原文:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#further-readings
torch.autograd是PyTorch的自动求导引擎,可以用来加速神经网络的训练。在本节,你将初步理解autograd是如何加速神经网咯训练的。
相关背景
神经网络(简称NN)是由一些内嵌函数组合而成,可以用来处理特定的输入数据。这些函数一般由一组参数来定义(参数一般包括权重和偏置),在Pytorch中,用tensors结构来存储这些参数。
训练一个神经网络通常需要两步:
前向传播:在前向传播过程中,神经网络接受输入数据并在内嵌函数中进行层层计算,最终得到一个当前网络的预测结果(这个结果通常与理想结果存在一定误差)。
反向传播:在反向传播过程中,神经网络根据本次计算得到的误差来进行权重的调整。具体做法是,把得到的结果在神经网络中进行反向传播,计算误差对每个参数节点的偏导数,然后利用梯度下降算法对节点参数进行调整(增大或减小)。如果你想进一步学习反向传播的详细原理,可以参考B站上3Blue1Brown相关的科普视频。
在PyTorch中的用法
我们先来看看神经网络的单词训练过程。在接下来的例子中,我们先从torchvision中加载resnet18预训练网络。我们首先创先一组tensor随机数来代表一个图像,图像有3个通道,宽度和高度均为64,它所对应的label也被初始化为一组随机变量。
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)
接下来,我们将创建的图像数据输入到resnet18网络中,经过层层计算,最终输出一个预测结果。这就是神经网络的前向传播过程。
prediction = model(data) # forward pass
现在我可以使用模型的prediction以及初始的label来计算本次的误差值(也称为loss)。接下来就是让误差值在网络中进行反向传播,当我们调用误差值(一般用tensor来表示).backward()方法时,整个网络的反向传播方法就开始启动。Pytorch的自动求导机制会计算网络中的每个参数的梯度并存储在相应参数的.grad属性当中。
loss = (prediction - labels).sum()
loss.backward() # backward pass
接下来我们加载一个优化器,本次例子中我们使用的时SGD(随机梯度下降方法),初始学习率为0.01、动量为0.9。我们将模型中的所有参数都导入到优化器当中。
optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
最后,我们调用优化器中的.step()方法。优化器会根据之前反向传播得到的参数梯度(存储在参数的.grad属性中)来更新所有的参数值。
optim.step() #gradient descent
到目前为止,你已经掌握了训练神经网络的所有要素。接下来的部分将探讨自动求导机制的一些实现细节,跳过这部分内容将不会影响你接下来的学习。
Autograd中的求导机制
我先来看看autograd如何得到参数的梯度值。我们先创建两个tensor变量a和b并设置requires_grad=True。这样autograd就会将这些变量的变化过程记录下来以便后续使用。
import torch
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
接下来我们创建另一个tensor变量Q,它由a和b计算得到。
Q = 3 a 3 − b 2 Q=3a^3-b^2 Q=3a3−b2
Q = 3*a**3 - b**2
其实这个式子可以看作一个最简单的神经网络,a和b是网络中的参数,Q是最终的误差值(也称为loss值)。在神经网络训练阶段,我们需要计算误差值对网络中参数的偏导数(也称为梯度)。
∂
Q
∂
a
=
9
a
2
,
∂
Q
∂
b
=
−
2
b
{\frac{\partial Q}{\partial a}}=9a^2,\quad {\frac{\partial Q}{\partial b}}=-2b
∂a∂Q=9a2,∂b∂Q=−2b
当我们调用Q的.backward()进行反向传播时,autograd会计算这些偏导数并存储在相对应参数的.grad属性当中。我们需要显式的传递一个gradient参数到Q.backward()方法,因为Q是一个向量(而非标量)。gradient的维度与Q相同,准确来说,它代表了Q对自己的梯度。
d
Q
d
Q
=
1
\frac{\mathrm{d}Q}{\mathrm{d}Q}=1
dQdQ=1
另一种方法是对Q进行求和(因为求和的结果是标量),然后再隐式的调用反向传播。例如Q.sum().backward()。
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
现在网络的梯度就存储在a.grad和b.grad当中。
# check if collected gradients are correct
print(9*a**2 == a.grad)
print(-2*b == b.grad)
显示:
tensor([True, True])
tensor([True, True])
选读部分 - 使用autograd来计算向量的偏导数
