最近恰好在搞异地双活,以下是一个梳理:
基本概念
1、异地容灾。这仅仅是一个冷备的概念。也就是在平时正常的时候,另外一个机房只是当做备份。
2、异地双(多)活。而异地双(多)活,却是指有两个或者多个可以同时对外服务的节点,任意一个点挂了,也可以迅速切换到其他节点对外服务,节点之间的数据做到准实时同步。
分类
根据是否需要数据同步大体分为三类:
1、必须同步型。(比如数据库)
2、无须同步型。比如缓存,仅仅是当做缓存,就可以这样做(这个有待商榷,其实缓存也需要同步的,严格来说的话)。
3、只能单活(对全局原子要求较高),不接受有一定时延的“不一致”窗口。
核心问题
数据同步、网络时延。
切换方式
1、自动切换。自动切换表现为当灾难来临时,程序内部可以自动识别出问题然后切换至可用机房。
2、手动切换。通过简单的配置,在几分钟或者一两小时内切换到另外的机房。
异地多活面临的挑战
1、切换问题。
切换问题不仅仅是灾难发生自动切换到好的机房,还有另外一个问题,就是灾难机房恢复能力后,如何再切换回去,切换回去的数据同步问题又是需要解决的。
2、跨机房流量问题。
跨机房的流量是花钱的。所以不是无限大的。控制跨机房消息体大小,越小越好。然而,很多时候要想保证数据同步是一件很耗费流量的事情。但跨机房流量真的是一座山。
既然跨机房流量有限制,而且不稳定。所以有一种解决方案就是不跨机房。既然不跨机房就要做用户分区,确保每个用户只能访问自己所在的区,这样至少能保证该用户自己的数据的完整。
3、所有的业务都适合做异地双活吗?
异地多活效果看起来很诱人,但如果不假思索贪大求全的要求所有业务都实现异地多活的话,就会把自己带到坑里去。
