Unreal渲染管线
前言
最近在搞超分相关的工作,发现自己对Unreal渲染管线的理解还是太浅,于是边工作边整理了此文,整篇文章比较长,建议边打开Unreal源码边阅读,跟随文中的顺序能够将Unreal渲染管线错综复杂的源码模块化串联起来,以后有新的发现也会持续更新此文,如果对文章内容有疑问欢迎指正。
游戏与渲染线程
Unreal与渲染管线有关的线程实际上有三条,分别是GameThread、RenderThread和RHIThread,它们都在引擎初始化FEngineLoop::PreInit的时候通过TaskGraphImplementation::Startup由TaskGraph创建,三者的关系是游戏逻辑线程在Tick结束后向渲染线程发送命令进行渲染,渲染线程根据场景内的信息以及渲染配置执行一条完整的渲染管线(比如DeferredRender),在这个过程中的每个Pass都打包成RHICommand发送给RHI线程,RHI线程作为封装层根据实际使用的图形接口等配置将命令转换为对应图形API的Call。
其中我们最关心的“渲染管线“实际上对应的就是RenderThread中运行的逻辑。首先,渲染所需要的所有场景数据都是通过与GameThread中对应类型的映射获取得到的(两个线程各自持有数据,避免thread race),一些基本的类型映射关系如下表,例如负责Mesh网格体的UPrimitiveComponent,它在渲染线程中的映射就是FPrimitiveSceneProxy,其中包括了在MeshCollect阶段中需要用到的顶点等信息,在每帧渲染前GameThread会调用函数将场景中的所有与渲染有关的信息同步到RenderThread上的映射上。场景渲染的基础是FScene,只有注册到FScene内的组件才会被渲染,其中包含了所有的场景渲染信息,并且它将根据渲染设置在每一帧中创建对应的SceneRenderer(每帧都重新创建的临时对象),其中Render为主要的渲染执行函数,Render中会调用渲染各个阶段的Pass具体执行函数。

| Game | Render |
| UWorld | FScene |
| UPrimitiveComponent | FPrimitiveSceneProxy/FPrimitiveSceneInfo |
| ULocalPlayer | FSceneViewState |
| ULightComponent | FLightSceneProxy/FLightSceneInfo |
在整个过程中线程间具体调用方式如下
Game->RenderThread
通过ENQUEUE_RENDER_COMMAN宏,将函数放入渲染队列
ENQUEUE_RENDER_COMMAND(FDrawSceneCommand)(
[LocalSceneRenderers = CopyTemp(SceneRenderers), DrawSceneEnqueue](FRHICommandListImmediate& RHICmdList)
{
uint64 SceneRenderStart = FPlatformTime::Cycles64();
const float StartDelayMillisec = FPlatformTime::ToMilliseconds64(SceneRenderStart - DrawSceneEnqueue);
CSV_CUSTOM_STAT_GLOBAL(DrawSceneCommand_StartDelay, StartDelayMillisec, ECsvCustomStatOp::Set);
TArray<FSceneRenderer*> SingleSceneRenderer;
SingleSceneRenderer.AddZeroed(1);
for (FSceneRenderer* SceneRenderer : LocalSceneRenderers)
{
SingleSceneRenderer[0] = SceneRenderer;
RenderViewFamilies_RenderThread(RHICmdList, SingleSceneRenderer);
FlushPendingDeleteRHIResources_RenderThread();
}
});
RenderThread->RHIThread
通过RDG的AddPass将Pass执行函数加入Graph中并指定依赖,在函数中将命令放入RHICmdList
GraphBuilder.AddPass(
RDG_EVENT_NAME("DepthPassParallel"),
PassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
[this, &View, PassParameters](const FRDGPass* InPass, FRHICommandListImmediate& RHICmdList)
{
FRDGParallelCommandListSet ParallelCommandListSet(InPass, RHICmdList, GET_STATID(STAT_CLP_Prepass), *this, View, FParallelCommandListBindings(PassParameters));
ParallelCommandListSet.SetHighPriority();
View.ParallelMeshDrawCommandPasses[EMeshPass::DepthPass].DispatchDraw(&ParallelCommandListSet, RHICmdList, &PassParameters->InstanceCullingDrawParams);
});
渲染全流程
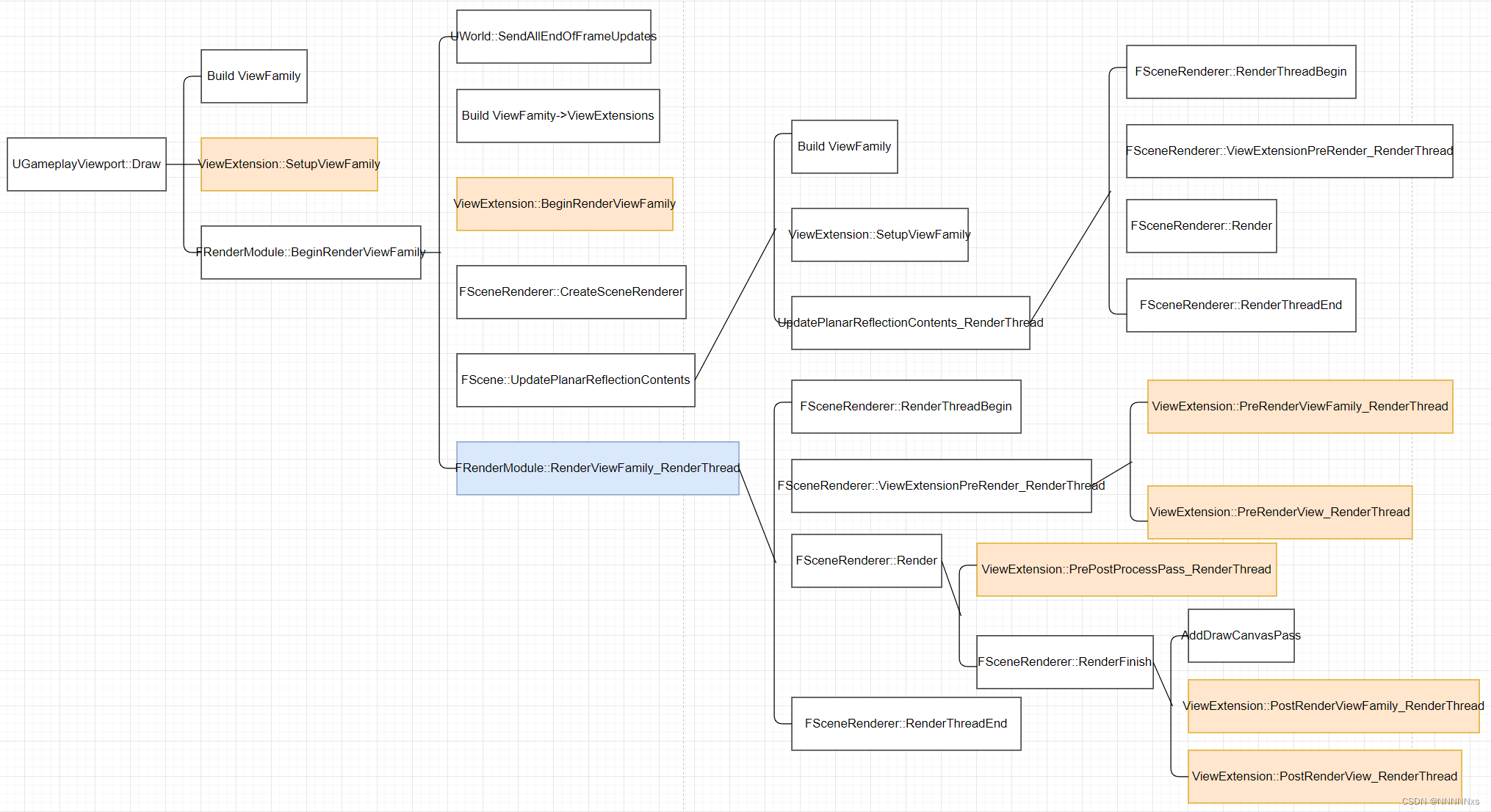
GameplayViewport::Draw
我们每帧画面绘制流程的分析从GameThread上的GameplayViewport::Draw开始,在函数中首先会创建这帧绘制的ViewFamily,然后会初始化其中的各值,比如ViewExtension就是在这个时候被填充的,紧接着就会调用各Extension中的SetupViewFamily。然后会处理很多有关动态分辨率、屏幕比例、LocalPlayer相关的内容,并且会进行更新LevelStreaming等,最后会调用RenderModule的BeginRenderViewFamily进入到真正的渲染部分(但还是在GameThread上)
FSceneViewFamilyContext ViewFamily(FSceneViewFamily::ConstructionValues(
InViewport,
MyWorld->Scene,
EngineShowFlags)
.SetRealtimeUpdate(true));
ViewFamily.ViewExtensions = GEngine->ViewExtensions->GatherActiveExtensions(ViewExtensionContext);
for (auto ViewExt : ViewFamily.ViewExtensions)
{
ViewExt->SetupViewFamily(ViewFamily);
}
FRenderModule::BeginRenderViewFamily
BeginRenderViewFamily中在真正开始任何渲染工作前首先调用UWorld::SendAllEndOfFrameUpdates将最新的渲染数据同步到渲染线程的代理上
World->SendAllEndOfFrameUpdates();
for (FSceneViewFamily* ViewFamily : ViewFamilies)
{
for (int ViewExt = 0; ViewExt < ViewFamily->ViewExtensions.Num(); ViewExt++)
{
ViewFamily->ViewExtensions[ViewExt]->BeginRenderViewFamily(*ViewFamily);
