注:md文件,Typora书写,md兼容程度github=CSDN>知乎,若有不兼容处麻烦移步其他平台,github文档供下载。
上传在github:https://github.com/FermHan/Learning-Notes
发表在CSDN:https://blog.csdn.net/hancoder/article/
发表在知乎专栏:https://zhuanlan.zhihu.com/c_1088438808227254272
学习总结
本文依次讲解了目标检测的必读论文:R-CNN,SPP,Fast R-CNN,Faster R-CNN。
网上有很多“一文读懂…”,其实这类文章只是带入门,知道某个名词是干什么的,真正想要看懂这些文章还是需要先大概看一遍论文。而此文针对的是论文原文与百度结合的读者。因为此文写作时间有点跨度,零散地看到些论文中的重点理解就记录下来,所以此文排版不是非常整齐,但内容还是非常丰富的。
前言与知识预热
-
目标检测由来:1966年,Marvin Minsky让他的学生Gerald Jay Sussman花费一个暑假把相机连接到电脑上以使电脑能描述看到的东西。
-
实例分割(instance Segmentation):标记实例和语义, 不仅要分割出
人这个类, 而且要分割出这个人是谁, 也就是具体的实例。即不仅要分类,而且同类间需要区别每个个体。semantic segmentation - 只标记语义, 也就是说只分割出人这个类来 -
定位框的表示:只需(x_0,y_0,width,height)四个参数,即可表示一个框
-
目标检测竞赛:
- Pascal VOC:20 classes常用
- COCO:200 classes,2018年COCO竞赛中国团队包揽全部六项任务的冠军,其中旷视取得4项冠军
- ImageNet ILSVRC停办
-
目标检测数据集:Caltech2005,Pascal VOC2005,,LabelMe2007,ImageNet2009,Caltech-USCD-birds-200 2010,FGVC-Aircraft2013
-
pre-train和fine-tune:pre-train指的是在ImageNet上对CNN模型进行预训练。预训练的数据和真实训练的数据集不必一样。fine-tune指的是使用真正的数据集进行训练,调整。
-
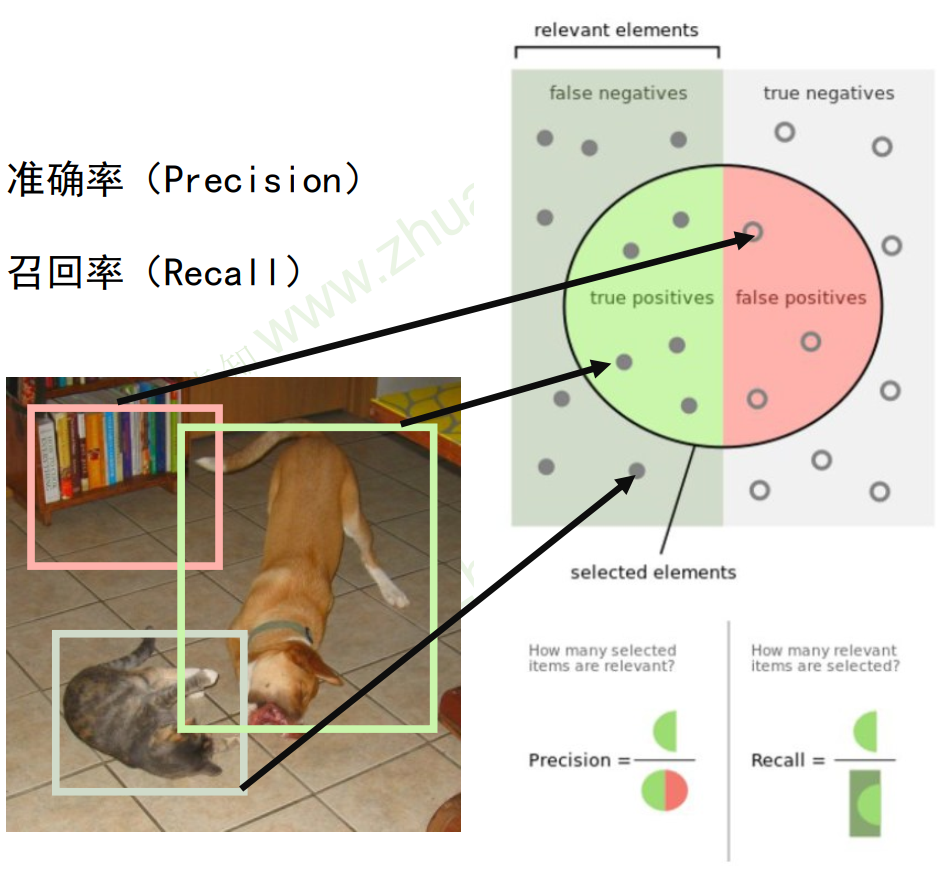
评价准则:召回率
- 如图所示,召回率指的是真实标签中有多少被检测出来了,想要的正例有多少被召回来了。
- IOU(Intersection-over-Union)指的是真实检测框与计算出来的检测框之间的交并比
- 从一张图中提取候选框Region Proposal方法:EdgeBoxes和Selective Search(SS)。