第一个原因是异地多活是有成本的,包括开发成本和维护成本。需要实现异地多活的业务越多,方案越复杂,投入的设计开发时间越多;同时维护成本也会越高,需要更多的机器,需要更多的带宽。
第二个原因是有的业务理论上就无法实现异地多活。典型的有“余额”和“库存”这两个业务。
以余额为例,假设我们实现了余额的异地多活业务,用户小明有10000块钱,在A机房给女友转账了5000块,还剩余5000块;如果此时A机房异常且数据还没同步到B机房,小明登录到B机房发现自己又有10000块了,小明感觉中彩票了,赶紧又转了10000块给女友,最后出现了小明只有10000块却转账了15000块的问题,对于和资金相关的业务,这样的问题是绝对无法容忍的,哪怕一个用户有问题都不行。
所以,异地多活也不能保证所有业务都异地多活,在设计异地多活方案的时候,需要从业务和用户的角度出发,识别出核心和关键业务,明确哪些业务是必须实现异地多活,哪些是可以不实现异地多活,哪些是不能实现异地多活的。比如“登录”必须实现异地多活、“注册”和“修改用户信息”不一定要实现异地多活。
4、冷备还是热备。冷备了以后,一直冷备,当真正出现问题,你还有勇气去切换到那个一直冷的机房吗?恐怕需要点勇气。
5、数据一致性问题。
解决方案:
(1)、守护进程同步。
(2)、客户端双写。
(3)、不去解决。不需要解决的前提是用户分区。分区后,从本质上说,其实是没有做到双活的。只是看起来一个业务确实被分到了多个机房而已。
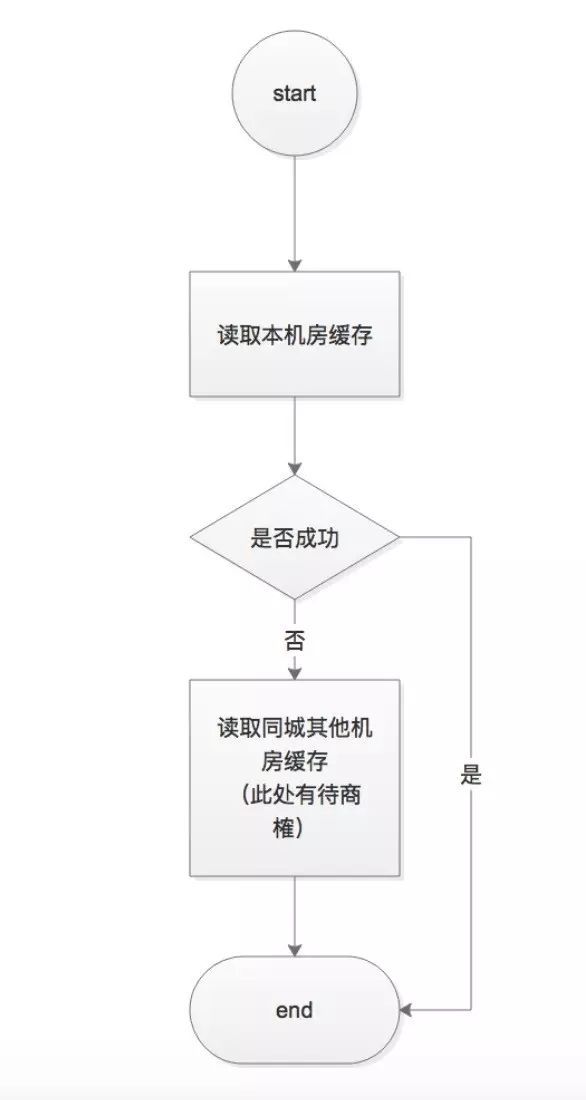
6、读取问题。
这个相对来说要好解决一些,就是就近读取。