}
}
FSceneRenderer::CreateSceneRenderers(ViewFamiliesConst, Canvas->GetHitProxyConsumer(), SceneRenderers);
然后会调用所有ViewExtension的BeginRenderViewFamily,然后是创建SceneRenderer
FScene::UpdatePlanarReflectionContents
接下来在进入RenderThread前还进行了PlanarReflection的渲染,PlanarReflection相当于从反射物体朝反射方向重新渲染一次场景,优点是能够使反射物体反射屏幕视野外的物体,但缺点也很明显,从流程图上可以看出UpdatePlanarReflectionContents内几乎重新走了一遍从Draw开始的整个渲染流程。
if (!bShowHitProxies)
{
USceneCaptureComponent::UpdateDeferredCaptures(Scene);
for (int32 ReflectionIndex = 0; ReflectionIndex < Scene->PlanarReflections_GameThread.Num(); ReflectionIndex++)
{
UPlanarReflectionComponent* ReflectionComponent = Scene->PlanarReflections_GameThread[ReflectionIndex];
for (FSceneRenderer* SceneRenderer : SceneRenderers)
{
Scene->UpdatePlanarReflectionContents(ReflectionComponent, *SceneRenderer);
}
}
}
ENQUEUE_RENDER_COMMAND(FDrawSceneCommand)(
[LocalSceneRenderers = CopyTemp(SceneRenderers), DrawSceneEnqueue](FRHICommandListImmediate& RHICmdList)
{
{...}
for (FSceneRenderer* SceneRenderer : LocalSceneRenderers)
{
SingleSceneRenderer[0] = SceneRenderer;
RenderViewFamilies_RenderThread(RHICmdList, SingleSceneRenderer);
FlushPendingDeleteRHIResources_RenderThread();
}
});
FRenderModule::RenderViewFamily_RenderThread
在真正的渲染线程中,首先会创建RDG,调用每个ViewExtension的PreRenderViewFamily_RenderThread和PreRenderView_RenderThread,然后调用RenderHitProxies或者Render进行多个Pass的实际渲染工作(将Pass指定依赖顺序加入RDG,然后调用RDG.Execute()),最后调用RenderThreadEnd释放渲染资源结束渲染。
//Init AllFamilyView
FSceneRenderer::RenderThreadBegin(RHICmdList, SceneRenderers);
//更新Defererd Resources
FDeferredUpdateResource::UpdateResources(RHICmdList);
for (FSceneRenderer* SceneRenderer : SceneRenderers)
{
FRDGBuilder GraphBuilder(
RHICmdList,
RDG_EVENT_NAME("SceneRenderer_%s(ViewFamily=%s)",
ViewFamily.EngineShowFlags.HitProxies ? TEXT("RenderHitProxies") : TEXT("Render"),
ViewFamily.bResolveScene ? TEXT("Primary") : TEXT("Auxiliary")
),
FSceneRenderer::GetRDGParalelExecuteFlags(FeatureLevel)
);
FSceneRenderer::ViewExtensionPreRender_RenderThread(GraphBuilder, SceneRenderer);
if (ViewFamily.EngineShowFlags.HitProxies)
{
SceneRenderer->RenderHitProxies(GraphBuilder);
bAnyShowHitProxies = true;
}
else
{
SceneRenderer->Render(GraphBuilder);
}
SceneRenderer->FlushCrossGPUFences(GraphBuilder);
GraphBuilder.Execute();
}
FSceneRenderer::RenderThreadEnd(RHICmdList, SceneRenderers);
FSceneRenderer::Render
在调用AddPostingProcessPass前会先调用各ViewExtension的PrePostProcessPass_RenderThread
ViewFamily.ViewExtensions[ViewExt]->PrePostProcessPass_RenderThread(GraphBuilder, View, PostProcessingInputs);
无论哪个Renderer的Render都会在结束时调用RenderFinish(),其中包括AddDrawCanvasPass绘制UI以及ViewExtension的PostRenderViewFamily_RenderThread和PostRenderView_RenderThread,然后以一个EndScenePass结束整个RDG的构建。不同管线通过继承SceneRenderer重写Render方法来实现不同的渲染流程,这个函数也是渲染管线中最核心的函数,不同管线的Render详细内容在下面的章节中具体分析。
AddDrawCanvasPass(...);
for(int32 ViewExt = 0; ViewExt < ViewFamily.ViewExtensions.Num(); ++ViewExt)
{
RDG_EVENT_SCOPE(GraphBuilder, "ViewFamilyExtension(%d)", ViewExt);
ISceneViewExtension& ViewExtension = *ViewFamily.ViewExtensions[ViewExt];
ViewExtension.PostRenderViewFamily_RenderThread(GraphBuilder, ViewFamily);
for(int32 ViewIndex = 0; ViewIndex < ViewFamily.Views.Num(); ++ViewIndex)
{
RDG_EVENT_SCOPE(GraphBuilder, "ViewExtension(%d)", ViewIndex);
ViewExtension.PostRenderView_RenderThread(GraphBuilder, Views[ViewIndex]);
}
}
AddPass(GraphBuilder, RDG_EVENT_NAME("EndScene"), [this](FRHICommandListImmediate& InRHICmdList)
{
// Notify the RHI we are done rendering a scene.
