RegExp
正则表达式的作用:匹配特殊字符或有特殊搭配原则的字符
两种创建方式
如果需要创建一个全局匹配字符串‘abc’的正则表达式,可以用下面两种方式
- 直接量,两个斜线间是需要匹配的字符串,斜线后可添加修饰符
var reg = /abc/g;
- new RegExp(),参数1为需要匹配的字符串,参数2为修饰符
var reg = new RegExp('abc','g');
三个修饰符
| 修饰符 | 匹配规则 |
|---|---|
| i | 忽略大小写 |
| g | 全局匹配 |
| m | 多行匹配 |
修饰符没有顺序之分,多行匹配这里举个例子,如果需要匹配多行以a开头的字符,则需要添加m修饰符,这里可以匹配到3个a
var str = 'abc\nabc\nabc';
var reg = /^a/mg;
str.match(reg); //(3) ["a", "a", "a"]
表达式
| 表达式 | 描述 |
|---|---|
| [abc] | 查找方括号之间的任何字符。 |
| [^abc] | 查找任何不在方括号之间的字符。 |
| [0-9] | 查找任何从 0 至 9 的数字。 |
| (x|y) | 查找由 | 分隔的任何选项。 |
中括号匹配一个字符,中括号之间的字符是一个范围
^在表达式里代表不是
小括号匹配完整的一组字符,匹配多组字符时可以用“|”分隔,代表任取其一
举个例子,如需匹配字符串“abc”或“bcd”

元字符
\w === [0-9A-z_]
\W === [^\w]
\d === [0-9]
\D === [^\d]
\s === [\t\f\n\r\v]
\S === [^\s]
\b === 单词边界
\B === 非单词边界
. === [^\r\n]
\uxxxx === 以十六进制数 xxxx 规定的 Unicode 字符
单词边界其实是个位置,有三点规则
1)\w和\W之间的位置
2)^和\w之间的位置
3)\w和$之间的位置
这里举个例子,将字符“c”+单词边界(后面是个边界的字符“c”),替换成字符“a”

量词
| 量词 | 描述 |
|---|---|
| n+ | 包含至少一个 n 的字符串 |
| n* | 包含零个或多个 n 的字符串 |
| n? | 包含零个或一个 n 的字符串 |
| n{X} | 包含 X 个 n 的序列的字符串 |
| n{X,Y} | 包含 X 至 Y 个 n 的序列的字符串 |
| n{X,} | 包含至少 X 个 n 的序列的字符串 |
位置
| 位置 | 描述 |
|---|---|
| $ | 匹配结尾位置 |
| ^ | 匹配开头位置 |
| (?=n) | 匹配任何其后紧接指定字符串 n 的位置 |
| (?!n) | 匹配任何其后没有紧接指定字符串 n 的位置 |
| (?<=n) | 匹配任何其前面紧接指定字符串 n 的位置 |
| (?<!n) | 匹配任何其前面没有紧接指定字符串 n 的位置 |
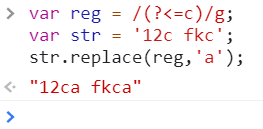
这里用 (?<=n) 举个例子,将前面是字符“c”的位置替换成字符“a”
RegExp 对象属性
| 属性 | 描述 |
|---|---|
| global | RegExp 对象是否具有标志 g。 |
| ignoreCase | RegExp 对象是否具有标志 i。 |
| multiline | RegExp 对象是否具有标志 m。 |
| source | 正则表达式的源文本。 |
| lastIndex | 一个整数,标示开始下一次匹配的字符位置。与exec方法搭配使用,介绍exec方法时再细说 |
RegExp 对象方法
- test
检索字符串中是否有符合某种规则的值,返回true或false。
- exec
检索字符串中符合某种规则的值,返回一个数组,并确定其位置(index)。数组的第 0 个元素是与正则表达式相匹配的文本(每次只返回一个匹配文本),第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExpObject 的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
匹配文本的最后一个字符的下一个位置会存储在lastIndex属性中,下次执行exec方法时,会从lastIndex位置开始检索。也就是说可以通过反复调用 exec() 方法来遍历字符串中的所有匹配文本。
当 exec() 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。

