文章目录
代码:https://github.com/salesforce/BLIP
线上体验:https://huggingface.co/spaces/Salesforce/BLIP
出处:ICML 2022 | Salesforce Research
时间:2022.02
贡献:
- 提出了一个可以联合训练理解和生成任务的多模态混合模型 MED,可以用于单模态编码、基于图像的文本编码、基于图像的文本解码
- 提出了 CapFilt 方法,能够为来源于网络的 image 生成更高质量的文本描述,提高数据集的可靠性和描述丰富性,为下游任务带来性能提升
一、背景
Vision Language Pretraining(VLP)已经很大程度上提升了很多 vision-language 任务的效果
但现有的模型有两个主要的问题:
- Model 层面:现有的很多方法都是使用 encoder 模型或 encoder-decoder 模型,但 encoder-based 模型并不能够很直接的用于文本生成任务,encoder-decoder 模型也不能很好的用于文本检索任务
- Data 层面:现有的方法如 CLIP、ALBEF、SimVLM 在从网络获取的大量 image-text pairs 上训练,其性能提升主要源于数据的堆叠(本文作者也证明了来源于网络的带噪声数据对图文学习并非最优的选择)
本文提出的 BLIP,是一个新的 VLP 框架,为 vision-language 的理解任务和生成任务提供了一个统一的 Language-Image Pre-training 框架,主要贡献在于:
-
Multimodal mixture of Encoder-Decoder (MED):提出了一个可以高效训练多任务且可以灵活迁移的模型解耦 MED
MED 可以作为单模态 encoder,也可以作为 image-grounded text encoder 或 image-grounded text decoder
MED 是使用三个 vision-language 目标函数来训练的:image-text 对比学习,image-text 匹配,图像语言建模
-
Captioning and Filtering (CapFilt):一个针对带噪声的 image-text pairs 数据集的提升的方式
对预训练后的 MED 进行了 finetuned 获得了两个模型,一个是标题生成模型,一个是噪声标题过滤模型
