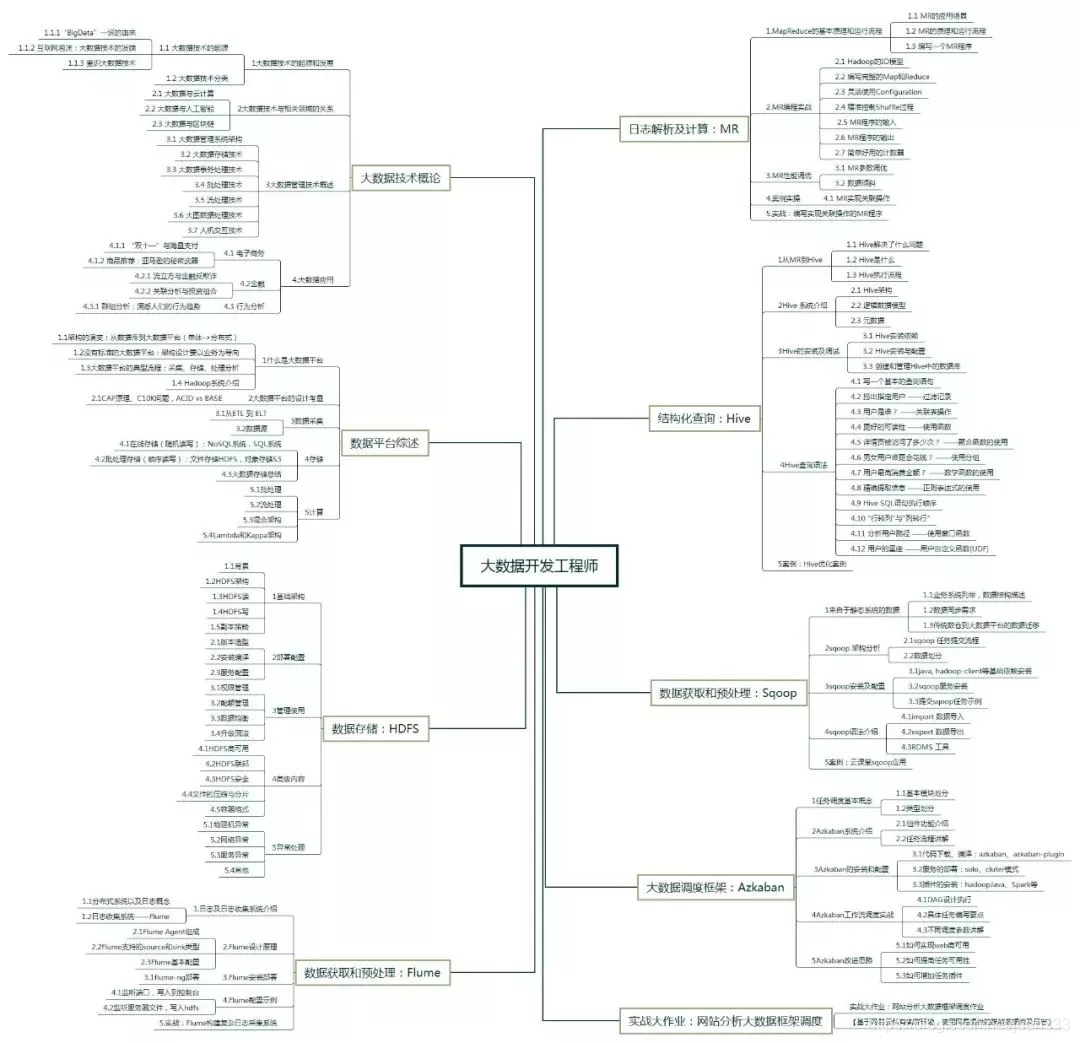
1、数据处理主要技术
Sqoop:(发音:skup)作为一款开源的离线数据传输工具,主要用于Hadoop(Hive) 与传统数据库(MySql,PostgreSQL)间的数据传递。它可以将一个关系数据库中数据导入Hadoop的HDFS中,
也可以将HDFS中的数据导入关系型数据库中。
Flume:实时数据采集的一个开源框架,它是Cloudera提供的一个高可用用的、高可靠、分布式的海量日志采集、聚合和传输的系统。目前已经是Apache的顶级子项目。使用Flume可以收集诸如日志、时间等数据
并将这些数据集中存储起来供下游使用(尤其是数据流框架,例如Storm)。和Flume类似的另一个框架是Scribe(FaceBook开源的日志收集系统,它为日志的分布式收集、统一处理提供一个可扩展的、高容错的简单方案)
Kafka:通常来说Flume采集数据的速度和下游处理的速度通常不同步,因此实时平台架构都会用一个消息中间件来缓冲,而这方面最为流行和应用最为广泛的无疑是Kafka。它是由LinkedIn开发的一个分布式消息系统,
以其可以水平扩展和高吞吐率而被广泛使用。目前主流的开源分布式处理系统(如Storm和Spark等)都支持与Kafka 集成。
Kafka是一个基于分布式的消息发布-订阅系统,特点是速度快、可扩展且持久。与其他消息发布-订阅系统类似,Kafka可在主题中保存消息的信息。生产者向主题写入数据,消费者从主题中读取数据。
作为一个分布式的、分区的、低延迟的、冗余的日志提交服务。和Kafka类似消息中间件开源产品还包括RabbiMQ、ActiveMQ、ZeroMQ等。
MapReduce:
MapReduce是Google公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度抽象为两个函数:map和reduce。MapReduce最伟大之处在于其将处理大数据的能力赋予了普通开发人员,
以至于普通开发人员即使不会任何的分布式编程知识,也能将自己的程序运行在分布式系统上处理海量数据。
Hive: MapReduce将处理大数据的能力赋予了普通开发人员,而Hive进一步将处理和分析大数据的能力赋予了实际的数据使用人员(数据开发工程师、数据分析师、算法工程师、和业务分析人员)。
Hive是由Face