今天分享一个Python量化策略加速的小技巧,不用修改原有代码,只需在原有代码里新增2行,策略执行速度便可能提高20+倍,正文开始~
现如今,无论是入门量化投资,还是做数据分析、机器学习和深度学习,Python成为了首选编程语言,直观的原因就是容易上手和资源丰富,但Python有个根深蒂固的标签,那就是“开发快,执行慢”,特别是执行for循环和大规模科学计算,速度很是“感人”。

小孩子才做选择,成年人全都要,那有没有可能既有开发效率,也有执行速度呢?
当然可以,现在安排!
那先来假设一个这样的场景,策略在不断接收实时Tick数据,或者是在回测当中模拟实际的数据接收,每进来一个新数据,就重新计算一次布林带(Bollinger Band)。
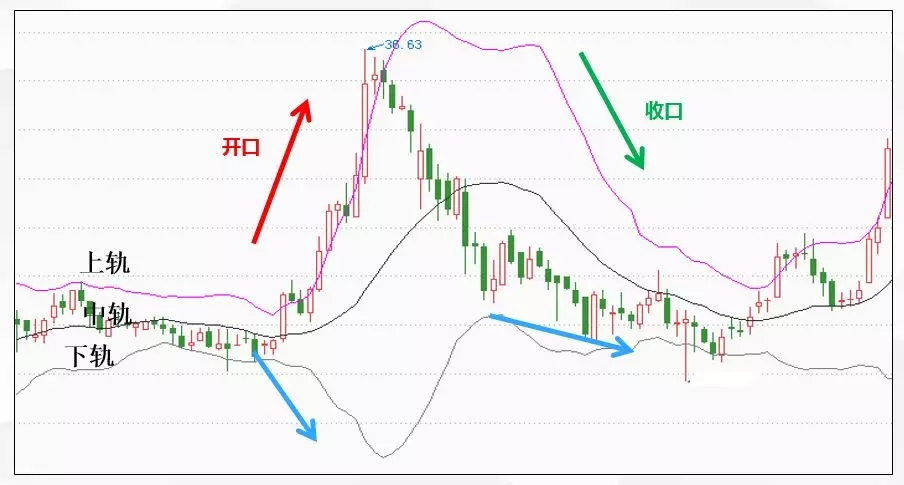
选择使用布林带作为例子是因为它在股票、期货、外汇和Coin量化中都被经常使用,它由三条线组成,一般这三条线从上至下被称为上轨、中轨、下轨,一般情况下,计算方式如下:
上轨 = MA20 + 2×STD
中轨 = MA20
下轨 = MA20 + 2×STD
其中,MA20是长度为20的均线,STD是与均线同长数据序列的标准差,“20”是默认的常用均线长度,人为可调。
假设有100万个数据点(random模块生成100万个随机数),取10次执行时间的平均值作为耗时结果,来看看不利用任何第三方库实现时的执行耗时。
测试环境如下:
处理器: Intel(R) Core(TM) i7-7700HQ @ 2.80GHz
内存:8G
操作系统:Windows10
import time
import random
# 随机生成100万个数据点
data = [random.randint(1, 100) for i in range(1000000)]
# 循环次数
iter_times = 10
# 计算布林带,返回上中下轨数据
def boll(data, periods=20):
up_line = [] # 上轨
mid_line = [] # 中轨
down_line = [] # 下轨
clip = data[:periods] #缓存接收到的数据,控制与periods等长
# 模拟实盘不断接收到新数据
for new_tick in data[periods:]:
# 剔除旧数据点,纳入新数据点,与periods等长
clip.pop(0)
clip.append(new_tick)
# 计算均值
v_sum = 0
for tick in clip:
v_sum += tick
v_mean = v_sum / periods
# 计算标准差
v_sum_std = 0
for tick in clip:
v_sum_std += (tick - v_mean)**2
v_std = (v_sum_std / periods)**0.5
up_line.append(v_mean+2*v_std)
mid_line.append(v_mean)
down_line.append(v_mean-2*v_std)
return up_line,mid_line,down_line
# 记录测试开始时点
start_time = time.time()
for i in range(iter_times):
up_line,mid_line,down_line = boll(data, periods=20)
# 记录测试结束时点
end_time = time.time()
comsued_time = (end_time - start_time) / iter_times
print('布林带boll计算平均耗时:%s秒' %comsued_time)输出结果:
布林带boll计算平均耗时:8.128175449371337秒
这个耗时结果看上去还行,因为这个策略本身任务量也不大,但执行执行速度可不可以更快,耗时可不可以被压缩到1秒内呢?
