Spark电商数据分析
数据展示与分析
上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的 4 种行为:搜索,点击,下单,支付。数据规则如下:
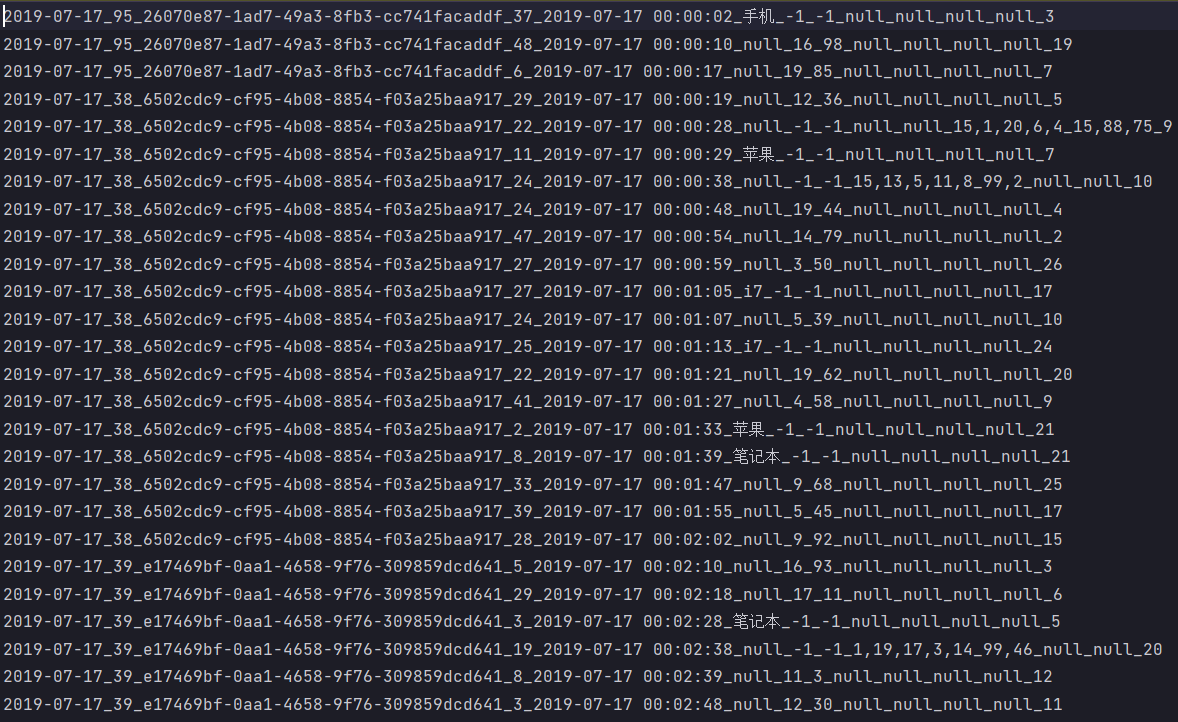
- ➢ 数据文件中每行数据采用下划线分隔数据
- ➢ 每一行数据表示用户的一次行为,这个行为只能是 4 种行为的一种
- ➢ 如果搜索关键字为 null,表示数据不是搜索数据
- ➢ 如果点击的品类 ID 和产品 ID 为-1,表示数据不是点击数据
- ➢ 针对于下单行为,一次可以下单多个商品,所以品类 ID 和产品 ID 可以是多个,id 之间采用逗号分隔,如果本次不是下单行为,则数据采用 null 表示
- ➢ 支付行为和下单行为类似
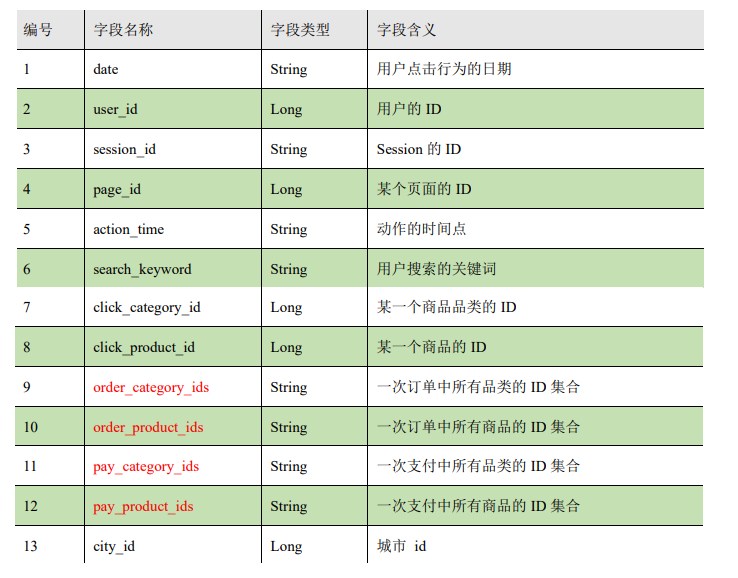
字段说明
需求:Top10 热门品类
需求分析
品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
我们先创建出SparkContext和读取数据文件,只适用于方法一到三
val spark = new SparkConf().setMaster("local[*]").setAppName("UserVisitAction")
val sc = new SparkContext(spark)
sc.setLogLevel("ERROR")
//读取文件
val sourceRDD = sc.textFile("data/user_visit_action.txt")
实现方法一
我们可以先分别求出点击量、订单量和支付量的总数,然后将三个数据合并,最后排序

@Test
def test01(): Unit = {
//统计品类的点击数量(商品品类,点击总量)
val clickRDD = sourceRDD.map(item => (item.split("_")(6), 1))
.filter(_._1 != "-1")
.reduceByKey(_ + _)
//统计品类的下单数(商品品类,下单总数)