- 选择性搜索SS于层次聚类算法,主要通过框与框之间的颜色,纹理,大小,吻合等相似度排序,合并相邻的相似区域来减少候选框。即不断合并相似的框,直到相似度达到一定程度或者框的数目减小到阈值(~2K个)。合并策略:S = a×S(color) + b× S(texture) + c×S(size) + d×S(fit);
- 非极大值抑制
- 抑制不是最大值的元素,把与指定框(分数高的)overlap大于一定阈值的其他框移除
- 框的表示:因为框是矩形,所以我们只需知道左上角和右下角坐标即可知道框的位置。此外,也可以用左上角坐标和框的宽高、或者框的中心坐标和框的宽高来表示。
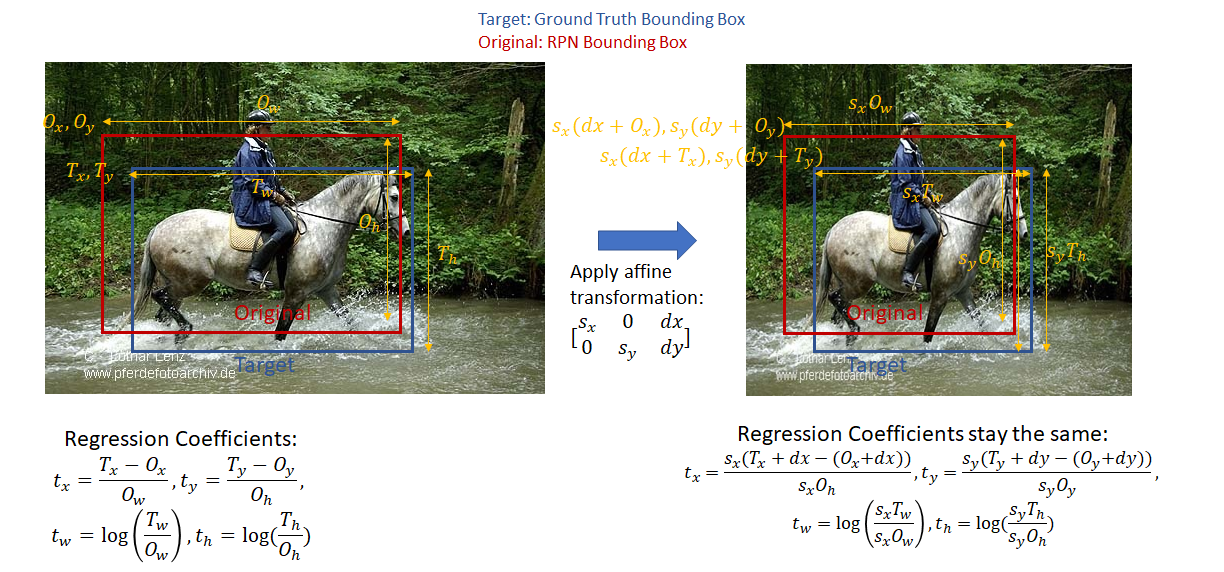
- 边界框回归:调整边界框是相对于anchor调整的,而不是直接回归出预测框坐标,而是通过间接转化得出的。
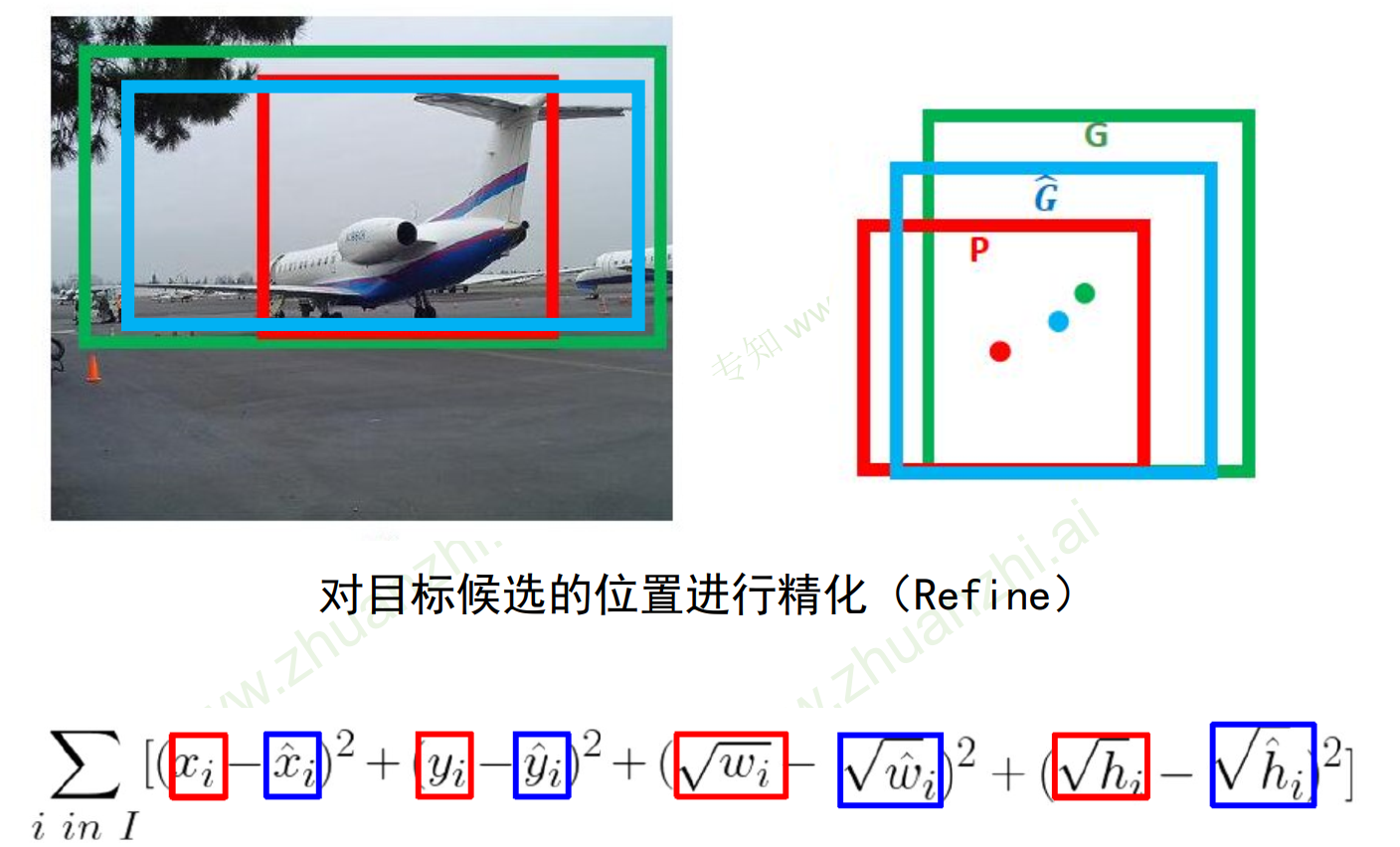
通常我们算位置框loss时使用的是xywh四个值进行回归。T字母代表Target,即预测的框,我们想要T接近于真实框。O代表Original,即原始anchor框。
这里我们先不讲3个框,而是只看预测框和anchor框。预测框与anchor框的距离可以通过如下表示:
-
t x = T x − O x O w , t y = T y − O y O h , t w = l o g ( T w O w ) , t h = l o g ( T h O h ) t_x={T_x-O_x\over{O_w}},t_y={T_y-O_y\over{O_h}},t_w=log({T_w \over O_w}),t_h=log({T_h \over O_h}) tx=OwTx−Ox,ty=OhTy−Oy,tw=log(OwTw),th=log(OhTh).
-
为什么是上式表示,而不是欧氏距离呢?原因是这么表示的框缩放图片后t是不变的
目标检测分为单阶段和二阶段检测,此文我们说的是单阶段检测
两阶段
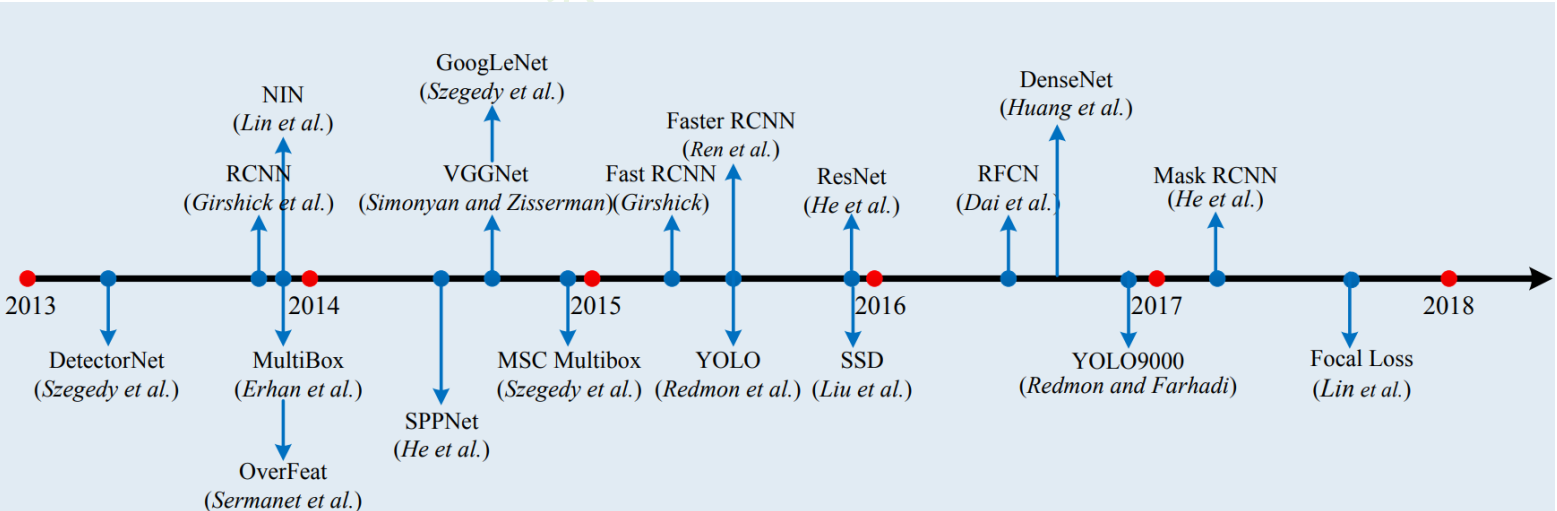
object detection技术的演进:
- RCNN(Selective Search + CNN + SVM)
- ->SPP-net:Spatial Pyramid Pooling(空间金字塔池化)(ROI Pooling)
- ->Fast R-CNN(Selective Search + CNN + ROI)
- ->Faster R-CNN(RPN + VGG + ROI)
- ->Mask R-CNN(resnet +FPN)
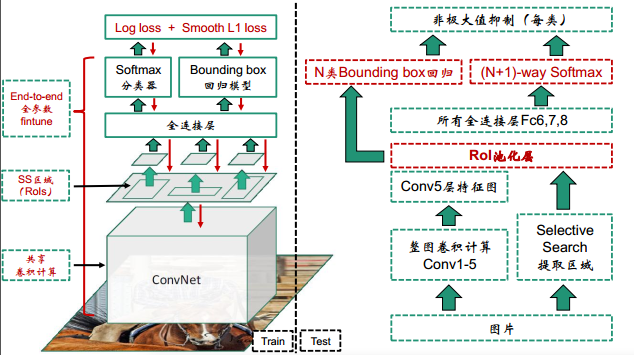
一. RCNN
2014年,作者RBG
R-CNN解决的是,“为什么不用CNN做classification呢?”
