论文:https://arxiv.org/pdf/2405.17933
代码:https://doubiiu.github.io/projects/ToonCrafter
给定首尾帧,生成逼真生动的动画,动画插值生成

MOTIVATION
- Traditional methods which implicitly assume linear motion and the absence of complicated phenomena like disocclusion, often struggle with the exaggerated non-linear and large motions with occlusion commonly found in cartoons, resulting in implausible or even failed interpolation results.【传统的方法,隐含地假设动画为线性运动且不存在复杂的现象,如disocclusion,往往难以解决卡通与夸张的非线性和大的运动与遮挡,导致难以置信的,甚至失败的插值结果。】
- cartoon frames are temporally sparse (hence, large motion) due to the high drawing cost.Such cost also leads to higher chance of textureless color regions in cartoon than in live-action video.
- directly applying existing models to cartoon interpolation is unsatisfactory
- there exists a domain gap as the models are mostly trained on live-action video content. Non-cartoon content may be accidentally synthesized. The model may also misunderstand the animationdomain content and fails to generate the appropriate motion.【由于模型大多是在真人视频内容上训练的,因此存在域差距。非卡通内容可能会意外合成。模型也可能误解animation-domaind的内容,无法生成适当的运动】
- to reduce the computational cost, current video diffusion models are based on highly compressed latent spaces , resulting in significant loss of details and quality degradation.
- the generative models can be somewhat random and lack of control. An effective control over the generated motion is necessary for cartoon interpolation.
CONTRIBUTIONS
- We point out the notion of generative cartoon interpolation and introduce an innovative solution by leveraging live-action video prior. It significantly outperforms existing competitors. 【指出了生成式卡通插值的概念,并引入了一种利用真人视频的创新解决方案】
- We present a toon rectification learning strategy that effectively adapts live-action motion prior to animation domain. 【我们指出了生成式卡通插值的概念,并引入了一种利用真人视频的创新解决方案。它的表现明显优于现有竞争对手。
- 我们提出了一种卡通整改学习策略,可以有效地适应动画领域的真人动作】
- We propose a dual-reference-based 3D decoder to compensate the lost details resulting from compressed latent space. 【提出了一种基于双参考的 3D 解码器,以补偿因压缩潜在空间而丢失的细节】
- Our system enables users to interactively create or modify interpolation results in a flexible and controllable fashion.【用户能够以灵活和可控的方式以交互方式创建或修改插值结果】
Related Work
Video Frame Interpolation[视频帧插值]
-
近年来,使用深度学习的视频帧插值方法主要分为三类
- 基于相位的方法(phase-based)
- 基于核的方法(kernel-based)
- 基于光流/特征流的方法(optical/feature
flow-based methods)
-
现有方法的局限性:尽管这些方法在真人视频插值方面取得了巨大成功,但它们通常难以处理卡通中的大范围非线性运动和无纹理区域。
-
现有工作的改进:现有方法依赖于明确的对应关系识别和线性或直接运动的假设。它们未能模拟卡通中的复杂非线性运动或遮挡现象。
- Zhu等人将卡通区域的对应关系问题表述为网络流优化问题。
- AnimeInterp通过基于颜色片段匹配的分段引导匹配模块来增强对应关系的识别。
- EISAI通过使用特定领域的感知损失从纯色区域去除异常来提高感知质量。
- Li等人引入了中间草图引导来解决大运动问题,但这种方法通常由于手工绘制的必要性而不总是可用。
Image-conditioned Video Diffusion Models
-
I2V合成的应用
- 近期的研究工作主要集中在使用扩散模型(DMs)在大规模数据集上训练T2V模型。这些模型通过学习大量数据,能够生成具有丰富动作和场景的视频内容。除了T2V模型,研究者也在探索将额外的图像条件引入这些模型中,以实现I2V合成。
