一、论文简介
https://github.com/microsoft/graphrag
该论文介绍了一种基于图的检索增强生成(Graph RAG)方法,用于针对私有文本语料库进行问题回答。这种方法结合了大语言模型(LLM)和图索引,通过创建一个实体知识图并生成社区摘要,以应对全局性问题。传统的RAG方法在面对整个文本语料库的全局性问题时表现不佳,而该方法通过图索引和社区检测来克服这一挑战。
二、方法
流程
论文提出的Graph RAG方法包含以下步骤:
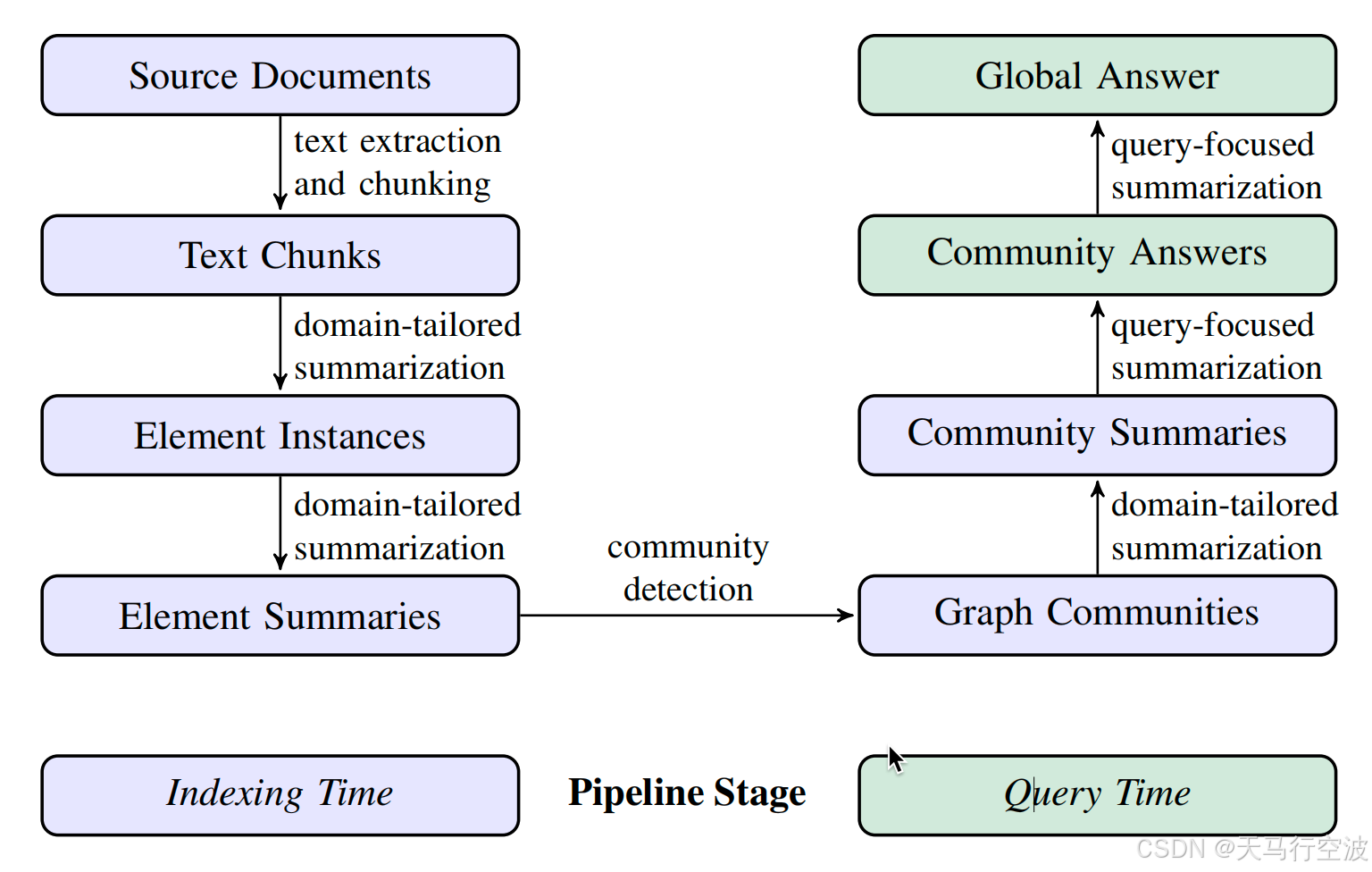
索引阶段
-
文本提取和分块:将源文档分割成较小的文本块。
-
元素实例化:使用LLM提取文本块中的实体及其关系,并生成描述。
-
元素摘要:将相同实体的描述汇总成单个摘要。
-
社区检测:使用Leiden算法将图分割成多个社区。
-
社区摘要:对每个社区生成报告式的摘要。
查询阶段
循环检测实体
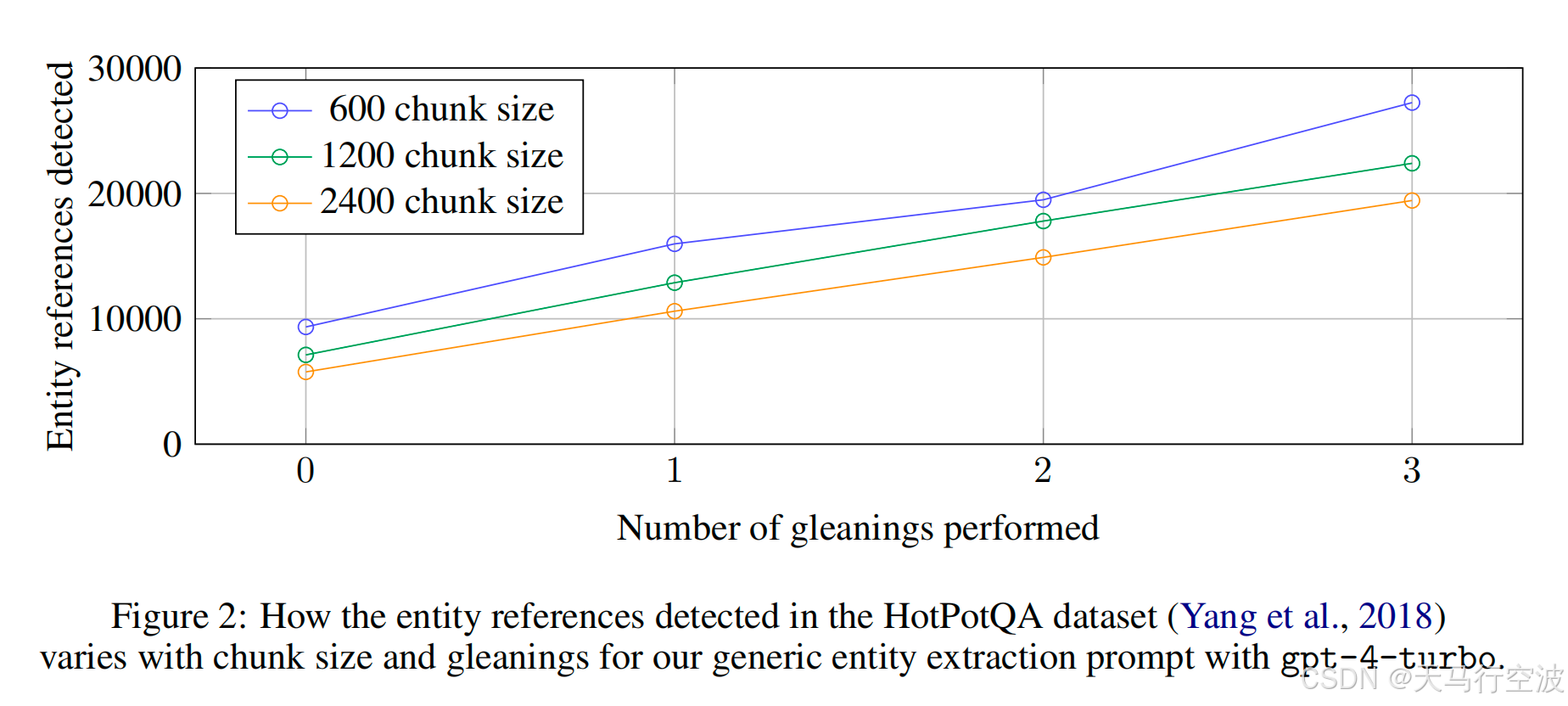
在相同的收集次数下,原始文档被切分 chunk size 越小,实体检测到的引用会越多。虽然一般来说引用越多越好,但任何提取过程都需要平衡任务的召回率和准确度。
Leiden算法
Leiden算法是一种聚类算法,可以将类似的数据点分组到一起形成簇。它基于模块化最大化原理,试图找到一个最优的分割,使得分割后的子图内部密度较大,子图之间联系较小。与传统的聚类算法相比,Leiden算法更适用于处理大规模高维数据。

三、代码实现
Graph RAG的实现是开源的,并且提供了Python版本。论文提供了详细的实现步骤和参数设置,接下来我们一步一步来看源码。中间有很多字段映射 ,数据组装,数据排序,数据筛选,数据聚合,数据压缩、解压缩的流程就不展开细讲,主要讲大的实现过程中的核心代码。由于代码长度过长,部分代码进行了缩减为一行,如需看源码可以直接点击对应步骤代码上方对应的源码链接查看。
https://aka.ms/graphrag
https://github.com/microsoft/graphrag
3.1 文本切分
根据 token 切分源文档
文本切分就是将一段长文本对象分割成多个较小的文本块,并确保这些文本块之间有一定的重叠,这个流程比较通用。当然tokens_per_chun、chunk_overlap的选择也会不同程度的影响效果。
def split_text_on_tokens(*, text: str, tokenizer: Tokenizer) -> list[str]:
"""Split incoming text and return chunks using tokenizer."""