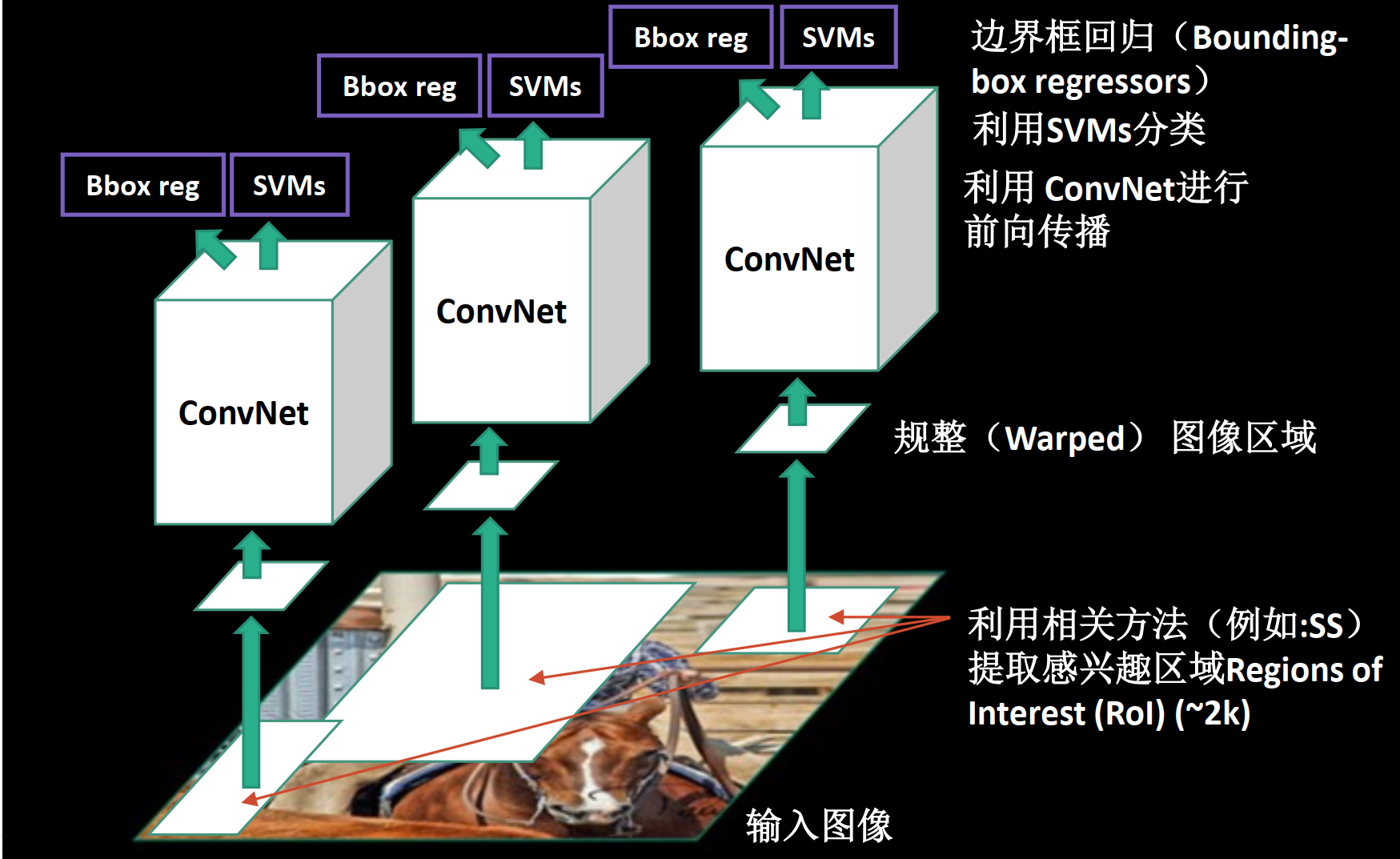
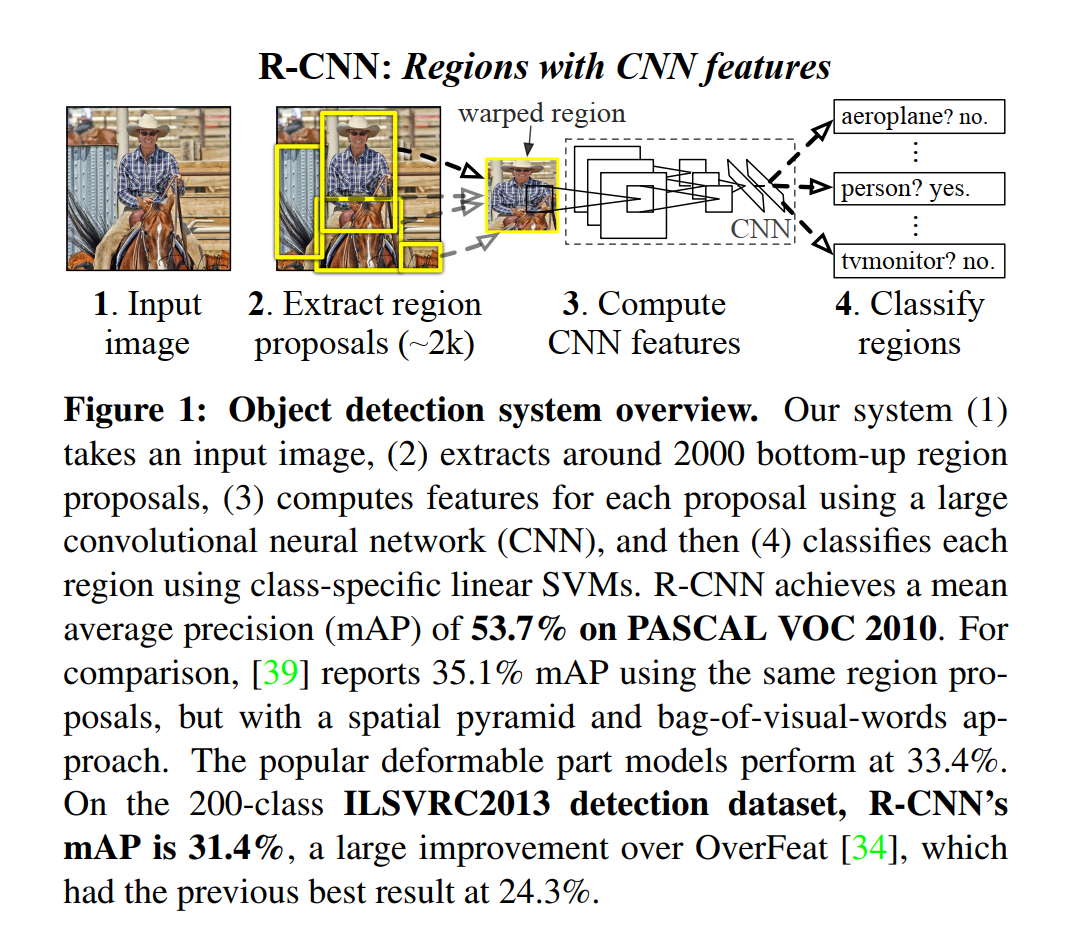
R-CNN步骤:
一:用SS提取候选区域
二:用CNN提取区域特征
三:对区域进行SVM分类+边框校准
R-CNN详解:
一:用SS提取候选区域

哪一层的特征好用?