业务以及基础组件异地双活方案

业务实例异地双活
业务实例的异地双活。这个相对来说要简单一些,只要做到无状态,再如果通过docker这些容器结束,基本上是相对来说容易一些。
消息队列的异地双活
rabbitmq 每个机房部署一套server,然后每个机房的业务使用各自机房的mq。通过haproxy自动映射到本机房的broker。topic同步,通过rest api读取到
配置文件,然后同步到另外一个机房的rabbitmq下。
具体restapi:
http://17X.XXX.X.XXX:15672/api/definitions
以上只是同步了rabbitmq的元数据,而且是全量同步。
消息同步问题:如果不同步会导致消息丢失。所以mq消息其实也是需要同步的。
同步可以通过客户端双写,或者服务端复制。双写更加容易。
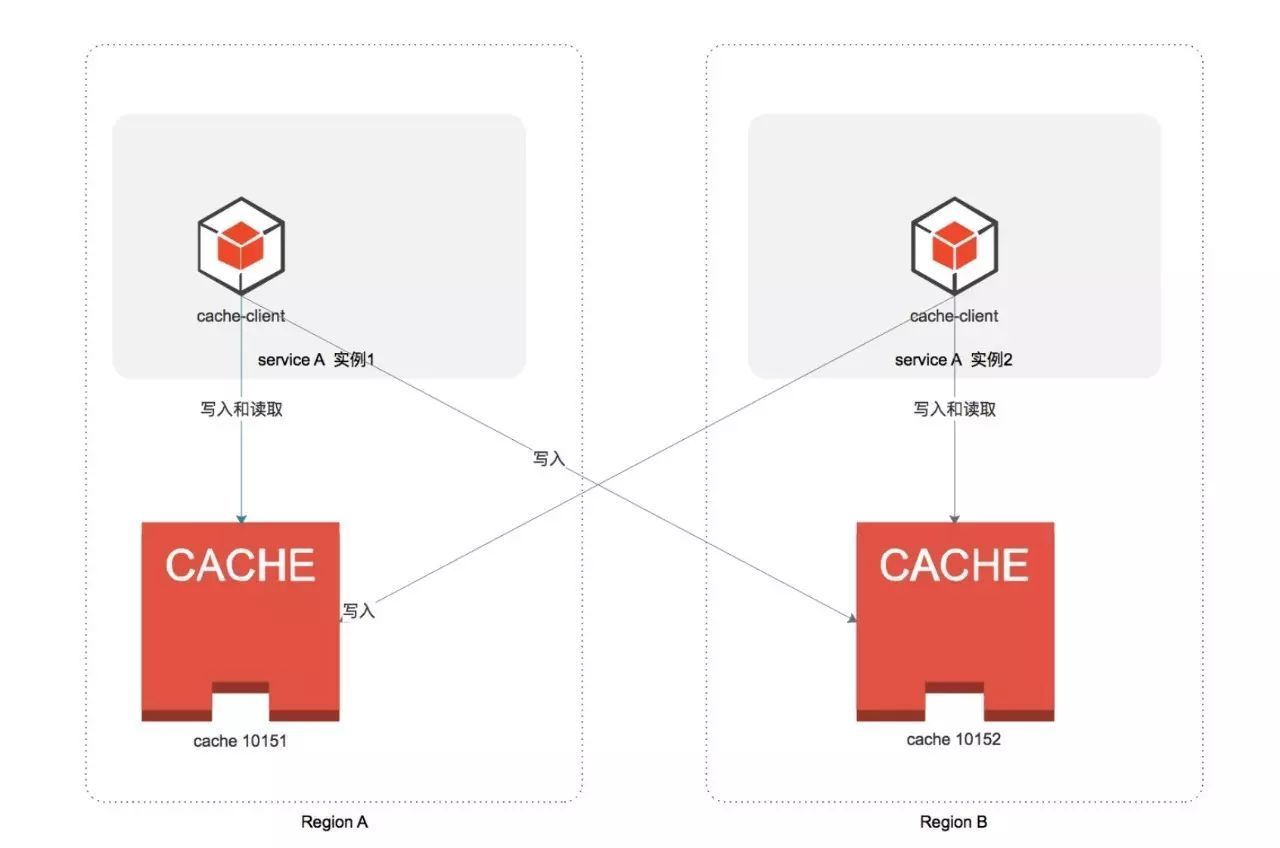
Redis的异地双活
Redis 的异地双活。就是分别在每个机房搭建一套Redis集群。 然后每个机房的业务都去访问各自机房的Redis集群。
但这样只是能保证基本的缓存能力。如果业务中涉及到一些全局的原子操作,那么这样的做法显然不能满足需求。
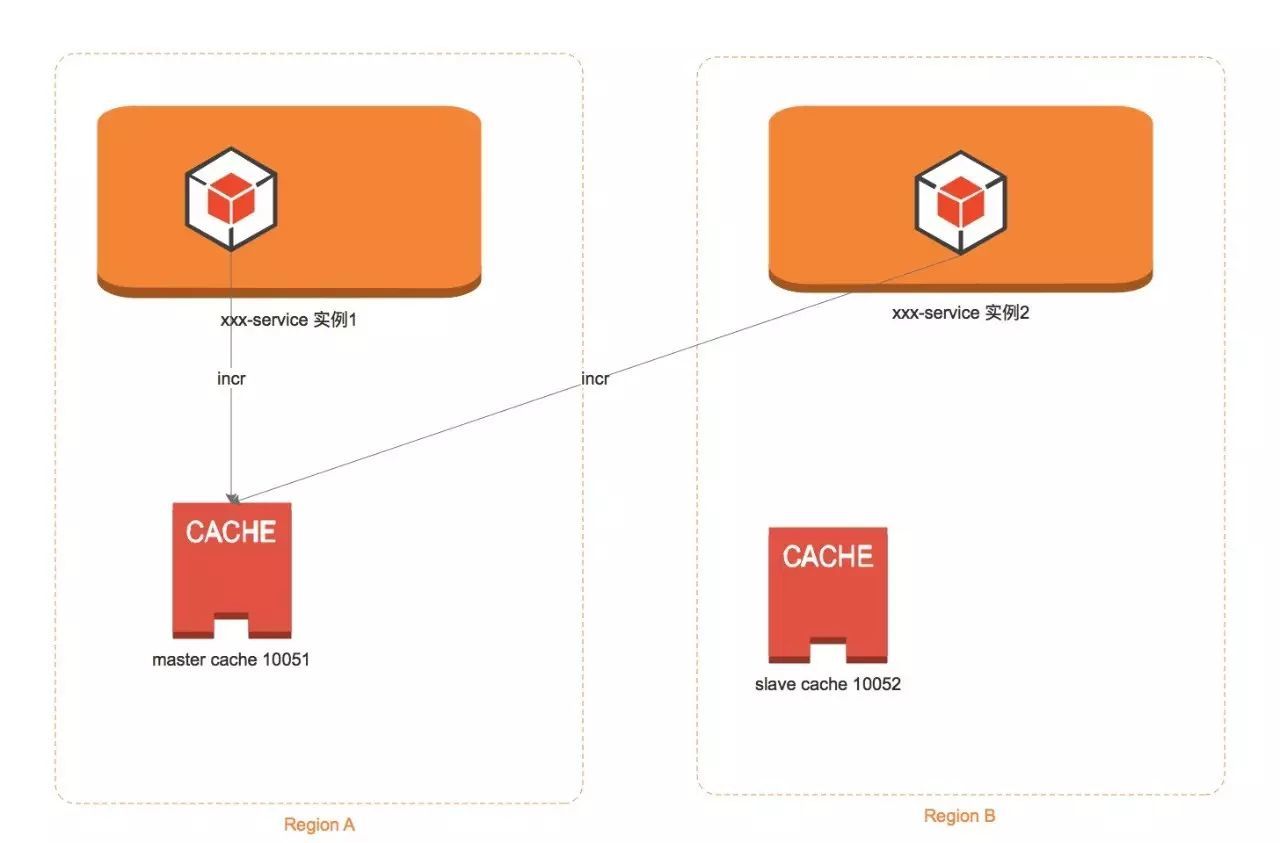
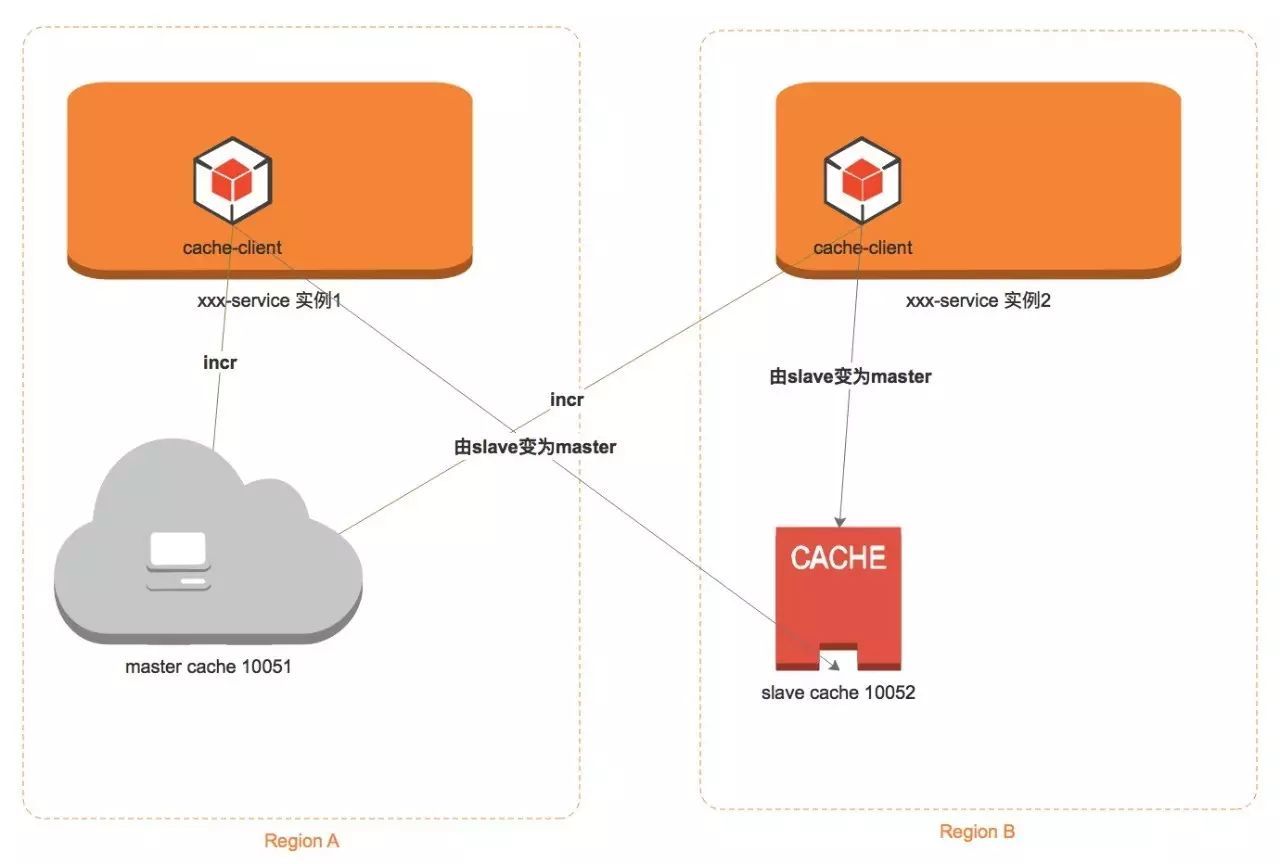
原因很简单,比如你使用redis incr自增命令:
a 机房 加1 后变为了1,b机房的业务也加1, 本来应该是2。结果由于各自都是访问了自己的redis,所以全局计数显然是有问题的。