答案是肯定的,这就要引入量化萌新的Python加速神器——Numba,它是Anaconda公司推出的针对Python的即时(Just-in-time,JIT)编译器,当你调用函数的时候,可以将全部或部分代码转换为“即时”执行的机器码,以本地机器码的速度运行。
简单来说,你不用理会复杂的实现技术,只需要导入这个库,在你的舒适区范围内,就能对函数代码进行优化,将执行速度明显提高。
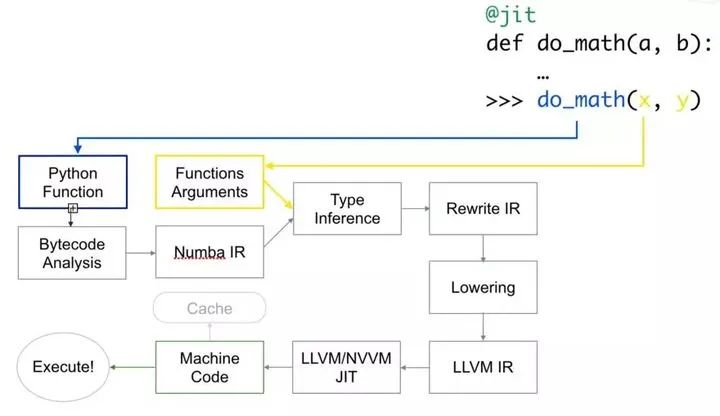
Numba库只需要“pip install numba”就可以直接安装上了,实现加速只需要在原始代码上加入2行代码,第一句就是导入Numba库:from numba import jit,第二句就是在函数前使用Numba的装饰器:@jit(nopython=True)。
Numba编译有两种模式——object模式和nopython模式。
object模式表示JIT解析器无法理解/加速/优化该代码内容,编译后代码执行速度跟原生Python一样慢,还可能更慢。
nopython模式表示强制不进入object模型,生成更快的机器码,若无法编译成功则会抛出异常。
from numba import jit
@jit(nopython=True)
def boll_fast(data, periods=20):
up_line = [] # 上轨
mid_line = [] # 中轨
down_line = [] # 下轨
clip = data[:periods] #缓存接收到的数据,控制与periods等长
# 模拟实盘不断接收到新数据
for new_tick in data[periods:]:
# 剔除旧数据点,纳入新数据点,与periods等长
clip.pop(0)
clip.append(new_tick)
# 计算均值
v_sum = 0
for tick in clip:
v_sum += tick
v_mean = v_sum / periods
# 计算标准差
v_sum_std = 0
for tick in clip:
v_sum_std += (tick - v_mean)**2
v_std = (v_sum_std / periods)**0.5
up_line.append(v_mean+2*v_std)
mid_line.append(v_mean)
down_line.append(v_mean-2*v_std)
return up_line,mid_line,down_line输出结果:
布林带boll_fast计算平均耗时:0.3585397005081177秒
8.128175449371337/0.3585397005081177≈22.7,增加2行代码一下子速度提高了20多倍,Numba的“加速神器”的头衔可不是浪得虚名的,以前需要跑一整天的程序,现在可能都不用看完一部国产电影就可以跑完了。

有的小伙伴可能就有疑问了,你在这个程序里面用了两个for循环计算均值和标准差,太麻烦了,为啥不使用Numpy模块中的mean()和std()函数分别计算均值和标准差,而且Numpy是经过科学计算优化的,速度会更快。
那就利用Numpy模块在相同的情况下重新计算一遍。
# 计算布林带,返回上中下轨数据
def boll_numpy(data, periods=20):
up_line = [] # 上轨
mid_line = [] # 中轨
down_line = [] # 下轨
clip = np.array(data[:periods]) #缓存接收到的数据,控制与periods等长
# 模拟实盘不断接收到新数据
for new_tick in data[periods:]:
# 剔除旧数据点,纳入新数据点,与periods等长
clip[0:periods-1] = clip[1:periods]
clip[-1] = new_tick
v_mean = np.mean(clip)
v_std = np.std(clip)
up_line.append(v_mean+2*v_std)
mid_line.append(v_mean)
down_line.append(v_mean-2*v_std)
return up_line,mid_line,down_line输出结果:
布林带boll_numpy计算平均耗时:42.0557097196579秒

WTF!怎么计算速度还比原来的慢了5倍,这是因为Numpy在复杂对象的开销耗时要比计算优化节省的时间要多,说人话就是,单次处理的数据序列要长(也就是periods数值要大),Numpy的计算优化效果才能展现出来,因为布林带的默认计算均线长度periods是20,算是比较短的,我们把它增加到200试一试。