二:用CNN提取区域特征
-
将不同大小的候选区域(原图)缩放到相同大小
-
将所有区域送入AlexNet提取特征:5个卷积层,2个全连接层
-
以最后一个全连接网络的输出作为区域的特征表示:

-
有监督预训练pretraining
- 图像分类任务:使用ImageNet,1000类,仅有图像标签,没有物体边框标准
- 数据量120张图像,多。此时得到的是分类的网络,而不是检测网络
-
针对目标任务进行微调 Fine-tuning
- 目标检测任务:Pascal VOC,20类,有物体边框标注
- 数据量:仅有数千或上万张图像,少。
- 已经经过了大量CNN的预训练,只需要少量图片就可以在检测上做的比较好

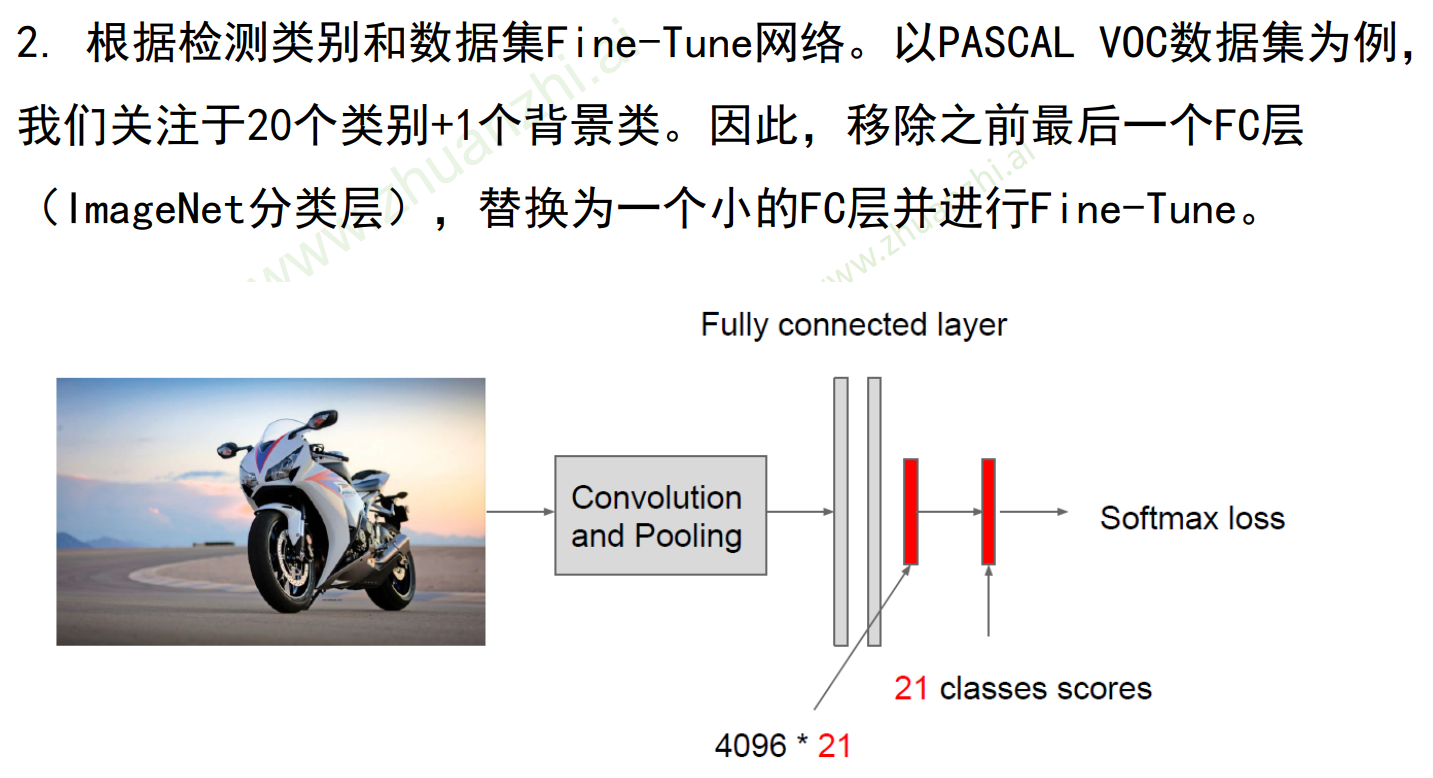
三:对区域进行分类+边框校准
-
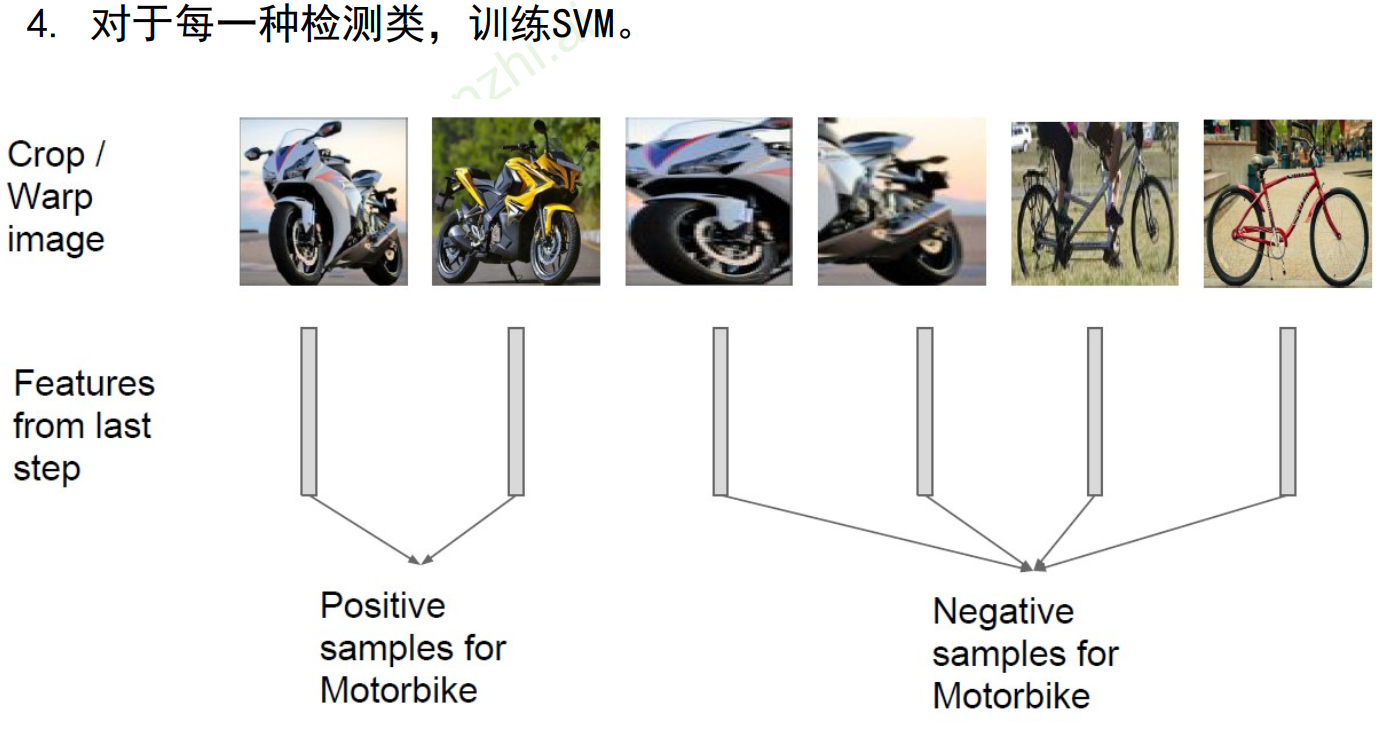
线性SVM分类器(不使用之前的softmax了)
- 针对每个类别分类训练,每个类别对应一个SVM分类器
- 两类分类:one-vs-all
- 对于摩托车SVM,摩托车是正类,其余是父类。对于自行车SVM,自行车是正类,其余是父类。
-
softmax分类
- 和整个CNN一起端到端训练
- 所有类别一起训练
- 多类分类
-
边框校准(包含更少的背景)
线性回归模型(x,y,w,h)
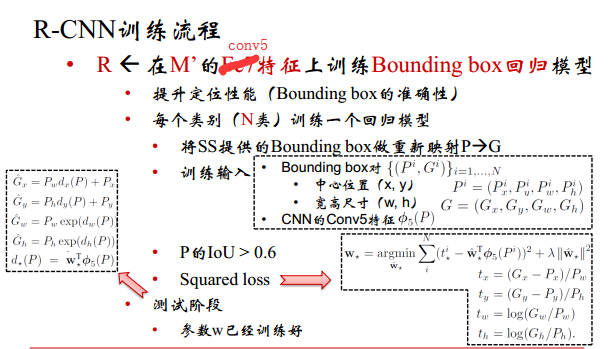
G x = P w d x ( P ) + P x G_x=P_w d_x(P)+P_x Gx=Pwdx(P)+Px
G y = P y d y ( P ) + P y G_y=P_y d_y(P)+P_y Gy=Pydy(P)+Py
G w = P w e x p ( d w ( P ) ) G_w=P_wexp(d_w(P)) Gw=Pwexp(dw(P))
G h = P h e x p ( d h ( P ) ) G_h=P_hexp(d_h(P)) Gh=Phexp(dh(P))

非极大值抑制算法:得分从大到小排序,最大的分别于后面的IoU比较,与拥有最大值的图片重合度大于0.5的,则丢掉小的。这样丢掉了一部分图片。然后拿出来最大值的图片,第二大的再和其余更小的去比较。
非极大值抑制后可能图片数大大减少了,然后再进行边框回归。

缺点:
- 需要变形特征到固定大小,crop/warp会丢失了长宽比信息,影响检测精度