怎么解决呢?就需要涉及到全局操作的业务,去单独的连接 一个全局的唯一的那个 redis集群,这个redis集群专门用于 业务的全局操作。
但这样的后果,就是会涉及到跨机房流量问题,因为这个全局的redis集群无论放在哪个机房,另外一个机房的业务要想访问都得跨机房。
读取流程:
写入流程:

全局操作:
数据库的异地双活
canal:
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
otter:
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otter4。
目前同步规模:
- 同步数据量6亿
- 文件同步1.5TB(2000w张图片)
- 涉及200+个数据库实例之间的同步
- 80+台机器的集群规模
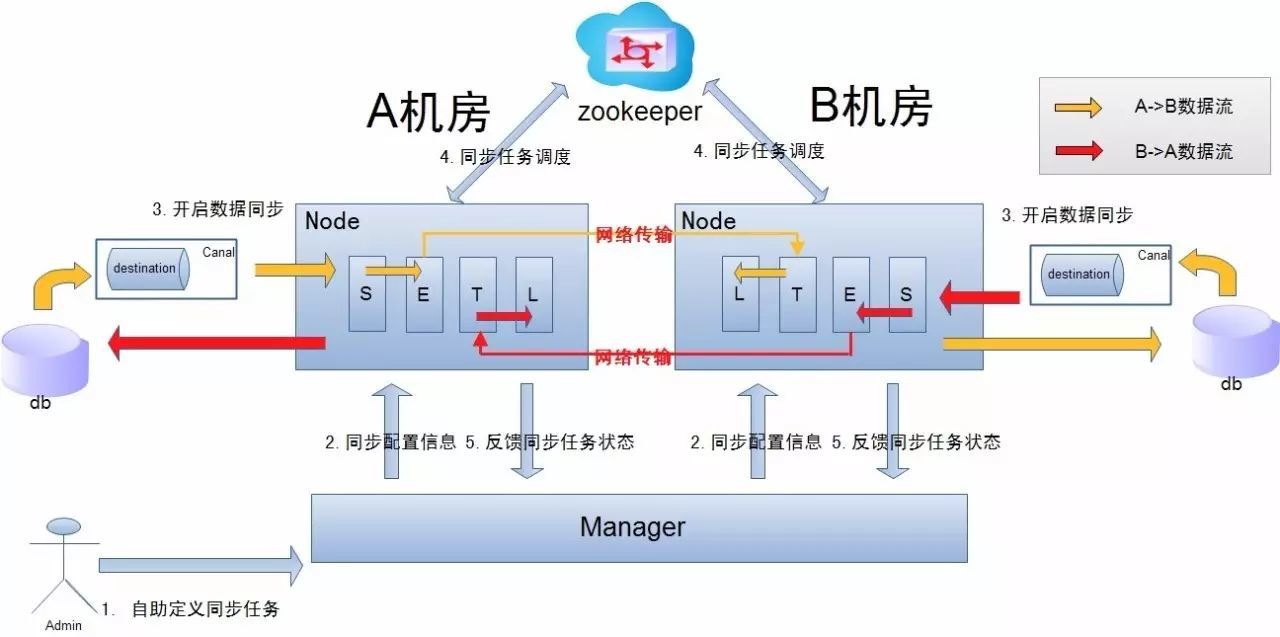
说明:
a. 数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node)
b. node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)
Zookeeper异地双活
先来点背景知识:
1、zookeeper中的server机器之间会组成leader/follower集群,1:n的关系。采用了paxos一致性算法保证了数据的一致性,就是leader/follower会采用通讯的方式进行投票来实现paxos。
2、zookeeper还支持一种observer模式,提供只读服务不参与投票,提升系统。
