下载hadoop3.0.0
https://archive.apache.org/dist/hadoop/core/hadoop-3.0.0/
下载spark3.5.3
Index of /dist/spark/spark-3.5.0
添加环境变量
HADOOP_HOME
SPARK_HOME
PATH中添加%HADOOP_HOME%\bin,%HADOOP_HOME%\sbin,
%SPARK_HOME%\bin,%SPARK_HOME%\sbin,
启动master
bin\spark-class org.apache.spark.deploy.master.Master
启动worker
bin\spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
有可能需要将localhost换成主机名
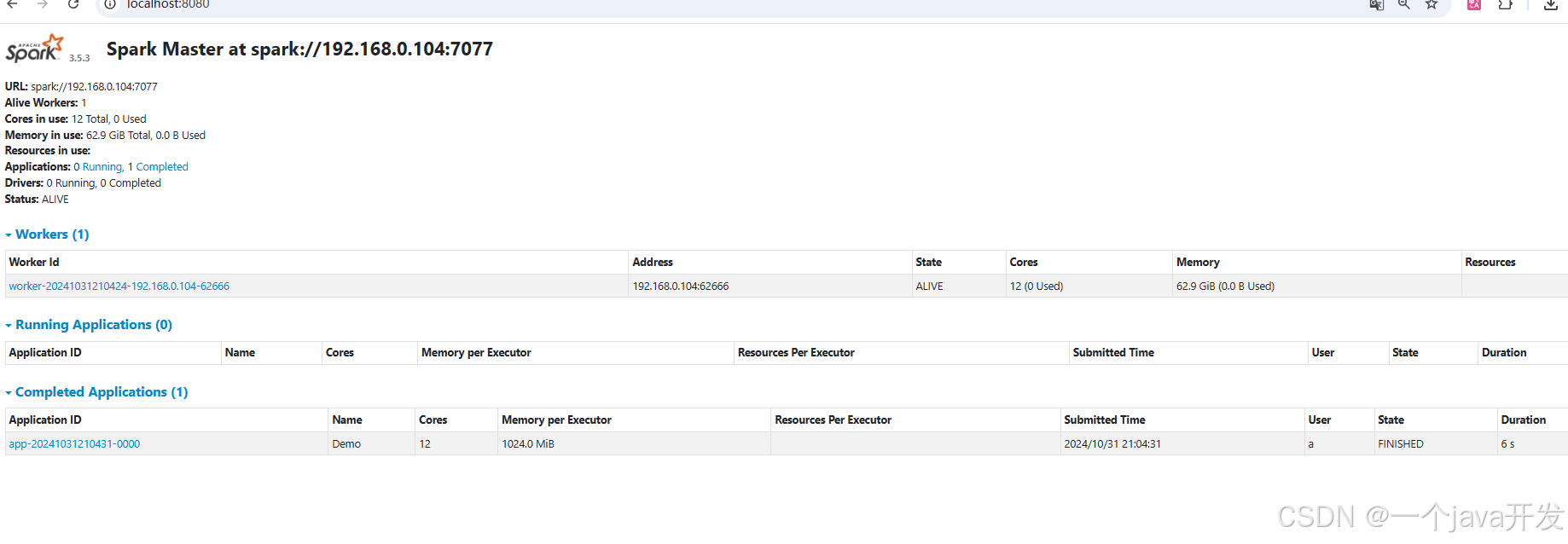
查看master UI
localhost:8080
安装python3.10
创建虚拟环境安装pyspark,
如果pip install pyspark报错了,就直接拷贝spark里自带的
将spark-3.5.3-bin-hadoop3\python\pyspark拷贝到python项目所用的解释器的LIB里
基于python3.10
编写测试代码
提交到集群执行
# Configure Python interpreter for PySpark
import os
import time
from pyspark.sql import SparkSession
os.environ['PYSPARK_PYTHON'] = "python"
if __name__ == '__main__':
# Initialize SparkSession
spark = SparkSession.builder.appName("Demo").master('spark://coderun:7077').getOrCreate()
spark.sparkContext.setLogLevel("DEBUG")
# Create sample data
data = [
("Zhang San", 16, 85, 90, 78, "Beijing"),
("Zhang San", 16, 85, 90, 78, "Beijing"),
("Li Si", 17, 88, 76, 92, "Shanghai"),
("Wang Wu", 15, 95, 89, 84, "Guangzhou"),
("Wang Wu", 156, 95, 89, 84, "Guangzhou"),
("Wang Wu", 158, 95, 89, 84, "Guangzhou")
]
# Define DataFrame column names
columns = ["Name", "Age", "Chinese", "Math", "English", "Home Address"]
# Create DataFrame
df = spark.createDataFrame(data, columns)
# Show original DataFrame
print("Original DataFrame:")
# df.show()
# Register DataFrame as a temporary view
df.createOrReplaceTempView("students")
# Use Spark SQL to filter students with age greater than 15
result_df = spark.sql("SELECT name,sum(Age) FROM students WHERE Age > 15 group by name ")
# Show transformed DataFrame
print("Transformed DataFrame ")
result_df.show()
# time.sleep(200)
# spark.stop()