- 例如,SEINE模型首次提出通过将两个输入帧与带噪声的视频潜在表示串联起来,作为扩散U-Net的输入,以产生创造性的过渡视频片段,连接两个不同的场景。
-
现有模型的局限性
- 尽管存在如DynamiCrafter、SparseCtrl和PixelDance要么通过将两个input frames与noisy frame latents连接或使用类似于ControlNet的辅助帧编码器(auxiliary frame encoder),展示它们对于视频内插/转换的下游应用的可扩展性
- 然而,当应用于卡通 插值时,这些模型由于卡通独特的挑战而不够稳定和可用。
-
ToonCrafter的目标与核心思想
- 本文的目标是利用从真人视频中学习到的丰富动作生成先验的I2V扩散模型,并将其适应于生成性卡通插值。
- 通过适配和改进现有的扩散模型,ToonCrafter希望能够克服真人视频与卡通视频之间的领域差异,同时保留真人视频中学到的丰富动作信息。
- 这涉及到对现有模型的结构和训练策略进行调整,以便更好地适应卡通视频的特点,如夸张的动作和非线性运动。
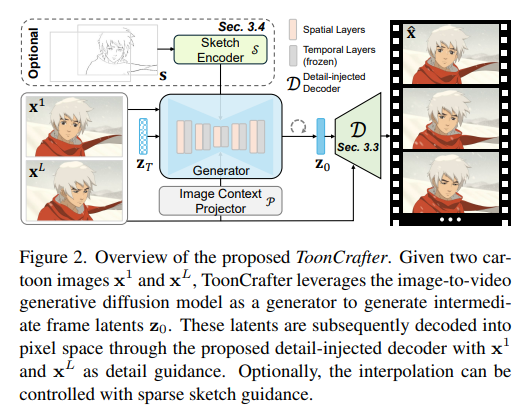
METHODS
Our generative cartoon interpolation framework is built upon the open-sourced DynamiCrafter interpolation model, a SOTA i2V generative diffusion model.,and incorporates three key improvements for generative cartoon interpolation:
- a meticulously designed toon rectification learning strategy for effective domain adaptation,
- a novel dual-reference 3D decoder D D D to tackle the visual degradation due to the lossy latent space,
- a frame-independent sketch encoder S S S that enables the user control over the interpolation.
Preliminary-DynamiCrafter&LDM
-
基于DynamiCrafter的图像到视频生成LDM:给定一个视频 x ∈ R L × 3 × H × W x \in \mathbb{R}^{L \times 3 \times H \times W} x∈RL×3×H×W,首先将其逐帧编码成潜在表示 z = E ( x ) z = E(x) z=E(x),其中 z ∈ R L × C × h × w z \in \mathbb{R}^{L \times C \times h \times w} z∈RL×C×h×w。
-
接下来,在潜在空间中执行前向扩散过程 z t = p ( z 0 , t ) z_t = p(z_0, t) zt=p(z0,t)和后向去噪过程 z t = p θ ( z t − 1 , c , t ) z_t = p_\theta(z_{t-1}, c, t) zt=pθ(zt−1,c,t)。 这里的 c c c代表去噪条件,如文本 c t x t c_{txt} ctxt和图像提示 c i m g c_{img} cimg。
-
根据DynamiCrafter的描述,插值应用是通过提供起始帧 x 1 x_1 x1和结束帧 x L x_L xL,同时将中间帧留空以供图像提示 c i m g c_{img} cimg使用来实现的。
-
优化目标
- 优化目标是最小化去噪网络参数
θ
\theta
θ的期望损失,损失函数是重构误差的平方,表示为:
min θ E x , t , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ ( z t ; c i m g , c t x t , t , f p s ) ∥ 2 2 ] \min_{\theta} \mathbb{E}_{x,t,\epsilon \sim \mathcal{N}(0,I)} \left[ \|\epsilon - \epsilon_\theta(z_t; c_{img}, ctxt, t, fps) \|_2^2 \right] θminEx,t,ϵ∼N(0,I)[∥ϵ−ϵθ(zt;cimg,ctxt,t,fps)∥22] - 这里, ϵ \epsilon ϵ是从标准正态分布中采样的噪声, ϵ θ \epsilon_\theta ϵθ是去噪网络, f p s fps fps是帧率控制。
- 优化目标是最小化去噪网络参数
θ
\theta
θ的期望损失,损失函数是重构误差的平方,表示为:
-
一旦去噪过程完成,潜在表示 z z z 通过解码函数 D ( z ) D(z) D(z) 被转换回视频空间,生成最终的视频 x ^ \hat{x} x^。
Toon Rectification Learning
Some potential issues include the unintentional synthesis of non-cartoon content, as well as the model’s inability to accurately comprehend animation content, leading to the generation of inappropriate motion【一些潜在的问题包括非卡通内容的无意合成,以及模型无法准确理解动画内容,导致生成不适当的运动】
Cartoon Video Dataset Construction
- We collect a series of raw cartoon videos and then manually select highquality ones based on the resolution and subjective quality. The total duration of the selected videos is more than 500 hours.