InRHICmdList.EndScene();
if (GDumpMeshDrawCommandMemoryStats)
{
GDumpMeshDrawCommandMemoryStats = 0;
Scene->DumpMeshDrawCommandMemoryStats();
}
});
延迟渲染管线
延迟渲染管线是PC端默认的渲染管线,但Unreal的延迟渲染管线并不是标准的延迟渲染(Geometry Pass + Lighting Pass),而是将若干个Pass排列后的定制化管线,可以灵活的添加新功能,但底层源码非常复杂。

UpdateAllPrimitiveInfo
更新图元数据,为InitView中对Mesh的处理做准备
InitView
PreVisibilityFrameSetup
更新静态网格数据,设置运动模糊、TAA的偏移抖动等,做计算可见性图元的预处理工作
ComputeViewVisibility
通过ComputeLightVisibility计算在视锥体内的光源,然后调用UpdateReflectionSceneData更新如SSR以及反射捕获等配置数据,UpdateStaticMeshes更新静态网格数据,查看是否有预计算的可见性数据,如果有就直接存起来。然后开始进行Mesh Culling,包括HLOD层面的Culling、PrimitiveCull和OcculusionCull,最后通过GatherDynamicMeshElements将可见网格根据材质等创建不同的MeshBatch(DrawCall),在SetupMeshPass中创建不同的MeshProcessor将DrawCall发送至RHI线程,并行绘制顶点
UE::Tasks::FTask ComputeLightVisibilityTask = LaunchSceneRenderTask(UE_SOURCE_LOCATION, [this]
{
ComputeLightVisibility();
});
UpdateReflectionSceneData(Scene);
FPrimitiveSceneInfo::UpdateStaticMeshes(RHICmdList, Scene, UpdatedSceneInfos, EUpdateStaticMeshFlags::AllCommands);
View.PrecomputedVisibilityData = ViewState->GetPrecomputedVisibilityData(View, Scene);
if(bNeedsFrustumCulling)
{
// Update HLOD transition/visibility states to allow use during distance culling
FLODSceneTree& HLODTree = Scene->SceneLODHierarchy;
if (HLODTree.IsActive())
{
QUICK_SCOPE_CYCLE_COUNTER(STAT_ViewVisibilityTime_HLODUpdate);
HLODTree.UpdateVisibilityStates(View);
}
else
{
HLODTree.ClearVisibilityState(View);
}
}
{
TRACE_CPUPROFILER_EVENT_SCOPE(FSceneRenderer_Cull);
int32 NumCulledPrimitivesForView = PrimitiveCull(Scene, View, bNeedsFrustumCulling);
STAT(NumCulledPrimitives += NumCulledPrimitivesForView);
}
// Occlusion cull for all primitives in the view frustum, but not in wireframe.
if (!View.Family->EngineShowFlags.Wireframe)
{
int32 NumOccludedPrimitivesInView = OcclusionCull(RHICmdList, Scene, View, DynamicVertexBuffer);
STAT(NumOccludedPrimitives += NumOccludedPrimitivesInView);
}
{
SCOPED_NAMED_EVENT(FSceneRenderer_GatherDynamicMeshElements, FColor::Yellow);
// Gather FMeshBatches from scene proxies
GatherDynamicMeshElements(Views, Scene, ViewFamily, DynamicIndexBuffer, DynamicVertexBuffer, DynamicReadBuffer,
HasDynamicMeshElementsMasks, HasDynamicEditorMeshElementsMasks, MeshCollector);
}
SetupMeshPass(View, BasePassDepthStencilAccess, ViewCommands, InstanceCullingManager);
PostVisibilityFrameSetup
调用GatherReflectionCaptureLightMeshElements利用视锥体裁剪筛选开启ReflectionCapture的光源Mesh,然后还会对贴花Mesh进行排序
GatherReflectionCaptureLightMeshElements();
Z-PrePass/Motion Vector Pass
Z-PrePass即Early-Z,一个Depth Only的pass,用于之后的遮挡剔除。如果符合条件的话(没有半透明物体),会在此计算MotionVector
AddClearDepthStencilPass(GraphBuilder, SceneTextures.Depth.Target, DepthLoadAction, StencilLoadAction);
// Draw the scene pre-pass / early z pass, populating the scene depth buffer and HiZ
if (bNeedsPrePass)
{
RenderPrePass(GraphBuilder, SceneTextures.Depth.Target, InstanceCullingManager);
}
else
{
// We didn't do the prepass, but we still want the HMD mask if there is one
RenderPrePassHMD(GraphBuilder, SceneTextures.Depth.Target);
}
GraphBuilder.SetCommandListStat(GET_STATID(STAT_CLM_AfterPrePass));
// special pass for DDM_AllOpaqueNoVelocity, which uses the velocity pass to finish the early depth pass write
if (bShouldRenderVelocities && Scene->EarlyZPassMode == DDM_AllOpaqueNoVelocity)
{
// Render the velocities of movable objects
GraphBuilder.SetCommandListStat(GET_STATID(STAT_CLM_Velocity));
RenderVelocities(GraphBuilder, SceneTextures, EVelocityPass::Opaque, bHairStrandsEnable);
GraphBuilder.SetCommandListStat(GET_STATID(STAT_CLM_AfterVelocity));
}
PreOcculusion/Pre Atmosphere/Pre Shadow Pass
预计算遮挡、阴影和大气(包括体积云)阶段所需要用到的信息,可以在这里预执行也可以直接放在对应的Pass计算
预计算Occulusion的前提时EarlyZPassMode为DDMAllOcculuders
const bool bOcclusionBeforeBasePass = ((DepthPass.EarlyZPassMode == EDepthDrawingMode::DDM_AllOccluders) || bIsEarlyDepthComplete);
预计算大气主要是计算LUT以及SkyEnvMap,还有体积云
if (SkyAtmospherePassLocation == ESkyAtmospherePassLocation::BeforeBasePass && bShouldRenderSkyAtmosphere)
{
// Generate the Sky/Atmosphere look up tables
RenderSkyAtmosphereLookUpTables(GraphBuilder);
}
// Capture the SkyLight using the SkyAtmosphere and VolumetricCloud component if available.