在下面几个任务上都有很好的表现:
- 图文检索
- 图像描述
- 视觉文本问答
二、方法

2.1 模型结构
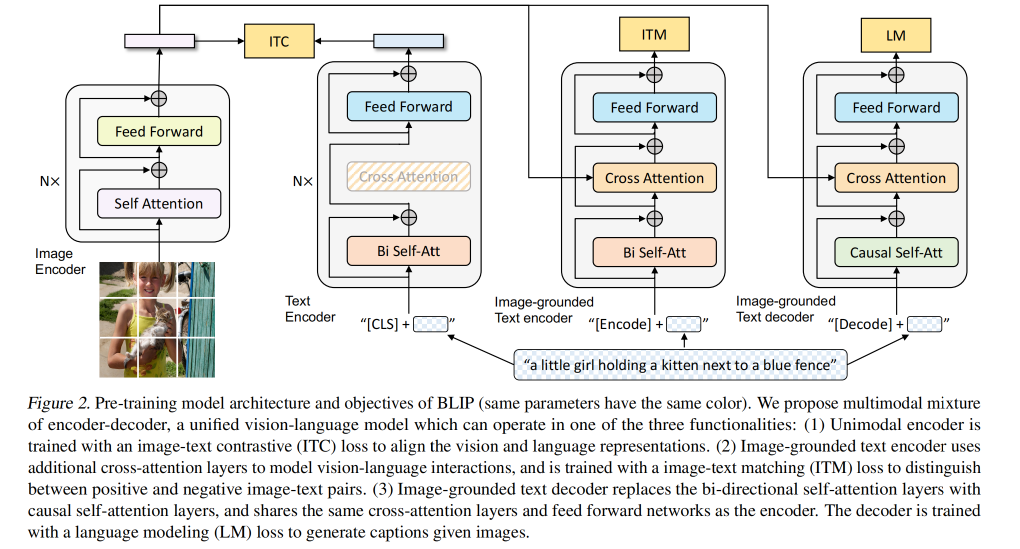
本文的 image encoder 使用的是 Transformer 结构,将图像切分成 patches 然后经过线性映射并加上位置编码和 cls token 后输入 Transformer Layer。
为了训练一个能同时实现理解和生成的统一的模型,提出了 MED,是一个可以实现下面三个任务中任何一个的多任务模型:
- Unimodel encoder:单模态模型,能够对图像或者文本进行编码,text encoder 类似 BERT
- Image-grounded text encoder:通过在多个 self-attention 中插入 cross-attention 来注入视觉信息,然后经过 FFN,text enbedding 中也会有一个 encode token,能拥有表达 image-text pairs
- Image-grounded text decoder:将 image-grounded text encoder 中的双向 self-attention layer 替换为 causal self-attention layer,然后使用 decode token 来标识一个句子的开始,end-of-sequence token 用来标记结束
2.2 Pre-training Objectives
在预训练阶段,作者联合优化三种目标函数,包括两个 understanding-based 目标函数和一个 generation-based 目标函数。
1、Image-text Contrastive Loss(ITC)
用于训练单模态 encoder,学习的目的是为了让正确匹配的 image-text pair 有更高的相似性表达
作者使用 ITC loss,其会引入动量编码器来产生特征,并从动量编码器中创建 soft label 作为训练目标,用于解释 negative pairs 中的潜在 positives
2、Image-Text Matching Loss (ITM)
用于训练 image-grounded text encoder,致力于学习 image-text 的多模态表达并捕捉 vision 和 language 的细粒度对齐