异地多活决定了我们需要进行跨机房操作,比如杭州,美国,香港,青岛等多个机房之间进行数据交互。
跨机房之间对应的网络延迟都比较大,比如中美机房走海底光缆有ping操作200ms的延迟,杭州和青岛机房有70ms的延迟。
为了提升系统的网络性能,在部署zookeeper网络时会在每个机房部署节点,多个机房之间再组成一个大的网络保证数据一致性。(zookeeper千万别再搞多个集群)。
最后的部署结构就会是:
- 杭州机房 >=3台 (构建leader/follower的zk集群)
- 青岛机房 >=1台 (构建observer的zk集群)
- 美国机房 >=1台 (构建observer的zk集群)
- 香港机房 >=1台 (构建observer的zk集群)
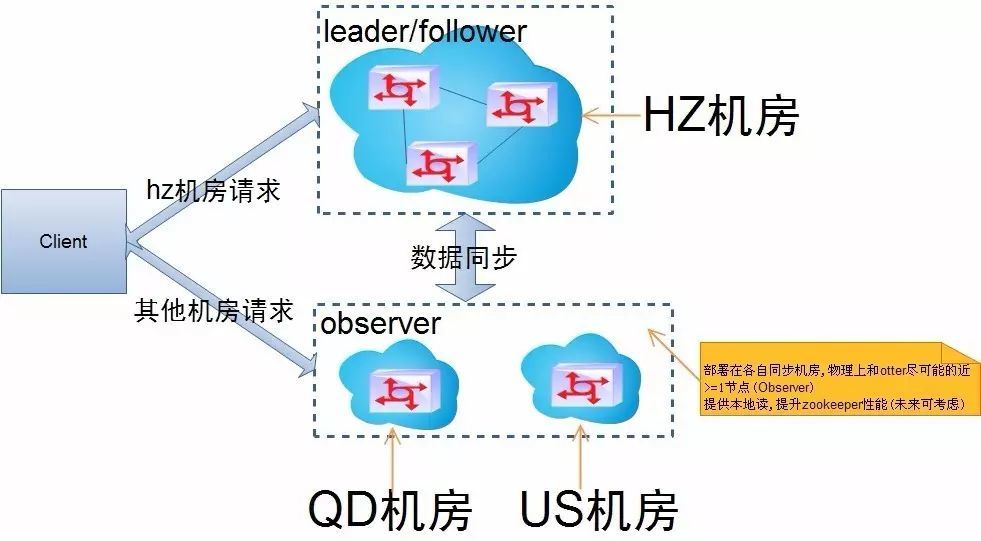
一句话概括就是: 在单个机房内组成一个投票集群,外围的机房都会是一个observer集群和投票集群进行数据交互。 这样部署的一些好处,大家可以细细体会一下。
针对这样的部署结构,我们就可以实现就近访问: 比如在美国机房的机器就去优先访问本机房的zk集群,访问不到后才去访问杭州机房。
默认在zookeeper3.3.3的实现中,认为所有的节点都是对等的。并没有对应的优先集群的概念,单个机器也没有对应的优先级的概念。
扩展代码:(比较暴力,采用反射的方式改变了zk client的集群列表)
- 先使用美国机房的集群ip初始化一次zk client
- 通过反射方式,强制在初始化后的zk client中的server列表中又加入杭州机房的机器列表
Java代码
ZooKeeper zk = null;
try {
zk = new ZooKeeper(cluster1, sessionTimeout, new AsyncWatcher() {
public void asyncProcess(WatchedEvent event) {
//do nothing
}
});
if (serveraddrs.size() > 1) {
// 强制的声明accessible
ReflectionUtils.makeAccessible(clientCnxnField);
ReflectionUtils.makeAccessible(serverAddrsField);
// 添加第二组集群列表
for (int i = 1; i < serveraddrs.size(); i++) {
String cluster = serveraddrs.get(i);
// 强制获取zk中的地址信息
ClientCnxn cnxn = (ClientCnxn) ReflectionUtils.getField(clientCnxnField, zk);
List<InetSocketAddress> serverAddrs = (List<InetSocketAddress>) ReflectionUtils
.getField(serverAddrsField, cnxn);
// 添加第二组集群列表
serverAddrs.addAll(buildServerAddrs(cluster));
}
}
}
异地双活思维误区
异步双活思维误区:
1、所有业务异地多活!