- We employ PySceneDetect [1] to detect and split shots. The static shots are filtered out by removing any videos with low average optical flow [46] magnitude.
- Moreover, we apply optical character recognition (CRAFT) [2] to weed out clips containing large amounts of text.
- In addition, we adopt LAION [42] regressive model to calculate the aesthetic score for removing the low-aesthetic samples to ensure quality.
- Next, we annotate each clip with the synthetic captioning method BLIP-2 [23].
- Lastly, we annotate the first, middle, and last frames of each video clip with CLIP [39] embeddings from which we measure the textvideo alignment, to filter out mismatched samples.
- In the end, we obtained 271K high-quality cartoon video clips, which were randomly split into two sets. The training set contains 270K clips, while the evaluation set contains 1K clips.
Rectification Learning
- PROBLEM:directly fine-tuning the denoising network of **DynamiCrafter interpolation model (DCinterp)**on our data would lead to catastrophic forgetting due to unbalanced scale between our cartoon video data (270K video clips) and the original training data of DCinterp (WebVid-10M [3], 10M), which deteriorates motion prior【直接微调DynamiCrafter插值模型(DCinterp)的去噪网络会导致灾难性的遗忘】
- The DCinterp model (DynamiCrafter interpolation model):
- three key components:an image-context projector;the spatial layers (sharing the same architecture as StableDiffusion v2.1);temporal layers
- Based on our experiments (Sec. 4.5), we have the following observations:
- the image-context projector helps the DCinterp model to digest the context of the input frames;【图像上下文投影仪帮助 DCinterp 模型消化输入帧的上下文】
- the spatial layers are responsible for learning the appearance distribution of video frames; 【空间层负责学习视频帧的外观分布】
- the temporal layers capture the motion dynamics between the video frames.【时间层捕获视频帧之间的运动动态】
- SOLUTION:our toon rectification learning strategy focuses on the appearance by freezing the temporal layers (to preserve the real-world motion prior,) and finetuning the image-context projector and spatial layers with only our collected cartoon data to achieve effective domain adaptation.
- 冻结时间层:在模型中,时间层负责捕捉视频帧之间的运动动态。为了保留从大规模真人视频数据中学到的真实世界运动先验,这些时间层在微调过程中被冻结,即不对其进行任何更改。
- 专注于外观的校正:卡通视频与真人视频在视觉风格、表达夸张度和纹理简化方面存在差异。这些视觉上的差异是领域适应的主要挑战。因此,卡通校正学习策略专注于调整模型的外观生成能力。
- 微调图像上下文投影器和空间层:图像上下文投影器帮助模型理解输入帧的上下文信息,而空间层负责学习视频帧的外观分布。通过对这两部分进行微调,模型能够更好地理解和生成卡通视频的特定外观特征。
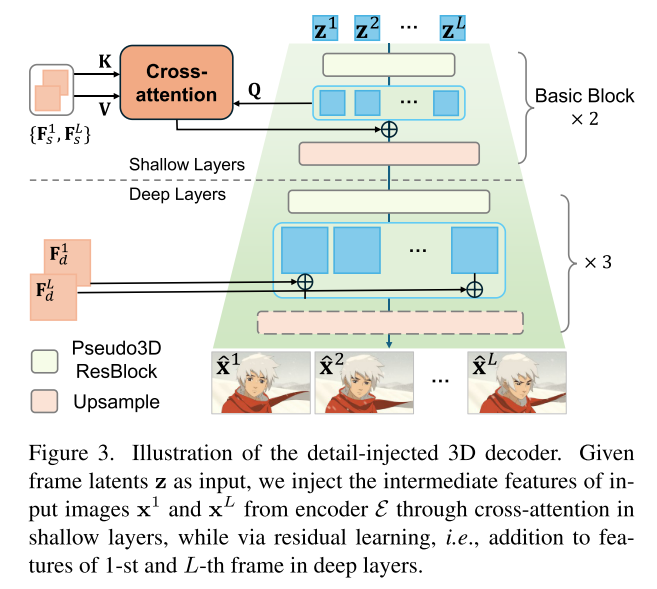
Detail Injection and Propagation in Decoding
- PROBLEM:directly applying the latent video diffusion model for cartoon interpolation could lead to unacceptable results, as the structure and texture are highly likely to contain artifacts and be inconsistent with the original input frames because they are addressed in latent space.【直接应用潜在视频扩散模型进行卡通插值可能会导致不可接受的结果,因为结构和纹理极有可能包含伪影,并且与原始输入帧不一致,因为它们是在潜在空间中寻址的】
