检索增强生成(Retrieval-Augmented Generation,简称RAG)用于提升大语言模型回答问题的准确性。传统的大语言模型会凭空“编造”答案,RAG 结合了信息检索和文本生成技术,增强了大语言模型的文本生成能力,是解决“幻觉”问题的重要方法。
高质量的 PDF 解析是 RAG 增强大语言模型的前提。在 RAG 之前,需要利用 PDF 解析器识别PDF文档结构来革新RAG技术,从而大大提升大语言模型的准确性和可信度,提高输出质量。
我们将最近大火的LlamaParse和 ChatDOC PDF 解析器(即PDFlux)进行对比,发现ChatDOC在处理包括财务报告、学术论文、法律文件在内的各类文档时都表现出了卓越的准确性和可靠性。这背后的秘密,是我们多年积累的全景文档结构提取技术。
而与ChatDOC PDF 解析器(即PDFlux)相比,LlamaParse的表现则还有很大进步空间。
如果你想体验ChatDOC PDF 解析器(PDFlux), 请访问网址:https://pdflux.com/
以下是对比细节:
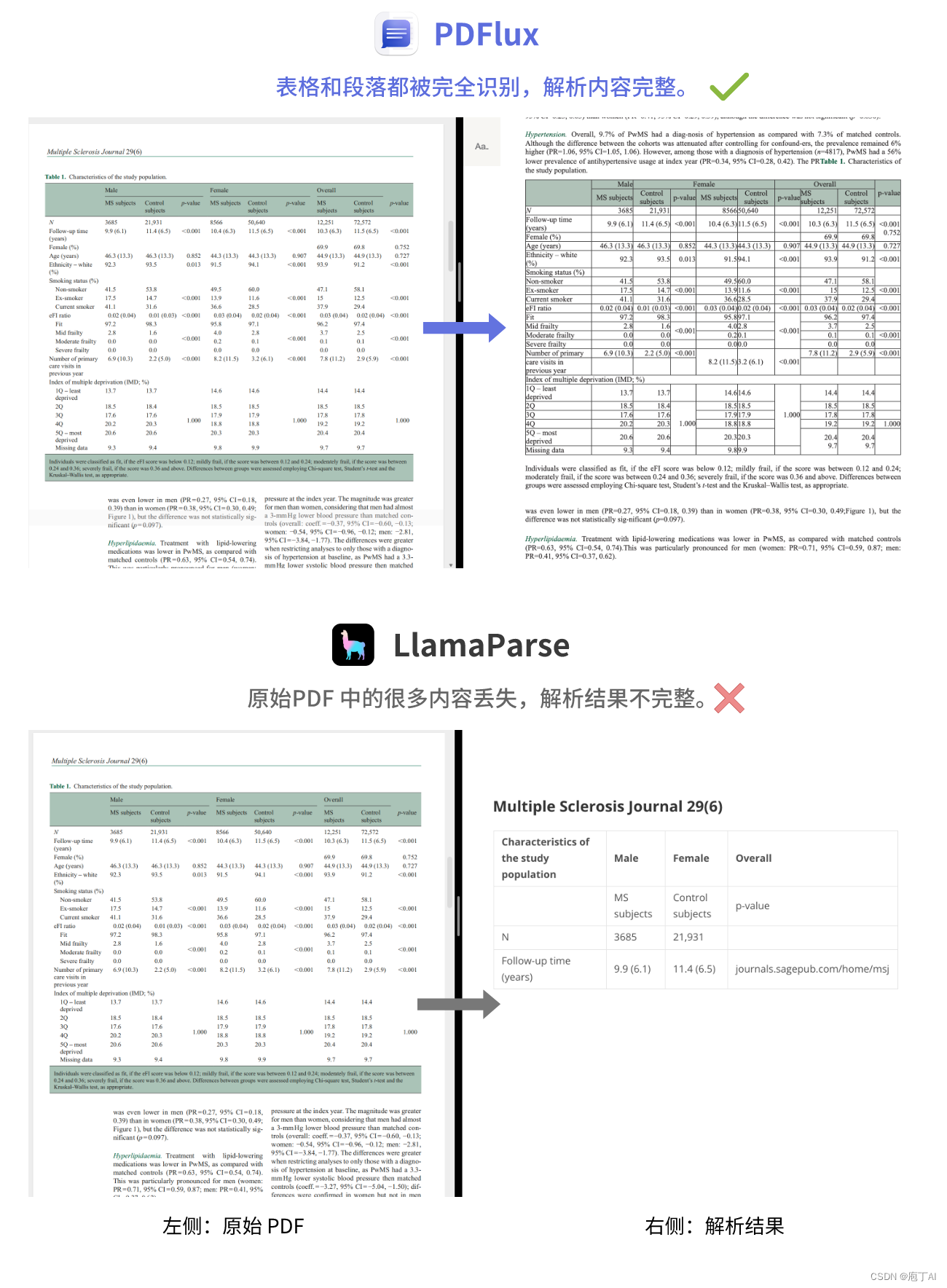
1. 内容识别是否完整
PDFlux能够完整并准确地识别表格、段落内容。而在LlamaParse上,原文档内容缺失严重,问题不只在于相对复杂的表格内容,段落内容也常常漏掉。
2. 多栏内容识别
PDFlux能够精准识别 PDF 中的多栏内容,而 LlamaParse 的多栏PDF识别效果不佳。我们测试了几份多栏PDF文档,虽然 LlamaParse能够识别部分文档,但还有很多文档无法识别。由于大多数论文都是多栏PDF格式,因此多栏内容的识别是一个关键问题。