const bool bRealTimeSkyCaptureEnabled = Scene->SkyLight && Scene->SkyLight->bRealTimeCaptureEnabled && Views.Num() > 0 && ViewFamily.EngineShowFlags.SkyLighting;
if (bRealTimeSkyCaptureEnabled)
{
FViewInfo& MainView = Views[0];
Scene->AllocateAndCaptureFrameSkyEnvMap(GraphBuilder, *this, MainView, bShouldRenderSkyAtmosphere, bShouldRenderVolumetricCloud, InstanceCullingManager);
}
if (bShouldRenderVolumetricCloud && bAsyncComputeVolumetricCloud && DepthPass.EarlyZPassMode == DDM_AllOpaque && !bHasRayTracedOverlay)
{
bAsyncComputeVolumetricCloud = RenderVolumetricCloud(GraphBuilder, SceneTextures, bSkipVolumetricRenderTarget, bSkipPerPixelTracing, HalfResolutionDepthCheckerboardMinMaxTexture, true, InstanceCullingManager);
}
预计算阴影的前提是开启前向渲染
if (IsForwardShadingEnabled(ShaderPlatform))
{
// With forward shading we need to render shadow maps early
RenderShadowDepthMaps(GraphBuilder, InstanceCullingManager);
RenderForwardShadowProjections(GraphBuilder, SceneTextures, ForwardScreenSpaceShadowMaskTexture, ForwardScreenSpaceShadowMaskHairTexture);
// With forward shading we need to render volumetric fog before the base pass
ComputeVolumetricFog(GraphBuilder, SceneTextures);
}
if (IsForwardShadingEnabled(ShaderPlatform) && bAllowStaticLighting)
{
RenderIndirectCapsuleShadows(GraphBuilder, SceneTextures);
}
BasePass
VS+RS+PS(包括Culling、坐标变换、插值计算等),申请G-Buffer并将深度、法线、材质等所有需要的信息写入其中,约等于标准延迟渲染中的Geometry pass,对应的光栅化过程可以参考后面Nanite BasePass的分析。
Occulusion Pass
如果没有执行PrePass的话在这里计算AO、体积云
if (!bOcclusionBeforeBasePass)
{
RenderOcclusionLambda();
}
// If not all depth is written during the prepass, kick off async compute cloud after basepass
if (bShouldRenderVolumetricCloud && bAsyncComputeVolumetricCloud && DepthPass.EarlyZPassMode != DDM_AllOpaque && !bHasRayTracedOverlay)
{
bAsyncComputeVolumetricCloud = RenderVolumetricCloud(GraphBuilder, SceneTextures, bSkipVolumetricRenderTarget, bSkipPerPixelTracing, HalfResolutionDepthCheckerboardMinMaxTexture, true, InstanceCullingManager);
}
Lighting/Shadow Pass
根据GBuffer中信息计算光照,包括
1.漫反射光照(Diffuse)和环境光(AO)
2.非直接光的胶囊阴影
3.距离场AO
4.lpv间接光照
5.高光反射和天空光照
RenderDiffuseIndirectAndAmbientOcculusion是计算间接Diffuse光照和环境光遮蔽
RenderIndirectCapsuleShadow/RenderDFAOsIndirectShadowing计算胶囊体阴影和DFAO
RenderLights计算的是直接光照
RenderDeferedReflectionAndSkyLighting计算Indirect Specular部分的各种反射和天光
AddSubsurfacePass计算次表面散射(SSR)

if (bRenderDeferredLighting)
{
RenderDiffuseIndirectAndAmbientOcclusion(
GraphBuilder,
SceneTextures,
LumenFrameTemporaries,
LightingChannelsTexture,
bHasLumenLights,
/* bCompositeRegularLumenOnly = */ false,
/* bIsVisualizePass = */ false,
AsyncLumenIndirectLightingOutputs);
// These modulate the scenecolor output from the basepass, which is assumed to be indirect lighting
if (bAllowStaticLighting)
{
RenderIndirectCapsuleShadows(GraphBuilder, SceneTextures);
}
// These modulate the scene color output from the base pass, which is assumed to be indirect lighting
RenderDFAOAsIndirectShadowing(GraphBuilder, SceneTextures, DynamicBentNormalAOTexture);
// Clear the translucent lighting volumes before we accumulate
if ((GbEnableAsyncComputeTranslucencyLightingVolumeClear && GSupportsEfficientAsyncCompute) == false)
{
TranslucencyLightingVolumeTextures.Init(GraphBuilder, Views, ERDGPassFlags::Compute);
}
RenderLights(GraphBuilder, SceneTextures, TranslucencyLightingVolumeTextures, LightingChannelsTexture, SortedLightSet);
InjectTranslucencyLightingVolumeAmbientCubemap(GraphBuilder, Views, TranslucencyLightingVolumeTextures);
FilterTranslucencyLightingVolume(GraphBuilder, Views, TranslucencyLightingVolumeTextures);
// Do DiffuseIndirectComposite after Lights so that async Lumen work can overlap
RenderDiffuseIndirectAndAmbientOcclusion(
GraphBuilder,
SceneTextures,
LumenFrameTemporaries,
LightingChannelsTexture,
bHasLumenLights,
/* bCompositeRegularLumenOnly = */ true,
/* bIsVisualizePass = */ false,
AsyncLumenIndirectLightingOutputs);
// Render diffuse sky lighting and reflections that only operate on opaque pixels
RenderDeferredReflectionsAndSkyLighting(GraphBuilder, SceneTextures, DynamicBentNormalAOTexture);
#if !(UE_BUILD_SHIPPING || UE_BUILD_TEST)
// Renders debug visualizations for global illumination plugins
RenderGlobalIlluminationPluginVisualizations(GraphBuilder, LightingChannelsTexture);
#endif
AddSubsurfacePass(GraphBuilder, SceneTextures, Views);
}
Atmosphere Pass
绘制天空环境,如果之前没有计算体积云则会在这里计算
if (bShouldRenderVolumetricCloud && !bHasRayTracedOverlay)
{
if (!bAsyncComputeVolumetricCloud)
{
RenderVolumetricCloud(GraphBuilder, SceneTextures, bSkipVolumetricRenderTarget, bSkipPerPixelTracing, HalfResolutionDepthCheckerboardMinMaxTexture, false, InstanceCullingManager);
}
// Reconstruct the volumetric cloud render target to be ready to compose it over the scene
ReconstructVolumetricRenderTarget(GraphBuilder, Views, SceneTextures.Depth.Resolve, HalfResolutionDepthCheckerboardMinMaxTexture, bAsyncComputeVolumetricCloud);
}
// Draw the sky atmosphere
if (!bHasRayTracedOverlay && bShouldRenderSkyAtmosphere && !IsForwardShadingEnabled(ShaderPlatform))
{
RenderSkyAtmosphere(GraphBuilder, SceneTextures);
}
// Draw fog.
