
Thread 类及常见的用法
Thread 就是在Java中,线程的代言人.系统中的一个线程,就对应到Java中的一个Thread对象,围绕线程的各种操作,都是通过 Thread来展开的

第一个方法就是创建一个类,然后让这个类继承Thread这个类.
第二个就是需要Runnable接口的写法
第三个方法,我们可以对线程进行命名
在Java中,Java官方给线程命名格式:
Thread-0 1 2 3...
但是这种命名方式,可读性比较差.如果一个程序中有很多个线程,且功能各不相同,我们通过官方的这种命名方式是无法知道这个线程究竟实现了什么功能的.
但我们自己命名的时候就可以起让我们容易看懂的名字
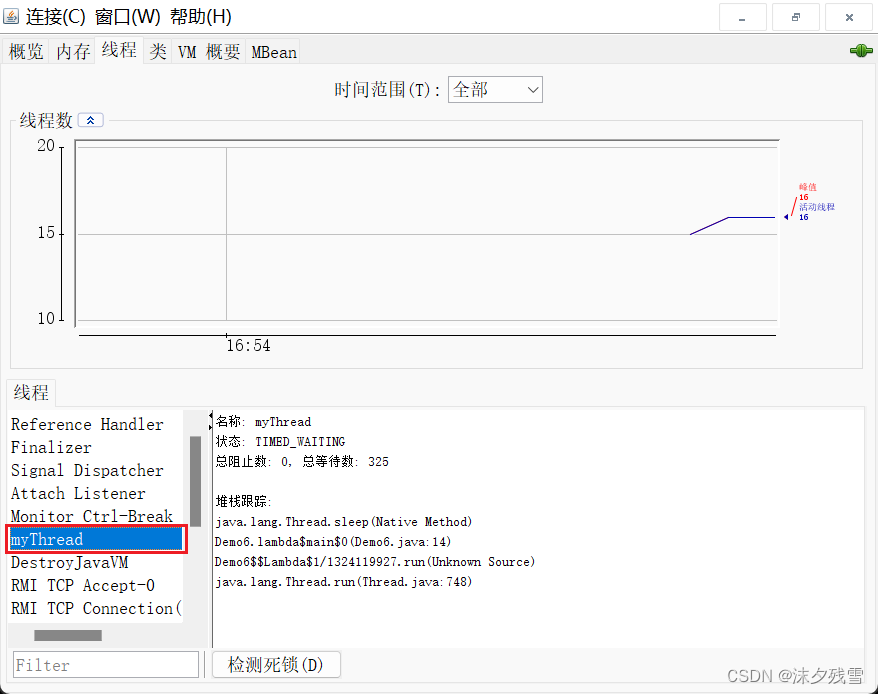
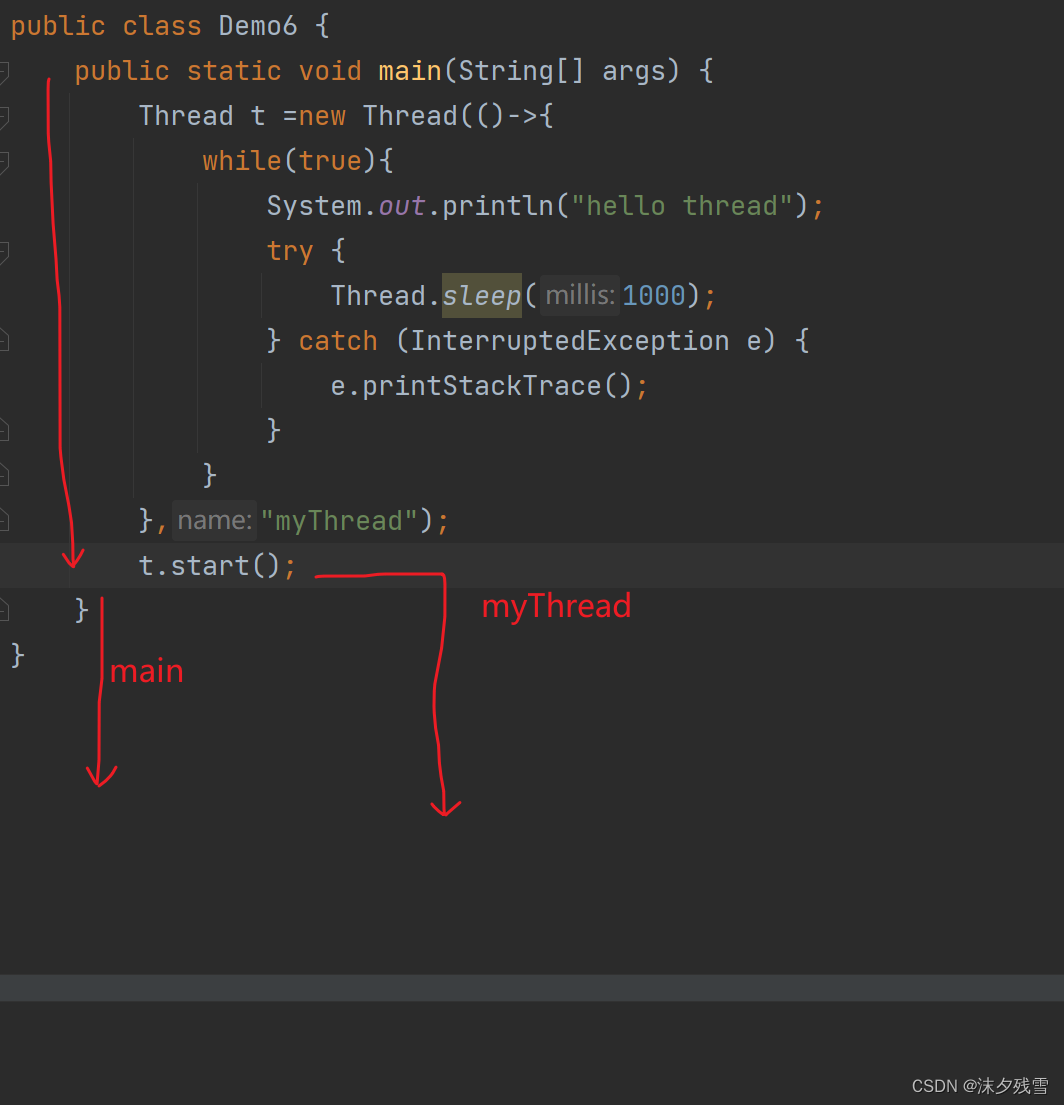
Thread的几个常见属性
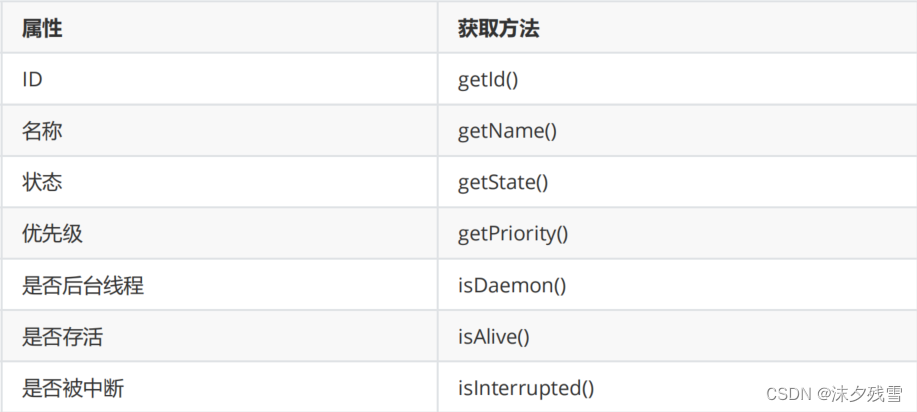
ID
线程的身份标识(在JVM这里给线程设定的标识)
一个人可以有好几个名字,一个线程也可以有好几个身份标识.
JVM会给一个身份标识
操作系统提供的pthread库(系统给程序员提供的操作线程的API),也有一个线程的身份标识.
