前一篇博客介绍了树莓派上tensorflow的配置,这里再配置下pytorch,主要还是通过已经编译好的whl来安装,其实我们平时直接pip install安装也是先从权威源网站上下载别人编译好的针对某种平台的安装包来安装的。如果需要源码安装,可以参考博主的其它博客(通过交叉编译来在树莓派上来配置,当然这里是其它的库)
Ubuntu下交叉编译OpenCV(WITH_QT)_竹叶青lvye的博客-CSDN博客_ubuntu交叉编译opencv
如下一篇是博主在windows x64平台上源码编译的tensorflow,方法可供借鉴。
win7下VS2015编译tensorflow源码教程(在线和离线)及调用配置_竹叶青lvye的博客-CSDN博客_vs编译教程
后续有精力,博主会来源码交叉编译安装下tensorflow及pytorch(直接在树莓派上编译花费太多时间,可以在别的平台上交叉编译好,然后将生成的库拷贝到site-packages文件夹下)。
1.配置好python环境
这里选择python3.7版本,树莓派上安装python3.7可参考博主之前博客
树莓派4B上多版本python切换(一)_竹叶青lvye的博客-CSDN博客_树莓派修改python版本
注意,如下此处安装和上面帖子不一样,之前编译静态库的命令语句如下:
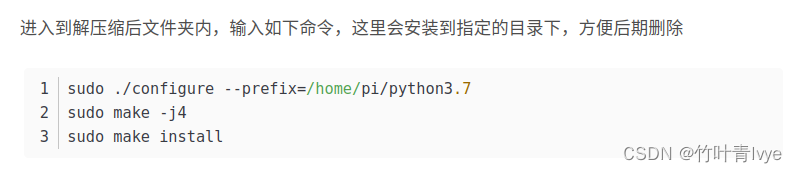
这里需要编译动态库,所以命令语句,suo ./configure --prefix=/home/pi/python3.7应改为
sudo ./configure --prefix=/home/pi/python3.7 --enable-shared其它两条命令还是同前。
完毕后,记得在.~/.bashrc中添加下环境变量
export LD_LIBRARY_PATH=/home/pi/python3.7/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}记得编辑好后执行下命令语句:source ~/.bashrc
同时注意,cd到编译获得的python3.7/lib目录下,执行下命令语句:
sudo cp -r libpython3.7m.so.1.0 /usr/lib

不然执行一些安装命令时,会出现报错:
After this operation, 1,861 kB of additional disk space will be used.
/usr/bin/python3: error while loading shared libraries: libpython3.7m.so.1.0: cannot open shared object file: No such file or directory
E: Sub-process /usr/bin/apt-listchanges --apt || test $? -lt 10 returned an error code (1)
E: Failure running script /usr/bin/apt-listchanges --apt || test $? -lt 10
2.安装numpy,博主这里安装的是如下版本
pip3 install numpy==1.21.2

3.分别下载pytorch、torchvision、torchaudio
这里需要结合自己树莓派的具体硬件情况来分析。
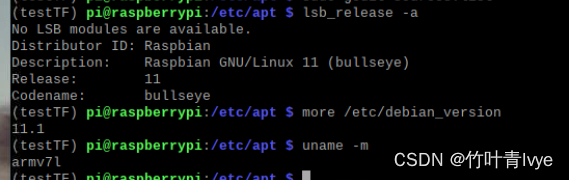
可看到博主的树莓派架构师armv71,然后如下网址
https://torch.kmtea.eu/whl/stable.html
博主下载的版本如下,这里和之前博客(当时是在在PC ubuntu20.04下)里的版本是一致的,可参考博客
使用Pytorch自带模型预测图片_竹叶青lvye的博客-CSDN博客_pytorch自带模型
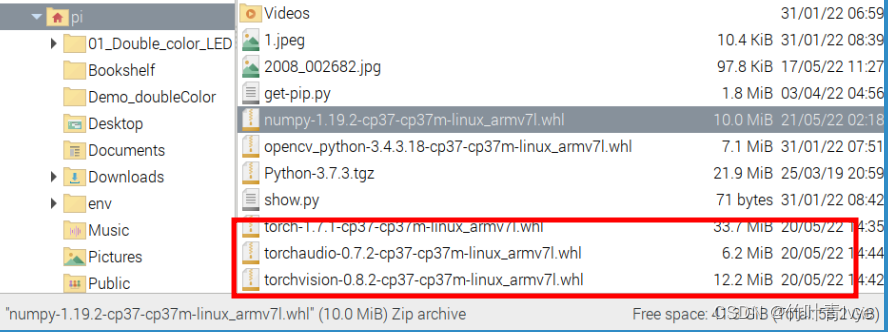
4.安装
分别执行如下命令语句进行安装
pip install torch-1.7.1-cp37-cp37m-linux_armv7l.whl
pip install torchaudio-0.7.2-cp37-cp37m-linux_armv7l.whl
pip install torchvision-0.8.2-cp37-cp37m-linux_armv7l.whl安装完毕后在对应python环境下import库看是否正常。