从数学上来说,如果现在有一个关于向量的函数:
y
⃗
=
f
(
x
⃗
)
\vec {y} = f(\vec {x})
y=f(x)
则向量y对x的偏导数是一个雅可比矩阵J:
J
=
(
∂
y
⃗
∂
x
1
⋯
∂
y
⃗
∂
x
n
)
=
(
∂
y
1
∂
x
1
⋯
∂
y
1
∂
x
n
⋮
⋱
⋮
∂
y
n
∂
x
1
⋯
∂
y
n
∂
x
n
)
J = \left( \frac{\partial \vec {y}}{\partial x_1}\quad\cdots\quad\frac{\partial \vec {y}}{\partial x_n} \right) = \left( \begin{matrix} \frac{\partial y_1}{\partial x_1} &\cdots &{\frac{\partial y_1}{\partial x_n}}\\ \vdots&\ddots&\vdots \\ \frac{\partial y_n}{\partial x_1} & \cdots & \frac{\partial y_n}{\partial x_n} \end{matrix} \right)
J=(∂x1∂y⋯∂xn∂y)=⎝⎜⎛∂x1∂y1⋮∂x1∂yn⋯⋱⋯∂xn∂y1⋮∂xn∂yn⎠⎟⎞
简单来说,torch.autograd就是一个计算向量-雅可比积的引擎。给定任意向量v,计算:
J
T
⋅
v
⃗
J^T\cdot\vec {v}
JT⋅v
如果v正好是标量函数的梯度所组成的向量:
l
=
g
(
y
⃗
)
=
(
∂
l
∂
y
1
⋯
∂
l
∂
y
n
)
l=g(\vec {y})=\left( \frac{\partial l}{\partial y_1}\quad\cdots\quad\frac{\partial l}{\partial y_n} \right)
l=g(y)=(∂y1∂l⋯∂yn∂l)
依据链式法则,计算的向量-雅可比积的结果将是L对向量x的梯度:
J
T
⋅
v
⃗
=
(
∂
y
1
∂
x
1
⋯
∂
y
n
∂
x
1
⋮
⋱
⋮
∂
y
1
∂
x
n
⋯
∂
y
n
∂
x
n
)
(
∂
l
∂
y
1
⋮
∂
l
∂
y
n
)
=
(
∂
l
∂
x
1
⋮
∂
l
∂
x
n
)
J^T\cdot\vec {v} =\left( \begin{matrix} \frac{\partial y_1}{\partial x_1} &\cdots &{\frac{\partial y_n}{\partial x_1}}\\ \vdots&\ddots&\vdots \\ \frac{\partial y_1}{\partial x_n} & \cdots & \frac{\partial y_n}{\partial x_n} \end{matrix} \right) \left( \begin{matrix} \frac{\partial l}{\partial y_1} \\ \vdots \\ \frac{\partial l}{\partial y_n} \end{matrix} \right) =\left( \begin{matrix} \frac{\partial l}{\partial x_1} \\ \vdots \\ \frac{\partial l}{\partial x_n} \end{matrix} \right)
JT⋅v=⎝⎜⎛∂x1∂y1⋮∂xn∂y1⋯⋱⋯∂x1∂yn⋮∂xn∂yn⎠⎟⎞⎝⎜⎛∂y1∂l⋮∂yn∂l⎠⎟⎞=⎝⎜⎛∂x1∂l⋮∂xn∂l⎠⎟⎞
上面的例子中我们就利用到了向量-雅可比积的这个特性,external_grad就代表向量v。
计算图概述
从定义上来看,autograd在一个由函数对象所组成的一个有向无环图(DAG)中记录所有的数据(张量)和相关的计算操作(以及随之生成的新张量)。在有DAG中,叶子节点通常是输入张量,根节点则是输出张量。首先通过在DAG中跟踪从根节点到叶子节点的整个计算过程,再通过链式法我们就可以自动计算出所有参数张量的梯度信息。
在一次前向传播过程中,autograd会同时完成两件事情:
-
在输入数据上执行所有的已定义的运算并输出结果。
-
在
DAG中保留所有操作相对应的梯度计算函数(.grad_fn)。
当调用DAG中根节点的.backward()函数时,反向传播开始执行,autograd会执行以下操作:
- 通过保存的
.grad_fn梯度计算函数计算相应的梯度信息。 - 将梯度信息累加到相应张量的
.grad属性当中。 - 通过链式规则,层层计算所有叶子节点的梯度信息。
接下来是一个DAG的可视化例子(Q=3a^3-b^2)。在图中,箭头表示了前向传播的方向,灰色节点则代表了反向传播所需要的计算函数,蓝色的叶子节点则代表参数张量a和b。
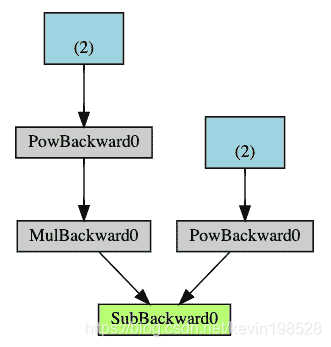
注意:
在PyTorch中DAGs是动态的,需要注意的是每次
DAG都是从头开始创建的。每次调用.backward()执行完反向传播操作后,autograd都会重新开始构建DAG。这种动态生成方法允许你在模型中使用各种控制流声明,意味着你可以在每次迭代中动态的修改模型的操作维度、尺寸和大小。
扩展学习