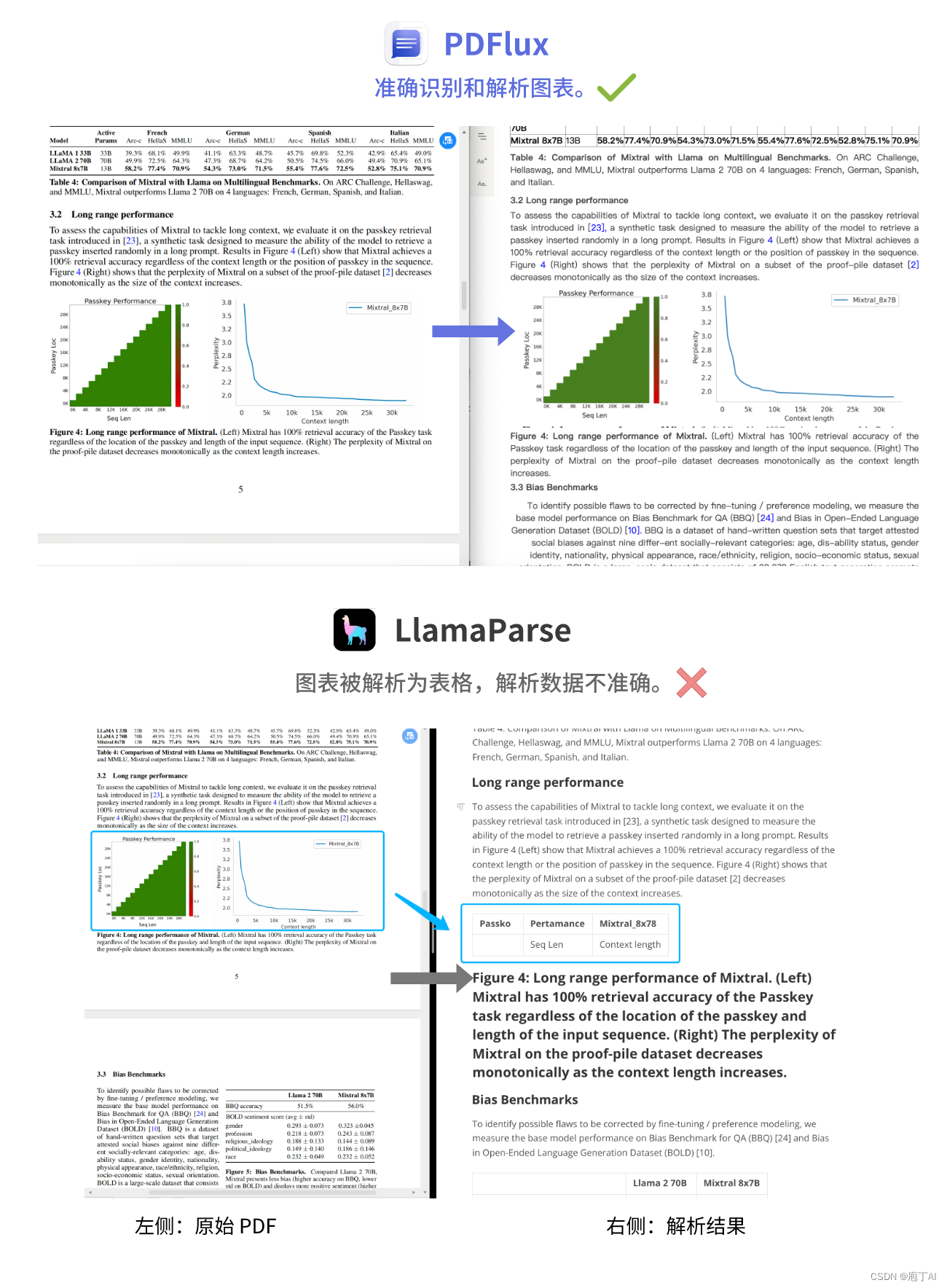
3. 表格和图表解析能力
PDFlux 可以精准解析表格和图表数据。LlamaParse 虽然可以解析嵌入表格,然而数据不准确,并且图表被错误地解析成了表格。
4. 页眉页脚识别
PDFlux 可以准确识别页眉页脚,区别于正文内容。而 LlamaParse 无法识别页眉页脚,页眉页脚与正文混在一起。这虽然是个细节问题,但对最终性能影响很大。

5. 段落内容识别
PDFlux 可以正确识别解析段落内容,而 LlamaParse 将段落内容错误地识别为表格。

6. 多页文档内容识别
以跨页表格为例,PDFlux 可以准确地识别跨页表格,并将其合并。LlamaParse 无法识别和合并跨页表格。我们推测这是因为没有识别出页眉和页脚,所以LlamaParse无法确定。

本文中提到的评测 PDF:https://journals.sagepub.com/doi/pdf/10.1177/13524585231164296