val orderRDD = sourceRDD.map(_.split("_")(8))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//统计品类的支付数(商品品类,支付总数)
val payRDD = sourceRDD.map(_.split("_")(10))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//组合
/**
* 此时数据的格式
* (商品品类,点击量)
* (商品品类,订单量)
* (商品品类,支付量)
* 此时我们需要将上面的三个RDD给结合起来,使它变成下面的所示的样子
* (商品品类,(点击量,下单总数,支付总数)),然后对第二个的整体来进行排序即可
* cogroup = connect + group将相同的key的value给组合起来
*/
val cogroupgroup = clickRDD.cogroup(orderRDD, payRDD)
val result = cogroupgroup.mapValues {
case (clickIter, orderIter, payIter) => {
var clickcnt = 0
val iter1 = clickIter.iterator
if (iter1.hasNext) {
clickcnt = iter1.next()
}
var ordercnt = 0
val iter2 = orderIter.iterator
if (iter2.hasNext) {
ordercnt = iter2.next()
}
var paycnt = 0
val iter3 = payIter.iterator
if (iter3.hasNext) {
paycnt = iter3.next()
}
(clickcnt, ordercnt, paycnt)
}
}
result.sortBy(_._2, false).take(10).foreach(println(_))
}
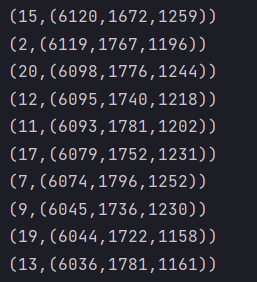
结果展示,由于后面只是方法不同,结果都是一样的,所以结果只展示一次
实现方法二
在方法一中,我们虽然实现了需求,但是因为使用了cogroup,就会导致数据处理量的暴增,那我们也没有办法不使用cogroup而完成?