- 低效的流水线,SS耗时,每个候选区域输入到卷积也耗时
- 训练时间很长(48小时)=FineTune(18)+特征提取(63)+SVM/Bbox训练(3)
- 测试阶段很慢:VGG一张图片47s
- 所谓端到端是指在一个神经网络里整体去实现


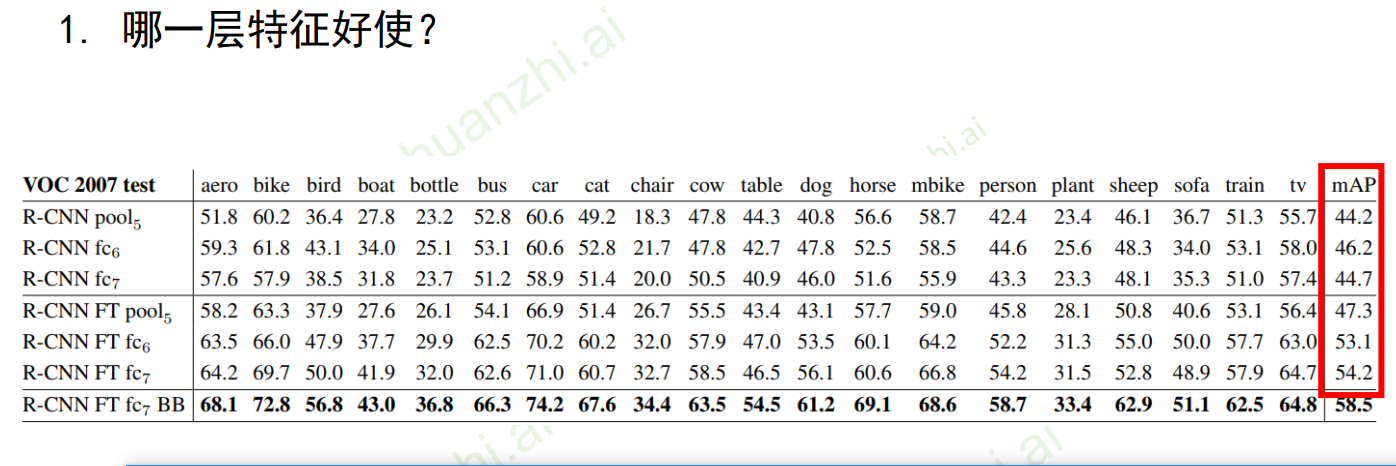
pool5底层的特征,万金油,但是准确率不高

| 候选区域目标(RP) | 特征提取 | 分类 | |
|---|---|---|---|
| RCNN | selective search | CNN | SVM |
| 传统的算法 | objectness,constrainedparametric min-cuts,sliding window,edge boxes,… | HOG , SIFT,LBP, BoW,DPM,… | SVM |
二. SPP - net:Spatial Pyramid Pooling
作者何凯明
R-CNN的低效原因是因为全连接层的输入长度需要固定(而卷积层的输入大小任意),SPP的贡献是1:将不同大小的特征图归一化到相同大小。此外:2“SPP还对整张图计算卷积特征,去除了各个区域的重复计算。在整张图片上只进行一躺卷积,然后SPP-net从feature map上抽取特征。
SPP-net与R-CNN的对比

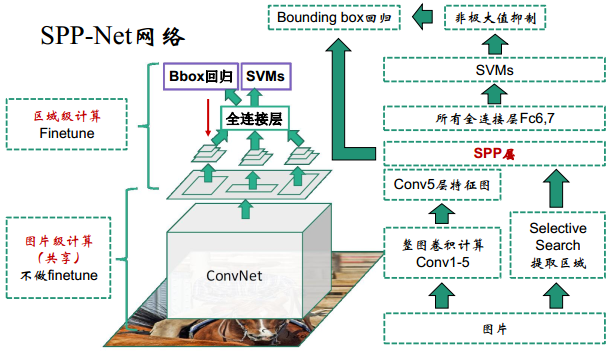
区别:RCNN输入原图像的proposal VS SPP输入特征的proposal
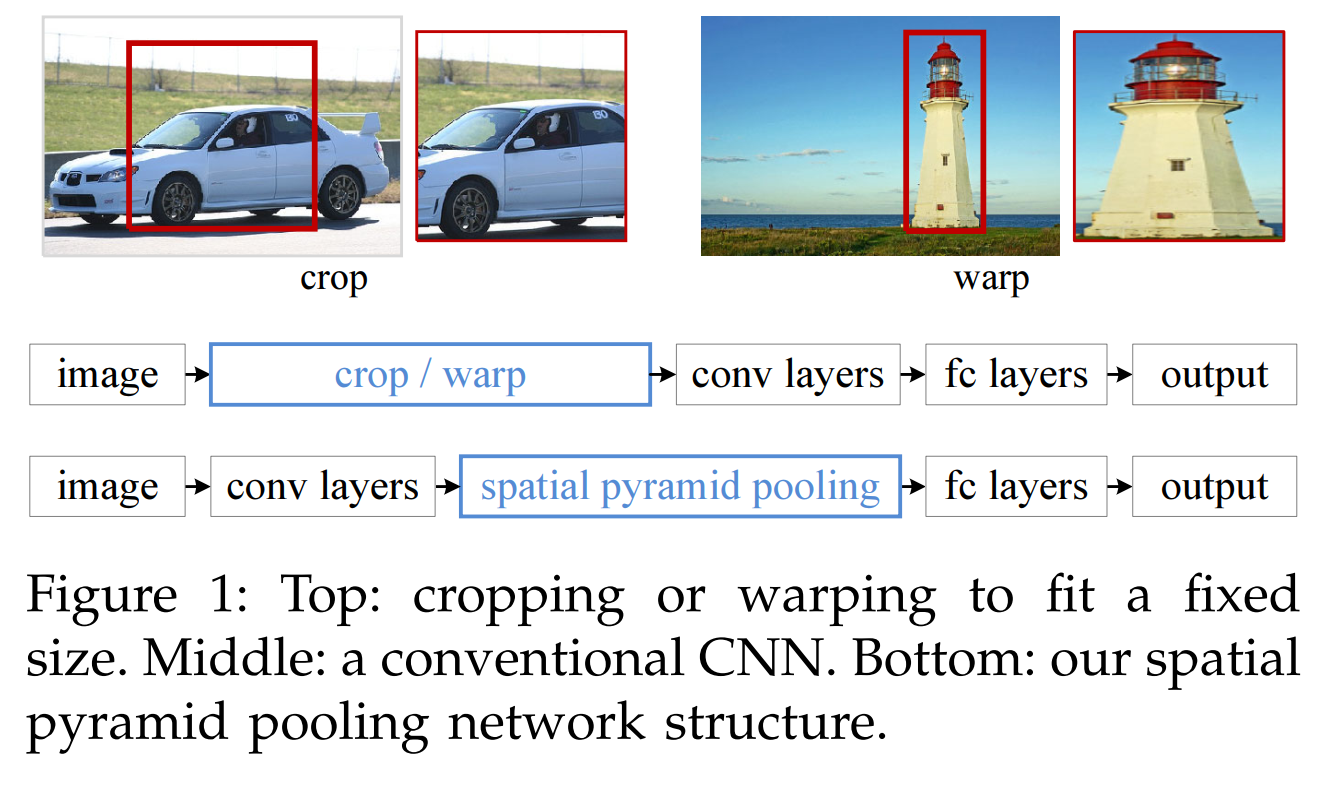
SPP:3个level和21个Bin:1×1,2×2,4×4。在bin内使用maxpooling。如图所示,把特征图分别16,4,1等分,从每个等分块中取一个像素,从而构成相同长度的向量。也可以只进行16等分,从而得到长度16的向量。(为了可以把卷积层与全连接层连接)
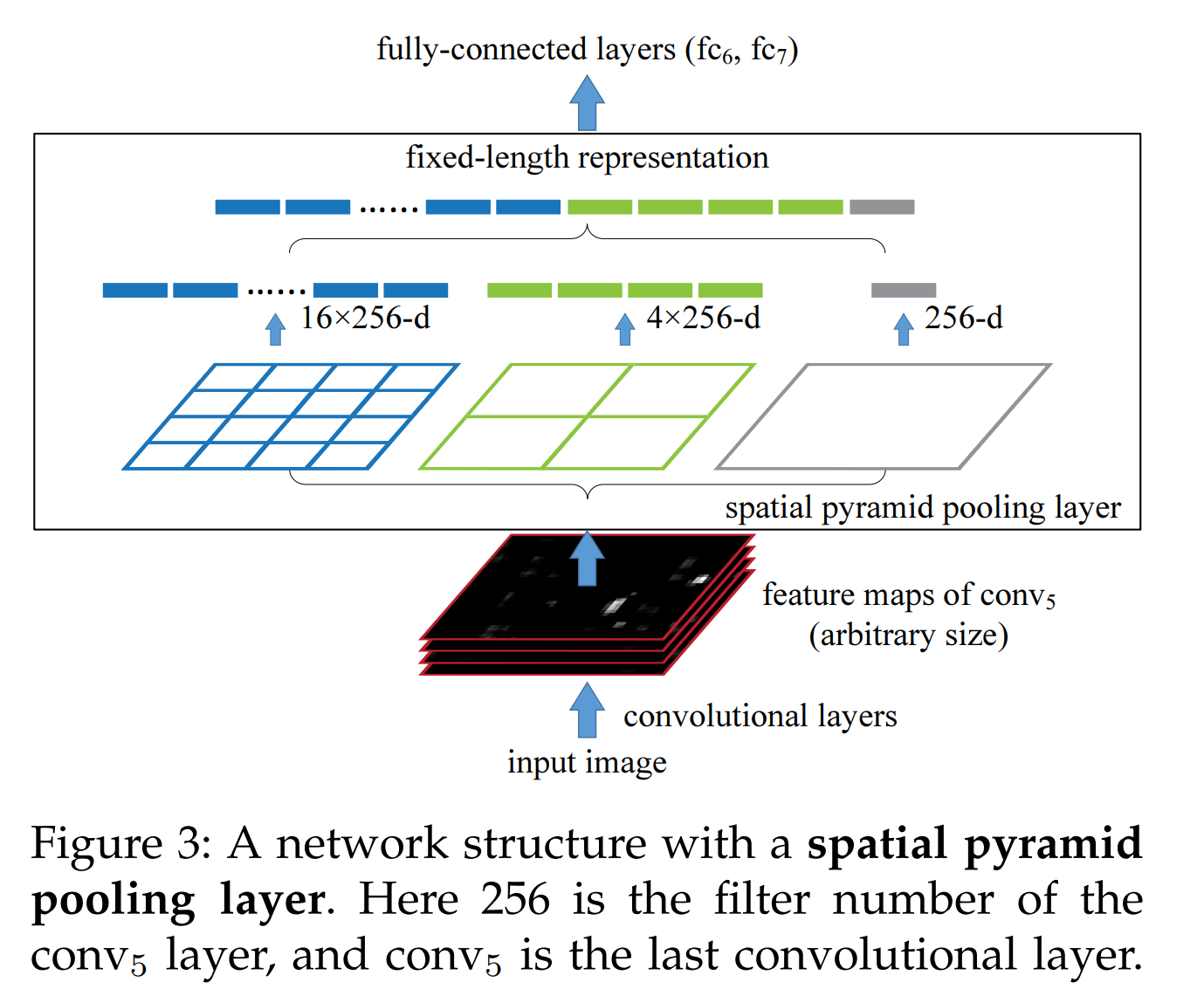
窗口大小 w i n = ⌈ a / n ⌉ win = ⌈a/n⌉ win=⌈a/n⌉,步长 s t r i d e = ⌊ a / n ⌋ stride = ⌊a/n⌋ stride=⌊a/n⌋
