
作者 | Vanessa Volz、Jacob Schrum、Jialin Liu、 Simon M. Lucas、Adam Smith、Sebastian Risi
译者 |林椿眄
编辑 | Jane
出品 | 人工智能头条(公众号ID:AI_Thinker)
【导读】PCG —— 程序内容生成,通过算法创建游戏内容,例如游戏规则,关卡,角色,背景故事,纹理和声音。近年来国际会议组织了各种比赛,例如马里奥AI级别生成比赛,Platformer AI比赛,AI鸟类等级生成比赛和一般视频游戏AI(GVGAI)等级生成比赛 。今天为大家介绍一项关于 PCGML 的最新研究(PCG 通过机器学习的例子),这篇论文也被 GECCO 2018 提名为 Best Paper Award ,这也是一个新兴的研究领域。
研究中以无监督学习方式训练生成对抗网络(近期关于无监督学习与GAN的内容我们也给大家介绍了不少),模型根据视频游戏级语料库中的实际游戏级别进行训练。并引入了隐变量进化(LVE)的概念;为了在这个潜在空间内找到最佳水平段,进化算法协方差矩阵自适应进化策略(CMA-ES)用于找到产生水平段的潜在向量,由此产生的系统有助于发现人类专家创建的示例空间中的新级别。

▌摘要
生成性对抗网络(GAN) 是能够在给定的训练样本空间内生成新的样本输出的一种机器学习方法。视频游戏中的程序内容生成(PCG) 可以从这种模型中受益,特别是对于那些预先存有语料信息的游戏。本文,我们利用视频游戏语料库,训练一个GAN 模型为超级马里奥兄弟生成游戏级别(Super Mario Bros)。
我们的方法不仅能够成功地生成与原始视频语料库中级别相当的各种游戏,还能通过应用协方差矩阵自适应进化策略(CMA-ES) 进一步改进游戏级别。具体地说,我们使用各种适应度函数(fitness function) 来探索GAN 模型潜在空间水平,以最大化期望属性,而诸如tile 类型分布的静态属性都能够被进一步优化。此外,我们使用2009版Mario AI比赛的冠军A* 智能体,用于评估游戏级别的可玩性,以及需要多少跳跃动作来击败它。这些适应度函数允许模型在专家设计的样本空间中探索各种游戏级别,并指导进化朝着满足一个或多个指定目标水平的方向。
▌方法
我们的方法分为两个主要阶段,如下图1所示。
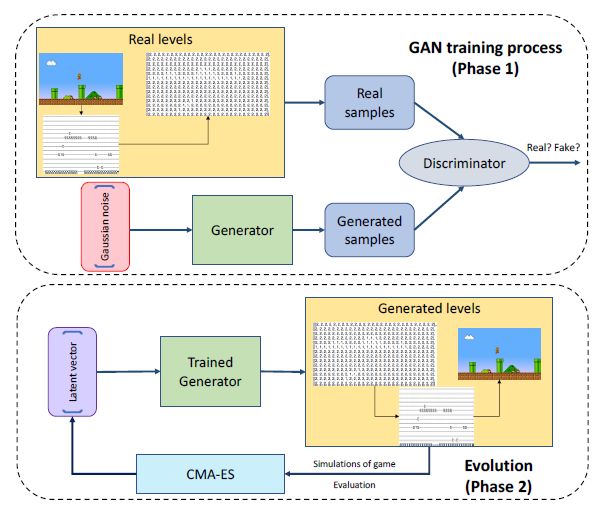
图1 GAN 训练流程及隐向量进化概述。我们的方法可以分为两个截然的阶段。在第一阶段中,GAN 以无监督学习的方式进行训练并生成马里奥游戏水平。在第二阶段,我们搜索潜在向量空间产生具有特定属性的游戏级别。
首先,GAN 在现有的Mario 级别上进行训练(下图2所示)。该级别将被编码为多维数组,并在黄色框中描绘。模型中生成器(用绿色表示) 输入的是高斯噪声向量(用红色表示),并以相同表征水平输出。而判别器用于区分现有级别和生成级别之间的差异性。我们使用对抗性学习的原则来训练生成器和判别器。
图2 训练水平。通过水平从左向右滑动一个28×14 窗口生成训练数据。