解题思路

@Test
def test02(): Unit = {
sourceRDD.cache()
//统计品类的点击数量(商品品类,点击总量)
val clickRDD = sourceRDD.map(item => (item.split("_")(6), 1))
.filter(_._1 != "-1")
.reduceByKey(_ + _)
//统计品类的下单数(商品品类,下单总数)
val orderRDD = sourceRDD.map(_.split("_")(8))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//统计品类的支付数(商品品类,支付总数)
val payRDD = sourceRDD.map(_.split("_")(10))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//第一步:将数据转换变形
val rdd1 = clickRDD.map {
case (cid, cnt) => {
(cid, (cnt, 0, 0))
}
}
val rdd2 = orderRDD.map {
case (cid, cnt) => {
(cid, (0, cnt, 0))
}
}
val rdd3 = payRDD.map {
case (cid, cnt) => {
(cid, (0, 0, cnt))
}
}
//进行聚合操作
val result = rdd1.union(rdd2).union(rdd3)
result
.reduceByKey(
(v1, v2) => (v1._1 + v2._1, v1._2 + v2._2, v1._3 + v2._3)
)
.sortBy(_._2, false)
.take(10)
.foreach(println(_))
}
在方法二中,我们是使用union来代替category,减少了最后聚合是处理数据的压力
跳转顶部
实现方法三
在第二个方法中我们是将数据转换成(商品品类,(点击量,0,0))的方法来计算,但是在一开始求和时依旧有三个reducByKey,还是要经历shuffle,那么我们是否可以将数据一开始就转换成(商品品类,(点击量,0,0))的形式?
思路解析

@Test
def test03(): Unit = {
sourceRDD.cache()
/**
* 我们可以在第一步是就将数据的格式给转换成所需要的,
* 这样就是还有多次reduceByKey也没事,因为reduceByKey自带缓存(只有在相同的数据源中多次reduceByKey才有效)
*/
val result = sourceRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
//这就是点击
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
//这就是订单的操作
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
//这就是支付的操作
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
).reduceByKey(
(v1, v2) => (v1._1 + v2._1, v1._2 + v2._2, v1._3 + v2._3)
).sortBy(_._2, false)
.take(10)
.foreach(println(_))
}
实现方法四
虽然第三中的性能已经很高了,但是还是存在着shuffle阶段
- 我们是否可以不包含shuffle阶段直接运行出代码呢?
- 现在的唯一shuffle阶段就是再reduceByKey,有什么是可以不经过shuffle却可以实现reduceByKey的功能的呢?——————累加器
我们先自定义一个类,方便数据的存储
case class HotCategory(cid: String, var clickCnt: Int, var orderCnt: Int, var payCnt: Int)
自定义累加器
/**
* 自定义累加器
* 1. 继承AccumulatorV2,定义泛型
* IN : ( 品类ID, 行为类型 )
* OUT : mutable.Map[String, HotCategory]
* 2. 重写方法(6)
*/
class HotCategoryAccumulator extends AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] {
//一般直接定义一个输出类型的数据
private val hcMap = mutable.Map[String, HotCategory]()
//默认值,或者说当什么时候值是0(也就是输出为空时)
override def isZero: Boolean = {
hcMap.isEmpty
}
//直接new一个自定义的累加器就可(也就是本类)
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = {
new HotCategoryAccumulator()
}
//重置
override def reset(): Unit = {
hcMap.clear()
}
//当外面调用累加器时的方法,也就是分区内的累加逻辑
override def add(v: (String, String)): Unit = {
val cid = v._1
val actionType = v._2
val category: HotCategory = hcMap.getOrElse(cid, HotCategory(cid, 0, 0, 0))
if (actionType == "click") {
category.clickCnt += 1
} else if (actionType == "order") {
category.orderCnt += 1
} else if (actionType == "pay") {
category.payCnt += 1
}
hcMap.update(cid, category)
}
//分区间的累加逻辑
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
val map1 = this.hcMap
val map2 = other.value
map2.foreach {
case (cid, hc) => {
val category: HotCategory = map1.getOrElse(cid, HotCategory(cid, 0, 0, 0))
category.clickCnt += hc.clickCnt
category.orderCnt += hc.orderCnt
category.payCnt += hc.payCnt
map1.update(cid, category)
}
}
}
//输出值是什么?
