文章目录
线检测目前的排名(20210715):
paper with code的整理如下:
https://paperswithcode.com/sota/line-segment-detection-on-wireframe-dataset
F1 score 在 0.8以上的有四个,由高到低分别为:LETR>ELSD>HAWP>M-LSD
LETR code:https://github.com/mlpc-ucsd/LETR
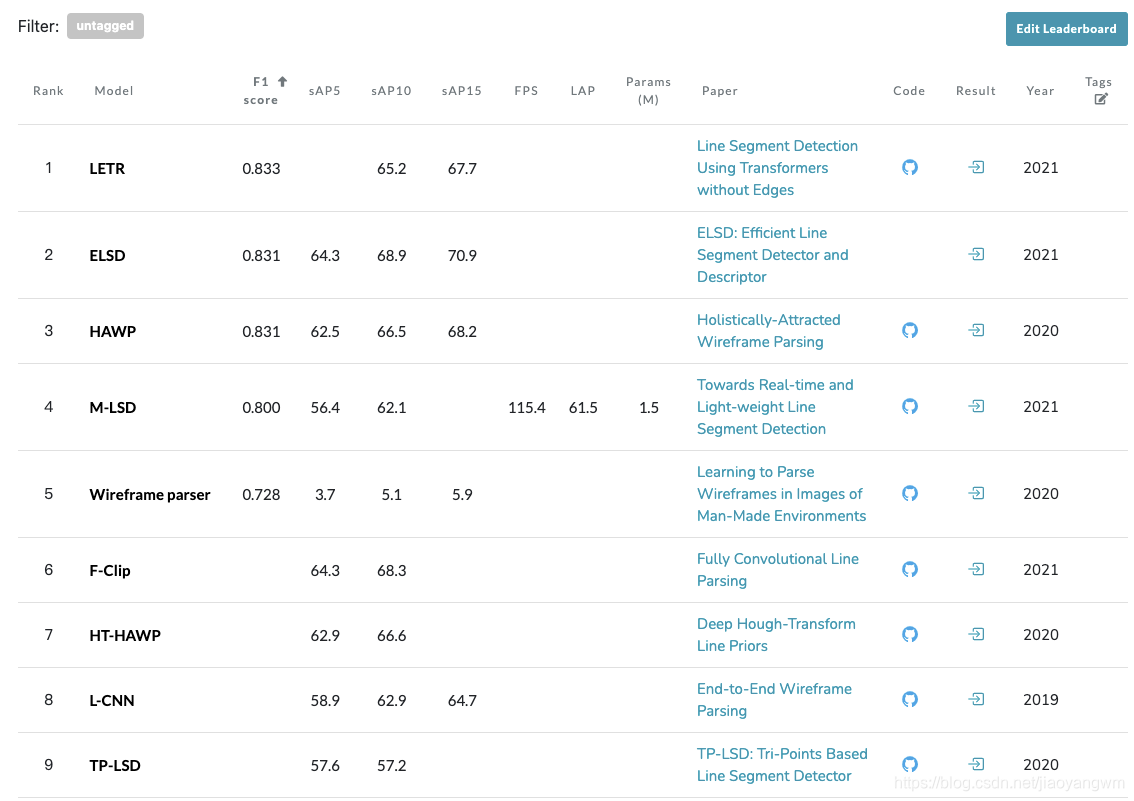
ELSD code: None
HAWP code: https://github.com/cherubicXN/hawp
M-LSD code: https://github.com/lhwcv/mlsd_pytorch
一、背景
现有的基于深度学习的 line segment detection (LSD) 方法,大都使用大体量的模型,时间消耗较大,这就限制了该种方法在实时场景下的应用。

线检测或角点检测都是很重要的 low-level 任务,是姿态估计、3D 识别、图像匹配、线到框架的生成等任务的基础。
但这种模型往往由于模型大小和算力的影响,难以在移动端部署,所以,如何来平衡速度和准确率,是该文章想要解决的问题。
使用深度学习来做线检测的方法主要有三个类型:
- Top-down[30]:先检测包含线段的区域,然后通过 squeeze region 来预测线段
- Bottom-up[10,11,31,35,36]:首先检测junctions,然后把这些点汇聚成线段,最后使用分类/聚合等方式来验证是否为线段
- Tri-Points(TP):[12] 提出了 TP 的表示方法,去掉了耗时的 line proposal 和 verification 的步骤。
二、动机
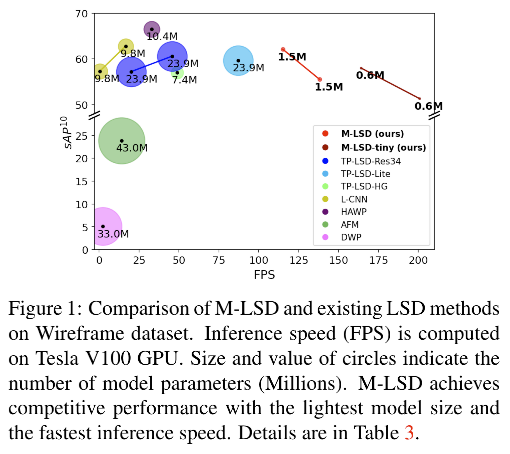
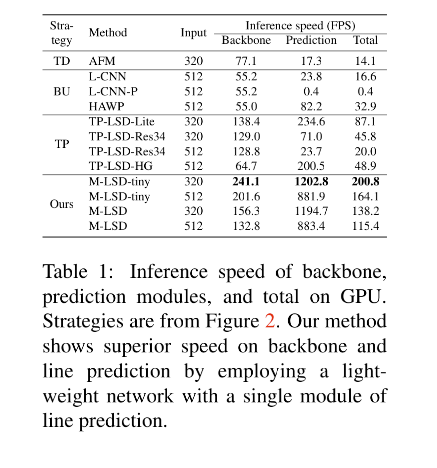
Tabel 1 展示了一些 real-time 的方法,虽然这些方法是为了实时而提出的,但仍然依赖于GPU,因为这些方法大都使用了庞大的backbone(Res50/hourglass/U-net)。这样的形式使得这些方法难以部署到算力受限的平台。所以本文作者提出了一个可以在 Mobile 设备上部署的方法,Mobile LSD(M-LSD)。
三、方法
M-LSD 的初衷是为了实现准确率和速度的平衡,故其:
- 使用轻量级backbone,减小了用于线预测的模型大小
- 使用了额外的训练方式(SoL augmentation && geometric learning) 来捕捉几何信息
3.1 Light-weight backbone