内核里,针对线程读的pcb还有身份标识.
以上三种身份标识相互独立,而且Java只需要看JVM提供的身份标识即可
名称
前面说过了
状态
Java中的线程状态和操作系统中,有一定的差异
优先级
设置/获取优先级,作用其实不是很大,线程的调度,主要还是系统内核来负责的,在用户层面上是感知不到有多大差异,为什么?因为系统调度的速度实在是太快了,一般用默认的优先级就可以了.
是否后台线程
后台线程/守护线程:后台线程不影响程序结束.
前台线程:前台线程,会影响到进程结束,如果前台没执行完,进程是不会结束的.
如果一个进程中所有的前台线程都执行完了,退出了,此时即使存在后台线程仍然没执行完,也会随着进程一起退出
我们创建的线程默认是前台线程,通过setDaemon显示的设置成后台线程

此时 t 就是一个前台线程,只要线程 t 没有执行完毕,进程就不会停止.
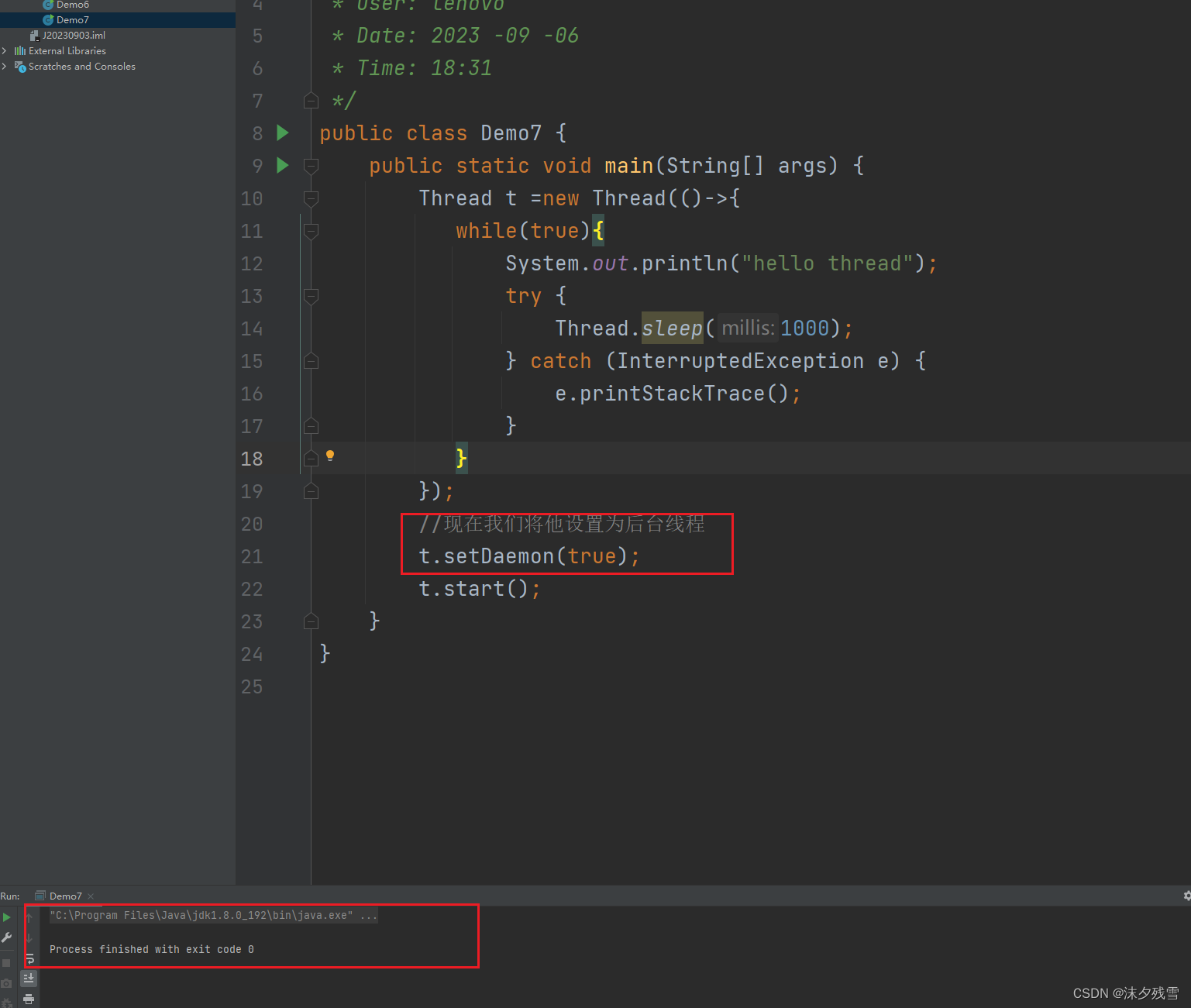
这里由于我们只有一个前台线程:main 所以当main执行结束之后,后台线程 t 也会瞬间结束
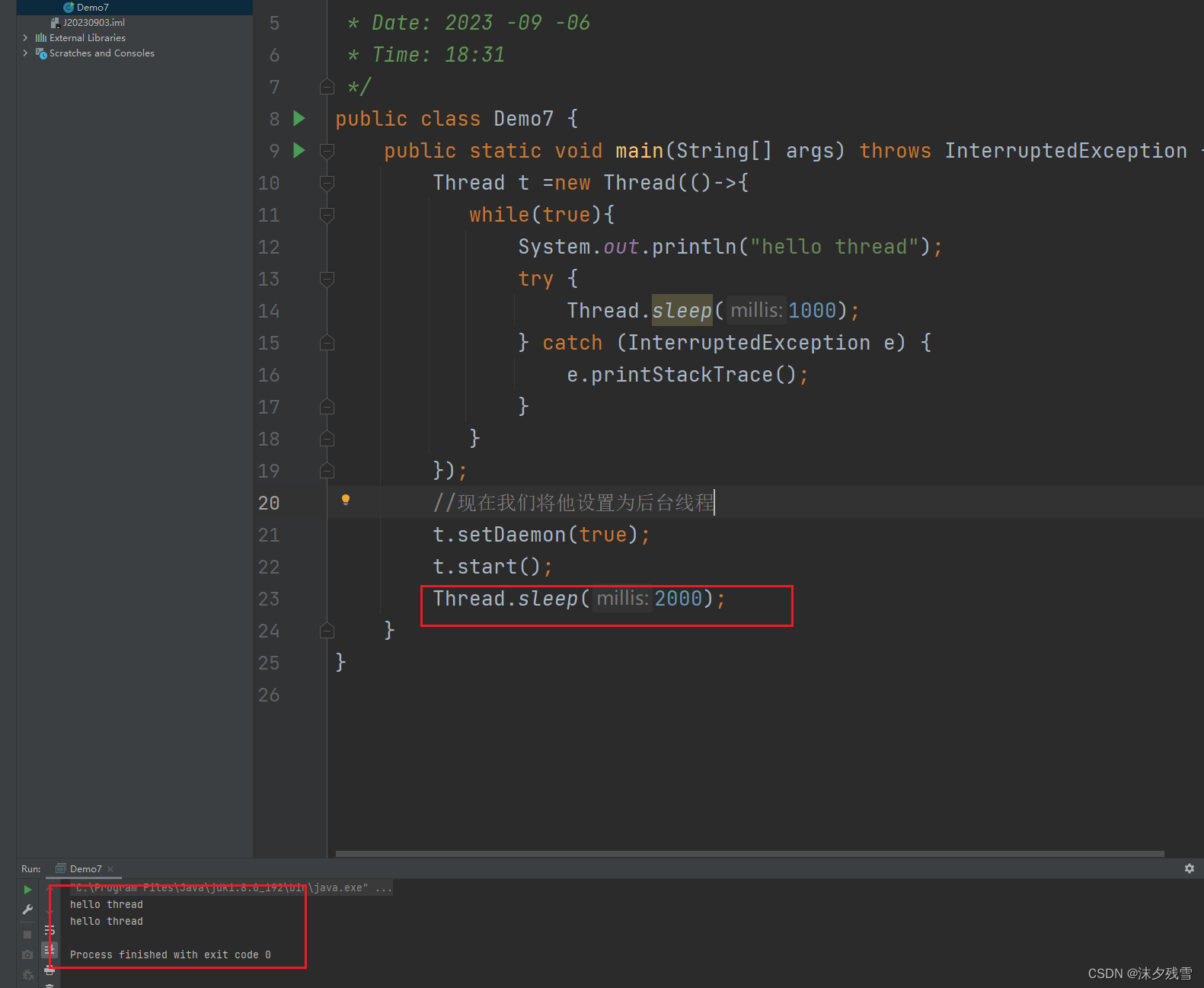
这样会更直观一点
是否存活
Thread 对象对应的线程(系统内核中)是否存活
Thread 对象的生命周期,并不是和系统中的线程完全一致的!!!
