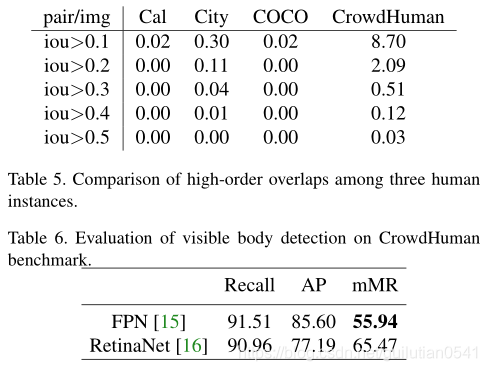
图3比较CrowdHuman和CityPersons数据集之间的可见比率。可见比率定义为可见边界框与完整边界框的比。
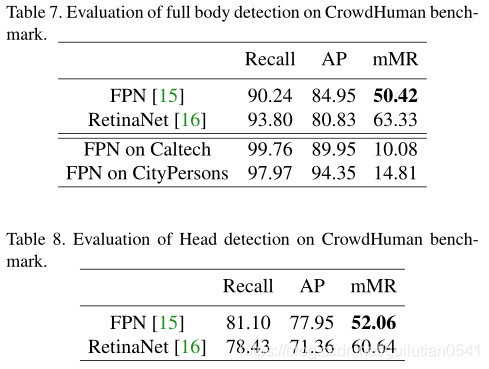
文章的第4部分对该数据集进行了实验,baseline是faster rcnn和retinanet(backbone都是resnet50)表6展示了 visible body detection的结果,表7和表8展示了 full body detection 和Head detection的结果。
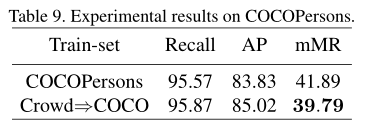
表9展示了COCOperson的结果和使用CrowdHuman数据集进行pretrain,然后使用COCOperson进行funtuning的结果。COCOperson数据集是coco数据集忽略其他79类目标的数据集,只关注person类别。对比发现,该数据集可以用来对模型做预训练。