ITM 是一个二分类任务,模型会使用 ITM head 来预测 image-text pair 是匹配(positive)还是不匹配(negtive)
此外,为了挖掘更多的 negative 信息,作者使用了负样本挖掘,在一个 batch 中具有高对比相似度的 negative pairs 会被选择出来并用于计算 loss
3、Language Modeling Loss(LM)
用于训练 image-grounded text decoder,用于生成给定图像的文本描述
使用 cross entropy loss 来训练模型,使用自回归的方式来最大化 text 的似然函数
此外,在计算 loss 的时候作者也使用了 label smoothing(0.1)
相比于 VLP 常用的 MLM loss,LM 能够使得模型在图生文方面有更好的泛化能力
4、其他
为了让预训练更加高效,text encoder 和 text decoder 的参数都是共享的(除过 SA layers 外),encoder 和 decoder 的作用如下,其中间的隐层(CA 和 FFN)都是类似的,所以使用参数共享能够提高训练效率:
- encoder 使用 bi-directional self-attention 来为当前输入 token 建立表达
- decoder 使用 causal self-attention 来预测下一个 token
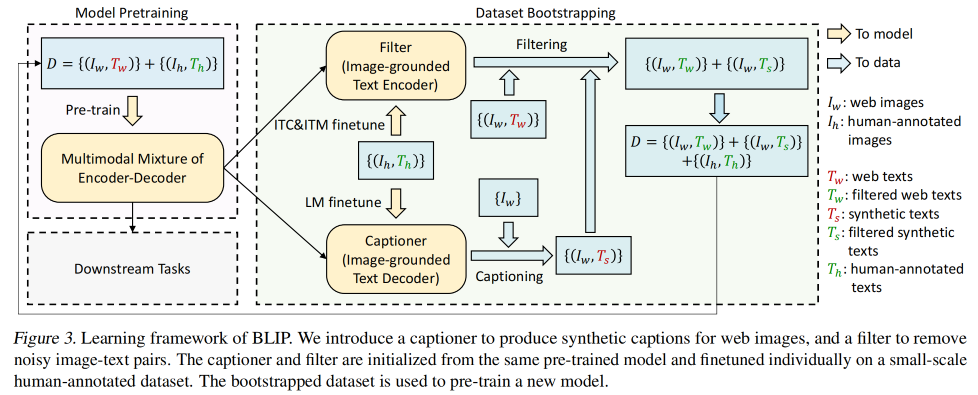
2.3 CapFilt
由于人工高质量标注很贵,所以现有的带标注的 image-text 数据量很少
当前很多 VLP 方法都使用直接从网络上收集的 image 和 alt-text pairs,alt-text 是有特定格式的文本,不能很好的描述一副图像,不能很好的指导模型的学习,会带一些噪声。
所以作者提出了 Captioning and Filtering (CapFilt):一个可以提升文本语料库质量的方法,包括两个模型,而且这两个模型都是使用预训练的 MED 来初始化,在 COCO 上进行微调
- captioner:是一个 image-grounded text decoder,使用 LM 目标函数来微调,为每个 images 解码出一个 text,也就是为给定的 images 生成文本描述