override def value: mutable.Map[String, HotCategory] = hcMap
}
处理方法
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 1. 读取原始日志数据
val actionRDD = sc.textFile("data/user_visit_action.txt")
val acc = new HotCategoryAccumulator
sc.register(acc, "hotCategory")
// 2. 将数据转换结构
actionRDD.foreach(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
acc.add((datas(6), "click"))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.foreach(
id => {
acc.add((id, "order"))
}
)
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.foreach(
id => {
acc.add((id, "pay"))
}
)
}
}
)
val accVal: mutable.Map[String, HotCategory] = acc.value
val categories: mutable.Iterable[HotCategory] = accVal.map(_._2)
val sort = categories.toList.sortWith(
(left, right) => {
if (left.clickCnt > right.clickCnt) {
true
} else if (left.clickCnt == right.clickCnt) {
if (left.orderCnt > right.orderCnt) {
true
} else if (left.orderCnt == right.orderCnt) {
left.payCnt > right.payCnt
} else {
false
}
} else {
false
}
}
)
// 5. 将结果采集到控制台打印出来
sort.take(10).foreach(println)
sc.stop()
}
数据展示
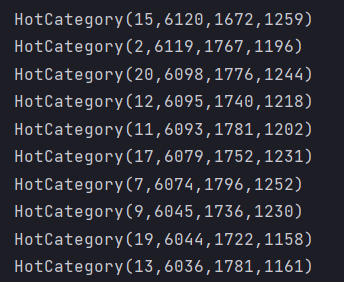
需求:Top10 热门品类中每个品类的 Top10 活跃 Session 统计
在本需求中,我们需要使用要上个需求的代码
我们只要以上个需求结果中的品类来进行分组求和即可
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 在需求一的基础上,增加每个品类用户session的点击统计
* TOP10热门品类中每个品类的TOP10活跃的Session
*/
object UserVisiterActionTest03 {
def main(args: Array[String]): Unit = {
val spark = new SparkConf().setMaster("local[*]").setAppName("UserVisitAction")
val sc = new SparkContext(spark)
sc.setLogLevel("ERROR")
//读取文件
val sourceRDD = sc.textFile("data/user_visit_action.txt")
val top10Ids = top10Category(sourceRDD)
//过滤原始数据,保留点击和前十品类的id
val filterActionRDD = sourceRDD.filter(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
top10Ids.contains(datas(6))
} else {
false
}
}
)
//将品类id和session id进行点击量的统计
val reduceRDD = filterActionRDD.map(
action => {
val datas = action.split("_")
((datas(6), datas(2)), 1)
}
).reduceByKey(_ + _)
//将统计结果转换