if (!bHasRayTracedOverlay && ShouldRenderFog(ViewFamily))
{
RenderFog(GraphBuilder, SceneTextures, LightShaftOcclusionTexture);
}
Render Traslucency
将所有半透明物体根据相机深度由远及近的被绘制到一张SeparateTranslucencyTexture上(在这里叫TranslucencyResourceMap)
同时因为有半透明物体,所以Velocity被延迟到这里进行计算
FTranslucencyPassResourcesMap TranslucencyResourceMap(Views.Num());
RenderTranslucency(GraphBuilder, SceneTextures, TranslucencyLightingVolumeTextures, &TranslucencyResourceMap, TranslucencyViewsToRender, InstanceCullingManager);
if (bShouldRenderVelocities)
{
RenderVelocities(GraphBuilder, SceneTextures, EVelocityPass::Translucent, false);
}
Post Processing
所有后处理效果相关的Pass都在这里,Unreal自身支持通过SceneViewExtension模块化的将自己的后处理效果加入渲染管线中而不需要修改引擎源码,FSR和DLSS等插件都是通过这种方式将他们Upscalling Pass加入到后处理的流程中
for (int32 ViewExt = 0; ViewExt < ViewFamily.ViewExtensions.Num(); ++ViewExt)
{
for (int32 ViewIndex = 0; ViewIndex < ViewFamily.Views.Num(); ++ViewIndex)
{
ViewFamily.ViewExtensions[ViewExt]->PrePostProcessPass_RenderThread(GraphBuilder, View, PostProcessingInputs);
}
}
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
if (IsPostProcessVisualizeCalibrationMaterialEnabled(View))
{
AddVisualizeCalibrationMaterialPostProcessingPasses(GraphBuilder, View, PostProcessingInputs, DebugMaterialInterface);
}
else
{
AddPostProcessingPasses(
GraphBuilder,
View, ViewIndex,
bAnyLumenActive,
ViewPipelineState.ReflectionsMethod,
PostProcessingInputs,
NaniteResults,
InstanceCullingManager,
&VirtualShadowMapArray,
LumenFrameTemporaries,
SceneWithoutWaterTextures,
TSRMoireInput);
}
}
Nanite渲染管线
Nanite渲染管线的本质是GPU-Driven的渲染管线,Nanite提供了一套从资产导入到数据压缩加载再到 它在Unreal中与现有的延迟渲染管线耦合在一起,
Nanite Mesh Build
有些Mesh适用于Nanite,有些则不适用,对于开启Nanite的Mesh引擎会进行一套Nanite Build流程来生成Nanite所需数据,主要流程如下

Cluster切分
Nanite渲染管线的整个流程中都是以Cluster为最小单位,光栅化时也是对每个Cluster进行,所以将模型进行Cluster划分是Nanite管线的基础。每个Cluster包含128个三角形(符合光栅化阶段Cache的大小);然后组合相邻的若干个Cluster为Cluster Group,Cluster Group是生成各级LOD时Lock Edge的单位(注意Cluster和Cluster Group在每级LOD都是重新划分生成的),同时也是分页数据存储的单位,在存储Cluster时每个页大小为128kb,只有同Group并且相邻的Cluster才能放入同一页中。Cluster的切分起始使用的是LOD0级别的模型数据(切分前也只有LOD0)
Mesh简化和构建BVH
将LOD0的模型切分为若干个Cluster和Cluster Group后,在每个Cluster Group锁定边界的情况下采取QEM算法进行减面并重新划分Cluster,然后由新Cluster组成新一级LOD的Cluster Group,递归的进行此过程来生成多级LOD。
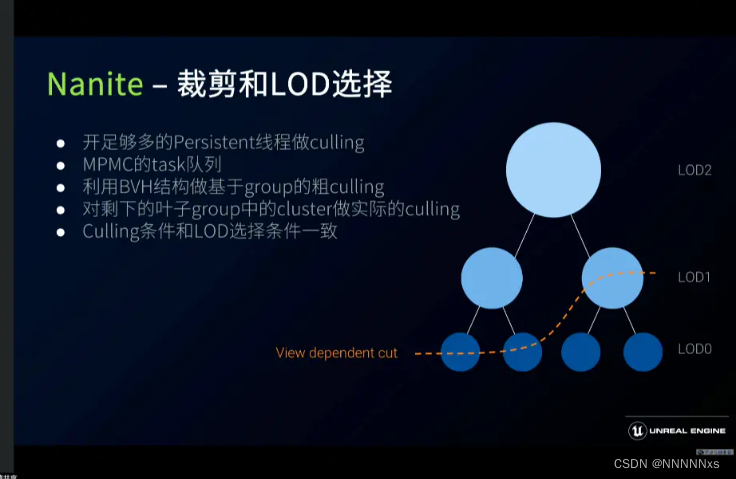
下图在边界不变的情况下将一个Group从4个Cluster减少至2个Cluster,并在这个过程中构建了之后用于剔除的BVH树结构。

BVH树的一层表示一级LOD,每个节点表示一个Cluster,所以一个模型简化的最终结果是只有一个Cluster作为Root节点,面减少到一定情况下后就只有一个Cluster Group。不难看出Cluster Group的划分算法直接决定了减面的效果(因为Cluster Group决定了减面时锁住的边界)。同时BVH树存储了每一层LOD的误差值,这个error值将作为层级选取的重要指标,根据与相机的距离找到某一层节点满足小于最大误差而父节点不满足要求(或者一直到叶子节点即LOD0都无法满足,则直接使用LOD0),按照这个逻辑在BVH树上做出当前需要加载Cluster的一个cut
数据压缩和Page编码
因为Nanite所面临的模型顶点数量往往特别巨大,所以需要一个兼顾压缩比和解压效率的压缩算法来处理大量顶点数据。一方面从数据特征上可以对不同面密度的Cluster指定不同的存储精度来实现压缩,同时每个顶点的坐标可以用更少的位数存储在LocalSpace的偏移,而且考虑到索引的连续性可以存储标志位来指示索引是否连续节省空间;另一方面因为Cluster中的index序列必然存在大量重复,每个Page可以使用LZ4等通用压缩算法进行压缩。
Nanite Mesh Render
Streaming
既然在存储Nanite Mesh时对数据进行了定制化的压缩,那么在Mesh加载进场景时也就需要进行定制化的Streaming。前面已经提到每个Page上存放的是同一个Group内的顶点数据,或者也可能是一个Group被分到两个Page中。Nanite采用自定义的方式以Page为单位将数据加载进内存,而GPU以Cluster Group为单位加载数据进入显存。除了Root级的数据外,不会将一个物体所有的Cluster数据全部加载进内存,而是在确定采用的LOD层级后以Cluster Group为单位进行加载。
当一个物体出现在视野中时,依据距离CPU查找BVH根据error确定需要请求的是哪一级的Cluster Group,将对应的Page(或者两个Page)加载进入内存,再按照Cluster Group的形式给到GPU。
这个部分可以作为定制引擎模型数据加载的案例深入研究。
UE5-nanite数据流处理_ue5 nanite_VT LI的博客-CSDN博客
Shadow
Virtual Shadow Map,原理与Virtual Texture以及上面提到的Streaming方案类似,生成多级的Shadow Map后,根据当前需要的精度(一个阴影像素对应一个屏幕像素)加载采样对应级别的Shadow Map,这样既能减少显存开销又能生成足够高精度的阴影。
BasePass
注意:BasePass只是输出GBuffer前的计算合集名称,并不是只有一个Shader Pass(由若干个Pass组成)

Nanite的管线是基于延时渲染管线上的,最大的变化就是BasePass部分,Conventional Mesh即传统Mesh在延时渲染管线中的步骤是标准的CPU-Driven渲染管线流程。开启Nanite的Mesh则会采用新的流程,但最终会输出兼容的GBuffer,并执行延时渲染管线中接下来的Lighting等步骤。
Culling
前面的Cluster、Cluster Group、BVH树以及存储和Streaming方案都是在为了高效的Culling铺垫

Instance Culling和传统管线的Culling完全一样,对整个Mesh做视锥体裁剪以及深度测试
Hierarchical Culling实际上是以Cluster Group为单位进行的Culling,会按照BVH从根节点向下进行视锥体裁剪以及深度测试,同时对于通过Culling的Cluster Group还会计算到相机的距离,根据SelfError和ParentError完成之前提到过的LOD层级选择,这个阶段后会输出StreamingPagesBuffer用于指引后续需要加载哪些Group(Page)的数据到显存。
Cluster Culling就是按照BVH树继续对通过Culling的Group进行Cluster Culling,方式依然是视锥体裁剪和深度测试,但这个阶段同时也会评估每个通过测试Cluster的大小并标记,用于确定后续采用硬件光栅还是软件光栅。这个阶段会输出VisibilityClusterBuffer包括需要光栅化的Cluster数据。

值得一提的是Nanite采取了双Pass的Depth Culling策略,在第一个Pass中使用上一帧的Z-Buffer,对通过初步筛选的Cluster建立本帧的Z-Buffer,再用本帧的Z-Buffer对未通过测试的Mesh做第二次Depth Culling。这里的思路就是连续两帧间画面变化不大,并且不该通过本帧Depth Culling的Cluster(第一次筛选出的部分Cluster)被绘制不会影响结果(最终会被覆盖),用第二个Pass来补上本帧新增需要被绘制的Cluster。
同时对于Cluster检测多线程策略采用了一个FIFO队列,不断将通过测试的BVH节点的子节点放入待检测队列,多线程持续从队列中拿去节点进行检测直至队列为空,保证了多个线程均匀分摊检测工作。
Rasterization
在实际光栅化前还会进行小三角形(小于一个像素)剔除和Back Culling,然后对大三角形和非Nanite Mesh使用硬件光栅化,小三角形使用软件光栅化。