start_time = time.time()
for i in range(iter_times):
up_line,mid_line,down_line = boll(data, periods=200)
end_time = time.time()
comsued_time = (end_time - start_time) / iter_times
print('布林带boll计算平均耗时:%s秒' %comsued_time)
start_time = time.time()
for i in range(iter_times):
up_line,mid_line,down_line = boll_numpy(data, periods=200)
end_time = time.time()
comsued_time = (end_time - start_time) / iter_times
print('布林带boll_numpy计算平均耗时:%s秒' %comsued_time)输出结果:
布林带boll计算平均耗时:68.52809438705444秒
布林带boll_numpy计算平均耗时:43.69762210845947秒
你看是不是这下子使用Numpy库的速度比原来使用for循环的速度快多了,而且随着单次处理数据序列的增加,Numpy的执行耗时提升不明显,所以说,在单次处理数据序列短的情况下,使用Numpy的效果未必有时用for循环的要好。
如果也对使用Numpy计算布林带的程序(periods=20)也进行加速,看看效果如何。
from numba import jit
@jit(nopython=True)
# 计算布林带,返回上中下轨数据
def boll_numpy_fast(data, periods=20):
up_line = [] # 上轨
mid_line = [] # 中轨
down_line = [] # 下轨
clip = np.array(data[:periods]) #缓存接收到的数据,控制与periods等长
# 模拟实盘不断接收到新数据
for new_tick in data[periods:]:
# 剔除旧数据点,纳入新数据点,与periods等长
clip[0:periods-1] = clip[1:periods]
clip[-1] = new_tick
v_mean = np.mean(clip)
v_std = np.std(clip)
up_line.append(v_mean+2*v_std)
mid_line.append(v_mean)
down_line.append(v_mean-2*v_std)
return up_line,mid_line,down_line输出结果:
布林带boll_numpy_fast计算平均耗时:0.5330439805984497秒
42.0557097196579/0.5330439805984497≈78.8,当periods=20时,Numba为布林带的计算加速了70+倍。
当periods=200时也进行加速测试,输出结果:
布林带boll_numpy_fast计算平均耗时:1.3904209852218627秒
43.69762210845947/1.3904209852218627≈31.4,当periods=200时,Numba为布林带的计算加速了30+倍。这从侧面也说明了,单次处理序列长度越长,Numpy的计算优化效果就越好,剩余的优化“压榨空间”也就不多了。
小结一下,无论是对“原始Python”,还是对第三方库Numpy,Numba都有明显的加速作用,而且对Numpy的加速作用更明显。所以,大家可以在“使用for循环”和“使用Numpy模块做大量科学计算”时,使用Numba模块进行加速。
使用Numba进行加速的方式也非常舒适:
在源码文件头部加入:from numba import jit在需要加速的函数前加入:@jit(nopython=True)
最后补充说明:
Numba并不能对所有的程序优化和加速,常用的优化场景是for循环和Numpy、cmath模块的计算。不能优化和加速的情况,若带有nopython=True参数,会出现异常(Exception),此时可改为使用其他Python解析器(例如PyPy),或者优化算法。
参考资料:
http://numba.pydata.org/numba-doc/latest/user/index.html
https://github.com/ContinuumIO/gtc2018-numba
http://stephanhoyer.com/2015/04/09/numba-vs-cython-how-to-choose/