- filter:是一个 image-grounded text encoder,使用 ITC 和 ITM 目标函数来微调,学习图像和文本是否匹配,可以移除网络文本和生成的文本中的 noisy text,如图 ITM head 的预测该文本不和 image 匹配,则认为该文本是 noisy text 剔除掉。filter 的作用就是从 web text 和 合成 text 中选择一个作为 image 的匹配 text
- captioner 和 filter 的联合使用能先为图像生成描述,然后选择更好的描述更新图像所对应的 text 描述,提升 web 数据集的文本描述质量
- 最后,将经过过滤的 image-text pairs 和手工标注的进行组合,形成新的数据集,用于 pre-train
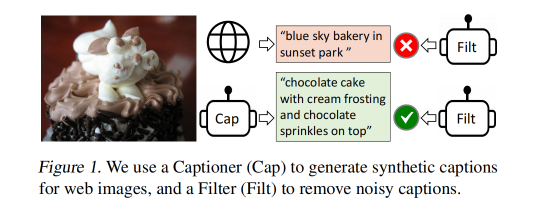
这里可能不太好理解,我们看看下面的图 4:
- T w T_w Tw:直接从网上拿下来的对应的 image 的文本数据,网络上的 text 有好的也有不好的
- T s T_s Ts: captioner 为 image 生成的文本数据,合成的文本数据也有好的也有不好的
- 一个 image 只会对应一个 text 作为匹配标签,所以 filter 的职责是在 T w T_w Tw 和 T s T_s Ts 中选择一个保留下来,绿色的表示 filter 保留下来的 text,红色的表示被 filter 过滤掉的 text
- 也就是说 filter 会在 web text 和 synthetic text 中选择保留下来一个作为 image 的匹配 text

三、效果
3.1 训练细节
在两个 16-GPU 卡上进行预训练
- image transformer 基于 ImageNet 预训练过的 ViT,也拓展了两个 ViTs 的变体:ViT-B/16 和 ViT-L/16(没有特殊声明情况下的实验都是基于 ViT-B)
- text transformer 是 BERT
- 分布使用 batch_size=2880 和 batch_size=2400,来预训练 ViT-B 和 ViT-H,20 个 epochs
- AdamW optimizer,weight decay=0.05
- 在预训练时图像大小为 224x224,finetuned 时图像大小为 384x384
数据集:
- 预训练共使用 1400 万数据
- 包括两个人工标注的数据集(COCO 和 Visual Genome)