一般都是 Thread 对象先创建好,手动调用start后,内核才真正的创建出线程.
消亡的时候,可能是 Thread 对象先结束了生命周期(没有引用指向这个对象)也可能是 Thread 对象还在,内核中的线程把 run 执行完了,就结束了.
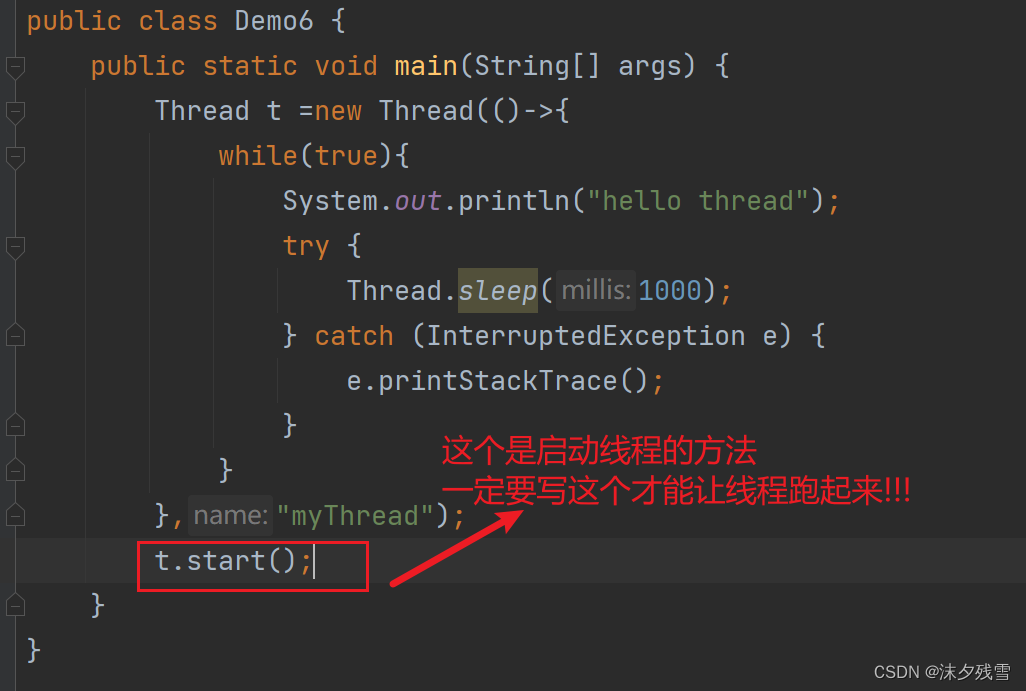
启动一个线程-start()
start方法:在系统中,真正创建出线程
(调用系统的API来完成线程创建工作)
1.创建出 PCB
2.把 PCB 加入到对应链表中
以上两个步骤都是由系统内核来完成的
什么是操作系统内核?
操作系统 = 内核 + 配套的程序
内核是一个系统最核心的功能
1.对下,管理好各种硬件设备
2.对上,给各种程序提供稳定的运行环境
start方法本身的执行是一瞬间就完成的,start方法只是告诉系统:你要创建个线程出来.调用 start 完毕之后,代码就会立即继续执行 start 后续的逻辑
终止一个线程
一个线程的 run 方法执行完毕,就算终止了(结束了),此处的终止线程,就是想办法让 run 能够尽快的去执行完毕
(正常情况下,不会出现 run 没执行完,线程就突然没了的情况,当然了,你要是强行给计算机断电,那就什么都没了)
那么我们怎么让 run 方法尽快结束呢?