硬件光栅化走的是标准的光栅化流程(VS+RS+PS),而软件光栅化除了用Compute Shader模拟计算光栅化外,还需要几个额外的全屏Pass进行Emit Depth Target,因为软件光栅化的结果全部写入了Visbility Buffer,而Depth、Stencil、Velocity和MaterialID需要写入Depth/Stencil/Velocity Buffer来和硬光栅结果对齐。

在输出MaterialID Buffer上Nanite采取了比较特殊的处理方式,对于画面中材质数量较少的情况,Buffer中每个像素存储一个MaterialID值,之后通过对每个材质进行一个全屏后处理Pass去Shading那些MaterialID等于当前材质的像素;但当画面中的材质数量非常大时,就无法在每个材质的全屏后处理Pass遍历对比所有像素。这时就会在Emit Depth阶段后添加一个Compute Shader将屏幕分成64*64的Block,统计每个Block内材质的范围(Min~Max),存储为一张Material Range贴图,之后Shading时就能快速筛选掉不含当前材质的像素块,加快每一个材质Pass的着色速度。

Visibility Buffer的思路其实很简单,就是通过存索引来替代完整的GBuffer以达到减少显存和带宽消耗的目的,Nanite为了和原有延迟管线兼容将通过Emit GBuffer步骤将Visibility Buffer转换为Gbuffer完成之后的着色等步骤。
Emit GBuffer
1.通过Visibility Buffer中存储的Cluster ID和Triangle ID查找VS信息(UV,Normal,Vertex Color等)
2.对顶点信息变化插值得到逐像素的信息
3.根据Material Range贴图,为每个材质进行一次全屏Pass对像素进行Shading计算出GBuffer所需数据(Albedo、Roughness、Normal等)

在管线中的位置与代码实现
UE5中Nanite与传统的Defered管线是整合在一起的,Nanite Mesh Render的工作实际上对应了传统管线中的Vertex Shader+Rasterization,所以它在延迟管线中的位置实际上是介于InitView和Z-PrePass之间的,虽然前面也有一些数据准备等工作,但Culling以及Raster都是在这里完成的
TArray<Nanite::FRasterResults, TInlineAllocator<2>> NaniteRasterResults;
{
RDG_GPU_STAT_SCOPE(GraphBuilder, NaniteVisbuffer);
RDG_EVENT_SCOPE(GraphBuilder, "Nanite VisBuffer");
if (bNaniteEnabled && Views.Num() > 0)
{
LLM_SCOPE_BYTAG(Nanite);
TRACE_CPUPROFILER_EVENT_SCOPE(InitNaniteRaster);
NaniteRasterResults.AddDefaulted(Views.Num());
if (NaniteVisibilityQuery != nullptr)
{
NaniteVisibility.Get().FinishVisibilityQuery(NaniteVisibilityQuery, NaniteRasterResults[0].VisibilityResults);
// For now we'll share the same visibility results across all views
for (int32 ViewIndex = 1; ViewIndex < NaniteRasterResults.Num(); ++ViewIndex)
{
NaniteRasterResults[ViewIndex].VisibilityResults = NaniteRasterResults[0].VisibilityResults;
}
uint32 TotalRasterBins = 0;
uint32 VisibleRasterBins = 0;
NaniteRasterResults[0].VisibilityResults.GetRasterBinStats(VisibleRasterBins, TotalRasterBins);
uint32 TotalShadingDraws = 0;
uint32 VisibleShadingDraws = 0;
NaniteRasterResults[0].VisibilityResults.GetShadingDrawStats(VisibleShadingDraws, TotalShadingDraws);
}
const FIntPoint RasterTextureSize = SceneTextures.Depth.Target->Desc.Extent;
// Primary raster view
{...}
}
}
核心部分实际上都集中在Nanite::CullRasterize中
CullRasterize
在CullRasterize中执行的实际上就是MainPass+PostPass的过程
第一部分就是先为MainPass的Culling准备输入参数,这里也可以看到HZBTexture使用的是上一帧的HZB(PrevHZB)
FCullingParameters CullingParameters;
{
CullingParameters.InViews = GraphBuilder.CreateSRV(CullingContext.ViewsBuffer);
CullingParameters.NumViews = Views.Num();
CullingParameters.NumPrimaryViews = NumPrimaryViews;
CullingParameters.DisocclusionLodScaleFactor = bDisocclusionHack ? 0.01f : 1.0f; // TODO: Get rid of this hack
CullingParameters.HZBTexture = RegisterExternalTextureWithFallback(GraphBuilder, CullingContext.PrevHZB, GSystemTextures.BlackDummy);
CullingParameters.HZBSize = CullingContext.PrevHZB ? CullingContext.PrevHZB->GetDesc().Extent : FVector2f(0.0f);
CullingParameters.HZBSampler = TStaticSamplerState< SF_Point, AM_Clamp, AM_Clamp, AM_Clamp >::GetRHI();
CullingParameters.PageConstants = CullingContext.PageConstants;
CullingParameters.MaxCandidateClusters = Nanite::FGlobalResources::GetMaxCandidateClusters();
CullingParameters.MaxVisibleClusters = Nanite::FGlobalResources::GetMaxVisibleClusters();
CullingParameters.RenderFlags = CullingContext.RenderFlags;
CullingParameters.DebugFlags = CullingContext.DebugFlags;
CullingParameters.CompactedViewInfo = nullptr;
CullingParameters.CompactedViewsAllocation = nullptr;
}
然后起了一个CS做GPU端的InitArgs工作
auto ComputeShader = SharedContext.ShaderMap->GetShader< FInitArgs_CS >( PermutationVector );
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME( "InitArgs" ),
ComputeShader,
PassParameters,
FIntVector( 1, 1, 1 )
);
为准备做裁剪的Node以及Cluster分配空间
AllocateNodesAndBatchesBuffers(GraphBuilder, SharedContext.ShaderMap, &MainAndPostNodesAndClusterBatchesBuffer);
然后就进行MainPass的Cull+Rasterize
{
RDG_EVENT_SCOPE_CONDITIONAL(GraphBuilder, !CullingContext.Configuration.bTwoPassOcclusion, "NoOcclusionPass");
RDG_EVENT_SCOPE_CONDITIONAL(GraphBuilder, CullingContext.Configuration.bTwoPassOcclusion, "MainPass");
AddPass_InstanceHierarchyAndClusterCull(
GraphBuilder,
Scene,
CullingParameters,
Views,
NumPrimaryViews,
SharedContext,
CullingContext,
RasterContext,
RasterState,
GPUSceneParameters,
MainAndPostNodesAndClusterBatchesBuffer,
MainAndPostCandididateClustersBuffer,
CullingContext.Configuration.bTwoPassOcclusion ? CULLING_PASS_OCCLUSION_MAIN : CULLING_PASS_NO_OCCLUSION,
VirtualShadowMapArray,
VirtualTargetParameters
);
MainPassBinning = AddPass_Rasterize(
GraphBuilder,
RasterPipelines,
VisibilityResults,
Views,
Scene,
SceneView,
SharedContext,
RasterContext,
RasterState,
CullingContext.PageConstants,
CullingContext.RenderFlags,
CullingContext.ViewsBuffer,
CullingContext.VisibleClustersSWHW,