作者建立了两种模型:
- light: M-LSD(输入 64-channels)
- lighter: M-LSD tiny (输入 96-channels)
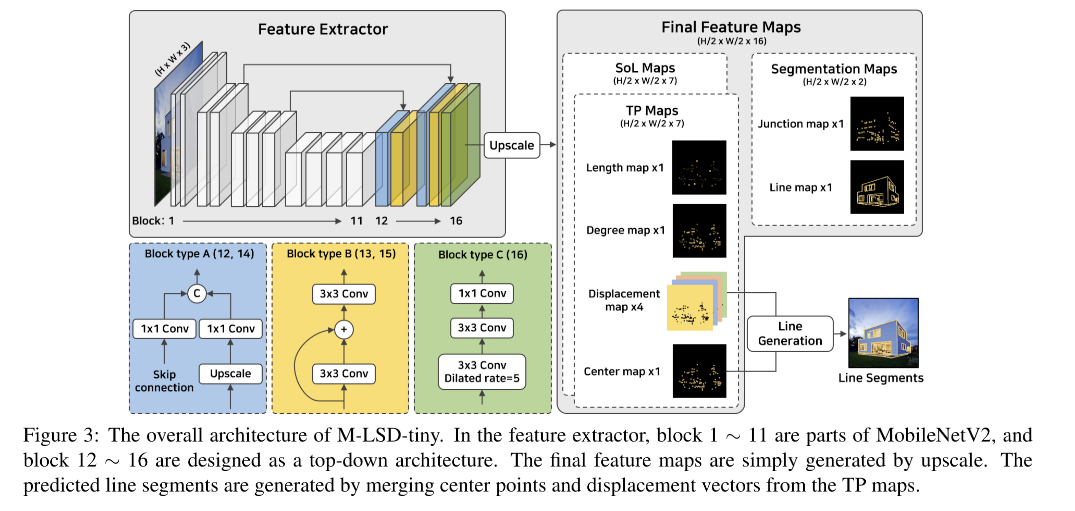
结构:encoder-decoder
- encoder:MobileNetV2 (block 1~11)
- decoder:使用 3 种 block 的组合
- A: 第12层和第14层的结构:把从第11层上采样的结果和第7层的结果进行concat,13层上采样的结果和第4层的结果进行concat。
- B: 第13层和第15层的结构:残差结构
- C: 第16层的结构:卷积结构
输入输出大小:
- 输入: H ∗ W ∗ 3 H * W * 3 H∗W∗3
- 输出: H / 2 ∗ W / 2 ∗ 16 H/2 * W/2 * 16 H/2∗W/2∗16
不同 channel 的不同任务:
- TP maps:7个,包括1个length map, 一个 degree map,1 个center map,4个 displacement map
- SoL maps: 7个,和 TP maps 的构成一样
- Segmentation maps:2个,1 个 junction map,1 个 line map
3.2 Line Segment Representation
线段的表达方式决定了如何生成线段并且会很大的影响 LSD 的效果
作者使用 [12] 中提出的 TP 表达方式,即使用3个 key-points 来描述一条线:
- start: l s l_s ls
- center: l c l_c lc
- end points: l e l_e le
起始点和终止点是使用和中间点有关的位移向量 ( d s , d e ) (d_s, d_e) (ds,de) 表示的,如图4a所示:
生成线的过程,就是把中心点和位移向量转化成一个线段的过程:

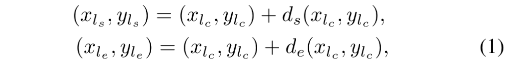
- Center point 和 位移向量的训练:使用 1 个 center map,4 个位移 maps
- Center point的获得:Center map 的真值生成过程如下,center point 的位置是在全零的map上标记的,然后使用3x3的高斯核来进行尺度缩放。在生成线的过程中,作者在 center map 上使用 NMS 来得到精确的 center point。
- 线段的生成:使用得到的 center point 和位移向量,使用上面的公式来计算得到