1.程序员手动设置标志位
通过这个手动设置标志位,来让 run 尽快结束
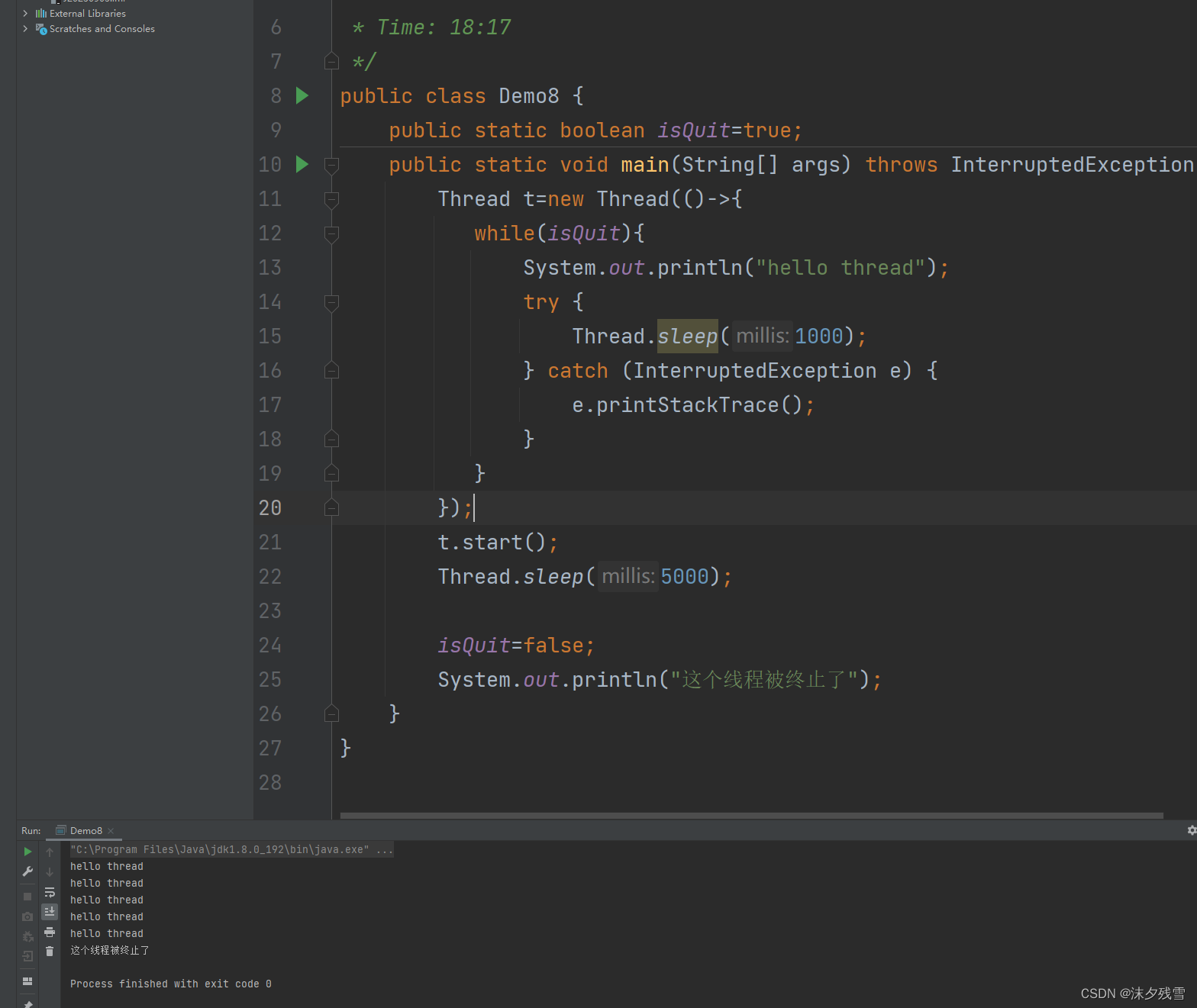
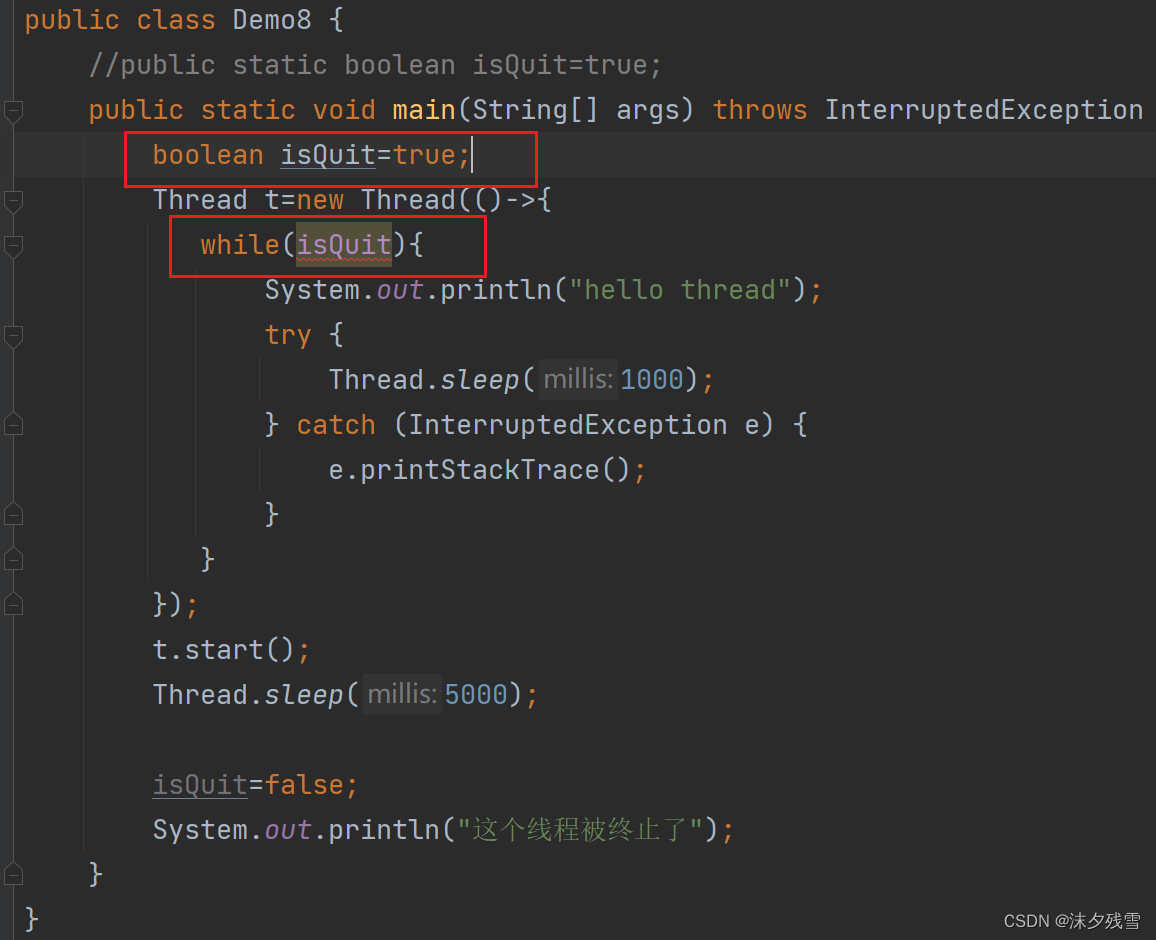
请问:为什么报错?
原因:变量捕获,lambda表达式,可以捕获到外面的变量,lambda表达式的执行时机是更靠后的,这就导致,后续真正执行lambda的时候,局部变量 isQuit 可能已经被销毁了(在上述代码中, isQuit 是main方法的局部变量,根据main方法的销毁而销毁)这里涉及到前面讲过的生命周期的知识.正因为会出现这样的情况,所以,lambda引入了"变量捕获"这样的机制,lambda内部看起来是在直接访问外部的变量,其实本质上是把外部的变量给复制了一份,到lambda里面(这样就可以解决刚才生命周期的问题了)
但是,lambda在捕获的时候有一个条件:要求捕获的变量是final的,或者至少事实是final的
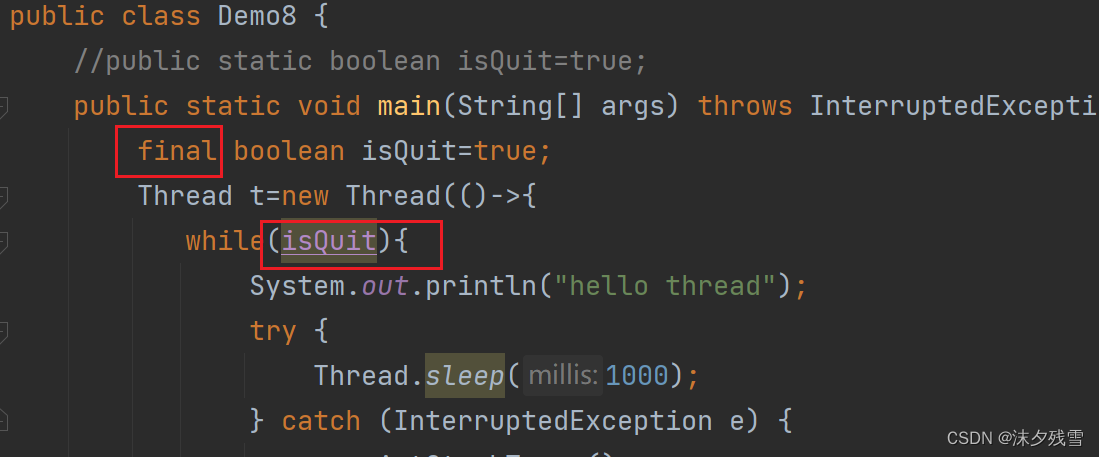
这里就不报错了
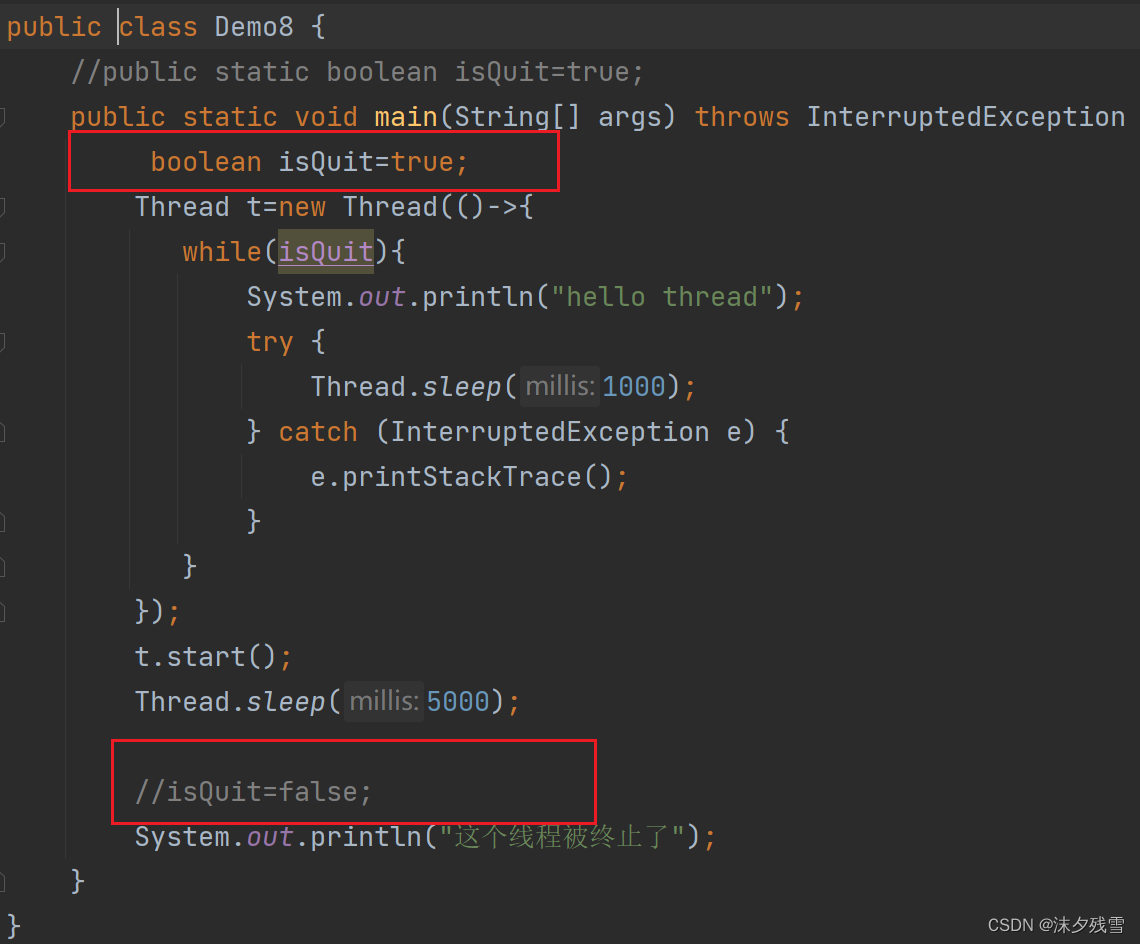
这里虽然没有报错,但是我们在代码中并没有去修改它,此时这就叫做事实final.