- SOLUTION:exploit the existing information from the input frames and introduce a dual-reference-based 3D decoder to propagate the pixel-level details from the two input frames to the decoding process of the generated lossy-space frame latents【利用输入帧的现有信息,引入基于双参考的三维解码器,将像素级细节从两个输入帧传播到生成的有损空间帧潜伏的解码过程中】
- Rather than relying solely on the decoder
D
D
D to recover the compressed details, we firstly extract the inner features {
F
i
K
F^K_i
FiK} at each residual block of
E
\mathcal{E}
E 【首先提取
E
\mathcal{E}
E的每个残差块的内部特征】
- i i i represents the i i i-th residual block from the end in the encoder
- K indicates the K-th frame
- and then inject them into the decoding process. This provides the necessary hints for achieving pixel-perfect compensation. [然后将它们注入到解码过程中]
- Specifically, we propose a hybrid-attention-residuallearning mechanism (HAR) to inject and propagate details.【提出了一种混合注意力残差学习机制(HAR)来注入和传播细节】
- Rather than relying solely on the decoder
D
D
D to recover the compressed details, we firstly extract the inner features {
F
i
K
F^K_i
FiK} at each residual block of
E
\mathcal{E}
E 【首先提取
E
\mathcal{E}
E的每个残差块的内部特征】
- IMPLEMENT: we introduce cross-frame-attention in
D
D
D to inject the intricate details from
{
F
i
1
}
i
∈
s
\{\mathbf{F}_{i}^{1}\}_{i\in s}
{Fi1}i∈sand
{
F
i
L
}
i
∈
s
\{\mathbf{F}_{i}^{L}\}_{i\in s}
{FiL}i∈sto decoder’s intermediate features
G
i
n
G_{in}
Gin【我们在
D
D
D 中引入了跨帧注意力,以将
F
i
1
i
i
n
s
{\mathbf{F}_{i}^{1}}_{iin s}
Fi1iins和
F
i
L
i
i
n
s
{\mathbf{F}_{i}^{L}}_{iin s}
FiLiins注入到解码器的中间特征
G
i
n
G_{in}
Gin】
- Shallow Layers:在解码器D中引入跨帧注意力,将输入帧
x
1
x_1
x1和
x
L
x_L
xL的复杂细节注入到解码器的中间特征
G
i
n
G^{in}
Gin中。
G o u t j = S o f t m a x ( Q K ⊤ d ) V + G i n j , j ∈ 1... L \mathbf{G}_{\mathrm{out}}^j=\mathrm{Softmax}(\frac{\mathbf{QK}^\top}{\sqrt{d}})\mathbf{V}+\mathbf{G}_{\mathrm{in}}^j,j\in1...L Goutj=Softmax(dQK⊤)V+Ginj,j∈1...L- Q = G j i n W Q Q = G^{in}_j W_Q Q=GjinWQ, G i n G^{in} Gin is decoder’s intermediate features
- K = [ F i 1 ; F i L ] W K K = [F^1_i; F^L_i] W_K K=[Fi1;FiL]WK
- V = [ F i 1 ; F i L ] W V V = [F^1_i; F^L_i] W_V V=[Fi1;FiL]WV
- [ ; ] [;] [;]表示连接。
- 考虑到注意力的计算成本,这种机制仅在解码器D的前两层(即浅层s = {1, 2})中实现。
- Deeper Layers: 由于输入帧
x
1
x_1
x1和结果
x
^
1
\hat{x}_1
x^1在像素级上是对齐的,因此将ZeroConv处理过的
{
F
i
1
}
\{F^1_i\}
{Fi1}(ZeroConv处理过的
{
F
i
L
}
\{F^L_i\}
{FiL})添加到第一帧(第L帧)的相应特征图中。
G o u t 1 = ZeroConv 1 × 1 ( F i 1 ) + G i n 1 . \mathbf{G}_{\mathrm{out}}^1=\text{ZeroConv}_{1\times1}(\mathbf{F}_i^1)+\mathbf{G}_{\mathrm{in}}^1. Gout1=ZeroConv1×1(Fi1)+Gin1.- 为了避免冗余计算,仅在解码器D的深层(d = {3, 4, 5})中实现这种残差学习。
- 此外,我们结合伪三维卷积(P3D,pseudo-3D convolutions),以进一步促进传播并提高时间相干性。
- Shallow Layers:在解码器D中引入跨帧注意力,将输入帧
x
1
x_1
x1和
x
L
x_L
xL的复杂细节注入到解码器的中间特征
G
i
n
G^{in}
Gin中。
- TRAINING:
- We freeze the image encoder E \mathcal{E} E and optimize the proposed decoder D D D, which is initialized from the vanilla image decoder.