- 训练 center map的损失函数:weighted binary cross-entropy loss,但由于前景和背景的极度不平衡,easy negative 占据了很大的空间,降低了 WBCE 的效果。所以作者把前景和背景的loss分开了,如下所示:
- I ( p ) I(p) I(p):1 → 当真值为非零;0 → 当真值为零
- σ \sigma σ:sigmoid 函数
- W ( p ) W(p) W(p):GT 中的像素值
- F ( p ) F(p) F(p):特征图中的像素值
- center loss L c e n t e r = l c l s ( C ) L_{center}=l_{cls}(C) Lcenter=lcls(C),其中C是 center map,且 ( λ p o s , λ n e g ) = ( 1 , 30 ) (\lambda_{pos}, \lambda_{neg}) = (1, 30) (λpos,λneg)=(1,30)
- 位移 loss L d i s p L_{disp} Ldisp:smooth L1
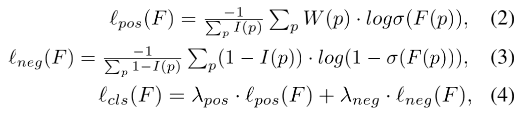
3.3 SoL Augmentation
为了增加更多的长度变化更广泛的线段用于训练,作者提出了线段 (SoL)增强。
原因在于:
在某些情况下,学习带有中心点和位移向量的线段可能是不够的,比如线段可能太长,无法在感受野内处理,或者两个不同线段的中心点彼此太近。
做法:
SoL 是将和其他线段有重叠的想到进行了切分,
3.4 Learning with Geometric Information
为了提升预测的效果,作者使用了多个不同的线段几何信息来提升学习的效果:
- matching loss
- junction and line segmentation
- length and degree regression
3.4.1 Matching Loss
在使用 TP 的方式表达线段的前提下,分别使用 center 和 displacement(位移)loss 来优化是自然而然的。
但是,这两者耦合的信息却没有被使用上
所以,作者提出了 matching loss,可以利用 ground truth 的耦合信息,同时在 TP 和 SoL maps 中使用。
如图5a所示,matching loss 会促使生成的线段更像和它匹配上的真值线段,即会优化起始点、终止点、中点, l ^ \hat{l} l^ 表示预测, l l l 表示真实线段。
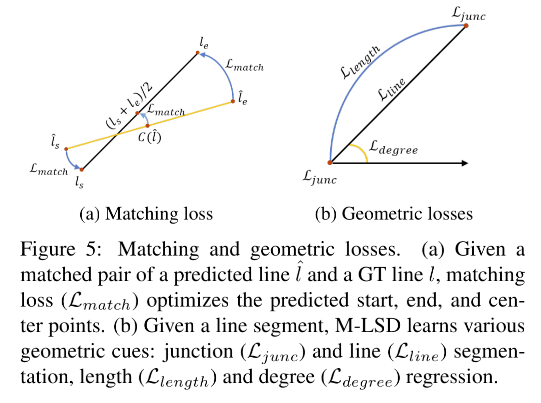
- 首先,可以通过线生成的过程产生 endpoint
- 然后,计算预测的 endpoint 和真实 endpoint 的欧氏距离 d ( . ) d(.) d(.)