如果这个变量要进行修改,就不能进行变量捕获了
为什么Java这样设定?,实际上Java是通过复制的方式来实现"变量捕获"的,如果外面的代码要对这个变量进行修改,那么就会出现一个情况:外面的变量变了,里面的没变,代码就具有歧义
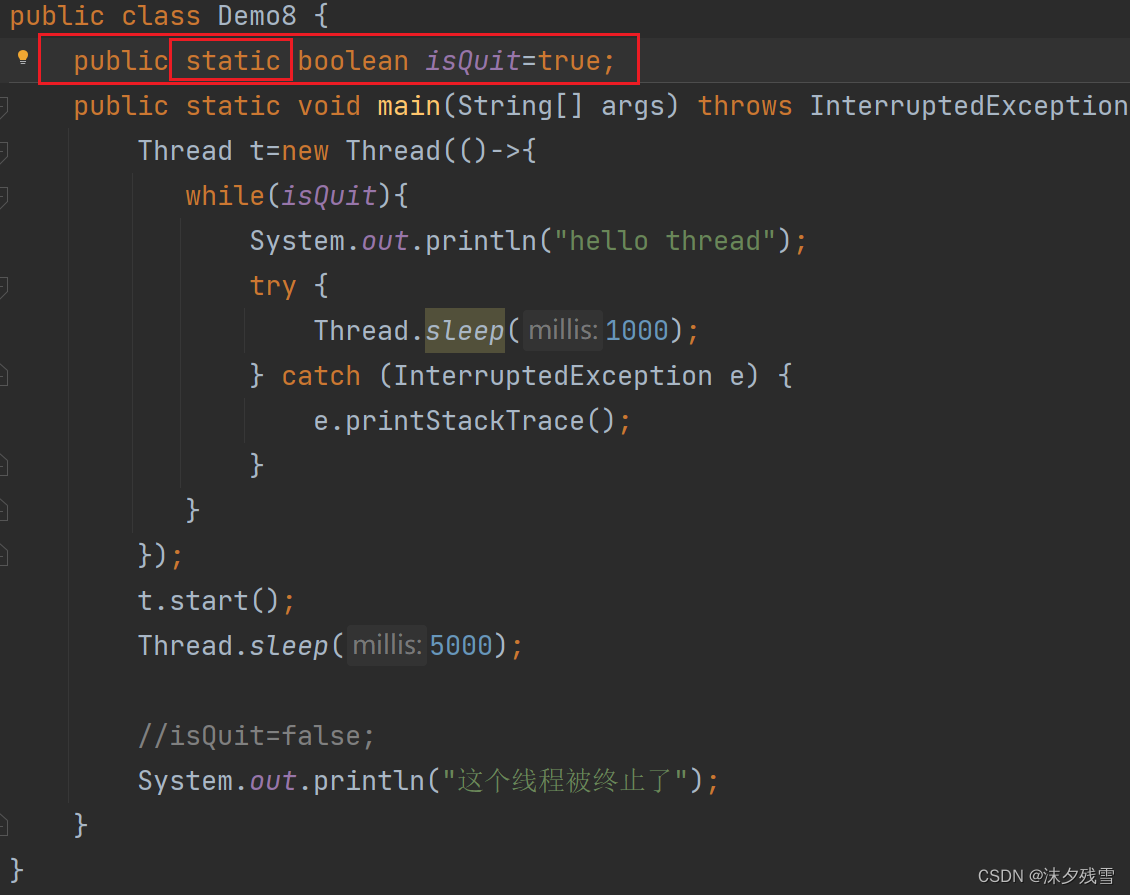
写作成员变量就不是触发变量捕获的逻辑了,而是"内部类访问外部类对象",这个本身就是OK的.