解决的是,因为全连接层的输入需要固定尺寸,既然卷积层可以适应任何尺寸,那么只需要在卷积层的最后加入某种结构,使得后面全连接层得到的输入为固定程度就可以了。所以将金字塔思想加入CNN,提取固定长度的特征向量,实现了数据的多尺度输入。Spatial Pyramid Pooling添加在卷积后,全连接前。SPP还有一个优化点是:如果对ss提供的2000多个候选区域都逐一进行卷积处理,很耗时。解决思路是先将整张图卷积得到特征图,然后再将ss算法提供的2000多个候选区域的位置记录下来,通过比例映射到整张图的feature map上提取出候选区域的特征图B(映射关系与补偿有关),然后将B送入到金字塔池化层中,进行权重计算。

**SPP-net的缺点:**步骤还是很繁琐
- R-CNN和SPP-net的训练都包含多个单独的步骤
- 1)多网络进行微调
- R-CNN对整个CNN进行微调
- SPP-net只对SPP之后的(全连接)层进行微调
- 2)训练SVM,
- 3)训练边框回归模型
- 1)多网络进行微调
- 检测速度慢,尤其是R-CNN
- RCNN+VGG16:检测一张图需要47s
- 和RCNN一样,训练过程仍然是隔离的,多阶段。提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
2 )SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
3)在整个过程中,Proposal Region仍然很耗时。
- 新问题:SPP之前的所有卷积层参数不能finetune
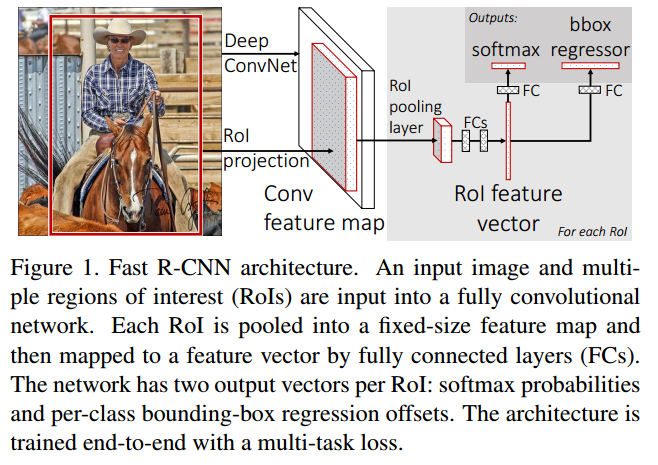
三. Fast R-CNN
之前方法缺点:

解决的是,“为什么不一起输出bounding box和label呢?”。把SVM和边框回归去掉,由CNN直接得到类别和边框。
框架
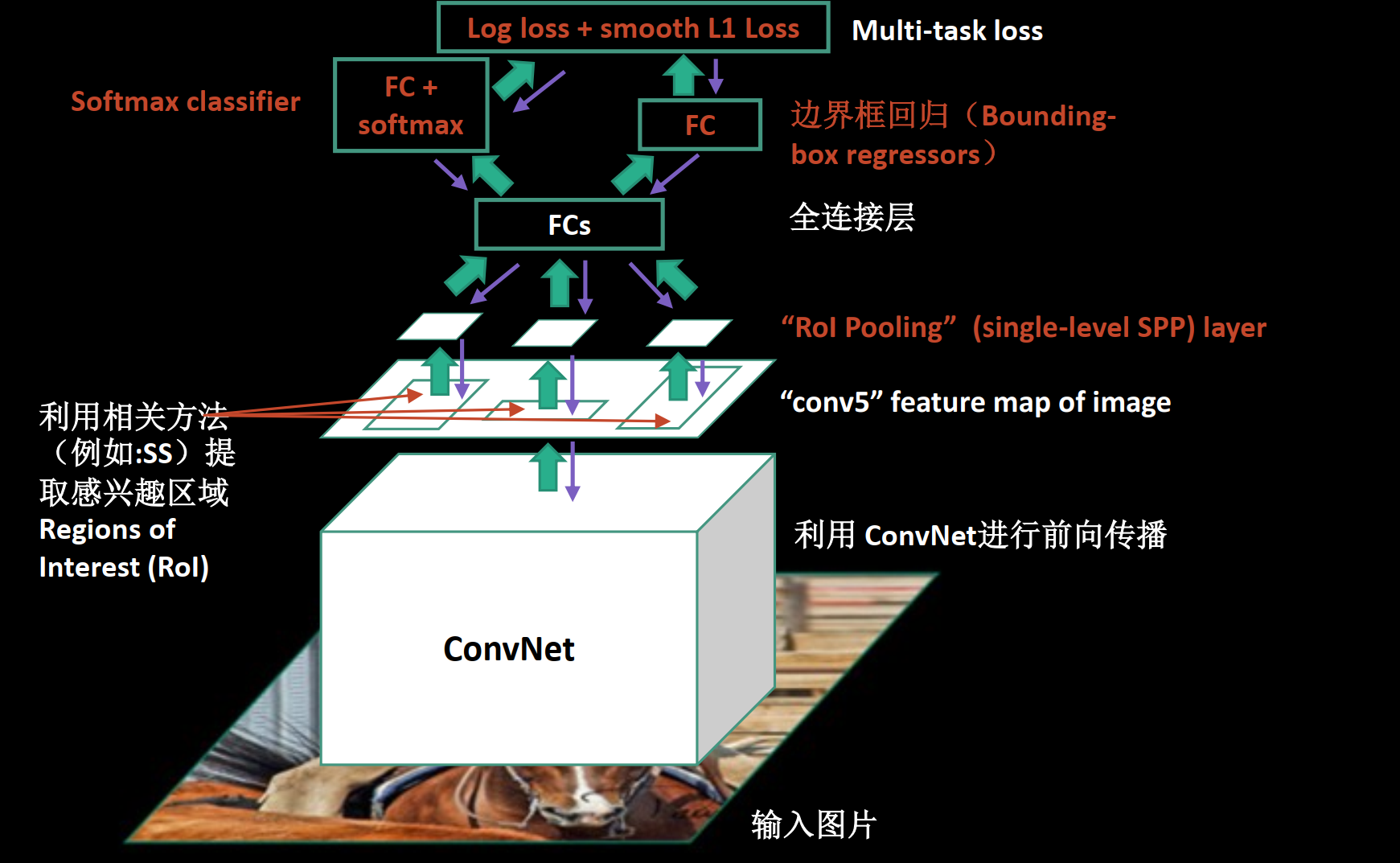
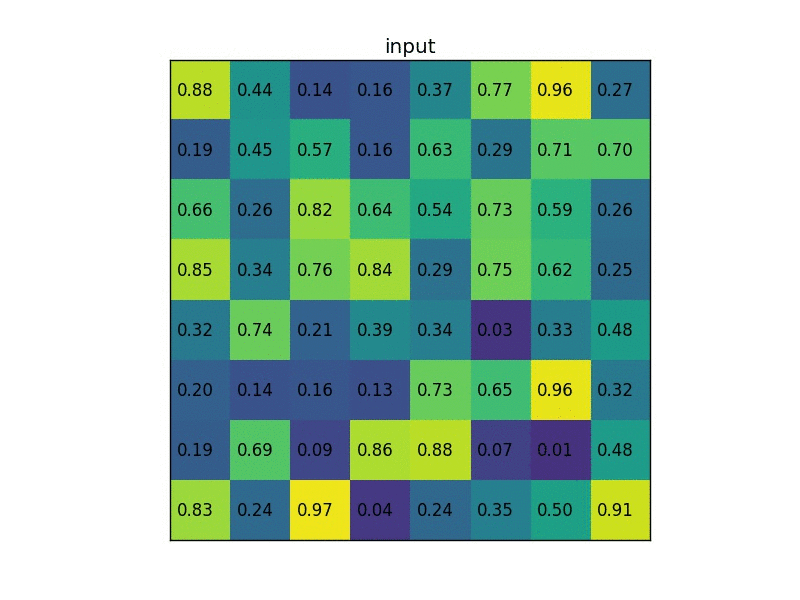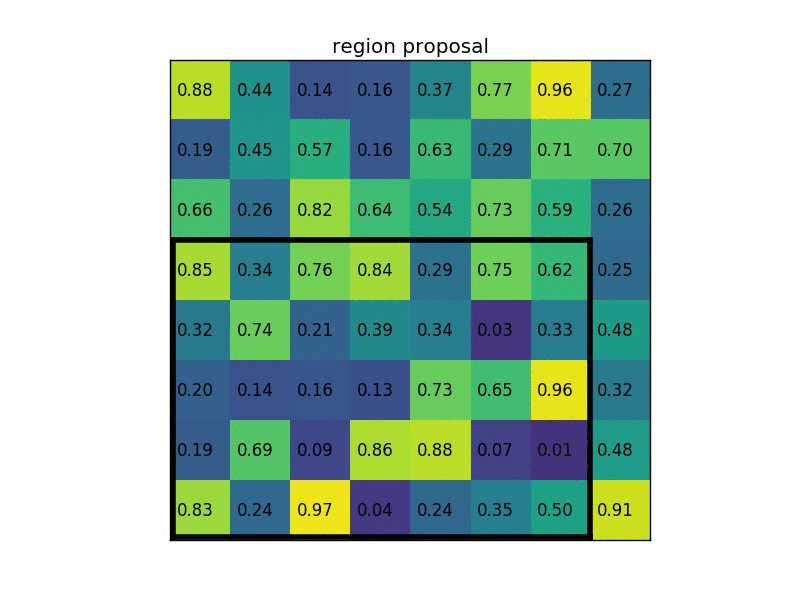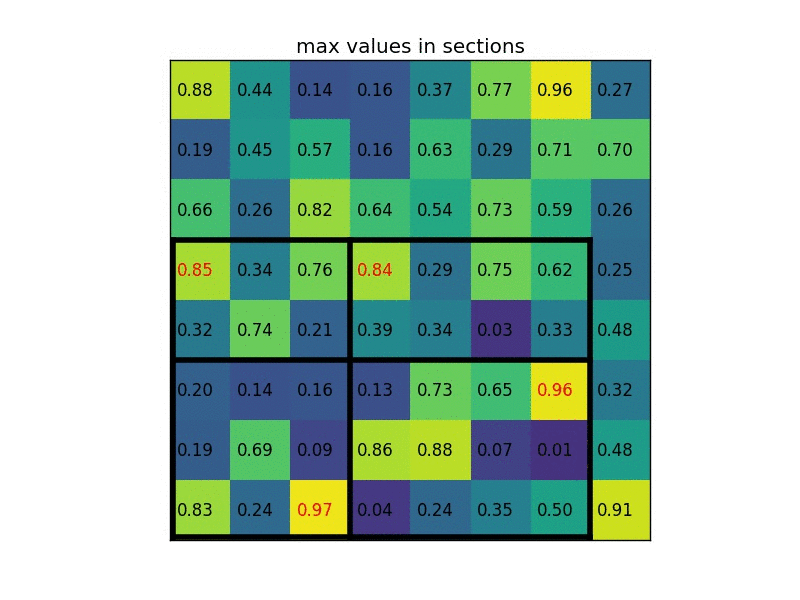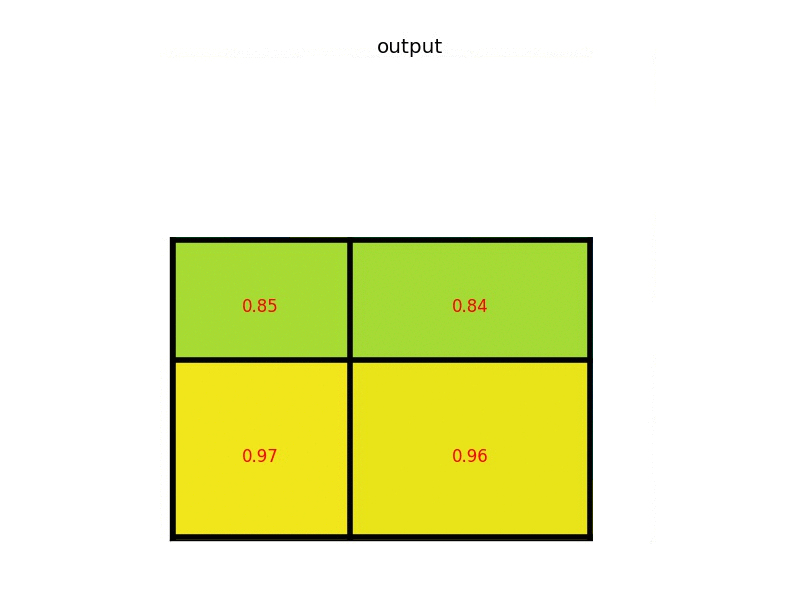
- 输入一张图和一堆bounding boxes(由SS产生)
- 产生卷积特征图
- 对于每一个box,通过ROI Pooling层得到一个定长特征向量
- 输入:(1)K+1类别概率 ,(2)回归框位置
贡献:

-
提出了ROI Pooling,可以看做是单层SPP-net(single-level SPP)