2、实时一致性。我要所有数据都同步!
3、只使用存储系统的同步功能!
4、我要保证业务100%可用!
5、所有用户异地多活
一句话谈“异地多活”
综合前面的分析,异地多活设计的理念可以总结为一句话:采用多种手段,保证绝大部分用户的核心业务异地多活!
选型时需要考虑的维度
以下是方案选型时需要考虑的一些维度:
- 能否整业务迁移:如果机器资源不足,建议优先将一些体系独立的服务整体迁移,这样可以为核心服务节省出大量的机架资源。如果这样之后,机架资源仍然不足,再做异地多活部署。
- 服务关联是否复杂:如果服务关联比较简单,则单元化、基于跨机房消息同步的解决方案都可以采用。不管哪种方式,关联的服务也都要做异地多活部署,以确保各个机房对关联业务的请求都落在本机房内。
- 是否方便对用户分区:比如很多游戏类、邮箱类服务,由于用户可以很方便地分区,就非常适合单元化,而SNS类的产品因为关系公用等问题不太适合单元化。
- 谨慎挑选第二机房:尽量挑选离主机房较近(网络延时在10ms以内)且专线质量好的机房做第二中心。这样大多数的小服务依赖问题都可以简化掉,可以集中精力处理核心业务的异地多活问题。同时,专线的成本占比也比较小。以北京为例,做异地多活建议选择天津、内蒙古、山西等地的机房。
- 控制部署规模:在数据层自身支持跨机房服务之前,不建议部署超过两个的机房。因为异地两个机房,异地容灾的目的已经达成,且服务器规模足够大,各种配套的设施也会比较健全,运维成本也相对可控。当扩展到三个点之后,新机房基础设施磨合、运维决策的成本等都会大幅增加。
- 消息同步服务化:建议扩展各自的消息服务,从中间件或者服务层面直接支持跨机房消息同步,将消息体大小控制在10k以下,跨机房消息同步的性能和成本都比较可控。机房间的数据一致性只通过消息同步服务解决,机房内部解决缓存等与消息的一致性问题。跨机房消息同步的核心点在于消息不能丢,微博由于使用的是MCQ,通过本地写远程读的方式,可以很方便的实现高效稳定的跨机房消息同步。
人们的总结以及经验
1 、如果业务量不大,没必要做异地多活,因为异地多活需要的运维资源成本、开发成本都非常高; 2 、注意机房间的延时问题,延时大的可能达到100ms以上,如果业务需要多次跨机房请求应用的话,延迟的问题会彻底放大; 3 、跨机房的专线很大概率会出问题,要做好运维或者程序层面的容错; 4 、不能依赖MySQL双写,必须有适应自身业务的跨机房消息同步方案; 5 、MySQL或者其他存储的数据同步问题,在高延时和较差的网络质量的情况下,考虑如何保证同步质量; 6、 考虑使用docker等容器虚拟化技术,提高动态调度能力;
7、Devops流程配套。devops要支持推送到两个机房。
真实的异地双活案例
真实的异地双活案例:
5.27日下午17时许,支付宝被反映故障;18时许,支付宝通过官方微博给出回应,解释是因为电信运营商光纤被挖断。19时许,支付宝服务恢复正常。22时许,支付宝官方微博正式回应复原了整个事件。 围绕整个事件有很多讨论,讨论的中心最主要的有两点:“为什么光纤被挖断,会造成整个机房瘫痪”、“为什么支付宝的业务恢复用了两个小时”。 其中,第一个问题,应该是电信运营商的光纤灾备出现问题。第二个焦点问题“为什么支付宝用了2个小时恢复了业务”,一堆所谓“业内人士”众说纷纭。其实,这应该是中国金融史上,首次完全意义的灾难成功切换案例。 在此之前,中国金融行业投入重金建设的灾备系统基本上有这么两类用武之地(一般来说,增建一个灾备数据中心的建设成本是单数据中心成本的1.1-1.2倍): 1,计划内灾备切换演习,全副武装、如临大敌、不开一枪、全身而退。 2,因系统升级造成的被动灾备切换。 例如2013年闹得沸沸扬扬的某行DB2升级造成的系统回滚切换。万幸的是,这是发生在凌晨的系统升级故障,当时没有实时交易发生;某行也准备了各种应急预案,只是恢复的时间超出了计划,网点推迟了一个小时开业而已;而另一家西部的区域银行就没有这么强的科技实力了,同样是DB2升级失败,系统恢复时间用了37小时40分钟(37小时啊,吼吼,坐火车都到莫斯科了) 像支付宝这种突发情形下的灾备切换还真是头一遭,而且居然成功了。支付宝虽然运气差了点,但技术能力还真不是一般金融机构能拼的。 在支付宝微博答复中,有一个新名词——“异地多活”。在传统了灾备方案中,一般提的都是同城灾备、异地灾备、两地三中心。与传统的灾备技术相比,异地多活的特点是:在不同地点的数据中心都可以同时支持业务,而且每个地点发生的交易都是真实业务流量,而不是常见的一主一备,如果主中心没有问题,备份中心永远都是“备胎”。 这种多活数据中心的好处是:因为所有的数据中心都在支持交易,所以能节约IT成本;另外传统方式中备份系统都不在真实的交易活动状态,所以很难判断它的状态到底怎么样,在出现问题时,都不一定敢切过去。 大规模的“异地多活”,据说目前全球除了阿里能做到,也就Google和Facebook实现了,还是非金融类的业务。中国银行业,只有某国有大行在去年6月份实现了上海同城两个数据中心的双活,是“同城双活”,还没有实现“异地多活”,而且在灾难真正发生时,切换效果如何,还有待验证。 昨天是支付宝“异地双活”第一次真刀实枪的上战场,支付宝因为要满足金融行业的很多要求,特别是对交易一致性、数据完整性等方面的要求,目前还处于小范围试用阶段,没有全体上线,例如昨天杭州机房瘫痪后,有一部分流量跑在支付宝异地机房。因此,在昨天支付宝2小时整体恢复之前,并不是所有交易都停止的,并且基于“异地多活”技术,实现了这部分用户的无感知切换。 对另外没有通过“异地多活”技术切换的交易流量,支付宝选择了最稳妥的做法:首先进行了完整的数据校验,保证所有客户的客户信息、账户信息、资金信息、交易信息都是正确的,一切确认完成后,才重新“开门迎客”。这个过程耗时了一个多小时,不过相比较支付宝数亿客户所对应的校对数据量,这个时间还是可以接受的。 侧面印证切换效果的是:被挖断的光纤修到半夜才恢复,而支付宝的业务在晚间19点多恢复正常。 客观来讲,支付宝的这次表现,是一次说不上完美、但很成功的真实灾难切换,也是中国金融史上第一次在完全突发情形下,成功完成切换的真实案例。整个切换过程中,没有一条客户数据丢失,也体现了金融级的数据高可用要求,虽然切换的时间对用户来说长了点,但“就像是一次跳水,整体完成的质量很高,只是落水时水花没有压好,水花稍微大了点。” 估计经过这次折腾,支付宝全盘推进“异地多活”的速度会加快,可能在今年七八月份实现。
部分内容整理自网络