nullptr,
CullingContext.ClusterCountSWHW,
CullingContext.ClusterClassifyArgs,
CullingContext.SafeMainRasterizeArgsSWHW,
CullingContext.TotalPrevDrawClustersBuffer,
GPUSceneParameters,
true,
VirtualShadowMapArray,
VirtualTargetParameters
);
}
接下来判断是否要做PostPass,如果做的话就先RebuidHZB,再重复上面的Cull+Rasterize(这里有个疑问,为什么它要叫PreviousOcculuderHZB,这不应该是当前这一帧的HZB吗)
if (CullingContext.Configuration.bTwoPassOcclusion)
{
BuildHZBFurthest(
GraphBuilder,
SceneDepth,
RasterizedDepth,
CullingContext.HZBBuildViewRect,
Scene.GetFeatureLevel(),
Scene.GetShaderPlatform(),
TEXT("Nanite.PreviousOccluderHZB"),
/* OutFurthestHZBTexture = */ &OutFurthestHZBTexture);
CullingParameters.HZBTexture = OutFurthestHZBTexture;
CullingParameters.HZBSize = CullingParameters.HZBTexture->Desc.Extent;
AddPass_InstanceHierarchyAndClusterCull()
AddPass_Rasterize()
}
AddPass_InstanceHierarchyAndClusterCull
整个函数体就两个步骤,InstanceCull和NodeAndClusterCull
InstanceCull的条件是有待Cull的Instance或者处于PostPass阶段,InstanceCull和传统管线一样不做深入
if (CullingContext.NumInstancesPreCull > 0 || CullingPass == CULLING_PASS_OCCLUSION_POST)
{
if( InstanceCullingPass == CULLING_PASS_OCCLUSION_POST )
{
PassParameters->IndirectArgs = CullingContext.OccludedInstancesArgs;
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME( "InstanceCull" ),
ComputeShader,
PassParameters,
PassParameters->IndirectArgs,
0
);
}
else
{
FComputeShaderUtils::AddPass(
GraphBuilder,
InstanceCullingPass == CULLING_PASS_EXPLICIT_LIST ? RDG_EVENT_NAME( "InstanceCull - Explicit List" ) : RDG_EVENT_NAME( "InstanceCull" ),
ComputeShader,
PassParameters,
FComputeShaderUtils::GetGroupCountWrapped(CullingContext.NumInstancesPreCull, 64)
);
}
}
AddPass_NodeAndClusterCull(
GraphBuilder,
CullingParameters,
SharedContext,
CullingContext,
GPUSceneParameters,
MainAndPostNodesAndClusterBatchesBuffer,
MainAndPostCandididateClustersBuffer,
CullingPass,
VirtualShadowMapArray,
VirtualTargetParameters,
bMultiView);
NodeAndClusterCull中根据线程是否支持我们之前说的按照队列取Node做Cull分成PersistentCull和手动循环每一层做NodeCull然后做ClusterCull两种
if (GNanitePersistentThreadsCulling)
{
AddPass_NodeAndClusterCull( GraphBuilder,
RDG_EVENT_NAME("PersistentCull"),
CullingParameters, SharedContext, CullingContext, GPUSceneParameters,
MainAndPostNodesAndClusterBatchesBuffer, MainAndPostCandididateClustersBuffer,
VirtualShadowMapArray, VirtualTargetParameters,
nullptr,
CullingPass,
NANITE_CULLING_TYPE_PERSISTENT_NODES_AND_CLUSTERS,
bMultiView);
}
else
{ const uint32 MaxNodeLevels = 12; // TODO: Calculate max based on installed pages?
for (uint32 NodeLevel = 0; NodeLevel < MaxNodeLevels; NodeLevel++)
{
FRDGBufferRef NodeCullArgs = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateIndirectDesc(3), TEXT("Nanite.NodeCullArgs"));
AddPass_InitCullArgs(GraphBuilder, RDG_EVENT_NAME("InitNodeCullArgs"), SharedContext, CullingContext, NodeCullArgs, CullingPass, NANITE_CULLING_TYPE_NODES);
AddPass_NodeAndClusterCull(
GraphBuilder,
RDG_EVENT_NAME("NodeCull_%d", NodeLevel),
CullingParameters, SharedContext, CullingContext, GPUSceneParameters,
MainAndPostNodesAndClusterBatchesBuffer, MainAndPostCandididateClustersBuffer,
VirtualShadowMapArray, VirtualTargetParameters,
NodeCullArgs,
CullingPass,
NANITE_CULLING_TYPE_NODES,
bMultiView);
}
FRDGBufferRef ClusterCullArgs = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateIndirectDesc(3), TEXT("Nanite.ClusterCullArgs"));
AddPass_InitCullArgs(GraphBuilder, RDG_EVENT_NAME("InitClusterCullArgs"), SharedContext, CullingContext, ClusterCullArgs, CullingPass, NANITE_CULLING_TYPE_CLUSTERS);
AddPass_NodeAndClusterCull(
GraphBuilder,
RDG_EVENT_NAME("ClusterCull"),
CullingParameters, SharedContext, CullingContext, GPUSceneParameters,
MainAndPostNodesAndClusterBatchesBuffer, MainAndPostCandididateClustersBuffer,
VirtualShadowMapArray, VirtualTargetParameters,
ClusterCullArgs,
CullingPass,
NANITE_CULLING_TYPE_CLUSTERS,
bMultiView);
}
AddPass_Rasterize
首先与普通光栅流程一样先进行Rasterize Binning,实际上Binning可以不算在真正的Rasterize中,它属于Rasterize的前置工作,以非常粗糙的粒度(比如8*8个Block,比Coarse Raster要更粗糙一级)确定哪些Tile被哪些Triangle覆盖了,最终将所有的Tile分成三类

其中只有Overlap的Tile需要以更低的粒度(Block)进入Rasterize Queue中做进一步的Rasterize,Trivial-Accept的Tile可以直接整个进入后面的Fragment Shading阶段
// Rasterizer Binning
FBinningData BinningData = {};
AddPass_Binning(
GraphBuilder,
Scene,
SharedContext,
PageConstants,
RenderFlags,
VisibleClustersSWHW,
ClusterOffsetSWHW,
ClusterCountSWHW,
ClusterClassifyArgs,
TotalPrevDrawClustersBuffer,
GPUSceneParameters,
bMainPass,
VirtualShadowMapArray != nullptr,
bUsePrimitiveShader,
BinningData
);
根据管线是否可编程以及硬件支持VS或MS,将Shader和参数绑定好,对应的软光栅CS就是FMicropolyRasterizeCS
struct FRasterizerPass
{
TShaderRef<FHWRasterizePS> RasterPixelShader;
TShaderRef<FHWRasterizeVS> RasterVertexShader;
TShaderRef<FHWRasterizeMS> RasterMeshShader;