2. Thread 类,给我们提供好了线程的标志位,不用咱们手动去设置这个标志
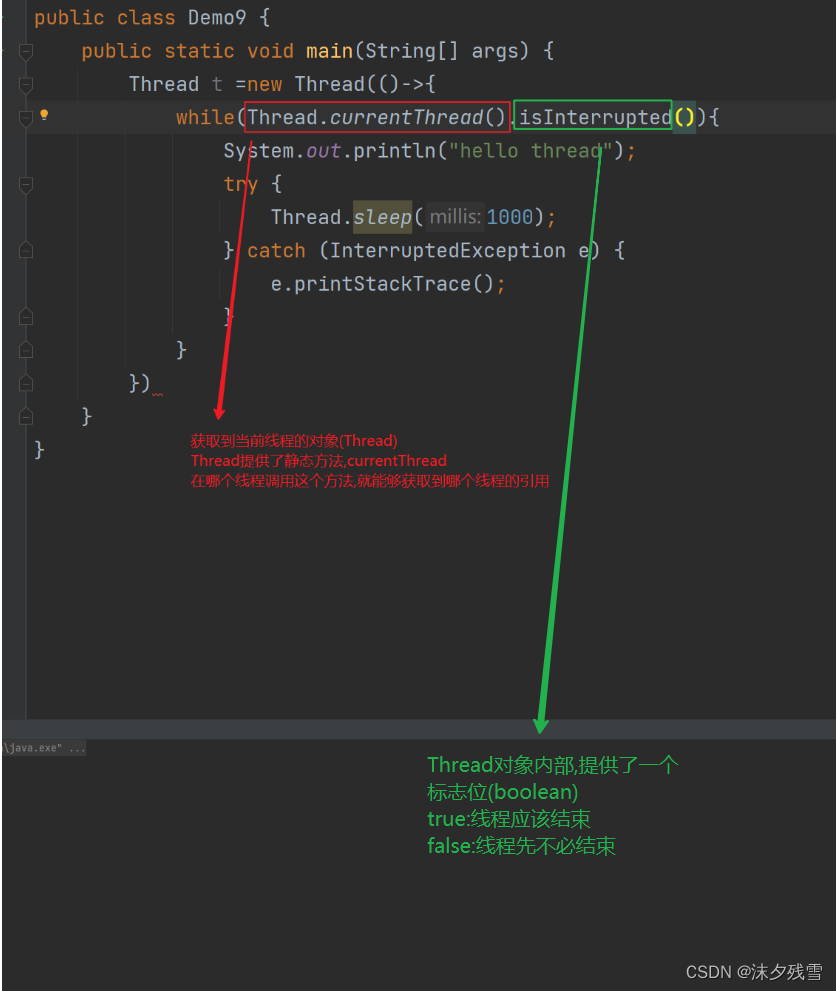
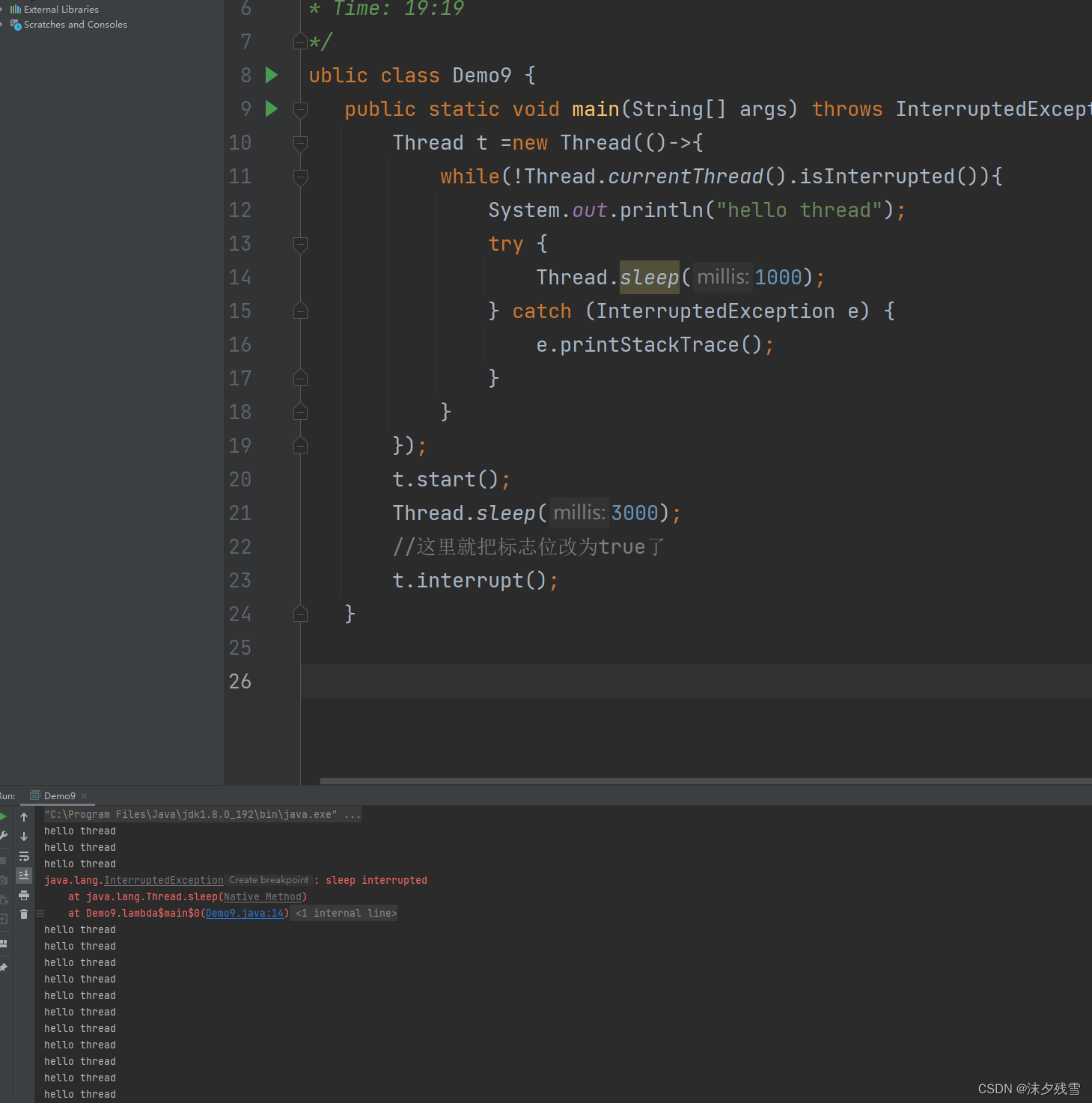
但是这个操作并没有让我们线程停止,反而报了一个异常

因此,线程正在sleep过程中,其他线程调用 interrupt 方法,就会强制使sleep抛出一个异常,sleep就被立刻唤醒了.(假设你设定sleep(1000),虽然只过去10ms,没到1000ms,也会被立刻唤醒)但是sleep在被唤醒的同时,会自动清除前面设置的标志位!!
那么我们怎么在这种情况下让线程结束
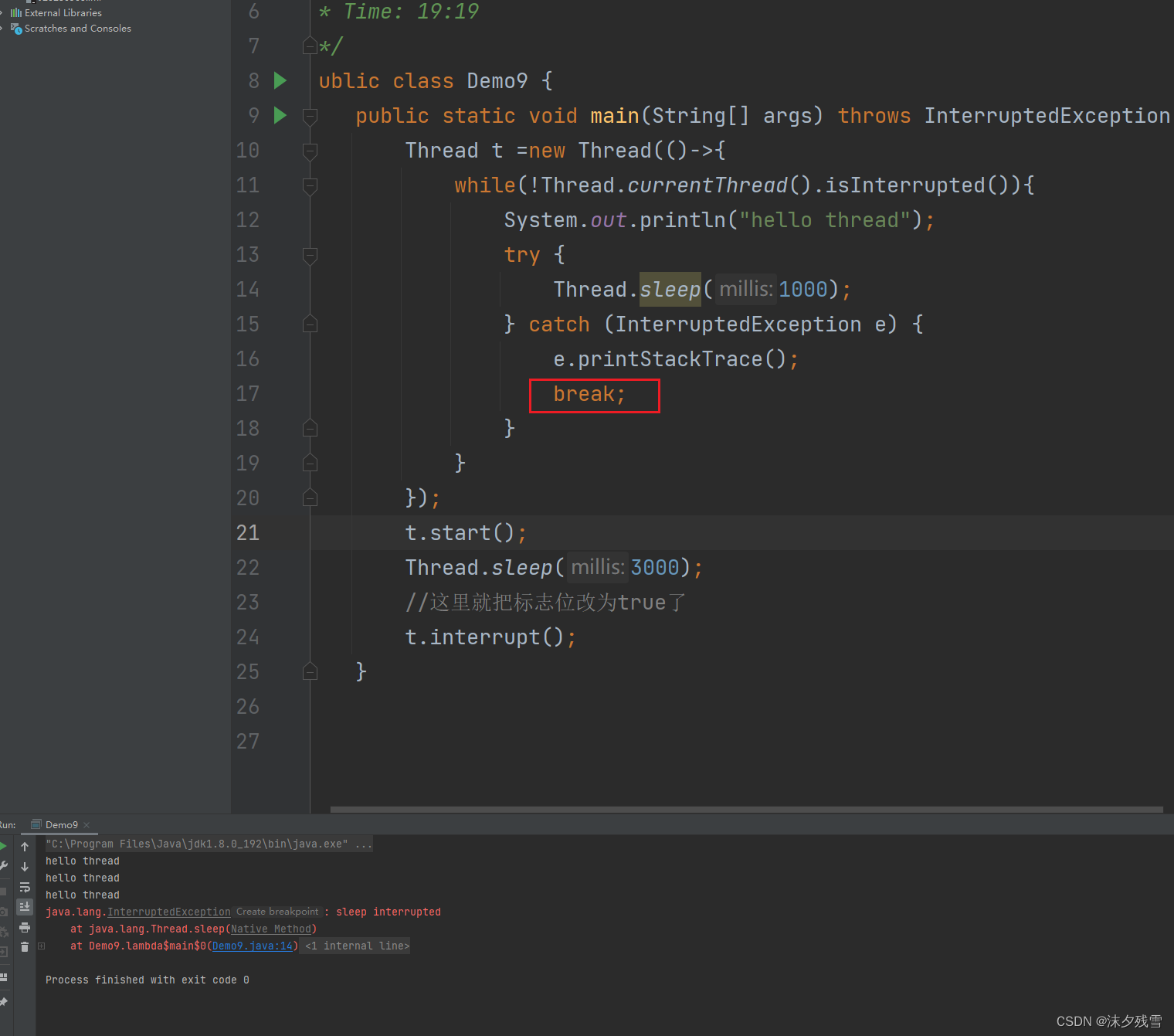

注释掉就可以了
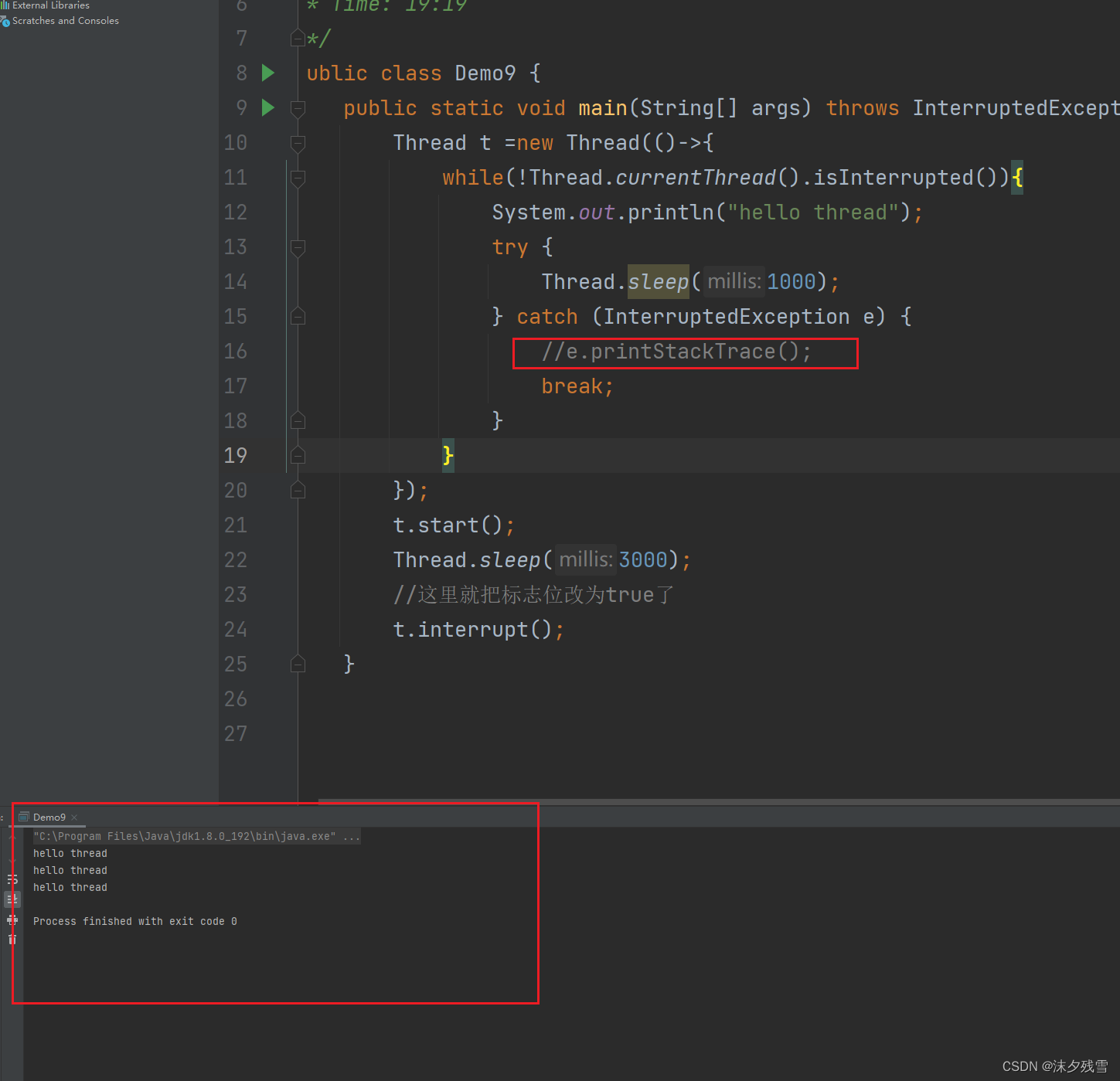
当sleep被唤醒之后,程序员接下来可以有以下几种操作方式
1.立即停止循环,立即结束进程(break)
2.继续做点别的事情(在catch中执行别的逻辑)
3.忽略终止请求,继续循环(原来的情况)
以上这几种处理方式,都是比较温和的方式,另一个线程提出请求,本线程自己决定,是否要终止.
