索引是帮助数据库高效获取数据的排好序的数据结构。
数据是如何存储与读取的?
1. 索引采用了什么数据结构呢?
常见的数据结构有:hash、二叉树、红黑树、B树、B+树。
首先来看如果采用Hash,它是把数据进行Hash直接对应磁盘存储引用地址,这样查找数据直接告诉磁盘数据在哪,查询很快。但是 hash 还是有些不足:那就是不能范围查找,如果通过大于或者小于去筛选数据,就需要扫描整个hash表,效率大大降低了。当然mysql还是提供了Hash索引,毕竟有些场合还是用起来也不错。
采用二叉树,每个节点存储了索引对应字段的值,这样我们根据索引去查询时就可以避免全表扫描,时间复杂度降为O(log n)。看起来很美好,但是二叉树在值单边递增的情况下回退化到链表。
采用红黑树,又叫自平衡二叉树,会通过特定操作保持二叉查找树的平衡,避免了单边增长的问题,从而获得较高的查找性能。
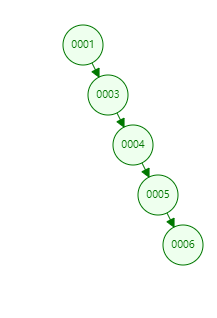
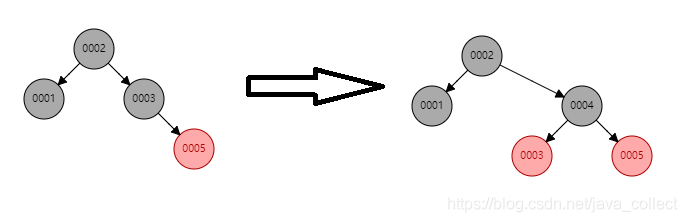
从上面我们发现,红黑树相比较于二叉树又进步了一些,但红黑树还是有些问题:那就是数据量大的话,红黑树的深度会很深,也就是说深