- 三个网络数据集(Conceptual Captions、Conceptual 12M、SBU captions)
- 还有一个有很多 noisy text 的网络数据集 LAION,共包含 11500 万 images,在某些实验中会用到
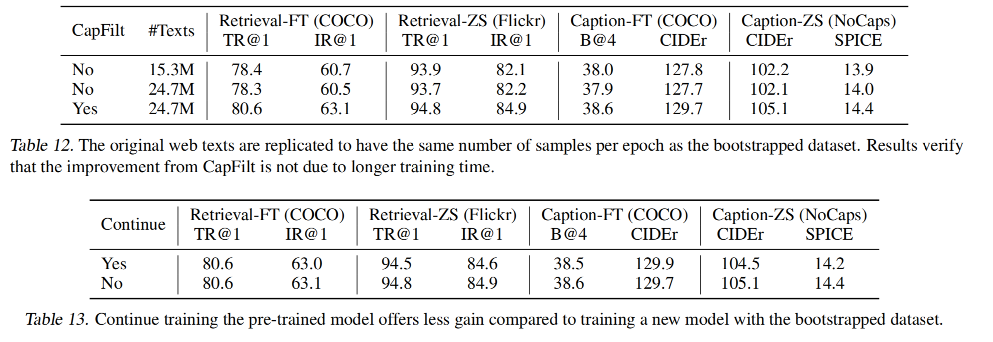
3.2 CapFilt 的效果
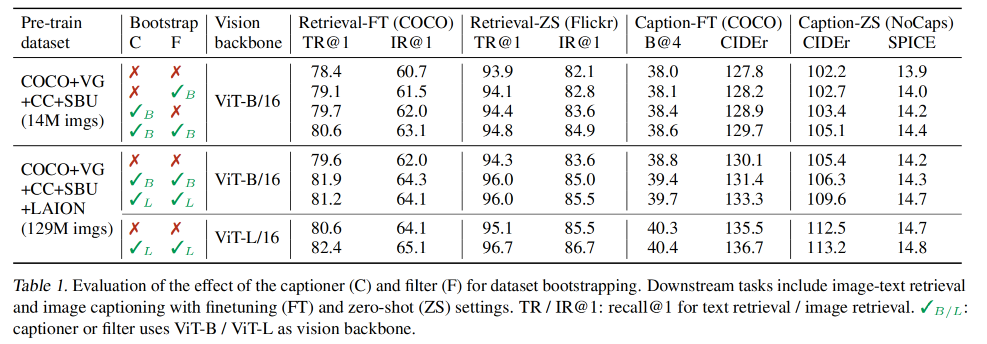
如表 1 所示,对比了模型在不同数据集上预训练时,使用 CapFilt 对下游任务的效果,如图文检索、生成文本描述等
- 当仅仅在 14M 数据集上使用 captioner 或 filter 时,可以带来一些性能的提升
- 当同时使用 captioner 和 filter 时,效果更好了
CapFilt 的作用:
- 通过使用更大的数据集和更大主干网络都可以进一步提高性能,这也验证了 CapFilt 在模型方面和数据方面都有提升的能力
- 此外,通过使用一个打的 ViT-L 用于 captioner 和 filter, base model 的性能也可以提高。
如图 4 展示了一些网络上的文本描述(红色)和合成的文本描述(绿色),说明了 captioner 的文本合成能力和 filter 的噪声文本过滤能力。

3.3 样本多样性是文本合成器的关键
在 CapFilt 中,作者使用 nucleus sampling 来生成合成的文本描述
- nucleus sampling 是一种随机解码的方式,每个解码 token 都是从大于阈值(如 0.9)的 token 中随机抽取的,能够为网络引入更大的样本多样性,包含了更多有利于网络学习的信息,所以效果更好一些
- beam search 是一种确定性的解码方式,选择得分最高的 token 作为对应的 text,少了一些多样性

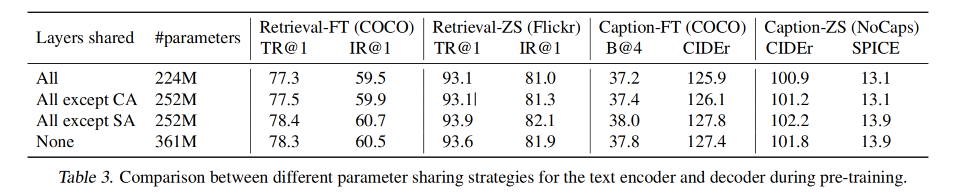
3.4 参数共享和解耦
在预训练阶段, text encoder 和 decoder 共享除了 self-attention 以外的参数,如表 3 所示,对比了几种不同的参数共享方式,在 14M 数据集和 LIONS 网络数据集上做的预训练。
结果表明:
- 共享除了 SA 以外的参数比不共享的效果更好,而且也能减少模型的参数,加速训练
- 如果共享 SA 层的参数的话,会因为 encoding 和 decoding 任务的冲突导致效果下降