简单地说就是把一张图差不多等分成很多份,从每一份中取一个像素,拼凑起来就得到相同长度的向量。窗口大小 w i n = ⌈ a / n ⌉ win = ⌈a/n⌉ win=⌈a/n⌉,步长 s t r i d e = ⌊ a / n ⌋ stride = ⌊a/n⌋ stride=⌊a/n⌋
RoI pooling的梯度回传。RoI有重叠,会有一些像素重叠。非重叠的区域是maxpooling类似的梯度回传,如果是重叠的:多个区域的偏导之和。假设有2个区域r0和r1。r0经过roi pooling后假设是2×2的。pooling之后是2×2的输出。重合了1个像素。对于r0来说是贡献到了右下角,r1贡献到了左上角。梯度回传的时候还有更深的层回传梯度。知道了2×2的梯度往回传的时候,算大图的梯度的时候,是两个小图梯度的相加。
-
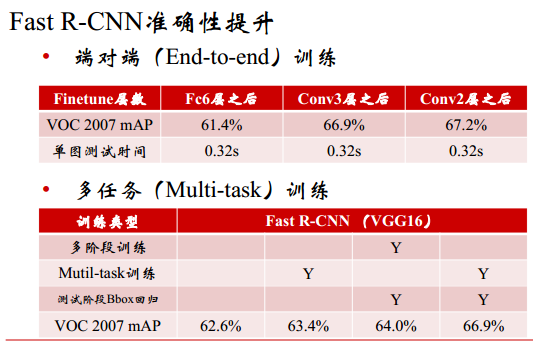
引入多任务学习,将多个步骤整合到一个模型中。
- SVM+Regressor -> Multitask Loss(SoftMax + Regressor)
- L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u > 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u>1]L_loc(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u>1]Lloc(tu,v),背景的时候,u是0
- 其中分类损失 L c l s = − l o g p u L_{cls}=-logp_u Lcls=−logpu
-
边框回归:Loc
即对于x,y,w,h,边框回归的损失都是smoothL1损失,t是预测的,v是真实的。u指示的是,背景的边框回归忽略掉不计算。 t k = ( t x , t y , t w , t h ) t^k=(t_x,t_y,t_w,t_h) tk=(tx,ty,tw,th)。smoothL1损失相较于L2损失的好处是当绝对值对于1值,梯度为1,梯度不会过大,而绝对值小于1时,梯度为x,而且在x=1处是连续可导的。
-
全连接层加速:Truncated SVD
W≈U
将一个大的全连接层分解层两个小的全连接层
时间复杂度:O(uv)→O(t(u+v))
-
多任务学习的优势
-
抛弃SVM vs 使用Softmax