//((品类ID,sessionId),sum) ==> (品类ID,(sessionId,sum))
val mapRDD = reduceRDD.map({
case ((cid, sid), sum) => {
(cid, (sid, sum))
}
})
//相同的品类进行分组
val groupRDD = mapRDD.groupByKey()
//将分组后的数据排序,取前十
groupRDD.mapValues(
iter =>{
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)
}
).collect()
.foreach(println(_))
sc.stop()
}
def top10Category(sourceRDD: RDD[String]) = {
//统计品类的点击数量(商品品类,点击总量)
val clickRDD = sourceRDD.map(item => (item.split("_")(6), 1))
.filter(_._1 != "-1")
.reduceByKey(_ + _)
//统计品类的下单数(商品品类,下单总数)
val orderRDD = sourceRDD.map(_.split("_")(8))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//统计品类的支付数(商品品类,支付总数)
val payRDD = sourceRDD.map(_.split("_")(10))
.filter(_ != "null")
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//组合
/**
* 求出三个的总数
* 此时的三个RDD的数据形式是
* (商品品类,总点击量)
* (商品品类,总订单量)
* (商品品类,总支付量)
* 需要的形式(商品品类,(点击量,订单量,支付量))
* 我们可以进行如下的转换
* (商品品类,点击量) ==> (商品品类,(点击量,0,0))
* (商品品类,订单量) ==> (商品品类,(0,订单量,0))
* (商品品类,支付量) ==> (商品品类,(0,0,支付量))
* 然后对数据来进行集合操作即可
*/
//第一步:将数据转换变形
val rdd1 = clickRDD.map {
case (cid, cnt) => {
(cid, (cnt, 0, 0))
}
}
val rdd2 = orderRDD.map {
case (cid, cnt) => {
(cid, (0, cnt, 0))
}
}
val rdd3 = payRDD.map {
case (cid, cnt) => {
(cid, (0, 0, cnt))
}
}
//进行聚合操作
val result = rdd1.union(rdd2).union(rdd3).reduceByKey((v1, v2) => (v1._1 + v2._1, v1._2 + v2._2, v1._3 + v2._3))
result.sortBy(_._2, false)
.take(10)
.map(_._1)
}
}
结果展示
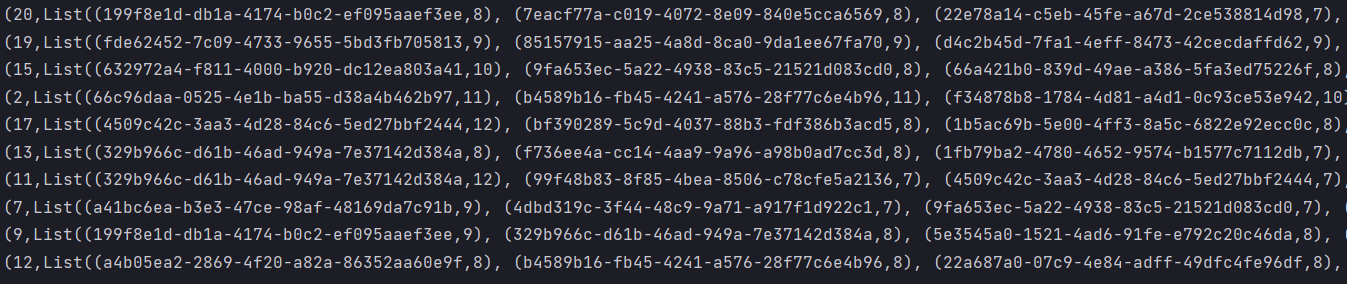
需求:页面单跳统计
什么是页面单跳
页面单跳转化率:计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化就是要统计页面点击的概率。
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么B/A 就是 3-5 的页面单跳转化率。
统计页面单跳的意义
- 产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
- 数据分析师,可以此数据做更深一步的计算和分析。
- 企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
计算流程
总结
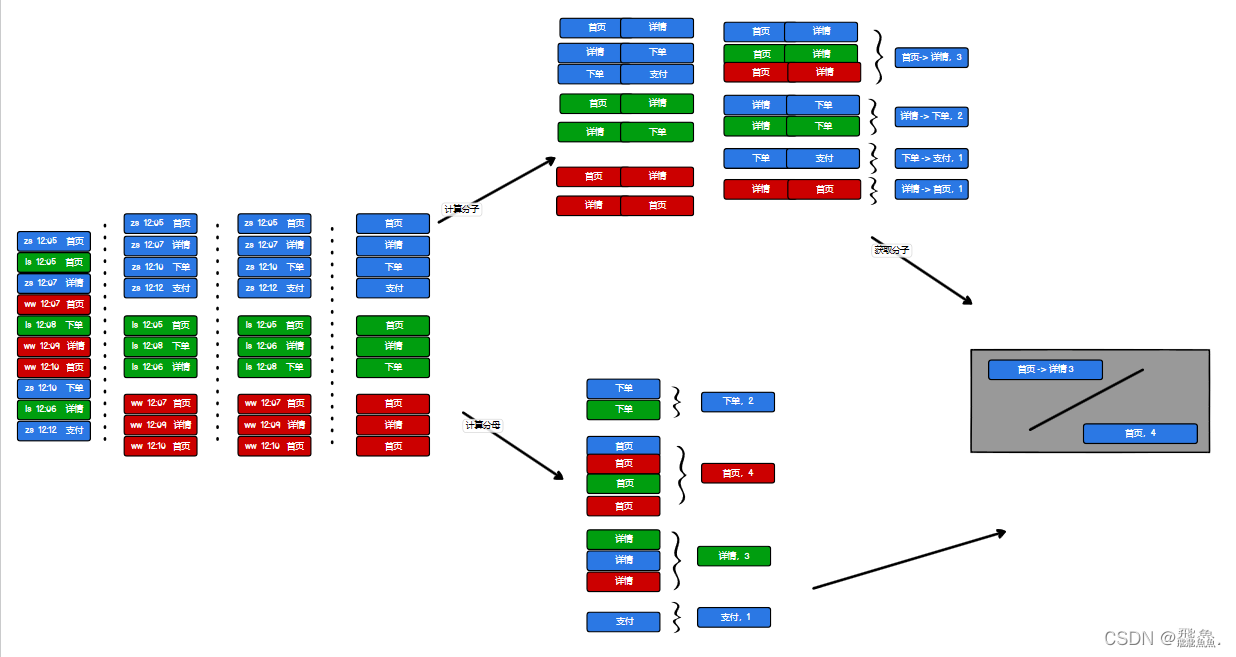
- 步骤大致可以分为三步,第一步求分母,也就是每个页面的总次数;第二步,求分子;第三步就是求分子除分母
- 求分母时较为简单,可以看作是一个
WordCount求和即可 - 求分子时,要先按照时间顺序排序,在两两连接,如:页面按照时间排序的点击顺序是
【A,B,C】就,可以分为【A-B,B-C】