splits: list[str] = []
input_ids = tokenizer.encode(text)
start_idx = 0
cur_idx = min(start_idx + tokenizer.tokens_per_chunk, len(input_ids))
chunk_ids = input_ids[start_idx:cur_idx]
while start_idx < len(input_ids):
splits.append(tokenizer.decode(chunk_ids))
# tokens_per_chunk: 每个块的最大 token 数量
# chunk_overlap: 块之间的重叠 token 数量
# 考虑到块之间的重叠
start_idx += tokenizer.tokens_per_chunk - tokenizer.chunk_overlap
cur_idx = min(start_idx + tokenizer.tokens_per_chunk, len(input_ids))
chunk_ids = input_ids[start_idx:cur_idx]
return splits
3.2 实体和关系提取
每条 chunk 提取元素
元素实例化主要依靠 提取元素 prompt 模版 利用大模型来提取对应的实体以及实体间关系,再使用循环提取模板和判断是否继续模板 来确保能最大化收集对应数据。具体模板已经贴在下面
async def _process_document(
self, text: str, prompt_variables: dict[str, str]
) -> str:
# 提取元素
response = await self._llm(self._extraction_prompt, variables={**prompt_variables, self._input_text_key: text,},)
results = response.output or ""
# 重复收集
for i in range(self._max_gleanings):
glean_response = await self._llm(CONTINUE_PROMPT, name=f"extract-continuation-{i}", history=response.history or [],)
results += glean_response.output or ""
# 达到最大次数停止
if i >= self._max_gleanings - 1:
break
continuation = await self._llm(LOOP_PROMPT, name=f"extract-loopcheck-{i}", history=glean_response.history or [], model_parameters=self._loop_args,)
# 大模型认为没有遗漏,停止
if continuation.output != "YES":
break
return results
创建图
主要步骤:
- 初始化图。
- 遍历结果并分割记录,处理每条记录,分割记录属性。
- 根据属性更新或创建实体节点、关系。
- 返回构建的图。
async def _process_results(self, results: dict[int, str], tuple_delimiter: str, record_delimiter: str,) -> nx.Graph:
"""Parse the result string to create an undirected unipartite graph.
"""
graph = nx.Graph()
for source_doc_id, extracted_data in results.items():
records = [r.strip() for r in extracted_data.split(record_delimiter)]
for record in records:
# 遍历结果并分割记录
record = re.sub(r"^\(|\)$", "", record.strip())
record_attributes = record.split(tuple_delimiter)
if record_attributes[0] == '"entity"' and len(record_attributes) >= 4:
# 将此实体作为节点添加到图中
entity_name = clean_str(record_attributes[1].upper())
entity_type = clean_str(record_attributes[2].upper())
entity_description = clean_str(record_attributes[3])
if entity_name in graph.nodes():
# 实体节点存在 实体节点内容拼接
node = graph.nodes[entity_name]
if self._join_descriptions:
node["description"] = "\n".join(list({*_unpack_descriptions(node), entity_description,}))
else:
if len(entity_description) > len(node["description"]):
node["description"] = entity_description
node["source_id"] = ", ".join(list({*_unpack_source_ids(node), str(source_doc_id),}))
node["entity_type"] = (entity_type if entity_type != "" else node["entity_type"])
else: # 实体节点不存在 创建实体节点
graph.add_node(entity_name, type=entity_type, description=entity_description, source_id=str(source_doc_id),)
if (record_attributes[0] == '"relationship"' and len(record_attributes) >= 5):
# 将此关系作为边添加到图中
source = clean_str(record_attributes[1].upper())
target = clean_str(record_attributes[2].upper())
edge_description = clean_str(record_attributes[3])
edge_source_id = clean_s