import torchvision的时候出现如下报错
File "/home/pi/python3.7/lib/python3.7/lzma.py", line 27, in <module>
from _lzma import *
ModuleNotFoundError: No module named '_lzma'
此时需要执行如下几条命令:
apt-get install liblzma-dev -y
pip install backports.lzma完毕后,再修改下上面报错中提到的/home/pi/python3.7/lib/python3.7/lzma.py文件

将上面红框标记处的代码修改为
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties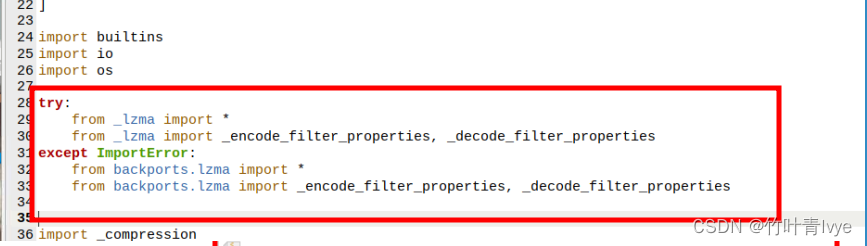
完毕后再次执行
import torchvision成功了。

5.验证
可以跑下博主之前的博客中的代码,稍微改了下,因为树莓派上没有gpu的配置,所以设置跑在cpu上,不用再去转成cuda形式了。
使用Pytorch自带模型预测图片_竹叶青lvye的博客-CSDN博客_pytorch自带模型
import torch
import torchvision
from PIL import Image
from torchvision import transforms
import torchvision.models as models
import time
vgg16 = torchvision.models.vgg16(pretrained=True)
#
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(), normalize]
)
img = Image.open("2008_002682.jpg")
print(img.size)
# 对图像进行归一化
img_p = transform(img)
print(img_p.shape)
# 增加一个维度
img_normalize = torch.unsqueeze(img_p, 0)
print(img_normalize.shape)
vgg16.eval()
t_model = time.perf_counter()
out = vgg16(img_normalize)
print(f'model cost:{time.perf_counter() - t_model:.8f}s')
# 最后一层是1000的一维向量,每一个表示对应类别的概率
print(out.shape)
with open('imagenet_classes.txt') as f:
classes = [line.strip() for line in f.readlines()]
_, indices = torch.sort(out, descending=True)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
prediction = [[classes[idx], percentage[idx].item()] for idx in indices[0][:5]]
print(prediction)
score = []
label = []
for i in prediction:
print('Prediciton-> {:<25} Accuracy-> ({:.2f}%)'.format(i[0][:], i[1]))
score.append(i[1])
label.append(i[0])
print(score)
结果如下:
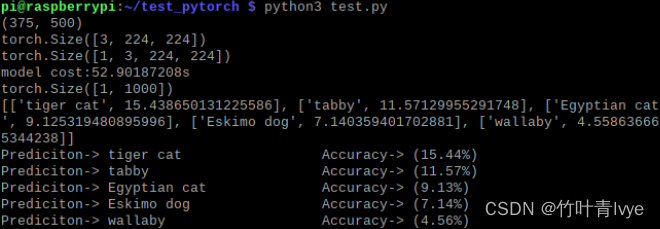
配置成功,可以看到这个预测时间接近53s了,太长了,后面会有博客介绍如何通过NSC 2神经棒来在树莓派上进行加速。
若需要在编译器里运行,可以参看之前博客方式