- We use a compound loss L to encourage reconstruction:
L
=
L
1
+
λ
p
L
p
+
λ
d
L
d
\mathcal{L}=\mathcal{L}_1+\lambda_p\mathcal{L}_p+\lambda_d\mathcal{L}_d
L=L1+λpLp+λdLd
- L 1 \mathcal{L}_1 L1 : MAE loss
- L p \mathcal{L}_p Lp :perceptual loss (LPIPS )
- L d \mathcal{L}_d Ld:discriminator loss
- λ p λ_p λp = 0.1, λ —— d λ——d λ——d is an adaptive weight following.
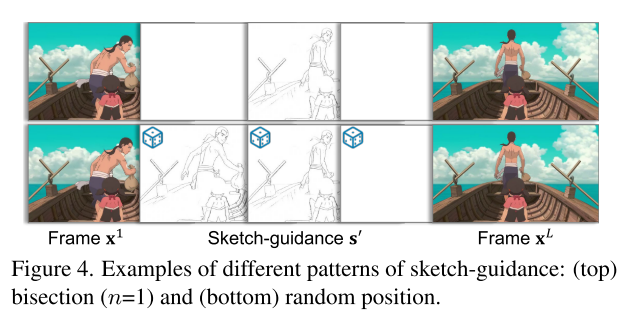
Sketch-based Controllable Generation
We propose a frame-independent sketch encoder S S S that enables users to control the generated motion using sparse sketch guidance.
-
稀疏输入支持:草图编码器模块S支持稀疏输入,用户不需要为目标帧提供所有草图图像。
-
帧独立适配:S被设计为帧独立的适配器,能够基于提供的草图独立调整每一帧的中间特征。
-
处理策略:草图编码器使用与ControlNet相似的策略处理输入的草图,无论草图是否存在,S都能接收输入并调整特征。
-
we design S S S as a frame-wise adapter that learns to adjust the intermediate features of each frame independently based on the provided sketch【 S S S去学习根据提供的草图独立调整每个帧的中间特征】
- 对于有草图指导的帧,草图编码器根据草图 s i s_i si、潜在表示 z i z_i zi和时间 t t t来调整特征: F inject i = S ( s i , z i , t ) F_{\text{inject}}^i = S(s_i, z_i, t) Finjecti=S(si,zi,t)。
- 对于没有草图指导的帧,草图编码器接收一个空图像作为输入,以改善学习动态: F inject i = S ( s ∅ , z i , t ) F_{\text{inject}}^i = S(s_\emptyset, z_i, t) Finjecti=S(s∅,zi,t)。
-
training:We freeze the denoising network ϵ θ ϵ_θ ϵθ and optimize the sketch encoder S S S. S uses a ControlNet-like architecture, initialized from the pre-trained StableDiffusion v2.1. The training objective is:【冻结去噪网络 ε θ ε_θ εθ,优化草图编码器 S S S】