- 之后,使用阈值判断的方式,匹配预测的线段和真实线段,
γ
=
5
\gamma=5
γ=5,得到一系列的匹配线段对儿
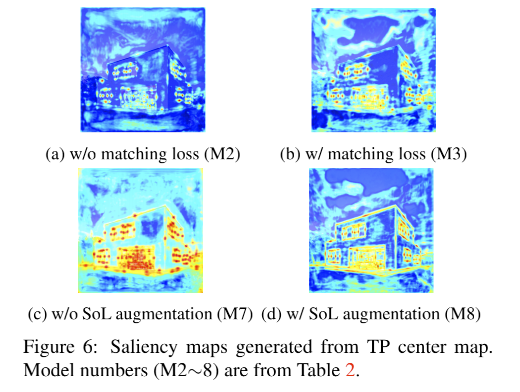
- 最后,使用 L1 loss,来最小化匹配对儿的几何距离,包括起始点、终止点、中点:
- 如图6a,不带 matching loss 的特征图中,对 center point 的关注较少
- 如图6b,带 matching loss 的特征图中,对 center point 的关注更强些
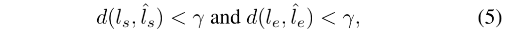
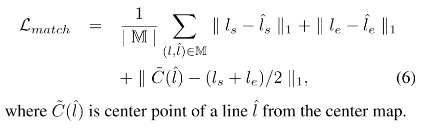
3.4.2 Junction and Line Segmentation
学习 junction 和 line segment 的 segmentation map 是空间中非常重要的线索,所以,M-LSD 包含了两个 segmentation maps,1 个 junction map,1 个 line map。
junction GT:使用高斯核来缩放得到, L j u n c = l c l s ( J ) L_{junc}=l_{cls}(J) Ljunc=lcls(J),J 为 junction map
line GT:二值化 map, L l i n e = l c l s ( E ) L_{line}=l_{cls}(E) Lline=lcls(E),E 为 line map
总 loss: L s e g = L j u n c + L l i n e L_{seg} = L_{junc} +L_{line} Lseg=Ljunc+Lline
3.4.3 Length and Degree Regression
位移向量可以从线段的 length 和 degree 来推断得到,所以可以作为位移 map 的一个额外的几何信息。
作者从 GT 中计算 length 和 degree,并且在每个 GT map 中标记每个线段的中点。然后把 3x3 区域内的所有点都设置成相同的像素值。
loss:都使用 L1 loss
3.5 Final Loss Function
TP map 的 loss:
SoL map 的 loss:
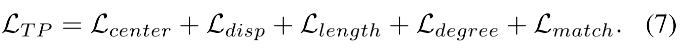
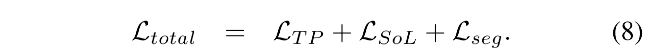
四、效果
4.1 数据集和测评指标
Wireframe:5000 training,462 testing
YorkUrban:102 testing
训练数据集:Wireframe
测试数据集:Wireframe testing + YorkUrban
测评指标:
- F H F^H FH:heatmap-based metric
- s A P sAP sAP: structural average precision
- L A P LAP LAP: structural average precision
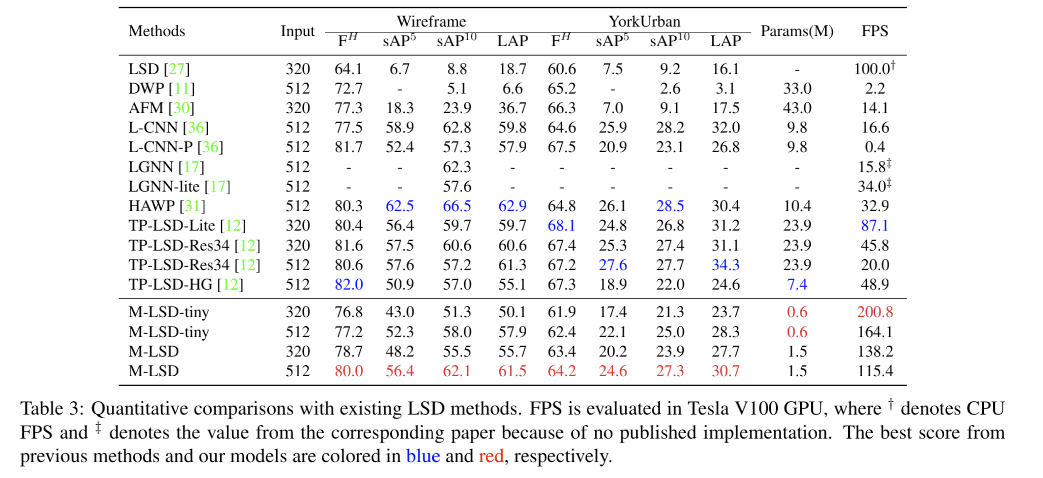
4.2 和其他方法的对比
可视化:蓝色为 junction,橘色为 line

五、代码
5.1 Wireframe 标注数据提取
数据下载:https://drive.google.com/file/d/18totta2M57jqOuimusI041SlIvYDSmZb/view
json 文件下载:https://drive.google.com/u/0/uc?id=18totta2M57jqOuimusI041SlIvYDSmZb&export=download
wireframe 数据集也有用npz形式存储的,每个图片的标注信息保存在一个 npz 文件里边:
以第一张图为例,读取 npz 里边的信息:

import numpy as np
npz_path = './wireframe/train/00030043_0_label.npz'
npz_data = np.load(npz_path)
print('npz_data:', npz_data.files)
>>>
'npz_data:', ['jmap', 'joff', 'lmap', 'junc', 'Lpos', 'Lneg', 'lpos', 'lneg']
其中:
jmap: [J, H, W] Junction heat map (H and W are 4x smaller)
joff: [J, 2, H, W] Junction offset within each pixel (Not sure about offsets)
lmap: [H, W] Line heat map with anti-aliasing (H and W are 4x smaller)