一旦训练过程完成,生成器网络可以被视为是我们学习到的genotype-to-phenotype 映射,它能够将潜在的实数向量(用蓝色表示) 作为输入(我们的论文实验中将其大小设置为32),并产生一个tile-level 的马里奥游戏级别。相比于简单地绘制来自潜在空间的独立随机样本,我们在进化控制策略下(在这种情况下使用CMA-ES) 进行探索。换句话说,我们在隐向量空间搜索并产生想要的不同属性的游戏级别,如tile 分布,难度等。
CMA-ES
协方差矩阵自适应进化策略(CMA-ES) 是一种功能强大而又广泛使用的进化算法,特别适合于实数向量的进化过程。CMA-ES 是一种二阶方法,通过有限差异法不断迭代估计协方差矩阵。它无需依赖一个光滑的自适应先验,而能够有效地处理连续域中非线性、非凸问题的优化。我们采用CMA-ES 策略来进化潜在向量,并生成的游戏级别上应用几种自适应度函数。所使用的自适应函数是基于生成的游戏级别的静态属性,或使用人工智能体进行游戏模拟结果。
游戏级别表征
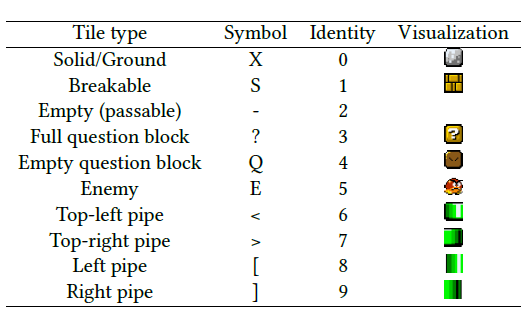
在视频游戏中,马里奥游戏级别有不同的表征Level Corpus (VGLC) 和Mario AI 框架,这两种都是基于tile的表征形式。具体地说,以VGLC 表征的马里奥级别使用特定的字符符号来表示每个可能的tile 类型。然而,应该注意的是这个VGLC 表征主要是关注tile 的功能特性而不是其艺术属性,因此无法区分视觉上某些特定的tile 类型。此外,通过仅提供的单个字符符号来表示不同的敌人类型,VGLC 编码忽略了不同敌人之间的功能差异,因此我们可以选择将其映射到通用的Goomba 敌人类型上。
为了对训练的水平进行编码,我们用不同的整数来表示每种tile 类型,它在输入到判别器前被进一步转换为一个独热编码(one-hot)。此外,生成器网络同样用独one-hot 编码形式输出再将其转换回整数值。基于整数格式的级别随后将被发送到用于渲染的Mario AI 框架。Mario AI 框架允许其tile 类型产生更广泛的艺术多样性,但由于其VGLC 编码的简单性,只有小部分子集的Mario AI tile 是可用的。从VGLC tile 类型和符号,到GAN 的训练数字编码再到最后Mario AI tile 的整个可视化流程如下表1所示。
表1生成的Mario 游戏级别所使用的tile 类型。符号字符是来自VGLC 编码,然后数字标识被映射到相应的值并用于生成可视化的Mario AI 框架。在GAN 训练期间,该数字标识值将被扩展为独热向量(one-hot) 输入到判别器网络。
GAN 模型
我们采用深度卷积生成对抗网络DCGAN 结构,并使用WGAN 算法进行训练,模型的结构示意图如下图3所示。遵循原始的DCGAN 架构,判别器网络中采用跨步长卷积(strided convolutions),而生成器中采用小步长卷积(fractional-strided convolutions),在生成器和判别器的每层后都接上batchnorm 以正则化。此外,在生成器中每一层我们都使用ReLU 激活函数(包括输出层,原始结构中输出层采用Tanh 激活函数),我们发现这能带更好的结果表现。而判别器中每一层我们采用LeakyReLU 激活函数。