在 CapFilt 中,captioner 和 filter 是分别在 COCO 上单独进行 finetuned 的
如表 4 所示,作者也验证了captioner 和 filter 共享参数的效果,会导致下游任务的性能下降
这应该是由于参数共享的话会导致 captioner 生成的 noisy caption 不能被 filter 过滤掉,也就是过滤的 noisy ratio 从 8% 降到了 25%。

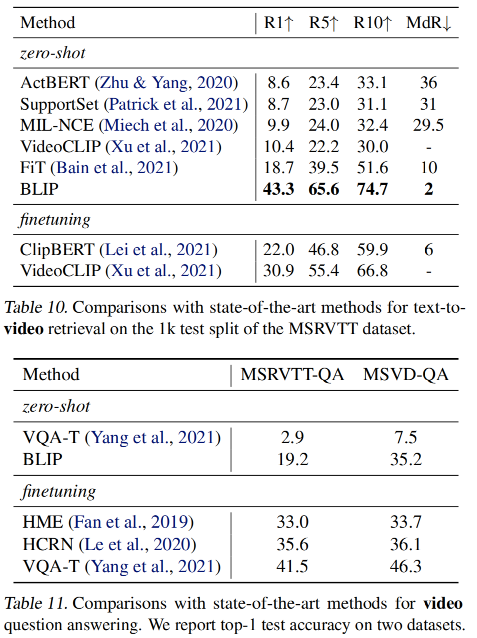
3.5 和 SOTA 的对比
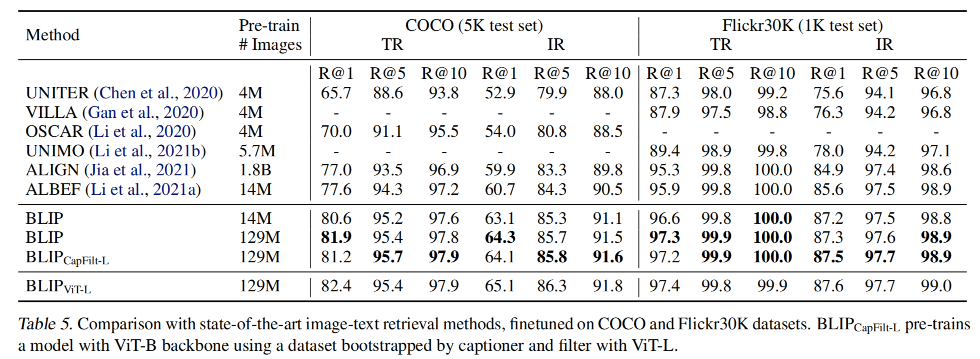
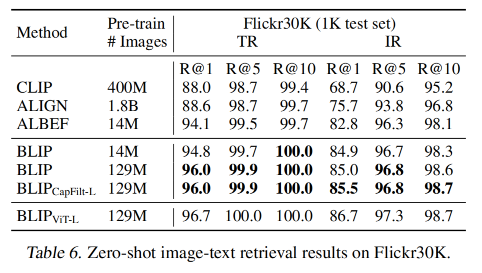
1、Image-text retrieval
作者在 COCO 和 Flickr30K 数据集上验证了 image-to-text retrieval (TR) 和 text-to-image retrieval (IR) 的效果
使用 ITC 和 ITM loss finetuned 了预训练好的模型
为了提高效率,作者首先基于 image-text 特征相似性选择 k 个候选,然后基于 ITM score 对这些候选排序
如表 5 和 6 所示,BLIP 获得了很好的效果
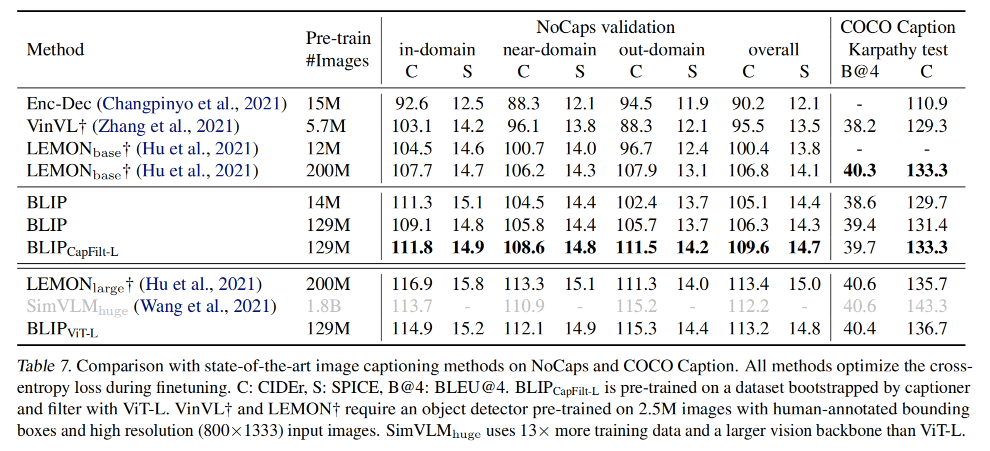
2、Image Captioning
使用 NoCaps 和 COCO 来作为评判数据集
作者给一个提示 “a picture of {}” 作为每个 caption 的开头
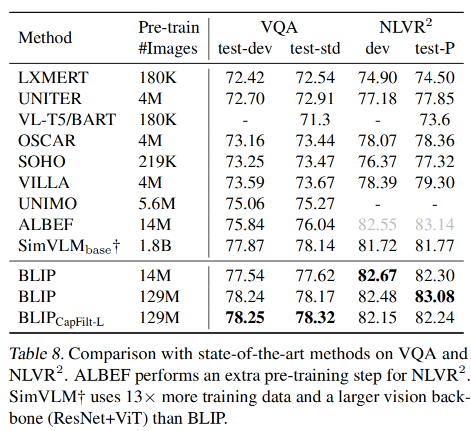
如表 7 所示,使用 14M 数据训练的 BLIP 超越了其他方法
使用 129M 数据训练的 BLIP 和使用 200M 数据训练的 LEMON 效果差不多
3、Visual Question Answering(VQA)
VQA 需要一个模型来对输入的图像和问题进行回答
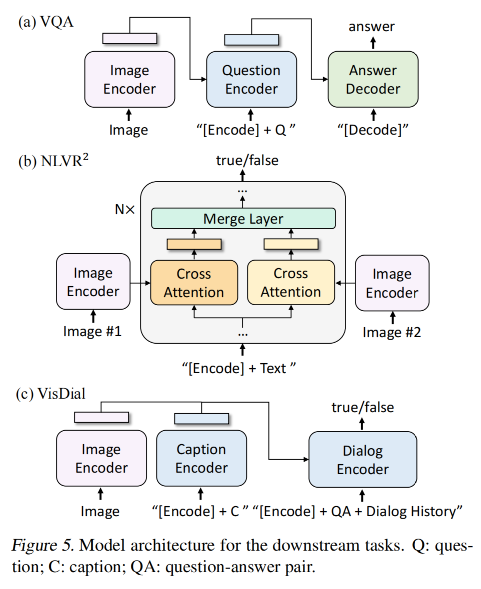
4、 Natural Language Visual Reasoning (NLVR2)
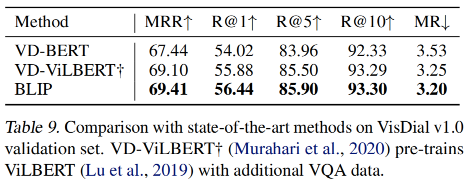
5、Visual Dialog (VisDial)