var reg = /(a)(b)/g;
var str = 'abcabcabc';
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //(3) ["ab", "a", "b", index: 0, input: "abcabcabc", groups: undefined]
console.log(reg.lastIndex); //2
console.log(reg.exec(str)); //(3) ["ab", "a", "b", index: 3, input: "abcabcabc", groups: undefined]
console.log(reg.lastIndex); //5
console.log(reg.exec(str)); //(3) ["ab", "a", "b", index: 6, input: "abcabcabc", groups: undefined]
console.log(reg.lastIndex); //8
console.log(reg.exec(str)); //null
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //(3) ["ab", "a", "b", index: 0, input: "abcabcabc", groups: undefined]
支持正则表达式的 String 对象的方法
- search
找到第一个匹配文本的索引
var reg = /aa/g;
var str = 'baabaabaa';
str.search(reg);//1
- match
找到正则表达式的匹配
var reg = /aa/g;
var str = 'baabaabaa';
str.match(reg);//(3) ["aa", "aa", "aa"]
- replace
替换与正则表达式匹配的文本,第一个参数是正则表达式,第二个参数可以是字符串或者回调函数
这里第二个参数用字符串举例,回调函数的例子在后面介绍
var reg = /aa/g;
var str = 'baabaabaa';
str.replace(reg,'cc');//bccbccbcc
- split
把字符串分割为字符串数组
var reg = /aa/g;
var str = 'baabaabaa';
str.split(reg);//(4) ["b", "b", "b", ""]
小括号的作用
小括号的作用是提供了分组,括号内的正则是一个整体,即提供子表达式,便于我们引用它。
在正则表达式中可以使用“\1”引用第一个小括号匹配到的文本,用“\2”引用第二个小括号匹配到的文本,以此类推。
如果需要匹配日期,日期分隔符可以是“-/.”这三个中的任意一个,但前后要保持一致,可以使用小括号分组并使用“\1”来引用小括号匹配到的文本,这里的日期用简单的8位数字代替
var reg = /\d{4}([-/.])\d{2}\1\d{2}/g;
var str1 = '2022-03/09';
var str2 = '2022-03-09';
console.log(reg.test(str1)); //false
console.log(reg.test(str2)); //true
通过js也可以引用分组内容,通过“$1”引用第一个小括号匹配到的文本,“$2”引用第二个小括号匹配到的文本,以此类推。
var reg = /(\d{4})([-/.])(\d{2})\2(\d{2})/g;
var str = '2022-03-09';
reg.test(str);
console.log(RegExp.$1);//2022
console.log(RegExp.$2);//-
console.log(RegExp.$3);//03
console.log(RegExp.$4);//09
在数据替换时,有下面三种写法
var reg = /(\d{4})([-/.])(\d{2})\2(\d{2})/g;
var str = '2022-03-09';
str.replace(reg,'$3/$4/$1');//03/09/2022
str.replace(reg,function(){
return RegExp.$3 + '/' + RegExp.$4 + '/' + RegExp.$1
});//03/09/2022
str.replace(reg,function($0,$1,$2,$3,$4){
return $3 + '/' + $4 + '/' + $1
});//03/09/2022
如果小括号后有量词,则分组匹配的是最后一次的匹配
var reg = /(\d)+-(\d)+/g;
var str = '21-03-09';
reg.test(str);
console.log(RegExp.$1);//1
console.log(RegExp.$2);//3
如果想要括号不被引用,可以使用非捕获性括号(?:n)
var reg = /(?:\d)+-(\d)+/g;
var str = '21-03-09';
reg.test(str);
console.log(RegExp.$1);//3
惰性匹配
正则匹配是采用的是贪婪匹配方式,即尽可能多的匹配
var reg = /a+/g;
var str = 'aaaaa';
str.match(reg);//["aaaaa"]
而惰性匹配是尽可能少的匹配,如果需要惰性匹配,则在量词后面加上“?”
var reg = /a+?/g;
var str = 'aaaaa';
str.match(reg);//(5) ["a", "a", "a", "a", "a"]
替换成$
由于$具有特殊含义,如果需要将匹配文本替换成$,可以用$$,相当于把$转义了
var reg = /aa/g;
var str = 'aabbaabb';
str.replace(reg,'$$');//$bb$bb