min θ E E ( x ) , s , t , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ S ( z t ; c i m g , c t x t , s ′ , t , f p s ) ∥ 2 2 ] \min_{\theta}\mathbb{E}_{\mathcal{E}(\mathbf{x}),\mathbf{s},t,\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\left[\|\epsilon-\epsilon_{\theta}^{\mathcal{S}}\left(\mathbf{z}_{t};\mathbf{c}_{\mathrm{img}},\mathbf{c}_{\mathrm{txt}},\mathbf{s}^{\prime},t,fps\right)\|_{2}^{2}\right] θminEE(x),s,t,ϵ∼N(0,I)[∥ϵ−ϵθS(zt;cimg,ctxt,s′,t,fps)∥22]- ϵ S θ \epsilon_{S}^{\theta} ϵSθ表示结合了 ϵ θ \epsilon_\theta ϵθ和S的网络
- s是通过Anime2Sketch从原始视频帧获得的草图
- s’是从s中选定的草图。
-
用户草图输入的典型模式
- 为了支持用户草图输入的典型模式,设计了一个二分选择模式(80%的时间被选择),在插值段(i, j)中选择第 ⌊ i + j 2 ⌋ \lfloor \frac{i+j}{2} \rfloor ⌊2i+j⌋帧的草图。
- 选择从段(1, L)到细分的段递归应用的(递归深度n从[1, 4]中均匀采样)。
- 这种二分选择模式模仿了现实世界中用户的行为,即用户在等间隔提供草图。
- 对于剩余的20%,从s中随机选择输入草图,以最大化泛化能力。
Experiments
-
实现细节:
- 实验主要基于图像到视频模型DynamiCrafter(插值变体@512×320分辨率)。
- 对于卡通校正学习,训练空间层和P(可能指投影层或某种网络结构)50K步,学习率(lr)为1×10^-5,小批量大小(bs)为32。
- 双重参考基础的3D解码器训练了60K步,学习率为4.5×10^-6,小批量大小为16。
- 草图编码器训练了50K步,学习率为5×10^-5,小批量大小为32。
- ToonCrafter在收集的卡通视频数据集上进行了训练,每批采样16帧,动态帧率,分辨率为512×320。
-
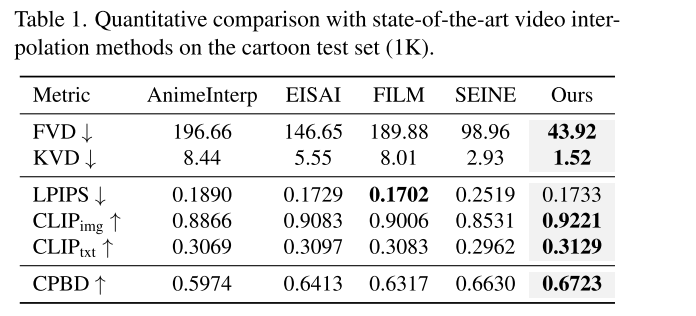
定量比较:
- 使用Fréchet Video Distance (FVD)和Kernel Video Distance (KVD)来评估生成视频在空间和时间域的质量和时间运动动态。
- 使用LPIPS来衡量与真实视频的感知相似性。
- 计算生成帧和真实帧(GT)以及文本提示的CLIP特征的余弦相似度,分别表示为CLIPimg和CLIPtxt。
- 使用累积概率模糊检测(CPBD)来评估清晰度。
- 在卡通视频数据集的1K评估集上评估这些指标(@512×320,16帧)。
- 与多种代表性的最新技术方法进行比较,包括卡通视频插值方法(AnimeInterp和EISAI)、处理大运动的一般视频插值方法(FILM)和生成视频转换(SEINE)。
-
定性比较:
- 展示了代表性插值结果的视觉比较。
- ToonCrafter生成的中间帧具有非线性合理运动,而传统基于对应关系的方法(如AnimeInterp、EISAI和FILM)在处理遮挡(如“man”案例中的“溶解”的手和手臂)和合成复杂非线性运动(如“car”案例中的变形)时表现不佳。
-
用户研究:
- 进行了用户研究,参与者被要求根据运动质量、时间连贯性和帧保真度选择最佳结果。
- 来自24位参与者的统计数据显示ToonCrafter在所有比较中都表现出显著的优势。
-
消融研究:
- 研究了不同校正学习策略的有效性,包括直接使用预训练模型、微调图像上下文投影器和整个去噪U-Net、微调图像上下文投影器和空间层同时保留时间层等。
- 通过构建基线来调查领域适应策略的有效性,并展示了不同策略的定量比较。