更激进的做法,这边提出请求,立即结束,来不及本线程反应,完全不考虑本线程的实际情况,就可能会造成一些负面的影响
等待一个线程-join
多个线程之间是并发执行的,具体的执行过程都是由操作系统进行调度的!操作系统的调度线程的过程是"随机"的
因此我们无法确定,线程执行的先后顺序.
等待线程,就是一种规划线程结束顺序的手段.
假设,我们现在有A,B两个线程,我们希望B先结束,A后结束,此时就可以让A线程中调用B.join()的方法.此时,B线程还没有执行完,A线程就会进入"阻塞"状态(所谓的"阻塞"状态,实际上就是让代码停下来)就相当于给B留下了执行的时间.B执行完毕之后,A再从阻塞状态中恢复回来,并且继续往后执行
如果A执行到B.join()(实际上B.join()这个方法就是在等待B结束(也就是 run 方法执行完毕的时候))的时候,B就已经执行完了,A就不必阻塞了,直接往下执行就可以了
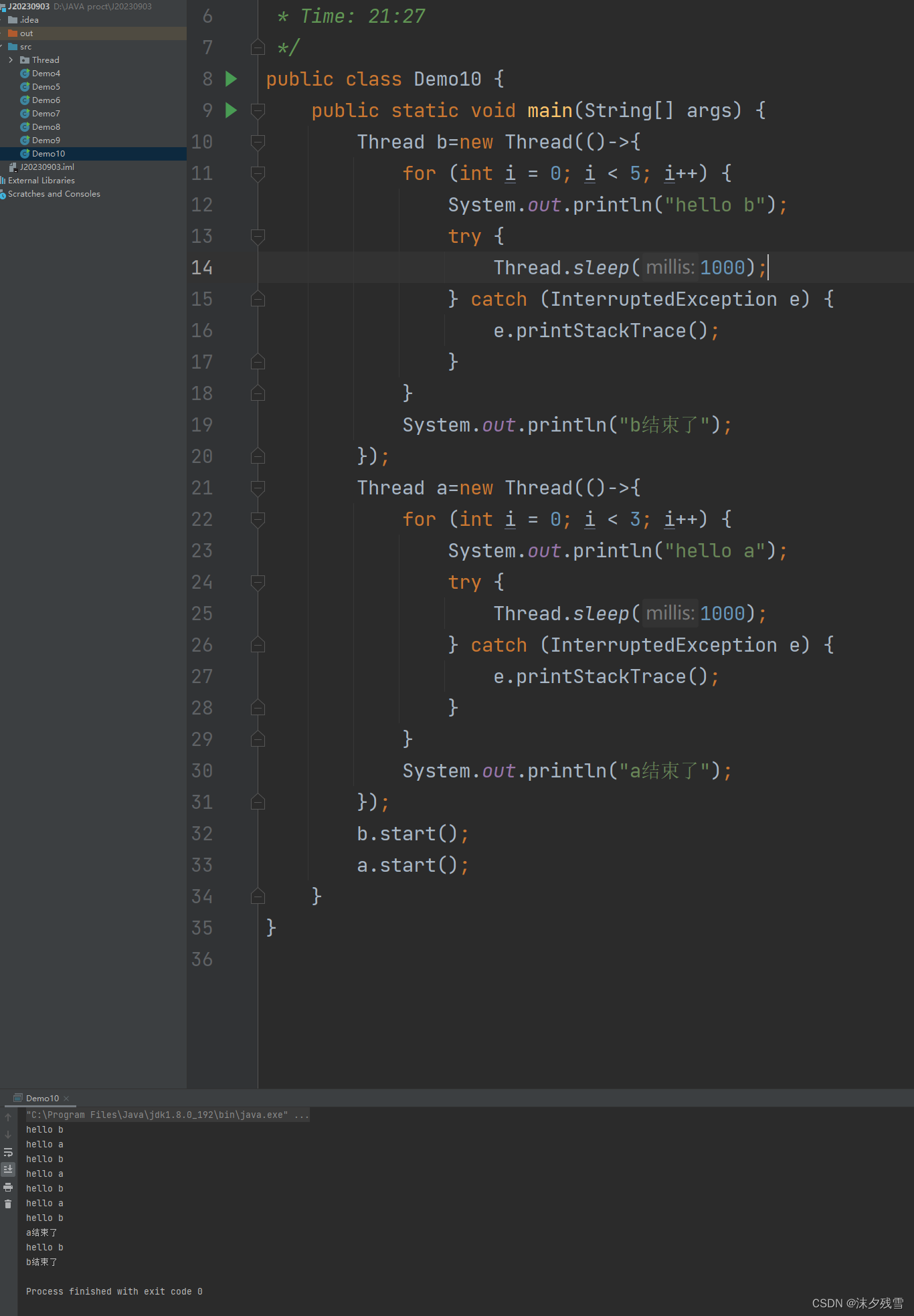
上述代码中,A打印3次,B打印5次,所以这里正常是A先结束,B后结束
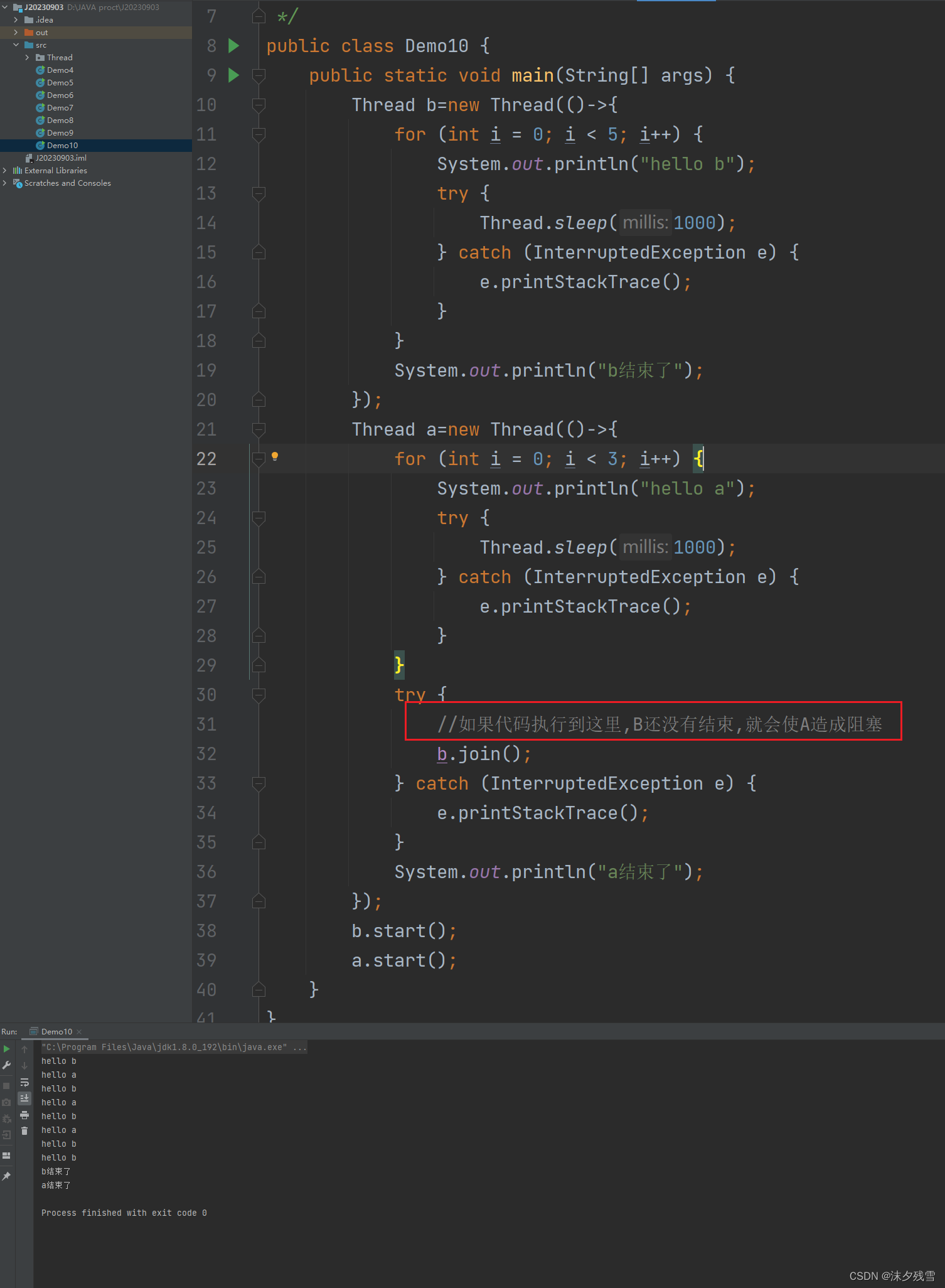