junc: [Na, 3] Junction coordinates (coordinates from 0~128 => 4x smaller.)
Lpos: [M, 2] Positive lines represented with junction indices
Lneg: [M, 2] Negative lines represented with junction indices
lpos: [Np, 2, 3] Positive lines represented with junction coordinates
lneg: [Nn, 2, 3] Negative lines represented with junction coordinates
此处使用 json 格式的标注数据来进行训练
- filename
- lines
- heights
- widths

5.2 YorkUrben 数据集
数据集下载路径:https://www.dropbox.com/sh/qgsh2audfi8aajd/AAAYNbaLAuLN-JfSP7Y4qJWna?dl=0&preview=YorkUrbanDB.zip
json 下载路径同 wireframe
5.3 MLSD 模型结构
MobileV2_MLSD(
(backbone): MobileNetV2(
(features): Sequential(
(0): ConvBNReLU(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(144, 144, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(144, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192, bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192, bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=192, bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(9): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(10): InvertedResidual(
(conv): Sequential(
(0): ConvBNReLU(
(0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(1): ConvBNReLU(
(0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)
(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
(max_pool): MaxPool2d(kernel_size=1, stride=1, padding=0, dilation=1, ceil_mode=False)
)
(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
)
(block12): BlockTypeA(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(block13): BlockTypeB(
(conv1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
)
(block14): BlockTypeA(
(conv1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(24, 32, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(block15): BlockTypeB(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
)
(block16): BlockTypeC(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(5, 5), dilation=(5, 5))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Conv2d(64, 16, kernel_size=(1, 1), stride=(1, 1))
)
(block17): BilinearConvTranspose2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
)
(Pdb)