论文提出了latent diffusion models (LDMs)。基于该模型最著名的工作是文本生成图像模型stable-diffusion。
普通的扩散模型在像素空间操作,运算复杂度较高。为了保证在低资源下训练扩散模型,并保留扩散模型的质量和灵活性,该论文使用预训练的自编码器得到隐含空间,并在隐含空间中训练扩散模型。另一方面,该论文使用cross-attention机制为扩散模型引入条件,条件可以是文本、bounding box等。
方法
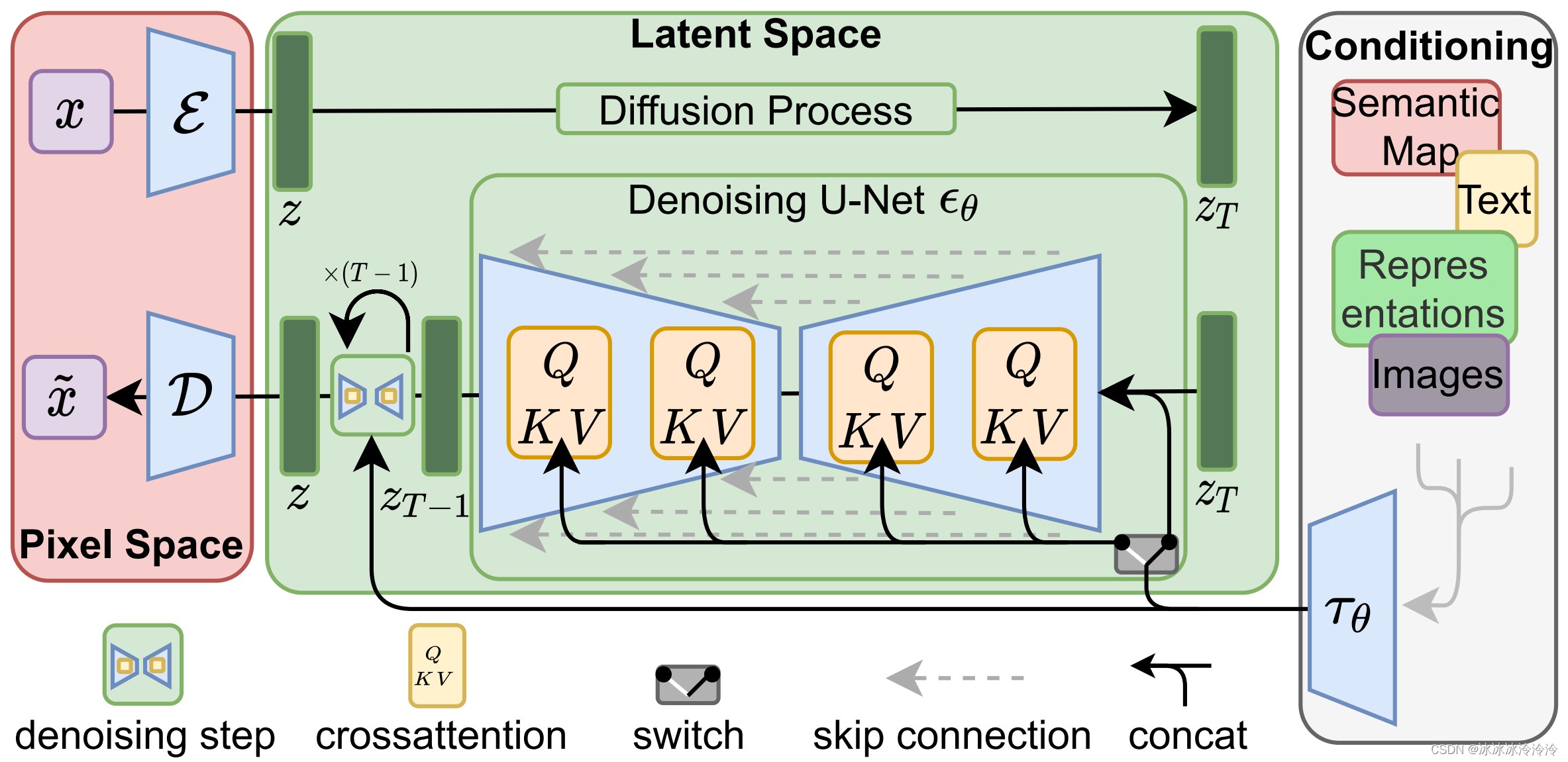
方法的整体结构如上图。
先用自编码器训练通用的压缩模型(红色部分),通用的压缩模型可以用来训练不同的扩散模型。
之后在自编码器的低维隐含空间上训练扩散模型(绿色部分),降低运算复杂度。
图片压缩
使用perceptual loss和patch-based adversarial objective训练一个自编码器用于图片的压缩。
用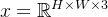
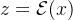
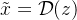
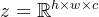
为了避免隐含空间有过高的方差,作者使用了两种regularization。
- KL-reg。类似VAE,假设隐含表示服从标准正太分布。
- VQ-reg。解码器使用vector quantization layer。
隐含扩散模型
普通的扩散模型的优化公式如下:
压缩模型被训练好后,就得到了低维的隐含空间。这个空间对于likelihood-based生成模型的好处是,生成模型可以更关注重要的语义信息,并且可以更为高效地训练。
论文提出在隐含空间训练扩散模型。基于隐含表示的扩散模型优化的公式如下:
其中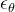
条件机制
作者通过使用cross-attention机制来补充UNet以引入条件。cross-attention的计算如下:
其中 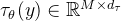
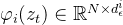
基于条件的隐含扩散模型优化公式如下:
遇到的一些名词
Bits Per Dimension
在论文的分析图中出现了bits/dim。这个是指标负log-likelihood除以图片的维度的单位。该指标越小模型性能越好。负log-likelihood等于用熵编码法(entropy coding scheme)无损压缩所需要的平均bit数。
The total discrete log-likelihood is normalized by the dimensionality of the images (e.g., 32 × 32 × 3 = 3072 for CIFAR-10). These numbers are interpretable as the number of bits that a compression scheme based on this model would need to compress every RGB color value.
参考:《Pixel Recurrent Neural Networks》