阻塞:让代码暂时不进行了.(该进程暂时不去CPU上参与调度)
sleep也能让线程阻塞,阻塞是有时间限制的.
join的阻塞,则是"死等""不见不散"
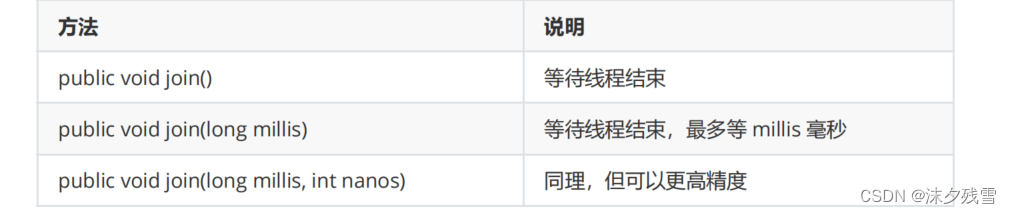
join的几种方法
 线程休眠(sleep)
线程休眠(sleep)
这个操作我们前面经常使用,这里就不做过多的介绍,只介绍一些重点.
sleep的参数是 ms 作为单位,但是sleep本身是存在一定误差的,设置sleep(1000),不一定就是精确的就休眠 1000ms (线程的调度也是需要时间的),sleep(1000)的意思是说该线程在1000ms之后,就恢复成"就绪状态"此时就可以随时去CPU上执行了但是不一定是马上就去指定.
因为sleep的特性,也诞生了一个特殊的技巧 sleep(0) 这个是让当前线程放弃CPU,由于sleep会使得当前线程从"运行状态"转为"阻塞状态",虽然这里休眠了0ms,但是这个操作可以使得当前的这个正在CPU上面执行的进程因sleep而去放弃占用CPU的资源从而进入排队状态,去准备下一轮的调度.由于sleep(0)比较抽象,所以在Java中,专门有一个方法:yield 效果和sleep(0)是一样的