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
object UserVisiterAction_Pageflow {
def main(args: Array[String]): Unit = {
val spark = new SparkConf().setMaster("local[*]").setAppName("UserVisitActionTest04")
val sc = new SparkContext(spark)
sc.setLogLevel("ERROR")
//读取文件
val sourceRDD = sc.textFile("data/user_visit_action.txt")
val actionDataRDD = sourceRDD.map(
action => {
val datas = action.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
//TODO 计算分母
val pageIDToCountMap = actionDataRDD.map(
action => {
(action.page_id, 1l)
}
).reduceByKey(_ + _).collect().toMap
//todo 计算分子
//根据session来进行分组
val sessionRDD: RDD[(String, Iterable[UserVisitAction])] = actionDataRDD.groupBy(_.session_id)
//根据时间来进行排序
val mvRDD = sessionRDD.mapValues(
iter => {
val sortList = iter.toList.sortBy(_.action_time)
//求出按照时间顺序排序的连续的访问网页的的一个顺序
/**
* 此时page_id也就是网页的访问顺序如下
* [1,2,3,4,5]
* 但是我们需要其变成
* [1-2,2-3,3-4,4-5]
* 可以使用zip(拉链)[1,2,3]zip[2,3,4](拉链就是第一个rdd做key,第二个相同位置的rdd做value)
*/
val flowIds: List[Long] = sortList.map(_.page_id)
//TODO tail方法是取除第一个之外的全部元素(列表里的)
val pageflowIds: List[(Long, Long)] = flowIds.zip(flowIds.tail)
pageflowIds.map((_, 1))
}
)
val flatRDD = mvRDD.map(_._2).flatMap(list => list)
val dataRDD = flatRDD.reduceByKey(_+_)
//TODO 计算单跳转换率(分子/分母)
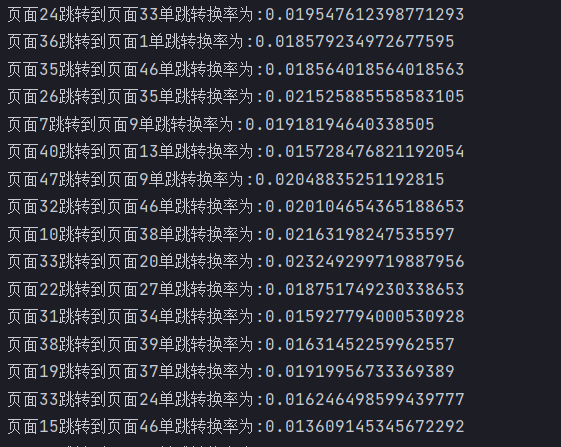
dataRDD.foreach{
case ((pageId1,pageId2),sum) =>{
val pageCount = pageIDToCountMap.getOrElse(pageId1,0l)
println(s"页面${pageId1}跳转到页面${pageId2}单跳转换率为:"+(sum.toDouble/pageCount))
}
}
sc.stop()
}
case class UserVisitAction(
date: String, //用户点击行为的日期
user_id: Long, //用户的 ID
session_id: String, //Session 的 ID
page_id: Long, //某个页面的 ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的 ID
click_product_id: Long, //某一个商品的 ID
order_category_ids: String, //一次订单中所有品类的 ID 集合
order_product_ids: String, //一次订单中所有商品的 ID 集合
pay_category_ids: String, //一次支付中所有品类的 ID 集合
pay_product_ids: String, //一次支付中所有商品的 ID 集合
city_id: Long //城市 id
)
}
部分结果展示