- 为什么不使用SVM了:训练使用难样本挖掘以使网络获得高判别力,从而精准定位目标
-
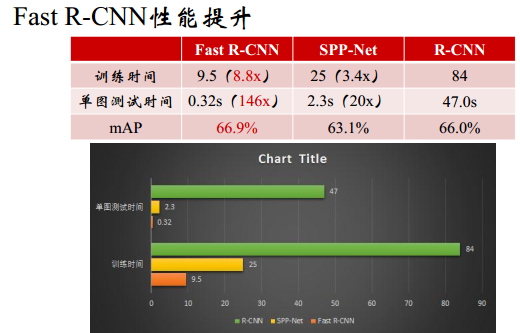
结果比R-CNN好一些,不需要磁盘存储


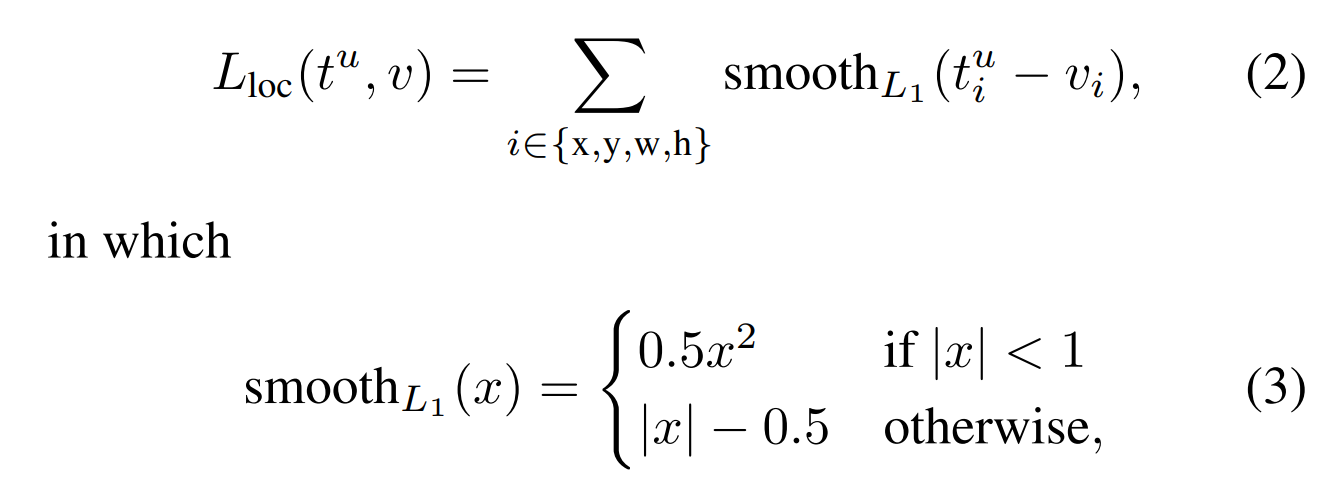
缺点:
- Fast R-CNN让然需要专门的候选窗口生成模块
- 候选框提取方法仍是SS:CPU,2s/图,速度慢
- 其他方法:EdgeBox,GPU,0.2S/图
Fast R-CNN的RegionProposal是在feature map之后做的,这样可以不用对所有的区域进行单独的CNN Forward步骤。

- 分类损失:交叉熵损失
- 回归损失:预测值和真实值差异小于1的话,让损失小一些。如果差异比较大,让损失大一些
faster rcnn: https://blog.csdn.net/hancoder/article/details/89922964
后续FPN等欢迎去本人博客查看:https://blog.csdn.net/hancoder/
参考:
B站视频:python tensorflow图像处理
https://zhuanlan.zhihu.com/p/31427164 #解读非常好,点进去看专栏
www.zhuanzhi.ai #专知-深度学习:算法到实践
https://cloud.tencent.com/developer/article/1015122
https://blog.csdn.net/wakojosin/article/details/79363224 #RPN
https://blog.csdn.net/mllearnertj/article/details/53709766 #RPN
https://blog.csdn.net/WZZ18191171661/article/details/79439212
http://www.cnblogs.com/zf-blog/p/7286405.html #rpn代码理解
https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/
https://blog.csdn.net/v1_vivian/article/details/73275259
https://blog.csdn.net/xiamentingtao/article/details/78598027