TShaderRef<FMicropolyRasterizeCS> RasterComputeShader;
}
// Programmable vertex features
if (bVertexProgrammable)
{
if (bUseMeshShader)
{
PermutationVectorMS.Set<FHWRasterizeMS::FVertexProgrammableDim>(bVertexProgrammable);
PermutationVectorMS.Set<FHWRasterizeMS::FPixelProgrammableDim>(bPixelProgrammable);
ProgrammableShaderTypes.AddShaderType<FHWRasterizeMS>(PermutationVectorMS.ToDimensionValueId());
}
else
{
PermutationVectorVS.Set<FHWRasterizeVS::FVertexProgrammableDim>(bVertexProgrammable);
PermutationVectorVS.Set<FHWRasterizeVS::FPixelProgrammableDim>(bPixelProgrammable);
ProgrammableShaderTypes.AddShaderType<FHWRasterizeVS>(PermutationVectorVS.ToDimensionValueId());
}
}
// Programmable pixel features
if (RasterizerPass.bPixelProgrammable)
{
PermutationVectorPS.Set<FHWRasterizePS::FVertexProgrammableDim>(bVertexProgrammable);
PermutationVectorPS.Set<FHWRasterizePS::FPixelProgrammableDim>(bPixelProgrammable);
ProgrammableShaderTypes.AddShaderType<FHWRasterizePS>(PermutationVectorPS.ToDimensionValueId());
}
// Programmable micropoly features
if (RasterizerPass.bVertexProgrammable || RasterizerPass.bPixelProgrammable)
{
PermutationVectorCS.Set<FMicropolyRasterizeCS::FTwoSidedDim>(RasterizerPass.RasterPipeline.bIsTwoSided);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FVertexProgrammableDim>(bVertexProgrammable);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FPixelProgrammableDim>(bPixelProgrammable);
ProgrammableShaderTypes.AddShaderType<FMicropolyRasterizeCS>(PermutationVectorCS.ToDimensionValueId());
}
auto* RasterPassParameters = GraphBuilder.AllocParameters<FRasterizePassParameters>();
RasterPassParameters->RenderFlags = RenderFlags;
if (RasterState.bReverseCulling)
{
RasterPassParameters->RenderFlags |= NANITE_RENDER_FLAG_REVERSE_CULLING;
}
RasterPassParameters->View = SceneView.ViewUniformBuffer;
RasterPassParameters->ClusterPageData = GStreamingManager.GetClusterPageDataSRV(GraphBuilder);
RasterPassParameters->GPUSceneParameters = GPUSceneParameters;
RasterPassParameters->RasterParameters = RasterParameters;
RasterPassParameters->VisualizeModeBitMask = RasterContext.VisualizeModeBitMask;
RasterPassParameters->PageConstants = PageConstants;
RasterPassParameters->HardwareViewportSize = FVector2f(ViewRect.Width(), ViewRect.Height());
RasterPassParameters->MaxVisibleClusters = Nanite::FGlobalResources::GetMaxVisibleClusters();
RasterPassParameters->VisibleClustersSWHW = GraphBuilder.CreateSRV(VisibleClustersSWHW);
RasterPassParameters->IndirectArgs = BinIndirectArgs;
RasterPassParameters->InViews = ViewsBuffer != nullptr ? GraphBuilder.CreateSRV(ViewsBuffer) : nullptr;
RasterPassParameters->InClusterOffsetSWHW = GraphBuilder.CreateSRV(ClusterOffsetSWHW, PF_R32_UINT);
RasterPassParameters->InTotalPrevDrawClusters = GraphBuilder.CreateSRV(TotalPrevDrawClustersBuffer);
RasterPassParameters->MaterialSlotTable = Scene.NaniteMaterials[ENaniteMeshPass::BasePass].GetMaterialSlotSRV();
RasterPassParameters->RasterizerBinData = GraphBuilder.CreateSRV(BinningData.DataBuffer);
RasterPassParameters->RasterizerBinHeaders = GraphBuilder.CreateSRV(BinningData.HeaderBuffer);
然后分别进行硬件光栅(VS/MS+PS)和软件光栅(CS)
GraphBuilder.AddPass(
RDG_EVENT_NAME("HW Rasterize"),
RasterPassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
[RasterPassParameters, &RasterizerPasses, ViewRect, &SceneView, FixedMaterialProxy, RPInfo, bMainPass, bUsePrimitiveShader, bUseMeshShader](FRHICommandList& RHICmdList)
{
...
});
if (Scheduling != ERasterScheduling::HardwareOnly)
{
GraphBuilder.AddPass(
RDG_EVENT_NAME("SW Rasterize"),
RasterPassParameters,
ComputePassFlags,
[RasterPassParameters, &RasterizerPasses, &SceneView, FixedMaterialProxy](FRHIComputeCommandList& RHICmdList)
{
...
});
}
这篇文章以非常简单易懂的方式阐述了普通硬件光栅化的过程
Chasing Triangles in a Tile-based Rasterizer | Tayfun Kayhan
EmitDepthTarget
结束光栅化后,如果需要Z-Prepass的话,则直接输出Depth Buffer
if (bNeedsPrePass)
{
// Emit velocity with depth if not writing it in base pass.
FRDGTexture* VelocityBuffer = !IsUsingBasePassVelocity(ShaderPlatform) ? SceneTextures.Velocity : nullptr;
const bool bEmitStencilMask = NANITE_MATERIAL_STENCIL != 0;
Nanite::EmitDepthTargets(
GraphBuilder,
*Scene,
Views[ViewIndex],
CullingContext.PageConstants,
CullingContext.VisibleClustersSWHW,
CullingContext.ViewsBuffer,
SceneTextures.Depth.Target,
RasterContext.VisBuffer64,
VelocityBuffer,
RasterResults.MaterialDepth,
RasterResults.MaterialResolve,
bNeedsPrePass,
bEmitStencilMask
);
}
BuildFinalHZB
最后再计算一次PostPass后的完整HZB,供之后部分以及下一帧使用
if (!bIsEarlyDepthComplete && CullingConfig.bTwoPassOcclusion && View.ViewState)
{
BuildHZBFurthest(
GraphBuilder,
SceneDepth,
RasterContext.VisBuffer64,
PrimaryViewRect,
FeatureLevel,
ShaderPlatform,
TEXT("Nanite.HZB"),
/* OutFurthestHZBTexture = */ &GraphHZB );
}