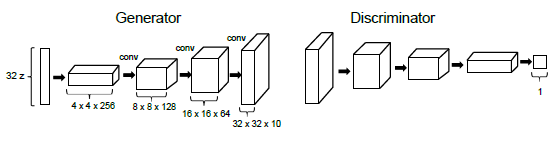
图3 训练Mario 游戏的DCGAN 模型结构
▌实验结果
为验证我们的方法,在实验部分我们通过两组不同实验分别进行基于表征测试(representation-based testing) 和基于代理测试(agent-based testing)。实验结果如下。
基于表征测试(representation-based testing)
下图4显示了该方法优化的ground tile 百分比与特定目标分布的接近程度。结果表明,每次运行中我们几乎都可以非常接近目标的百分比。
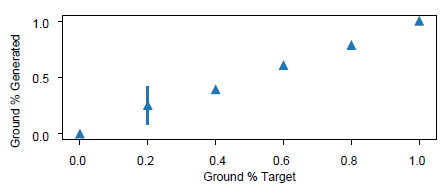
图4 优化不同百分比的ground tiles。运行20次后将平均每次的结果并产生一个标准差。除去20%的地面外,该方法总能够发现用于生成ground tiles 所需目标百分比的潜在编码。
此外,图5显示了逐级递增的游戏水平难度:其中第1和第2部分的地面覆盖率达100%,第3-5部分的地面覆盖率达70%,而第4、5节中我们还同时最大化敌人的总数n。实验结果表明我们的方法能够同时优化地面分配以及敌人的数量。

图5逐级递增的游戏难度。我们的LVE 方法能够创建含多个组成部分的游戏级别,这些级别的难度逐渐增加(即越来越少的地砖伴随着越来越多的敌人)。将来,这种方法可以用来创建一个实时的水平,以适应玩家的特殊技能(动态难度适应)。
基于代理测试(agent-based testing)
图6显示了自适应函数F1 和F2 的一些最佳和最差结果。我们可以看到,CMA-ES 策略确实可以发现一些不可玩的等级(如图6c所示)。自适应函数F1 的最佳效果(即具有大量所需跳跃操作的可玩级别) 如下图6a 和6d 所示。而图6b描述是自适应函数F2 所产生的最佳结果(即只需少量跳跃操作的可玩级别)。该级别只需要跳跃一次就能很容易地解决敌人。

图6 基于代理的优化示例。a 和b显示了F1 自适应函数下最大化跳跃次数的例子,此时最小化F2 函数。c显示了一个最差的结果,即在F1 自适应函数下不可玩的游戏级别例子。在d 中显示了高适应性的结果(即F1 下最大化跳跃步数),但同时破坏了标题的例子。
▌结论
本文提出了一种新的隐变量进化方法,它能够以无监督学习的方式,在现有的Mario 游戏水平上,进化并产生新的Mario 游戏级别。我们的方法不仅能够优化不同分布水平,并将tile 类型结合起来,还可以使用基于代理的评估函数来优化游戏级别。虽然我们的GAN 模型通常能够捕捉到高水平的训练结构,但有时也会产生破碎的结构。将来的工作我们可以通过采用更适合视频游戏离散表征的GAN 模型来优化这个问题,我们希望LVE 能够作为一种很有前景的快速生成方法,扩展到各种视频游戏以及其他类型的游戏。
参考阅读:
原文链接:
https://www.arxiv-vanity.com/papers/1805.00728/
Data 地址:
https://github.com/TheVGLC/TheVGLC
GitHub 地址:
https://github.com/TheHedgeify/DagstuhlGAN
—【完】—